点云上的深度学习及其在三维场景理解中的应用————PointNet(一)
最近在学3D方向的语义分析。
师兄推荐了一个哔哩大学的将门创投 | 斯坦福大学在读博士生祁芮中台:点云上的深度学习及其在三维场景理解中的应用!的宝藏视频,我会多看几遍,并写下每次观看笔记。
下文的截图都源自讲解的PPT,在我的资源:祁芮中台点云讲解.pdf
全篇手码,内容较多会持续更新。
带问号的句子都是乘上引下的重点作用,文章分为三篇,这是第一篇请耐心食用。

正文开始
Emerging 3D Applications
3D应用很多,比如自动驾驶

VR
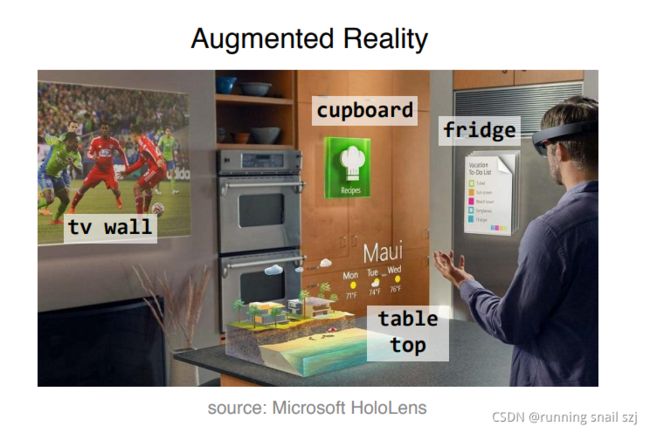
3D Representations
三维数据的深度学习和二维有不一样的地方,最大的不一样就是由三维数据的本书复杂性带来的,不像图像可以很精准的表示为二维矩阵:RGB。三维数据有很多种的表达形式,不同的表达形式有不同的应用驱动。如下下边四种表达形式:

第一种是点云,opint cloud,是一组点的集合,可以由深度传感器扫描得到的深度数据。
第二种为Mesh,可以由三角面片组成,在计算机图形学中有很多应用,是一种适合做建模、渲染的数据格式。
第三种Volumetric,可以把空间划分成三维的网格,每一个小的正方体代表此处有没有物体,就形成了一个结构来代表空间中物体的分布。
第四种Multi-View Images RGB(D),可以用图片的形式表达三维,用多个角度的图片来表达三维常常用在可视化的过程中,因为人对图片的理解远远好于对3D的理解。
在这多种表达中,点云数据是一种非常适合三维场景理解算法的格式,原因有二。
一:点云是最接近于最原始的传感器数据的,比如用激光雷达扫描到的数据直接就是点云,深度传感器有一个深度图像,实际上也是点云,只不过是一个局部的点云。这种原始的数据可以做出端到端的深度学习,能尽可能挖掘原始数据中的模式。
二:点云在表达形式中是十分简单的,仅仅是一组点,和其他格式相比,例如Mesh需要选择是三角面片还是四角或五角面片,以及面片的大小和链接方式,选择空间复杂。Volumetric需要选择分辨率,选择多大的网格,若选的小,则会有很多空白的区域,大则损失精度。Multi-View Images RGB(D)需要选择一些图像拍摄的角度,同时对3D表达形式不全面,仅仅能表达一个视角,不能表达完整的3D数据。
Previous Work(前人的工作概述)
点云是一种不规则的数据,不是定义在规则的网格上,在空间种任意分布,数量上也是任意。之前的研究工作是把他先转换成一种栅格化编程的规则数据,比如变成一个三维的栅格,他就会分布在一个均匀的三维网格中,我们就可以用3D CNN(2D CNN的扩展)来处理这种数据,这是一个很经典的做法。如下图:


但是有缺点:
一:三维的卷积他的代价很高,空间的复杂度和时间的复杂度随着分辨率的增长都是N的三次方(三次幂)的增长,计算代价很大,只能采用很低的分辨率,会带来量化的噪声错误,会限制识别的精确度。
二:若不计不复杂度,分辨率很高的话,会有很多空格是空白的状态,扫描物体只能扫描到表面,而内部是空白的,所以其实栅格并不是对三维的最好表达形式。
除了栅格化的转化,还有人尝试把3D的点云投影到一个平面,这样3D数据就变成了一个2D的数据,然后用2D的卷积神经网络去处理。这样做会损失一些3D的信息,因为投影的过程中3D会产生丢失,而且要决定投影的角度,并不简单。
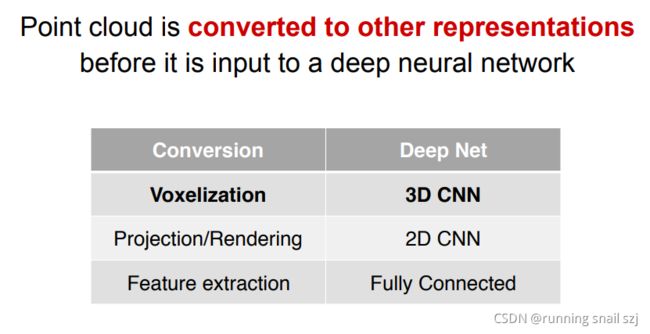
还有很多的方法,比如点云中手工提取特征,然后用一些用全连接的网络去处理,这样会被手工提取的局限性限制住。
综上:我们能不能做一种直接在点云上做特征学习的方法?有,PointNet。
PointNet:用于三维场景理解的点云深度学习
(此方法已经有别人总结过,可以看我上传的资源:PointNet.pdf)

下图有直接的感观,比如最左边是一个物体的点云(杯子、桌子)分开成不同的类,也可以把一个物体分成不同的区块,比如第二列,可以把飞机分成飞机机翼和机身,桌子分成桌面和桌脚。给出一个常见的空间的点云也可以做语义的分割,可以把场景的点分成桌子椅子墙壁,完成一系列的任务。

我们构建模型必须考虑点云的两点特性:
- 置换不变性:点云是一组无序点,点的顺序不影响集合本身。
- 变换不变性:点云旋转不应改变分类结果
首先看第1点:

点云往往会表达成二维的矩阵,他是一个N行D列的矩阵,N行代表有N个点,D列就代表每个点有D维的特征,最简单的D=3就代表这个点的xyz坐标,也可以有更多的特征比如颜色、法向量。若把矩阵的行做了变换,比如下图蓝色从一行到四行,他表示的仍是同一个点集。这就要求设计的网络对所有的置换都一样。

那如何做到置换的不变性?有一个系统化的解决方案,那就是设计一个对称函数。
因为神经网络本身就是一个函数,对称函数有置换不变性。下图为举例的取最大值的池化,就和点的顺序无关,取所有点的和、平均都无关。

在这种对称函数的框架下,如何利用神经网络来构建一组对称函数?
Construct Symmetric Functions by Neural Networks:构建过程为以下四个图片。
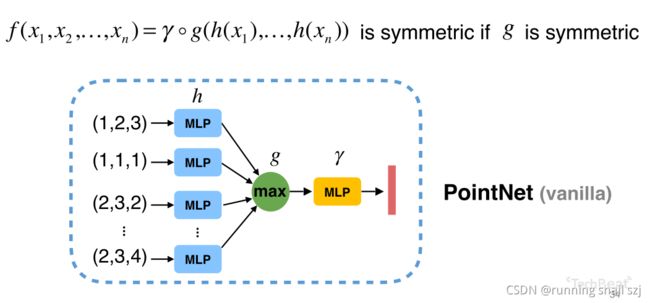
下图从最简单的例子开始,我们有一组点(第一个点坐标为(1,2,3))。我们取最大值,第一维最大值为2、第三维最大值为4,得出(2,3,4)。但这样的话我们只能得到最大值,其他信息就丢失了。

怎么才不丢失?
我们先把每个点映射到一个高维的空间,比如用一个一千维的空间来表示三维空间,再来做取最大值的对称性操作,可以避免信息丢失。
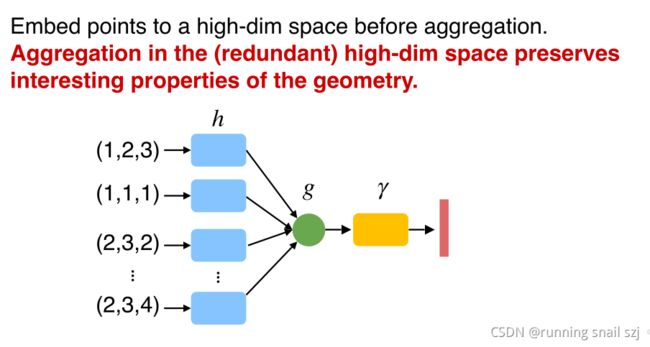
这个过程实际是一个函数的组合,函数g、h、r的一个组合,h把每个点做低维到高维的映射,然后只要函数g是对称的那么整个函数就是对称的。这个结构叫做原始的PointNet结构。
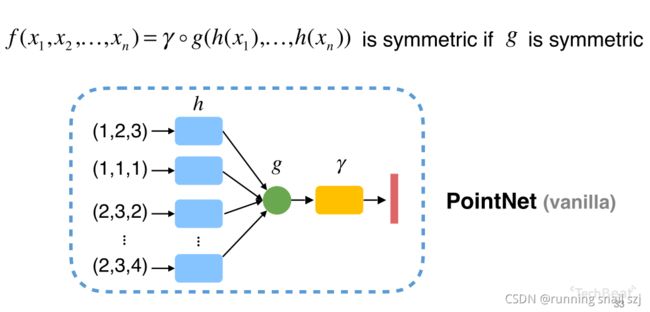
执行过程可以用多层感知器来描述函数h、r。对于函数g可以有很多种选择,比如max就是一个对称性好的池化操作。
我们用神经网络构建了PointNet(vanlilla),那么在所有的对称函数空间中,他占据了一个什么位置呢?什么函数能代表什么函数并不能代表呢?

实际上PointNet可以成为一种Universal Approximation(通用近似),可以任意的逼近集合上的对称函数。只要这个对称函数是在Hausdorff空间中是连续的,我们就可以通过增加神经网络的个数和网络的宽度来任意逼近这个函数。理论上是可行的。

再看第2点:
如何来应对输入点云的几何变换?一辆车从不同角度看都应该是车,网络也要应对这种视角的变化。

通过以下几个图片就可以理解:
Input Alignment by Transformer Network
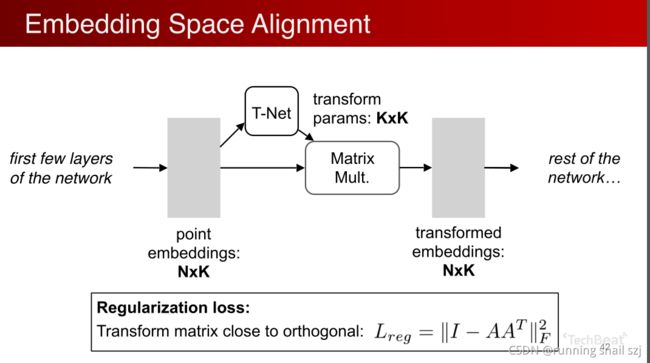
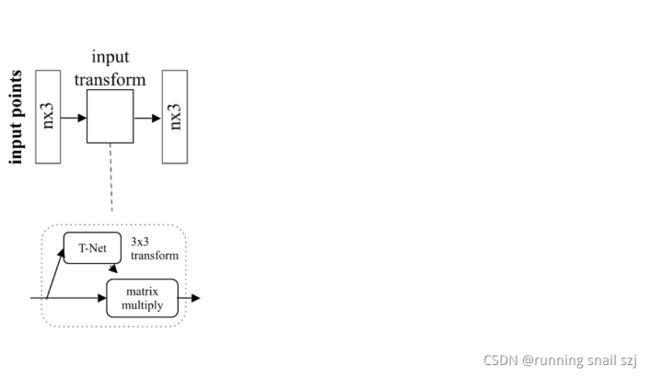
增加一个基于数据本身的变换函数模块。下图最左边输入的点云是n×3,有n个点,三个位置xyz。我们希望对这个点做一个变换,有一个神经网络T-Net,来生成一个变化参数,然后对n×3的点云做变换生成另一组变换后的点,之后再用后面的网络机制处理这组点。我们希望通过整体优化这个变换函数以及之后的网络,使得这个变换函数能够自动的去对准对齐我的输入,若对齐后会使得后面网络的任务很简单,把不同视角的问题简化。

实际中,点云是一个很容易做几何变换的数据,不像图片中要设计一个transform的network要涉及到很多插值等操作。点云里很简单,只要做一个矩阵的乘法就可以。比如对一个正交化的变化仅仅是一个3×3的矩阵乘法。实现很简单。

推广这个操作,不仅是输入时做这个变换,我们还可以在点的中间特征做这个变换。比如我们刚开始有几层网络已经把每个点变换成了k维,有一个N×K维的矩阵,每个点有k维的特征。我们可以用另外一个网络生成一个k×k的变换,我们可以用对个特征做一个特征空间的变换,也可以通过矩阵乘法方式实现。这样变换完我们得到另一组特征,用接下来的网络进行处理。在优化过程中,因为高维的变换优化起来难度高,我们加一个Regularization loss(正则化损失),比如我们希望这个矩阵尽可能的接近一个正交矩阵。
PointNet Classification Network
现在我们看如何把这些变换的网络和我们原始的PointNet结合起来,得到我们最终的分类网络和分割网络?
一步一步来看:
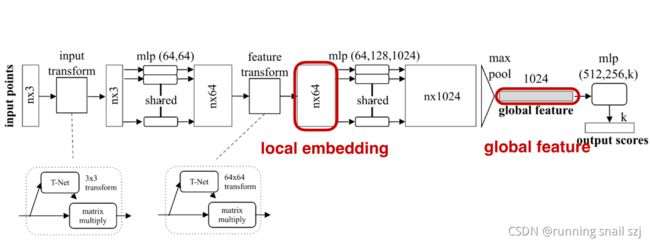
给定输入的点云,n×3。

先做输入的几何变换,通过一个变换网络生成一个3×3的矩阵做变换。
然后通过mlp把每个点投影到64维的高维空间。

然后在64维中再做一个高维空间的变换,把他变换到更归一化的64维空间。
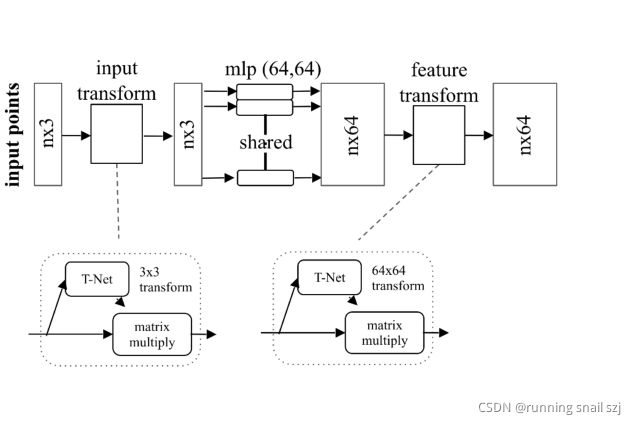
然后我们继续做mlp,把这64维继续映射到1024维。

在这1024维中我们可以做对称性的操作,就是有最大化池化max pool来实现,得到一个global feature全局特征,有1024维。

全局特征继续处理,我们可以通过级联的全连接网络,最后生成k个output scores,针对k的class,进行k的class分类。

以上就是对点云的分类网络。那如何做对点云的分割呢?
分割可以理解为对每个点的分类问题,如果我们知道每个点的分类,就可以对这个点进行固定类别的分割。通过全局坐标没法对每个点分割,我们可以把单个点的特征和全局坐标结合起来实现分割的功能。
最简单的做法,我们可以把全局的特征进行进行重复n遍,每一个和原来单个点的特征连接在一起,相当于单个点在全局特征中进行一次检索,他单个点在全局特征中看自己处于哪一个位置,就可以判断单个点属于哪一个类。

对每一个连接起来的特征做mlp的变换
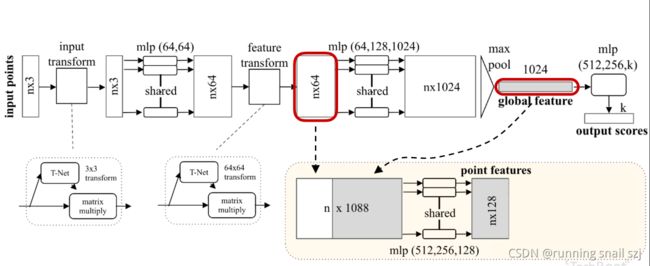
最后把每个点分类成m类,相当于输出m个scores

以上为一个分割网络。
Results on Object Classification
看一下上面网络的结果如何。
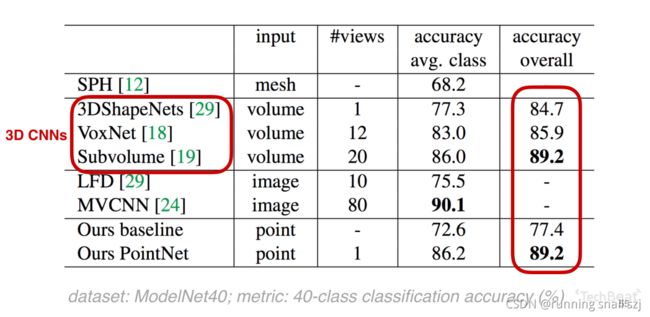
这是up主在点云深度学习中最早的一个工作,但是最早的工作和原来的3DCNN一些成熟的相比,在40个物体分类的问题上已经取得了很好的结果。
物体部件分割的可视化,左边为不全的物体Partial Inputs,右边为完整的物体Complete Inputs的分割,可以看到耳机可以分割成三个部分(线、架子、耳套)。

结果上也是明显好于原来的3DCNN

下面是场景分割的结果,第一行展示的是带有颜色的点云,虽然表示成图片,实际上是三维的点云。第二行显示的是网络分割的结果,可以分割成不同的区域,比如地面蓝色、墙壁淡蓝色、椅子红色。

PointNet不仅在理论上很有优异性,而且在实验室效果很好,而且是一个轻量快速高效的模型。和传统的基于多视角2DCNN、和基于3D栅格volumetricCNN的方法比,point能大幅提升空间利用效率和计算速度。和经典的volumetric相比可以剩下80%内存。
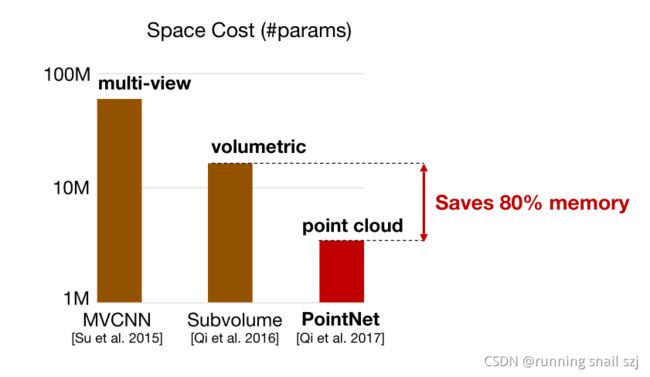
计算上也可以剩下88%的计算量,高效性可用于移动或可穿戴设备

同时对数据的丢失很鲁棒,在40分类的问题上,我们看到有50%的点丢失时,pointnet分类精度仅有2%的影响。

为什么PointNet对于数据的丢失这么鲁棒呢?
我们可以通过一个可视化去理解:
第一行为原始的点云输入,我们有一个最大池化的操作,实际上有些点的特征非常小,经过maxpool后他对全局特征没做任何贡献。
其中只有一些Critcal Point关键点展示出几何骨骼的轮廓,这些点保存就可以分类正确,即第二行的点。
所以PointNet对数据的丢失很鲁棒。
