python爬虫实战经典案例,突破反爬!爬取短视频!
今天在爬取某梨短视频时,发现前端代码跟之前都不一样了。加入了很多的反爬措施。在此特意记录一下!
先来看一下最终执行结果:
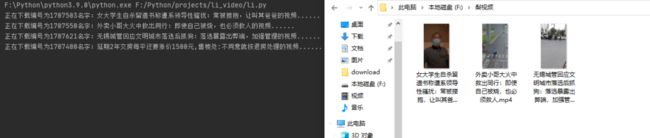
爬虫重要的不是写代码,而是分析!分析它的网页请求!
爬虫的基本过程一般如下:
1-发送请求
2-获取响应
3-解析并提取数据
4-保存数据
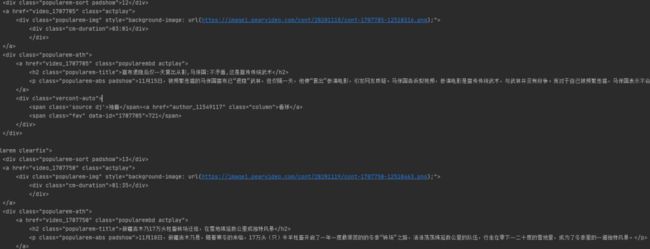
1.分析翻页网页
11.首先我们进入某梨视频首页如下,今天准备爬取的排行榜中的视频:
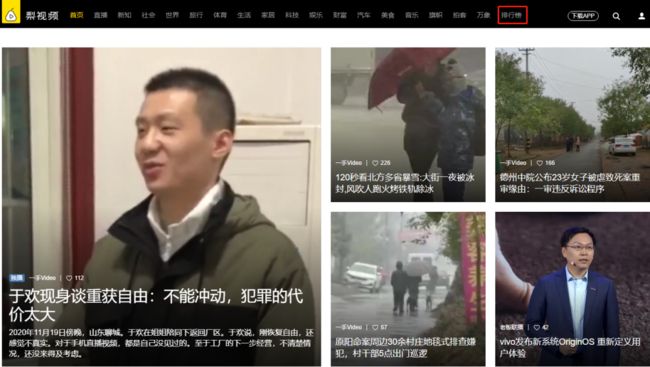
1.2.点开排行榜网页我们先来简单分析一下,发现它默认显示10个视频。
1.3.点击‘加载更多’或者继续下拉它会继续添加10个视频。是不是可以简单理解为它是以10为步长的格式来显示视频的?
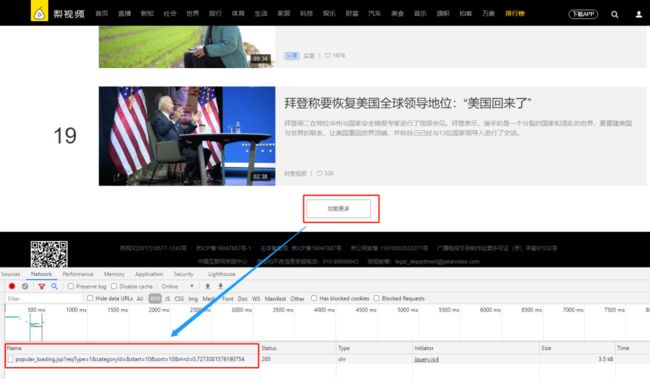
1.4.我们找到翻页功能对用的这个链接:

1.5.观察一下这个翻页链接:
https://www.pearvideo.com/popular_loading.jsp?reqType=1&categoryId=&start=10&sort=10&mrd=0.4643802437122859
发现它其中一个参数:start=10&sort=10
可以确认它是从第十条开始的,然后每页10条数据展示的方式显示的。
1.6.网页分析完成之后我们来进行编码:
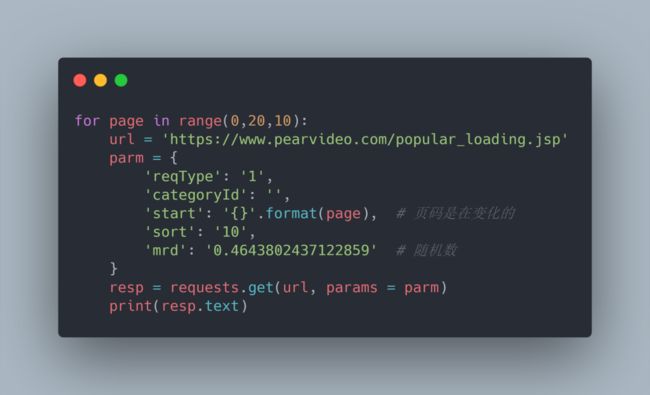
1.7.可以看出,我们在翻页这一层已经成功的爬到数据了。
2.分析视频网页
2.1.接下来我们点开视频,然后F12找到当前视频的请求链接
https://www.pearvideo.com/videoStatus.jsp?contId=1707705&mrd=0.8367214711596567
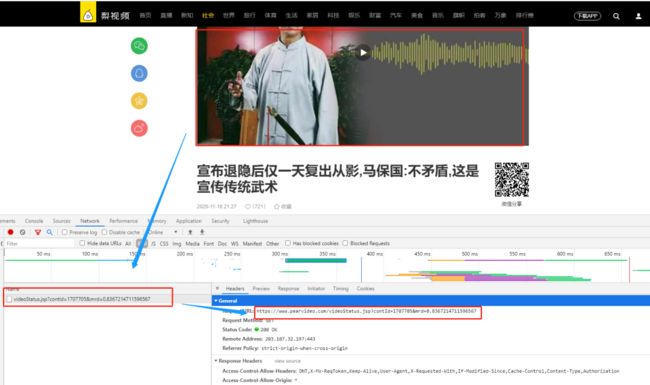
2.2.然后我们使用该链接模拟网络请求看是否可以获取到我们想要的视频
{"resultCode":"5","resultMsg":"该文章已经下线!","systemTime": "1605792063821"}
可以看出这条路是不行的,但是视频是确实存在的,为什么会显示文章下线了呢?有没有想到被反爬了呢?
2.3.咱们继续分析网页:
我们可以在Elements中也可以发现一个视频链接:
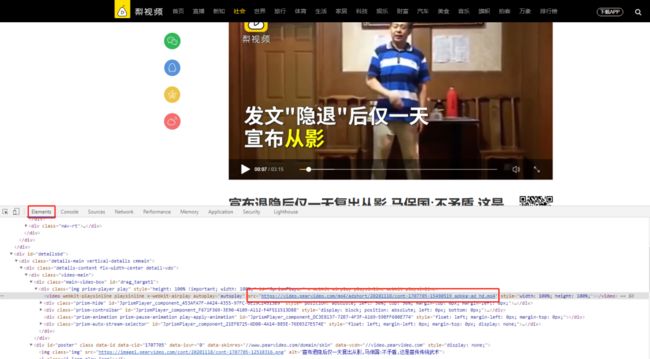
https://video.pearvideo.com/mp4/adshort/20201118/cont-1707705-15490519_adpkg-ad_hd.mp4
2.4点开这条链接发现是可以成功播放和下载的,说明我们最终要获取的视频里链接就是这条:

但是这条链接通过上面网页分析是获取不到的,显示文章下线还记得吗?所以我们还需要继续分析。
2.5经过分析观察,我们在preview中发现一个MP4格式的视频播放链接,会不会是这个呢?
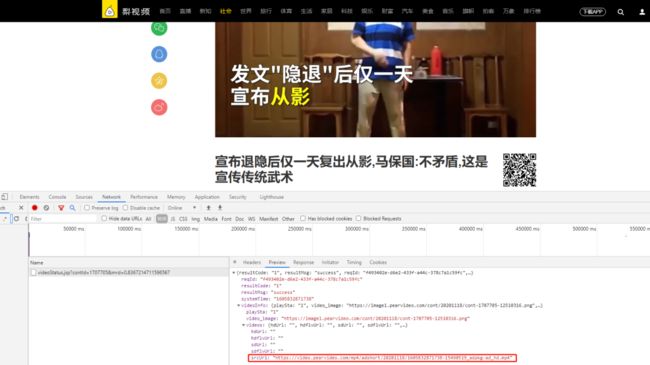
2.6.点开看一下发现是一条无效的链接。

2.7.现在通过网页分析出三条链接:
视频链接: https://www.pearvideo.com/videoStatus.jsp?contId=1707705&mrd=0.8367214711596567网页可播放链接:https://video.pearvideo.com/mp4/adshort/20201118/cont-1707705-15490519_adpkg-ad_hd.mp4网页请求连接:https://video.pearvideo.com/mp4/adshort/20201118/1605832871738-15490519_adpkg-ad_hd.mp4
再来捋一下啊。
我们通过视频链接得到的是网页请求连接,也就是第三个。但是这个链接显示的是404。
嵌套在网页中可播放视频的真实链接是第二个,但是我们请求不到。
所以我们就要想法子通过第三个链接构造出类似于第二个的可播放链接。
先来观察一下他们之间不同之处:发现这两个视频链接不同之处就在于一个是时间戳,一个是video_id。也就是说我们只要将第三个链接的时间戳改成跟第二个一样的video_id即可成功播放该视频。但是video_id又是在第一个链接中,所以我们就要想办法通过造出这条第二条可播放视频的链接。
2.8.刚才通过翻页链接我们已经得到video_id和video_name了。
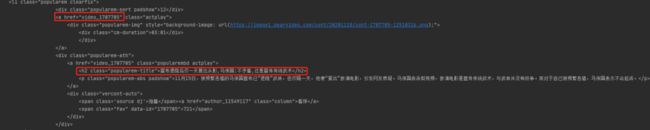
2.9现在我们需要用正则将其提取出来即可:
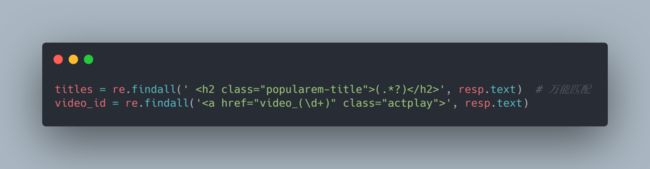
['1707591', '1707705', '1707750', '1707696', '1707630', '1707694', '1707710', '1707688', '1707716']
['女大学生自杀留遗书称遭系领导性骚扰:常被搂抱,让叫其爸爸', '外卖小哥大火中救出同行:即使自己被烧,也必须救人', '无锡城管回应文明城市落选后抓狗:落选暴露出弊端,加强管理', '延期2年交房每平还要涨价1500元,售楼处:不同意就按退房处理', '蛋壳公寓称仍可正常租房,律师支招蛋壳租客房东如何维权', '护士在副院长家楼顶自杀,父母拒收32万赔偿:他要求我们不发声', '幼儿园点名凭空多出1个娃,谁都不认识:亲妈首次送还送错地方', '痛惜!安徽2名蓝天救援队员潜水训练时遇难,一人捐出遗体', '四川眉山一水泥罐车与公交车追尾,致15人受伤,事发监控曝光', '爱马仕将建最大鳄鱼养殖场,5万只用来供应皮革和肉类产品']
2.10可以发现我们视频所需的video_id和video_name都已经被展示出来了
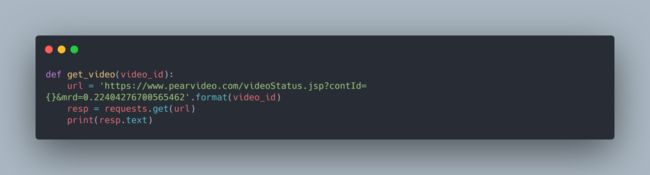
2.11接下来就是提取视频播放链接然后替换我们已经获取到video_id即可。还记得刚才的文章下线吗,就是被反爬了。加入我们的爬虫三件套。
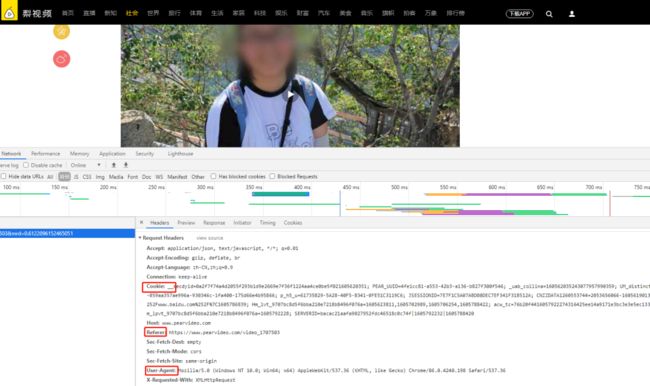
2.12可以看出我们获取到视频播放链接,再不是刚才的文章下线提示了。但这个不是真正的地址。还需要用video_id进行对时间戳的替换
https://video.pearvideo.com/mp4/adshort/20201118/1605835214479-15490655_adpkg-ad_hd.mp4https://video.pearvideo.com/mp4/adshort/20201118/1605835231211-15490519_adpkg-ad_hd.mp4https://video.pearvideo.com/mp4/adshort/20201119/1605835236250-15490907_adpkg-ad_hd.mp4https://video.pearvideo.com/mp4/adshort/20201118/1605835241582-15490403_adpkg-ad_hd.mp4
2.13所以接下来我们要做的就是替换,我们用正则表达式来实现

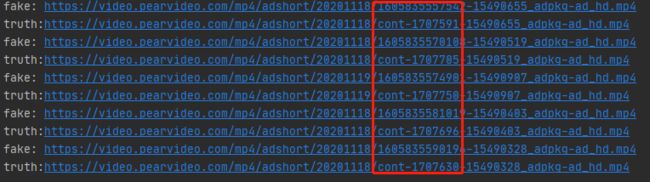
2.14可以看到所有链接的时间戳都已经成功被video_id替换。接下来我们找一个真实的链接试一下看是否可以成功播放

2.15可以看到是没有任何问题的。
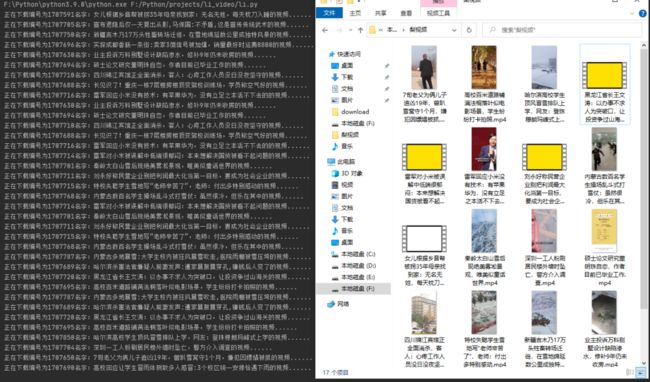
接下来我们需要将这些视频进行保存。

2.16现在视频已经被我们成功保存到指定位置了!

源码已经上传,需要的童鞋可以关注微信公众号'印象python'回复‘某梨视频’