U-Net学习笔记及Pytorch实战训练细节
文章目录
- 前言
- 一、卷积和核(Convolution and Kernels)
-
- 1.什么是卷积
- 2.什么是核
- 二、卷积层与全连接层的共同点
-
- 1.全连接层(Fully-connection)
- 2.卷积层1×1
- 三、U-Net
-
- 1.反卷积
- 2.U-Net结构
- 四、U-Net实战(Pytorch)
-
- 1.项目描述
- 2.搭建U-Net
-
- 2.1卷积层
- 2.2上采样层
- 2.3完成U-Net结构搭建
- 3.数据集定义
- 4.训练
- 5.预测
- 参考链接
前言
因为毕设需要针对遥感影像进行语义分割,在这里记录一下自己学习的心路历程。
提示:以下是本篇文章正文内容,下面案例可供参考
一、卷积和核(Convolution and Kernels)
1.什么是卷积
卷积和加法、乘法一样,只是一种数学运算,选择不同的内核,如“锐化”、“边缘检测”、“滤波”等,通过内核与原图像进行卷积,便能实现相应的功能。
例如,让我们找下图A的轮廓(边缘)。

给出一个内核如下:

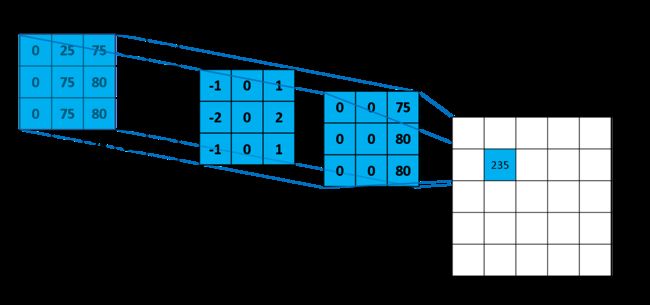



2.什么是核
感谢前人的大量研究,我们有了很多功能明确的核,例如上文的Vertical Sobel,可以提取图像的垂直信息,但是我们应该思考两个问题:
①我们并不知道需要用到怎样的核;
②假设你知道需要怎样功能的核,但并不是所有我们需要的核都被明确的开发出来了
因此,核中的值应该是被当做参数,通过误差反向传播、优化“学”出来的。就和简单的神经网络一样。
具体怎么理解呢?
首先,我们应该有这么一个认识:一个8×8的图像,一共有64个像素点,每个像素点的值都是它的一个特征,也就是输入的一个节点,通过卷积,结果会被放入到另一些节点,即隐藏节点,而核中的每个值对应着输入节点与隐藏节点的联系,即权重。这些权重以与普通神经网络完全相同的方式学习:首先随机初始化核值,将卷积后的结果与实际输出进行比较(然后对其进行误差反向传播和优化),最终迭代出新的核值。如果输入图像是二维的(即单通道),那么针对某一个功能的核(例如下图的绿色核)也是二维的,当你想提取四类特征时候,就应该采用4个二维核:
二、卷积层与全连接层的共同点
在一个识别X与O的任务中,我们输入一张图像,经过一系列卷积层、池化层后,得到了3×2×2的特征图:
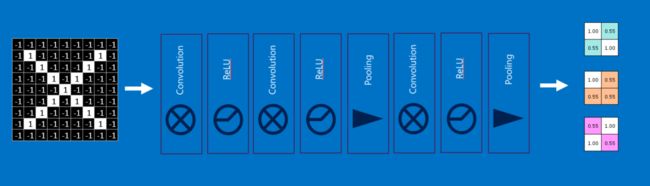
1.全连接层(Fully-connection)
全连接层所扮演的角色是主要建构单元,当我们向这个单元输入图片时,它会将所有像素的值当成一个一维清单,而不是前面的二维矩阵,清单里的每个值都可以决定图片中的符号是O还是X,不过这场选举并不全然民主。由于某些值可以更好地判别叉,有些则更适合用来判断圈,这些值可以投的票数会比其他值还多。所有值对不同选项所投下的票数,将会以权重(weight)的方式来表示。下图连接线的不同粗细代表权重的高低。
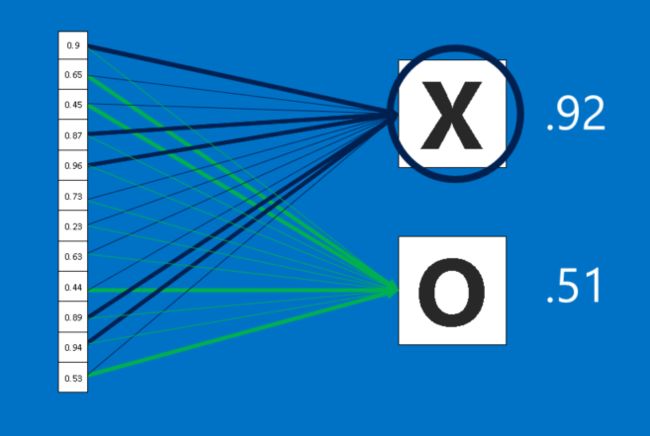
2.卷积层1×1
全连接层的结果是输入图像归属某类的强度,但很多时候我们需要得到的是输入图像中各个像素归属某类的强度,此时可以用1×1的卷积层来等价代替全连接层。
下图展示了1×1卷积核的计算,输出中的每个元素来自输入中在高和宽上相同位置的元素在不同通道间的按权重累加,这与上文的卷积运算相同。假设我们将通道维当作特征维,每个像素位置当成一个数据样本,那么一个样本是1×3,共有9个样本,输入为9×3。于是下图实际上是9个全连接层的组合,每组样本与核的卷积输出就相当于一个全连接层输出,下图的两个通道维对应着两个输出类别。

三、U-Net
1.反卷积
经过上面的学习我们知道,卷积会导致尺寸变小,为了使得输入输出图像有相同的尺寸,我们会填充原图像(padding)。
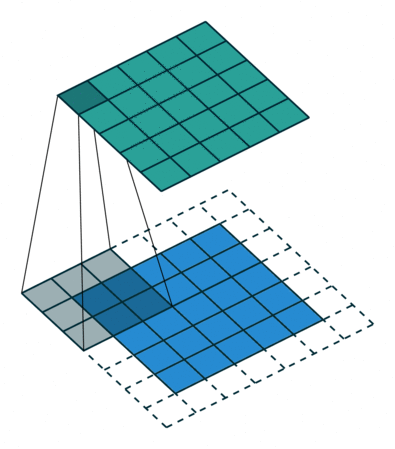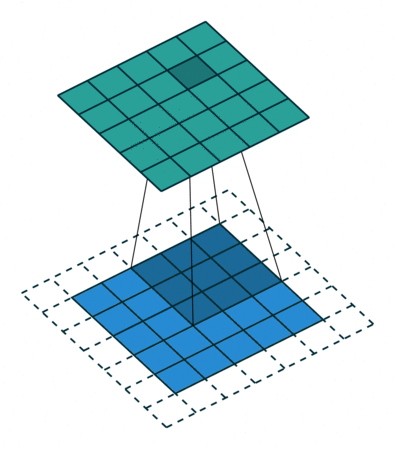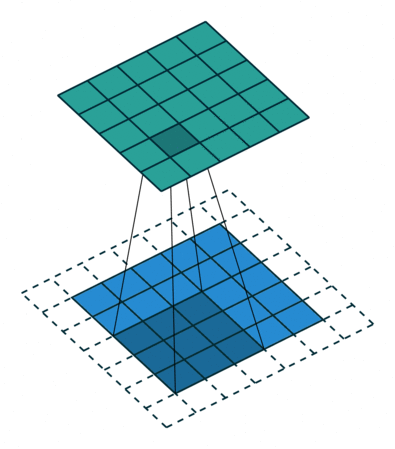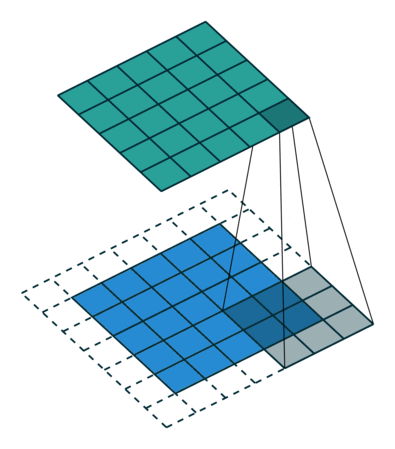
2.U-Net结构
U-Net: Convolutional Networks for Biomedical Image Segmentation

U形的结构非常简洁优雅,灰色的箭头是Skip Connection,是将不同深度的下采样层的输出裁剪后与同深度的上采样层的输入叠加,叠加结果为通道数加倍,目的在于保留下采样中部分损失的特征信息。绿色的箭头是反卷积,产生的结果是通道数减半但尺寸加倍。最后一层采用了1×1卷积层,目的是二分类。
为什么最终输出图片尺寸与输入图片尺寸不同呢?原论文中首先对数据进行了镜像填充,可以减少有效数据的损失。此外,有些图像尺寸较大(如遥感影像),需要分块输入,之后再拼接结果,这样做还可以避免拼接过程中边缘部分不连接问题。
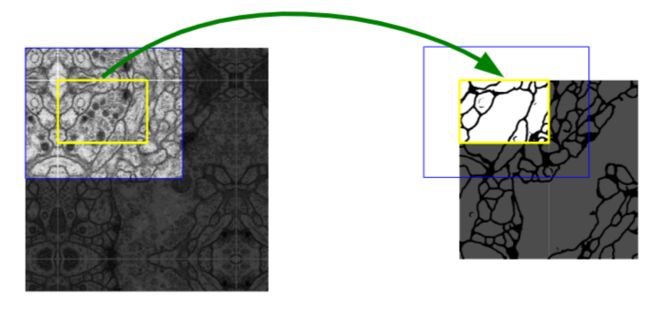
为什么是四层深网络,而不是五层、六层,网络越深精度会越高吗?针对不同的训练数据,会有不同的最佳网络深度,网络过深会出现“退化”现象,即随着网络层数变多,训练误差反而降低了。
强烈推荐阅读:研习U-Net
四、U-Net实战(Pytorch)
1.项目描述
复现原论文中的医学图像分割实验,共有30张原始图像,分辨率为512×512。

2.搭建U-Net
根据U-Net的结构,首先重现卷积池化层与上采样层,最后再在Unet中按顺序连接起来。
2.1卷积层
导入模块,实现卷积层
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary
#1.模型搭建
#***数据tensor是四维的(N,C,H,W)
#①卷积层
class Unetconv(nn.Module):
def __init__(self,in_channels,out_channels):
super(Unetconv,self).__init__()
self.conv1=nn.Sequential(
nn.Conv2d(in_channels,out_channels,kernel_size=3,stride=1,padding=0),
nn.ReLU(inplace=True),#inplace=True,节省内存开销
)
self.conv2=nn.Sequential(
nn.Conv2d(out_channels,out_channels,kernel_size=3,stride=1,padding=0),
nn.ReLU(inplace=True),
)
def forward(self,X):
X=self.conv1(X)
outputs=self.conv2(X)
return outputs
2.2上采样层
Attention 1:在最后一行的torch.cat()中,我们需要数据在通道维进行叠加,而网络中的数据是四维的,(批大小,通道数,高,宽),dim=0时按批叠加,dim=1时按通道数叠加,大家可以动手实现下面这个例子来加深理解。
x=torch.randn(1,2,3)
print("x.shape:",x.shape)
print("dim1.shape:",torch.cat((x,x),dim=1).shape)
print("dim2.shape:",torch.cat((x,x),dim=2).shape)
输出:
x.shape: torch.Size([1, 2, 3])
dim1.shape: torch.Size([1, 4, 3])
dim2.shape: torch.Size([1, 2, 6])
Attention 2:反卷积层的输出通道数为in_channels//2(//为向下取整除法),但进入卷积层的张量是torch.cat()后的,因此Unetconv的输入通道数是in_channels.
Attention 3:torch.cat()要求待叠加张量在除叠加维度外的其他维相同,例如按通道维叠加,那么另外三个维度应该完全相同(批大小、高、宽)。批大小是人为给定一定相同,高和宽是不同的,因此需要对高、宽进行裁剪(crop),也就是U-Net结构中的copy and crop,pad=[左,右,上,下],数组中的数大于0为填充,小于0为裁剪,例如“左=-2”则原图像裁剪两列。详细见:functional.pad()说明文档
#②上采样层
class upconv(nn.Module):
def __init__(self,in_channels, out_channels):
super(upconv,self).__init__()
self.conv=Unetconv(in_channels, out_channels)
#①反卷积
self.upconv1=nn.ConvTranspose2d(in_channels, in_channels//2, kernel_size=2, stride=2)
#②skip connection,数据合并
def forward(self,inputs_R,inputs_U):
#self,x2,x1
outputs_U=self.upconv1(inputs_U)
offset=outputs_U.size()[-1]-inputs_R.size()[-1]
pad=[offset//2,offset-offset//2,offset//2,offset-offset//2] # 2*[1,1]=[1,1,1,1]
outputs_R=F.pad(inputs_R,pad)
#这里教程写的dim=1,但torch(c,h,w),我觉得dim=0的时候才是通道相加
#tensor是四维的,所以dim=1,即按三维拼接
return self.conv(torch.cat((outputs_U,outputs_R),dim=1))
2.3完成U-Net结构搭建
在最后的1×1卷积层中,为了使得输出结果与原始图像有相同尺寸,使用了Upsample层,这并不是最好的办法。
#③完成U-net构建
#in_channels:图片维度
#n_classes:最终分类数
class Unet(nn.Module):
def __init__(self,in_channels=3,n_classes=1):
super(Unet,self).__init__()
self.in_channels=in_channels
filters=[64,128,256,512,1024]
#下采样
self.conv1=Unetconv(self.in_channels,filters[0])
self.maxpool1=nn.MaxPool2d(kernel_size=2)
self.conv2=Unetconv(filters[0],filters[1])
self.maxpool2=nn.MaxPool2d(kernel_size=2)
self.conv3=Unetconv(filters[1],filters[2])
self.maxpool3=nn.MaxPool2d(kernel_size=2)
self.conv4=Unetconv(filters[2],filters[3])
self.maxpool4=nn.MaxPool2d(kernel_size=2)
self.center=Unetconv(filters[3],filters[4])
#上采样
self.upnet4=upconv(filters[4],filters[3])
self.upnet3=upconv(filters[3],filters[2])
self.upnet2=upconv(filters[2],filters[1])
self.upnet1=upconv(filters[1],filters[0])
#
self.final=nn.Sequential(
nn.Conv2d(filters[0],n_classes,kernel_size=1),
######为了使得输出与label同尺寸,这里加入了一个Upsample层,但为什么是2D而不是4D呢?
nn.Upsample(size=(512, 512)),
)
def forward(self,inputs):
#下
conv1=self.conv1(inputs)
maxpool1=self.maxpool1(conv1)
conv2=self.conv2(maxpool1)
maxpool2=self.maxpool2(conv2)
conv3=self.conv3(maxpool2)
maxpool3=self.maxpool3(conv3)
conv4=self.conv4(maxpool3)
downputs=self.maxpool4(conv4)
centerputs=self.center(downputs)
#上
up4=self.upnet4(conv4,centerputs)
up3=self.upnet3(conv3,up4)
up2=self.upnet2(conv2,up3)
up1=self.upnet1(conv1,up2)
#1×1
final=self.final(up1)
return final
3.数据集定义
Pytorch提供了自定义数据集的框架,我们需要重构dataset,然后用dataloader读取,框架如下:
对Dataloader感兴趣的话推荐看一下这个:Dataloader讲解-Miracle8070
# ================================================================== #
# Input pipeline for custom dataset #
# ================================================================== #
# You should build your custom dataset as below.
class CustomDataset(torch.utils.data.Dataset):
def __init__(self):
# TODO
# 1. Initialize file paths or a list of file names.
pass
def __getitem__(self, index):
# TODO
# 1. Read one data from file (e.g. using numpy.fromfile, PIL.Image.open).
# 2. Preprocess the data (e.g. torchvision.Transform).
# 3. Return a data pair (e.g. image and label).
pass
def __len__(self):
# You should change 0 to the total size of your dataset.
return 0
# You can then use the prebuilt data loader.
custom_dataset = CustomDataset()
train_loader = torch.utils.data.DataLoader(dataset=custom_dataset,
batch_size=64,
shuffle=True)
于是我们自定义数据集如下,我的理解是:在__init__()中得到一个列表,这个列表中的每个元素是一个图片的路径,即[图片路径1,图片路径2,…],在__getitem__(index)中,用index来挨个读取某一个图片路径,从而能得到一张图片数据,及其对应标签数据,再return即可。
from torch.utils.data import Dataset
from matplotlib import pyplot as plt
import os
import glob
import cv2
import random
class MyDataset(Dataset):
def __init__(self,data_dir,transform=None):
# TODO
# 1. Initialize file paths or a list of file names.
self.data_dir=data_dir
#img_dir为图片路径列表
self.img_dir=glob.glob(os.path.join(data_dir,'image/*.png'))
def __getitem__(self, index):
# TODO
# 1. Read one data from file (e.g. using numpy.fromfile, PIL.Image.open).
# 2. Preprocess the data (e.g. torchvision.Transform).
# 3. Return a data pair (e.g. image and label).
#先传入图片的路径列表
img_path=self.img_dir[index]
#修改后得到了对应标签的路径列表
label_path=img_path.replace('image','label')
#得到图片和标签数据
image = cv2.imread(img_path)
label = cv2.imread(label_path)
#数据转换为单通道
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
label = cv2.cvtColor(label, cv2.COLOR_BGR2GRAY)
image = image.reshape(1, image.shape[0], image.shape[1])
label = label.reshape(1, label.shape[0], label.shape[1])
#把标签从[0,255]变到[0,1]
if label.max()>1:
label=label/255
flipCode = random.choice([-1, 0, 1, 2])
if flipCode != 2:
## 使用cv2.flip进行数据增强,filpCode为1水平翻转,0垂直翻转,-1水平+垂直翻转
image = cv2.flip(image, flipCode)
label=cv2.flip(label,flipCode)
return image,label
def __len__(self):
# You should change 0 to the total size of your dataset.
return len(self.img_dir)
4.训练
损失函数采用了论文中的交叉熵损失函数,优化算法采用了RMSprop。训练中保存了best_model.pth,它是loss最小时保存的模型参数,并不是最后一次迭代的模型参数。
from torch import optim
def train_net(net, device, data_path, epochs=10, batch_size=15, lr=0.001):
# 加载训练集
isbi_dataset = MyDataset(data_path)
train_loader = torch.utils.data.DataLoader(dataset=isbi_dataset,
batch_size=batch_size,
shuffle=True)
# 定义RMSprop算法
optimizer = optim.RMSprop(net.parameters(), lr=lr, weight_decay=1e-8, momentum=0.9)
# 定义Loss算法
criterion = nn.BCEWithLogitsLoss()
# best_loss统计,初始化为正无穷
best_loss = float('inf')
# 训练epochs次
for epoch in range(epochs):
# 训练模式
net.train()
# 按照batch_size开始训练
for image, label in train_loader:
optimizer.zero_grad()
# 将数据拷贝到device中
image = image.to(device=device, dtype=torch.float32)
label = label.to(device=device, dtype=torch.float32)
# 使用网络参数,输出预测结果
pred = net(image)
# 计算loss
loss = criterion(pred, label)
print('Loss/train', loss.item())
# 保存loss值最小的网络参数
if loss < best_loss:
best_loss = loss
torch.save(net.state_dict(), 'best_model.pth')
# 更新参数
loss.backward()
optimizer.step()
print("训练结束")
5.预测
# 选择设备,有cuda用cuda,没有就用cpu
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 加载网络,图片单通道1,分类为1。
net = Unet(in_channels=1, n_classes=1)
# 将网络拷贝到deivce中
net.to(device=device)
# 指定训练集地址,开始训练
data_path = "C:/Users/tc/Desktop/lesson-2/data/train/"
train_net(net, device, data_path)
参考链接
How do Convolutional Neural Networks work?
Dive into Pytorch
Convolutional Neural Networks - Basics