集群相关
Cluster Manager指的是在集群上获取资源的外部服务,为每个spark application在集群中调度和分配资源的组件,目前有三种类型:
• Standalone:Spark 原生的资源管理,由 Master 负责资源的分配
• Apache Mesos:与 Hadoop MapReduce 兼容性良好的一种资源调度框架
• Hadoop Yarn:主要是指的 Yarn 中的 ResourceManager
Worker 指集群中的工作节点,启动并运行executor进程,运行大数据培训作业代码的节点
• standalone模式下:Worker进程所在节点
• yarn模式下: yarn的nodemanager进程所在的节点
Deploy Mode 分为两种模式,client和cluster,区别在于driver运行的位置
• Client模式下driver运行在提交spark作业的机器上,
• 可以实时看到详细的日志信息
• 方便追踪和排查错误,用于测试
• cluster模式下,spark application提交到cluster manager,cluster manager(比如master)负责在集群中某个节点上,启动driver进程,用于生产环境
• 通常情况下driver和worker在同一个网络中是最好的,而client很可能就是driver worker分开布置,这样网络通信很耗时,cluster没有这样的问题
Spark分布式计算组成
Application
• 用户编写的Spark程序,通过一个有main方法的类执行,完成一个计算任务的处理。
• 它是由一个Driver程序和一组运行于Spark集群上的Executor组成
Driver
• 运行main方法的Java虚拟机进程负责
• 监听spark application的executor进程发来的通信和连接
• 将工程jar发送到所有的executor进程中
• driver调度task给executor执行
• Driver与Cluster Manager、Worker协作完成
• Application进程的启动
• DAG划分
• 计算任务封装
• 分配task到executor上
• 计算资源的分配等调度执行作业等
• Driver调度task给executor执行,所以driver最好和spark集群在一片网络内,便以通信
Executor
• 运行在worker节点上,负责执行作业的任务,并将数据保存在内存或磁盘中
• 每个spark application,都有属于自己的executor进程,spark application不会共享一个executor进程
• executor在整个spark application运行的生命周期内,executor可以动态增加/释放
• executor使用多线程运行SparkContext分配过来的task,来一批task就执行一批
用户操作spark的入口
SparkContext是Spark的入口,负责连接Spark集群,创建RDD,累积量和广播量等
• SparkContext是Spark的对外接口,负责向调用者提供Spark的各种功能
• driver program通过SparkContext连接到集群管理器来实现对集群中任务的控制
• 每个JVM只有一个SparkContext,一台服务器可以启动多个JVM
SparkSession
• The entry point to programming Spark with the Dataset and DataFrame API.
• 包含了SQLContext、HiveContext、sparkcontext
Spark计算切分相关
Job
• 一个spark application可能会被分为多个job,每次调用Action时,逻辑上会生成一个Job
• 一个Job包含了一个或多个Stage
Stage
• 每个job都会划分为一个或多个stage(阶段),每个stage都会有对应的一批task(即一个taskset),分配到executor上去执行
• Stage包括两类
• ShuffleMapStage
• ResultStage
TaskSet
• 一组关联的,但相互之间没有Shuffle依赖关系的Task集合
• Stage可以直接映射为TaskSet,一个TaskSet封装了一次需要运算的、具有相同处理逻辑的Task,
• 这些Task可以并行计算,粗粒度的调度是以TaskSet为单位的。
• 一个stage对应一个taskset
Task
• driver发送到executor上执行的计算单元,每个task负责在一个阶段(stage),处理一小片数据,计算出对应的结果
• Task是在物理节点上运行的基本单位,Task包含两类
• ShuffleMapTask => 对应于Stage中ShuffleMapStage中的一个执行基本单元
• ResultTask => 对应于Stage中ResultStage中的一个执行基本单元
Spark其他重要部分
数据结构
• RDD
• DataFrame 引入了schema和off-heap
• DataSet 整合了rdd和dataframe的优点,支持结构化和非结构化数据,采用堆外内存存储,gc友好
核心调度器
• DAGScheduler 根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler。
• SparkEnv Spark 公共服务们相互交互,用来给 Spark 应用程序建立分布式计算平台的运行时环境
• TaskScheduler 将Taskset提交给Worker node集群运行并返回结果。
Spark调度
提交方式
• yarn-cluster模式,用于生产模式,driver运行在nodeManager,没有网卡流量激增问题,但查看log麻烦,调试不方便
• Yarn-client模式,yarn-client用于测试,driver运行在本地客户端,负责调度application,会与yarn集群产生超大量的网络通信,从而导致网卡流量激增,yarn-client可以在本地看到所有log,方便调试
• yarn-client vs yarn-cluster
• yarn-client下,driver运行在spark-submit提交的机器上,ApplicationMaster只是相当于一个ExecutorLauncher,仅仅负责申请启动executor;driver负责具体调度
• yarn-cluster下,ApplicationMaster是driver,ApplicationMaster负责具体调度
Spark通用任务执行过程
• 用户通过 spark-submit 脚本提交应用
• spark-submit 脚本启动Driver,调用用户定义的 main() 方法构建sparkConf和sparkContext对象,在sparkContext入口做了三件事,创建了
• sparkEnv对象
• TaskScheduler
• DAGScheduler
• Driver与cluster manager通信,申请资源以启动Executor;
• cluster manager为Driver启动Executor;
• 在用户应用中代码遇到对RDD的action算子操作的时候,触发一个job,这时就会
• 调用DAGScheduler对象进行Stage划分,将划分好的stage按照分区生成一个一个的task,并且封装到TaskSet对象中
• TaskSet提交到TaskScheduler,TaskScheduler按照提交过来的TaskSet,拿到一个序列化器,将TaskSet序列化,将序列化好的Task封装并且提交到worker
• 任务在Executor中进行计算并保存结果;
• 如果Driver的 main() 方法退出,或者调用了SparkContext.stop(),Driver会终止Executor,并且通过集群管理器释放资源。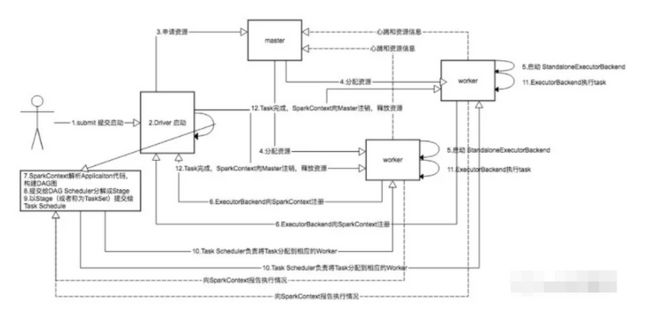
spark 提交过程分析standalone
• SparkContext连接到Master,向Master注册并申请资源
• Master根据资源申请要求和Worker心跳周期内报告的信息决定在哪个Worker上分配资源,然后在该Worker上获取资源,然后启动StandaloneExecutorBackend
• StandaloneExecutorBackend向SparkContext注册,建立Executor线程池
• SparkContext将Applicaiton代码发送给StandaloneExecutorBackend
• SparkContext解析Applicaiton代码,构建DAG图,
• 提交给DAG Scheduler分解成Stage(当碰到Action操作时,就会催生Job;每个Job中含有1个或多个Stage,Stage一般在获取外部数据和shuffle之前产生)
• 以Stage(或者称为TaskSet)提交给Task Scheduler,
• Task Scheduler负责将Task分配到相应的Worker,最后提交给StandaloneExecutorBackend执行
• StandaloneExecutorBackend会建立Executor线程池,开始执行Task,并向SparkContext报告,直至Task完成。
• 所有Task完成后,SparkContext向Master注销,释放资源。