机器学习基础算法笔记(一)——梯度下降算法(以housing数据集为例)
简述机器学习基础算法(一)——梯度下降算法(以housing数据集为例)
-
- 问题是从哪来的
- 过程综述
- 核心思想
- 数据的预处理
- 正则化
- 随机梯度下降
- 实现代码
问题是从哪来的
生活中,很多事情是有因果关系的,比如房价受地段,小区绿化程度,周围学校好坏等因素影响;一杯果汁的价格可能受水果的种类,果汁的含量影响;再比如一个男性的魅力值或许受身高,财产,身材,年龄,学历等因素影响。我们在进化的过程中总是想总结出更多的因果关系,定性的相关性是比较好发现的,可是我们更希望得到一个定量的结果,这样才是有实际意义和价值的东西。
好了,现在问题转化成了想求得一个函数 y = f ( x ) y=f(x) y=f(x),其中y代表的是我们最终想得道的值,也就是上面所说的房价,果汁的价格,其中的x代表的则是影响因素的集合。
我们为了说明的方便,用一个具体的数据集,这里用的是housing数据集
housing.data 包含506个训练样本
该数据集包含 13 个不同的特征:
1.人均犯罪率。
2.占地面积超过 25000 平方英尺的住宅用地所占的比例。
3.非零售商业用地所占的比例(英亩/城镇)。
4.查尔斯河虚拟变量(如果大片土地都临近查尔斯河,则为 1;否则为 0)。
5.一氧化氮浓度(以千万分之一为单位)。
6.每栋住宅的平均房间数。
7.1940 年以前建造的自住房所占比例。
8.到 5 个波士顿就业中心的加权距离。
9.辐射式高速公路的可达性系数。
10.每 10000 美元的全额房产税率。
11.生师比(按城镇统计)。
12.1000 * (Bk - 0.63) ** 2,其中 Bk 是黑人所占的比例(按城镇统计)。
13.较低经济阶层人口所占百分比
14.房价
1~13也就是特征也就是X,14是最终结果也就是Y
过程综述
我们的任务就是用一个我们自己定义的函数 f ( x ) f(x) f(x)去接近真实的函数 g ( x ) g(x) g(x),真实的函数是什么没人知道,像这种经典数据集,使用什么样的函数去拟合是已知的,但是在实际应用中使用什么样的函数来拟合是需要测试的。
我们的目标是让 f ( x ) f(x) f(x)去接近 g ( x ) g(x) g(x),换一种表达方式也就是让 ∣ f ( x ) − g ( x ) ∣ |f(x)-g(x)| ∣f(x)−g(x)∣尽可能的小,如果两个函数的差值小,也就是意味着他们接近了。不过我们手上有的不是 g ( x ) g(x) g(x)而是 g ( x ) g(x) g(x)上的若干个点,即训练集中的点,这些点都是真实存在的数据,是真实函数上的点。解决问题的一个办法是转而求解另一个函数,比如 M i n ( ∑ i = 0 N ∣ f ( x i ) − g ( x i ) ∣ ) Min(\sum_{i=0}^{N}|f(x_i)-g(x_i)|) Min(∑i=0N∣f(xi)−g(xi)∣) (N代表样本的数量)。这个函数也就是损失函数,当然,上面的不是最终的损失函数,它有很多计算层面上的问题和不方便,不过我们也知道了需要一个损失函数来告诉我们现在的接近程度。我们需要求解损失函数的最小值,这个过程需要使用梯度下降算法。当求得最小值时,其对应的 f ( x ) f(x) f(x)即是我们的最终结果。
核心思想
梯度下降是求解函数极值的方法,整个过程就是一个下山的过程(如下图),站在山顶上找最陡峭的地方向下一步步走(因为陡峭的地方下的快),直到你下一步前进的时候发现自己在上升,就知道刚刚自己已经到达山脚(最低点)了。显然,梯度下降找到一个极值点就会停止,这个极值点不一定是全局的最大值最小值。
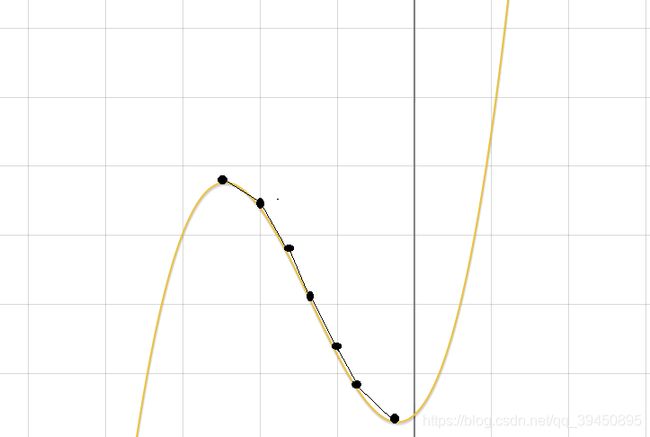
对于梯度下降算法,我们需要定义一些变量:
- 步长:步长决定了在梯度下降迭代的过程中,每一步沿梯度负方向前进的长度。
- 特征:指的是样本中输入部分,即数据集中的特征值。数据集中的特征值是一个包含13个特征的向量,定义为X={ x 1 , x 2 , . . . , x 13 x_1,x_2,...,x_{13 } x1,x2,...,x13}
- 假设函数:在监督学习中,为了拟合输入样本,而使用的假设函数,记为h_θ (x)。对于该数据集,特征数为13,样本数为506的样本 ( x j i , y j ) (x^i_j,y_j) (xji,yj)(j=1,2,…506)(i=1,2…13)。实验中选取的拟合函数为一次函数即 h θ ( x ) = θ 0 + θ 1 ∗ x 1 + ⋯ + θ 13 ∗ x 13 h_θ (x)=θ_0+θ_1*x_1+⋯+θ_{13}*x_{13} hθ(x)=θ0+θ1∗x1+⋯+θ13∗x13
- 代价函数:为了评估模型拟合的好坏,通常用损失函数来度量拟合的程度。损失函数极小化,意味着拟合程度最好,对应的模型参数即为最优参数。在线性回归中,损失函数通常为样本输出和假设函数的差取平方。比如对于m个样本 ( x j i , y j ) (x^i_j,y_j) (xji,yj)(i=1,2,…13;j=1,2,…,m),采用线性回归,损失函数为:
J ( θ 0 , θ 1 , . . . , θ 13 ) J(θ_0,θ_1,...,θ_{13}) J(θ0,θ1,...,θ13) = 1 2 m ∑ i = 1 m ( h θ ( x i ) − y i ) 2 \frac{1}{2m}\sum_{i=1}^m(h_θ(x^{i})-y^i)^2 2m1∑i=1m(hθ(xi)−yi)2
其中x_^((i) )表示第i个样本特征,y^((i) )表示第i个样本对应的输出,h_θ (x_^((i) ) )为假设函数。
参数的变化为:
{ θ 0 = θ 0 − α 1 m ∑ i = 1 m ( h θ ( x i ) − y i ) θ 1 = θ 1 − α 1 m ∑ i = 1 m ( h θ ( x i ) − y i ) x 1 i θ j = θ 1 − α 1 m ∑ i = 1 m ( h θ ( x i ) − y i ) x j i \left\{ \begin{aligned} θ_0 & =θ_0- \alpha\frac{1}{m}\sum_{i=1}^m(h_θ(x^{i})-y^i) \\ θ_1 & =θ_1-\alpha\frac{1}{m}\sum_{i=1}^m(h_θ(x^{i})-y^i)x^i_1 \\ θ_j & =θ_1-\alpha\frac{1}{m}\sum_{i=1}^m(h_θ(x^{i})-y^i)x^i_j \end{aligned} \right. ⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧θ0θ1θj=θ0−αm1i=1∑m(hθ(xi)−yi)=θ1−αm1i=1∑m(hθ(xi)−yi)x1i=θ1−αm1i=1∑m(hθ(xi)−yi)xji
参数的变化是怎么得到的?
首先梯度就是表示某一函数在该点处的方向导数沿着该方向取得较大值,即函数在当前位置的导数。
参数的变化应该是 θ j = θ j − α ∂ J ( θ 1 , θ 2 , . . . , θ 13 ) ∂ θ j θ_j=θ_j-\alpha\frac{\partial J(θ_1,θ_2,...,θ_{13})}{\partial θ_j} θj=θj−α∂θj∂J(θ1,θ2,...,θ13)
其中 α \alpha α表示学习率,即控制每次下降的快慢
数据的预处理
在看了吴恩达老师的机器学习课程视频学习到的东西,由于这个数据集刚好也存在同样的问题,即不同特征值的取值范围差异十分大,可能会导致梯度下降时收敛速度过慢。
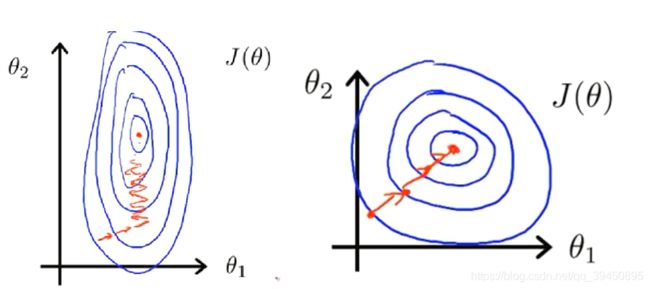
在有两个特征值 θ 1 , θ 2 θ_1,θ_2 θ1,θ2的情况下,如果两个特征值的取值范围近似则会有较高的收敛速度,相反如果差距较为悬殊,会导致收敛速度过慢,如上图所示,所以需要进行特征缩放。
目标是将所有的特征值都限制在[-1,1]的范围内,求出每一列特征值的平均值 X ‾ \overline{X} X,最大值 X m a x X_{max} Xmax
对每一个特征值 X i j X_{ij} Xij(i表示行,j表示列),进行计算 X i j ′ = ( X i j − X ‾ ) X m a x X_{ij}'=\frac{(X_{ij} -\overline{X} )}{X_{max}} Xij′=Xmax(Xij−X)得到新的特征值,特征值会出现负数,后续的计算需要使用到绝对值。
正则化
需要正则化的原因是为了防止过拟合,可能是参数数量过多,导致过度拟合各个点,而失去了预测的准确性,所以需要添加一个正则系数。
在代价函数的后面加入L2正则项 λ ∑ i = 1 m θ j 2 λ\sum_{i=1}^mθ_j^2 λ∑i=1mθj2 ,将新的代价函数带入参数更新函数中,化简得到新的更新函数
θ j = θ j ( 1 − α λ m ) − α 1 m ∑ i = 1 m ( h θ x i − y i ) x j i θ_j=θ_j (1-α \frac{λ}{m})-α \frac{1}{m} \sum_{i=1}^m(h_θ x^i-y^i) x_j^i θj=θj(1−αmλ)−αm1∑i=1m(hθxi−yi)xji
其中λ就是正则系数
正则化不止能防止过拟合,还能一定程度上加快收敛的速度
随机梯度下降
随机梯度下降与梯度下降不同的是,他不是算所有数据的代价,而是选取其中一行数据进行计算。可以预见的是,它的收敛速度会比梯度下降要快,因为它不用顾虑所有的数据,相应的它的结果肯定也不如梯度下降好,下降的效果也是在不断地波动中,因为是随机选取的所以效果不确定。他的更新参数为:
θ j = θ j − α ( h θ x i − y i ) x j i θ_j=θ_j-α(h_θ x^i -y^i)x_j^i θj=θj−α(hθxi−yi)xji
其中 i ∈ [ 0 … m ] i∈[0…m] i∈[0…m],且为随机选取的, j ∈ [ 0 … n ] j∈[0…n] j∈[0…n]n为参数的数量
实现代码
包括梯度下降源程序和留一法测试,使用RMSE作为评价标准
梯度下降
import sys
import copy
from numpy import *
import numpy as np
import matplotlib.pyplot as plt
f = open("housing.data", "r")
Data = f.readlines()
'''
处理数据,先对数据进行分割,并转换成float型变量
为了之后梯度下降的过程中减少消耗,进行特征缩放
获取平均值,与最大值:
平均值分别为
3.61352356, 11.36363636, 11.13677866, 0.06916996, 0.55469506, 6.28463439, 68.57490119, 3.79504269, 9.54940711, 408.23715415, 18.4555336, 356.67403162, 12.65306324
最大值分别为
88.9762, 100, 27.74, 1, 0.871, 8.78, 100, 12.1265, 24, 711, 22, 369.9, 37.97
大概的范围选择在-1~1
定义初始的参数向量为全 1
'''
for i in range(506):
Data[i] = Data[i].rstrip('\n')
Data[i] = Data[i].split()
for j in range(13):
Data[i][j] = float(Data[i][j])
Data = np.mat(Data)
Data = Data.astype("float64")
Average = Data.sum(axis=0)/506
Max = Data.max(axis=0)
#为了保证特征值范围进行调整
for i in range(14):
Data[:, i] = (Data[:, i]-Average[0,i])/Max[0, i]
#梯度
Alpha = 0.01
#特征值向量
Feature = Data[:,0:13]
#结果向量
Result = Data[:,13]
#创建参数向量,为一个1*13的矩阵
Parameter = mat(ones((13,1)))
intercept = 0 #截距
Sub_value = sys.maxsize
count = 0
debugging = [0 for i in range(11)]
debugging_1 = [i for i in range(11)]
IsEnd = False
''''
#通过转置完成计算
Parameter = np.transpose(Parameter)
#计算结果
Feature = Feature*Parameter
Result = abs(Result - Feature)
print(Result)
进行梯度下降,定义代价函数,操作全局变量判断是否结果更加优化
'''
def Steepest_Descent(Feature_1,Result_1,x):
global Parameter,Alpha,Sub_value,IsEnd,intercept,count
Feature_temp = copy(Feature_1) #防止特征向量被修改
Forecast = Feature_temp*Parameter #预测结果
Forecast = Forecast - Result_1 #差值
#print(Forecast)
Value_mat = abs(Forecast)
Value = Value_mat.sum(axis=0)
#debugging[count] = Value[0,0]
count = count + 1
'''
#计算限度
if count==20000 or count==30000 or count==79000:
print(Value)
#print("Feature_temp",Feature_temp.shape)
Forecast:506*1
Feature_temp:506*13
Parameter:13*1
'''
#print(Value)
if Value[0,0]<Sub_value:
Sub_value = Value[0,0]
else:
print(Value[0, 0])
IsEnd = True
return
Delta = mat(ones((13,1)))
#计算变化量
for i in range(13):
#temp = mat(ones((506,1)))
temp = Feature_temp[:, i] #因为要*Xij
np.transpose(Forecast)
temp_1 = temp*Forecast
Delta[i,0] = temp_1[0,0]/x
#更新系数
Parameter = Parameter*0.9 - Alpha*Delta
intercept = intercept -Alpha*Forecast.sum(axis=0)[0,0]/x
#print("Parameter's shape:",Parameter.shape)
if __name__=="__main__":
RootError = 0
'''
留一法测试的内容
for n in range(506):
Feature_left = copy(Feature)
Result_left = copy(Result)
delete(Feature_left,n,axis=0)
delete(Result_left,n,axis=0)
for i in range(30000):
Steepest_Descent(Feature_left,Result_left,505)
temp = Feature[n,:] #取出这一行当做测试数据
temp = temp*Parameter
RootError = RootError +abs(temp[0,0]-Data[n,13])
#初始化
Parameter = mat(ones((13, 1)))
Sub_value = sys.maxsize
IsEnd = False
intercept = 0
RootError = RootError / 506
IsEnd = False
#整体再算一遍
'''
while not IsEnd:
Steepest_Descent(Feature,Result,506)
print("总次数",count)
print("参数向量为",Parameter)
#print("常数项为",intercept)
print("留一法得到RMSE为",RootError)
plt.figure()
plt.scatter(debugging_1, debugging, color="b")
plt.xlabel('x')
plt.ylabel('y')
plt.show()
随机梯度下降
import sys
import copy
from numpy import *
import numpy as np
import matplotlib.pyplot as plt
f = open("housing.data", "r")
Data = f.readlines()
for i in range(506):
Data[i] = Data[i].rstrip('\n')
Data[i] = Data[i].split()
for j in range(13):
Data[i][j] = float(Data[i][j])
Data = np.mat(Data)
Data = Data.astype("float64")
Average = Data.sum(axis=0) / 506
Max = Data.max(axis=0)
# 为了保证特征值范围进行调整
for i in range(14):
Data[:, i] = (Data[:, i] - Average[0, i]) / Max[0, i]
# 梯度
Alpha = 0.01
# 特征值向量
Feature = Data[:, 0:13]
# 结果向量
Result = Data[:, 13]
# 创建参数向量,为一个1*13的矩阵
Parameter = mat(ones((13, 1)))
intercept = 0 # 截距
Sub_value = sys.maxsize
count = 0
debugging = [0 for i in range(80000)]
debugging_1 = [i for i in range(80000)]
IsEnd = False
def Steepest_Descent(Feature_1, Result_1, x):
global Parameter, Alpha, Sub_value, IsEnd, intercept, count
Random_value = random.randint(0,506)
Feature_temp = copy(Feature_1[Random_value,:]) #随机选取一行数据
Result_temp = copy(Result_1[Random_value,:])
Forecast = Feature_temp * Parameter # 预测结果
Forecast = Forecast - Result_temp # 差值
Value = abs(Forecast.sum(axis=0)) #误差
debugging[count] = Value[0,0]
count = count + 1
'''
曾经试过的收敛方式的判断
rotio = abs(Value[0,0]/Result_temp[0,0])
# print(Value)
if rotio<0.05:
# Sub_value = Value[0, 0]
count = count + 1
if count>10:
print(Sub_value)
IsEnd = True
return
'''
Delta = mat(ones((13, 1)))
# 计算变化量
for i in range(13):
# temp = mat(ones((506,1)))
temp = Feature_temp[:, i] # 因为要*Xij
np.transpose(Forecast)
temp_1 = temp * Forecast
Delta[i, 0] = temp_1[0, 0]
# 更新系数
Parameter = Parameter - Alpha * Delta
# print("Parameter's shape:",Parameter.shape)
if __name__ == "__main__":
RootError = 0
for i in range(80000):
Steepest_Descent(Feature, Result, 506)
print(len(debugging))
plt.figure()
plt.scatter(debugging_1, debugging, color="b")
plt.xlabel('x')
plt.ylabel('y')
plt.show()
print("总次数", count)
print("参数向量为", Parameter)
# print("常数项为",intercept)
print("留一法得到RMSE为", RootError)