拓端tecdat|R语言谱聚类、K-means聚类分析非线性环状数据比较
原文链接:http://tecdat.cn/?p=23276
原文出处:拓端数据部落公众号
有些问题是线性的,但有些问题是非线性的。我假设,你过去的知识是从讨论和解决线性问题开始的,这是一个自然的起点。对于非线性问题的解决,往往涉及一个初始处理步骤。这个初始步骤的目的是将问题转化为同样具有线性特征的问题。
一个教科书式的例子是逻辑回归,用于获得两类之间的最佳线性边界。在一个标准的神经网络模型中,你会发现逻辑回归(或多类输出的回归)应用于转换后的数据。前面的几层 "致力于 "将不可分割的输入空间转化为线性方法可以处理的东西,使逻辑回归能够相对容易地解决问题。
同样的道理也适用于谱聚类。与其用原始输入的数据工作,不如用一个转换后的数据工作,这将使它更容易解决,然后再链接到你的原始输入。
谱聚类是一些相当标准的聚类算法的重要变体。它是现代统计工具中的一个强大工具。谱聚类包括一个处理步骤,以帮助解决非线性问题,这样的问题可以用我们所喜欢的那些线性算法来解决。例如,流行的K-means。
内容
- 谱系聚类的动机
- 一个典型的谱聚类算法
- 编码实例
谱聚类的动机
"一张图片胜过万语千言"(Tess Flanders)。
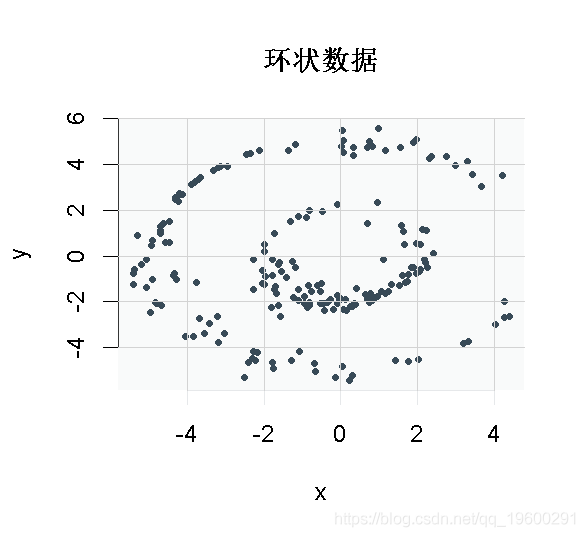
目标是划分两个不相交的类别。我们的数据就有这种 "两个环 "的形状。你可以看到,由于数据不是线性可分离的,K-means解决方案没有太大意义。我们需要考虑到数据中特别的非线性结构。 做到这一点的方法之一是使用数据的特征子空间,不是数据的实际情况,而是数据的相似性矩阵。
典型的谱聚类算法步骤
输入:n个样本点![]() 和聚类簇的数目k;
和聚类簇的数目k;
输出:聚类簇![]()
(1)使用下面公式计算![]() 的相似度矩阵W;
的相似度矩阵W;

W为![]() 组成的相似度矩阵。
组成的相似度矩阵。
(2)使用下面公式计算度矩阵D;
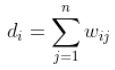 ,即相似度矩阵W的每一行元素之和
,即相似度矩阵W的每一行元素之和
D为![]() 组成的
组成的![]() 对角矩阵。
对角矩阵。
(3)计算拉普拉斯矩阵![]() ;
;
(4)计算L的特征值,将特征值从小到大排序,取前k个特征值,并计算前k个特征值的特征向量![]() ;
;
(5)将上面的k个列向量组成矩阵![]() ,
,![]() ;
;
(6)令![]() 是的第
是的第 行的向量,其中
行的向量,其中![]() ;
;
(7)使用k-means算法将新样本点![]() 聚类成簇
聚类成簇![]() ;
;
(8)输出簇![]() ,其中,
,其中,![]() .
.
上面就是未标准化的谱聚类算法的描述。也就是先根据样本点计算相似度矩阵,然后计算度矩阵和拉普拉斯矩阵,接着计算拉普拉斯矩阵前k个特征值对应的特征向量,最后将这k个特征值对应的特征向量组成![]() 的矩阵U,U的每一行成为一个新生成的样本点,对这些新生成的样本点进行k-means聚类,聚成k类,最后输出聚类的结果。这就是谱聚类算法的基本思想。相比较PCA降维中取前k大的特征值对应的特征向量,这里取得是前k小的特征值对应的特征向量。但是上述的谱聚类算法并不是最优的,接下来我们一步一步的分解上面的步骤,总结一下在此基础上进行优化的谱聚类的版本。
的矩阵U,U的每一行成为一个新生成的样本点,对这些新生成的样本点进行k-means聚类,聚成k类,最后输出聚类的结果。这就是谱聚类算法的基本思想。相比较PCA降维中取前k大的特征值对应的特征向量,这里取得是前k小的特征值对应的特征向量。但是上述的谱聚类算法并不是最优的,接下来我们一步一步的分解上面的步骤,总结一下在此基础上进行优化的谱聚类的版本。
编码示例
环数据在代码中是对象dat。下面的几行只是简单地生成K-means解决方案,并将其绘制出来。
plot(dat, col= kmeans0cluster)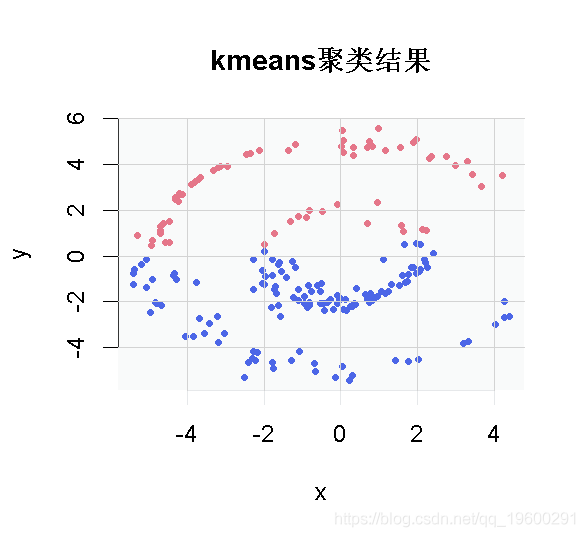
现在是谱聚类解决方案。
# 计算距离矩阵
dist(dat, method = "euclidean", diag= T, upper = T)
sig=1 # 超参数
# 一个点与自身的距离为零
diag(tmpa) <- 0 #设置对角线为零
# 计算程度矩阵
# 因为D是一个对角线矩阵,所以下面一行就可以了:
diag(D) <- diag(D)^(-0.5)
# 现在是拉普拉斯的问题:
# 特征分解
eig_L <- eigen(L, symmetric= T)
K <- 4 # 让我们使用前4个向量
# 它是相当稳健的--例如5或6的结果不会改变
x <- eig_L$vectors[,1:K]
# 现在进行归一化处理:
sqrt( apply(x^2, 1, sum) ) # 临时分母
# 临时分母2:转换为一个矩阵
# 创建Y矩阵
# 在y上应用聚类
# 可视化:
plot(dat, col= spect0$cluster)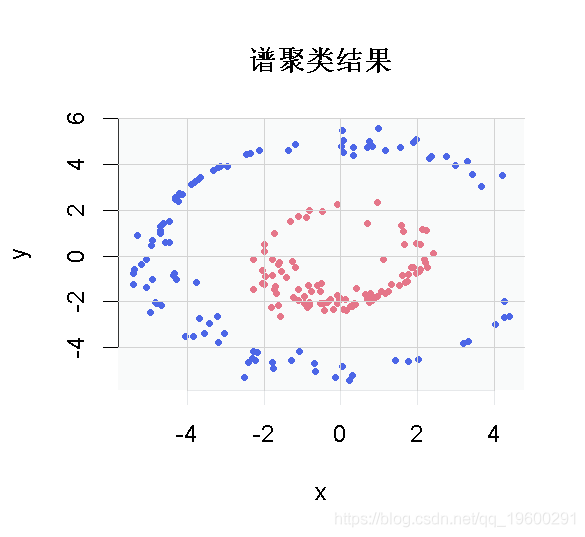
* 在我们的例子中,![]() 的条目不仅是0和1(连接或不连接),而且是量化相似性的数字。
的条目不仅是0和1(连接或不连接),而且是量化相似性的数字。
参考资料
Ng, Andrew Y., Michael I. Jordan, and Yair Weiss. “On spectral clustering: Analysis and an algorithm.” Advances in neural information processing systems. 2002.

最受欢迎的见解
1.R语言k-Shape算法股票价格时间序列聚类
2.R语言中不同类型的聚类方法比较
3.R语言对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归
4.r语言鸢尾花iris数据集的层次聚类
5.Python Monte Carlo K-Means聚类实战
6.用R进行网站评论文本挖掘聚类
7.用于NLP的Python:使用Keras的多标签文本LSTM神经网络
8.R语言对MNIST数据集分析 探索手写数字分类数据
9.R语言基于Keras的小数据集深度学习图像分类