机器学习——聚类算法之DBSCAN(密度聚类)
学习周志华老师《机器学习》的P211密度聚类。通过matlab编程实现。
DBSCAN全称为“Density-Based Spatial Clustering of Applications with Noise”,密度聚类相较于基于距离的K均值算法的优点有二:
1.密度聚类不需要预设分类数,而K均值算法/学习向量量化和高斯混合聚类都需要预先设好分类数
2.密度聚类可以排除部分噪音点,接下来的实例可以体现
3.可以发现任意形状的聚类
算法逻辑描述如照片所示,我是看书搞懂后,根据以下算法逻辑进行地编程:
关于一些基本概念比如“核心对象/密度直达/密度可达/密度相连”就不在这里赘述了,可以找《机器学习》这本书看,书上的介绍比较细致。
以下是我的matlab程序:
clc,clear,close all
data1=[0.697,0.774 0.634 0.608 0.556 0.403 0.481 0.437 0.666 0.243 0.245 0.343 0.639 0.657 0.36 0.593 0.719 0.359 0.339 0.282 0.748 0.714 0.483 0.478 0.525 0.751 0.532 0.473 0.725 0.446];
data2=[0.460 0.376 0.264 0.318 0.215 0.237 0.149 0.211 0.091 0.267 0.057 0.099 0.161 0.198 0.37 0.042 0.103 0.188 0.241 0.257 0.232 0.346 0.312 0.437 0.369 0.489 0.472 0.376 0.445 0.459];
data=[data1' data2'];
% 定义参数Eps和MinPts
MinPts = 5;
Eps = 0.11;
[m,n]=size(data);
for i=1:m
for j=i:m
dis(i,j)=norm(data(i,:)-data(j,:));
end
end
dis=triu(dis,0)+tril(dis',-1); %矩阵对角对称得到各个点距所有点的距离
%找出所有核心对象
omega=[];
for i=1:m
ind=length(find(dis(i,:)=MinPts
omega=[omega i];
end
end
%判断是否有核心对象
if(isempty(omega))
error('参数设置原因,没有核心对象')
end
plot(data(:,1),data(:,2),'ko');
grid on;
axis([0.1 0.9 0 0.8])
hold on
plot(data(omega,1),data(omega,2),'k*')
%初始化聚类簇数
k=0;
gamma=1:m;
while omega~=0
gammaold=gamma;
if k==0
hexin=8; %omega(randi([1 m]));
else
hexin=omega(randi([1 length(omega)]));
end
Q=hexin;
gamma(find(gamma==hexin))=[];
while ~isempty(Q)
q=Q(1);
Q(1)=[];
ind=(find(dis(q,:)=MinPts
delta=intersect(gamma,ind);
Q=[Q delta];
gamma=setdiff(gamma,delta);
end
end
k=k+1;
C=setdiff(gammaold,gamma);
cu{k}=C;
omega=setdiff(omega,C);
end
scatter(data(cu{1},1),data(cu{1},2),'b')
scatter(data(cu{2},1),data(cu{2},2),'r')
scatter(data(cu{3},1),data(cu{3},2),'g')
scatter(data(cu{4},1),data(cu{4},2),'m') 比较了一下,比网上的聚类算法更精简一些,欢迎学习及转载(转载请表明出处)。其中数据是书上例子的数据。
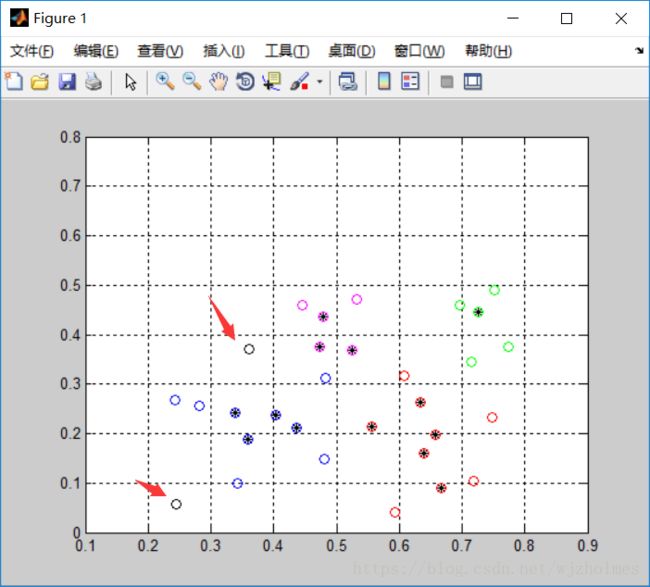
以下是程序的运行结果,其中每种颜色代表一类,“*”表示是核心对象,圆圈表示是一般数据点。
显而易见,数据共被分为四类,且我箭头所指的两个黑色圆圈在这四类之外,也就是我开头所说的噪音点。
为方便大家直接调用matlab函数,我将其改成函数包,使用格式,大家在matlab里help dbscan就看到了。函数下载链接如下:
密度聚类算法matlab函数