使用ResNet模型进行无线电调制识别
一、前言
传统的无线电调制识别方法通常是计算无线电信号的各种特征,如高阶矩,通过构建一棵分类树,对比不同的调制类型特点,最终将信号分类。这种方法实现复杂,需要极强的专业知识。深度学习的大热将神经网络模型带入无线电通讯领域,如图1所示,不同的调制类型产生的IQ信号在时域上表现出不同的形状特征,类似于图像中的分类任务,研究者们发现使用神经网络模型也能很好地完成无线电调制类型分类,且效果要比传统方法还好。
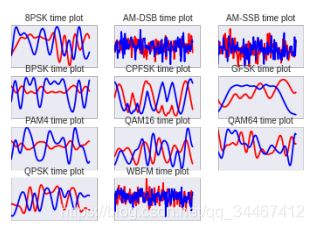 图1 不同调制类型的IQ时域信号图
图1 不同调制类型的IQ时域信号图
这篇文章主要基于Tim O’Shea的两篇论文:
① Convolutional Radio Modulation Recognition Networks
② Over the Air Deep Learning Based Radio Signal Classification
论文①提出了进行无线电信号分类的卷积神经网络模型,公开了训练的模型和代码,并发布了一个用于深度学习的无线电信号仿真数据集和数据集生成脚本,这个公开数据集后来被广泛地使用于相关的使用深度学习方法进行调制识别的研究中。
论文②提出了深层的残差网络模型进行调制分类,效果较论文①有很大的提升,在②中还做了大量的超参对比试验,且使用了新的数据集。
二、用于调制识别的卷积神经网络模型(论文一)
Convolutional Radio Modulation Recognition Networks这篇论文是较早使用深度学习技术进行调制识别的研究之一,且取得了相当可观的识别效果,该论文主要有两个成果:
1、仿真数据集
论文中提出了一个高质量的无线电型信号仿真数据集,数据集基于GNU Radio环境生成,相关链接:RML2016.10a.tar.bz2和数据集生成脚本。
数据集中共包含如图1所示的11类调制信号,每种调制包含20种信噪比,每种信噪比有1000个样本,每个样本有I和Q两路信号,每路信号包含128个点,所以数据集大小为:220000×2×128。
2、卷积神经网络模型
作者提出了如图2所示的卷积神经网络模型,在论文中被称为CNN模型,包含两个卷积层和两个全连接层。此外,作者还通过增加卷积层的卷积核数量,构建了CNN2模型,CNN2模型结构与CNN模型相同,只是两个卷积层的卷积核数量分别增加为256和80,第一个全连接层神经元个数增加为256个,CNN2的源码已经公开,因此不再追究其中的细节,需要的自己看代码更加清楚,源码地址:RML2016.10a_VTCNN2_example.ipynb
 图2 调制识别卷积神经网络模型
图2 调制识别卷积神经网络模型
值得注意的是,作者在代码中首先将2×128的数据reshape成1×2×128,对应图像中的channel×width×height,可见是将IQ数据看成单通道的2×128大小的图像数据进行处理。由于公开的数据集只有22w条数据,数据量相对来说较小,因此训练完成后的模型分类准确率也只有73%左右,测试集分类准确率如图3所示。
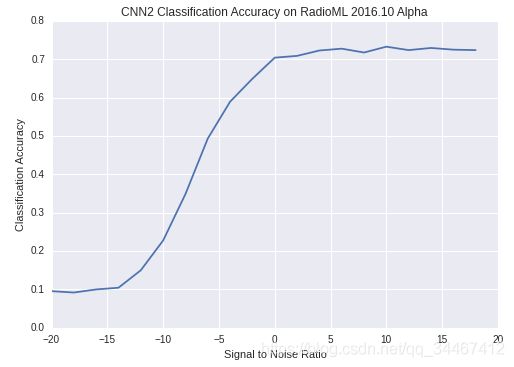 图3 CNN2模型测试集准确率随snr变化图
图3 CNN2模型测试集准确率随snr变化图
作者在论文中指出,增加数据集的大小会使准确率进一步上升,在使用1200万的数据集进行训练和测试后,模型能够达到87.4%的准确率,有硬件条件的大佬可以试试。至此,论文①中的内容大概介绍完毕。
三、用于调制识别的深度残差网络模型(论文二)
论文二的主要内容有:提出新的数据集,提出调制识别深度残差网络,对比不同超参数下模型的性能,在真实数据上测试模型效果并提出使用迁移学习优化模型在真实数据上的表现。
1、数据集
作者在论文二中使用了新的数据集,相对于之前的数据集,这个数据集包含24种调制,每种调制包含26种信噪比,每种信噪比下包含4096条数据,每条数据包含IQ两路信号,每路信号包含1024个点,所以新数据集的大小变为:2555904×1024×2(不是2555904×2×1024,其实两者没有区别,只是作者公开的数据集就是这个维度),新的数据集大小高达20G。
数据集:2018.01.OSC.0001_1024x2M.h5.tar.gz
2、残差网络模型
作者提出了用于调制识别的残差神经网络模型,模型的结构如图4所示,其中Residual Unit就是我们熟悉的残差网络中的残差块,在残差块的基础上,作者构建了Residual Stack单元,每个Residual Stack包括一个卷积核大小为1×1的卷积层,用于在channel维度上做计算,此外还包含两个残差块,以及一个Max Pooling层。在整个模型中又包含6个Residual Stack单元,数据每经过一个Residual Stack单元维度减半。模型中所有卷积层的卷积核数量均为32,而卷积核大小则并未说明。
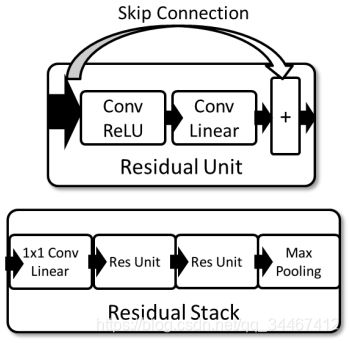
 图4 残差网络模型结构图
图4 残差网络模型结构图
使用Keras实现上述模型,代码如下:
"""建立模型"""
classes = ['32PSK',
'16APSK',
'32QAM',
'FM',
'GMSK',
'32APSK',
'OQPSK',
'8ASK',
'BPSK',
'8PSK',
'AM-SSB-SC',
'4ASK',
'16PSK',
'64APSK',
'128QAM',
'128APSK',
'AM-DSB-SC',
'AM-SSB-WC',
'64QAM',
'QPSK',
'256QAM',
'AM-DSB-WC',
'OOK',
'16QAM']
data_format = 'channels_first'
def residual_stack(Xm,kennel_size,Seq,pool_size):
#1*1 Conv Linear
Xm = Conv2D(32, (1, 1), padding='same', name=Seq+"_conv1", kernel_initializer='glorot_normal',data_format=data_format)(Xm)
#Residual Unit 1
Xm_shortcut = Xm
Xm = Conv2D(32, kennel_size, padding='same',activation="relu",name=Seq+"_conv2", kernel_initializer='glorot_normal',data_format=data_format)(Xm)
Xm = Conv2D(32, kennel_size, padding='same', name=Seq+"_conv3", kernel_initializer='glorot_normal',data_format=data_format)(Xm)
Xm = layers.add([Xm,Xm_shortcut])
Xm = Activation("relu")(Xm)
#Residual Unit 2
Xm_shortcut = Xm
Xm = Conv2D(32, kennel_size, padding='same',activation="relu",name=Seq+"_conv4", kernel_initializer='glorot_normal',data_format=data_format)(Xm)
X = Conv2D(32, kennel_size, padding='same', name=Seq+"_conv5", kernel_initializer='glorot_normal',data_format=data_format)(Xm)
Xm = layers.add([Xm,Xm_shortcut])
Xm = Activation("relu")(Xm)
#MaxPooling
Xm = MaxPooling2D(pool_size=pool_size, strides=pool_size, padding='valid', data_format=data_format)(Xm)
return Xm
in_shp = X_train.shape[1:] #每个样本的维度[1024,2]
#input layer
Xm_input = Input(in_shp)
Xm = Reshape([1,1024,2], input_shape=in_shp)(Xm_input)
#Residual Srack
Xm = residual_stack(Xm,kennel_size=(3,2),Seq="ReStk0",pool_size=(2,2)) #shape:(512,1,32)
Xm = residual_stack(Xm,kennel_size=(3,1),Seq="ReStk1",pool_size=(2,1)) #shape:(256,1,32)
Xm = residual_stack(Xm,kennel_size=(3,1),Seq="ReStk2",pool_size=(2,1)) #shape:(128,1,32)
Xm = residual_stack(Xm,kennel_size=(3,1),Seq="ReStk3",pool_size=(2,1)) #shape:(64,1,32)
Xm = residual_stack(Xm,kennel_size=(3,1),Seq="ReStk4",pool_size=(2,1)) #shape:(32,1,32)
Xm = residual_stack(Xm,kennel_size=(3,1),Seq="ReStk5",pool_size=(2,1)) #shape:(16,1,32)
#############################################################################
# 多次尝试发现减少一层全连接层能使loss下降更快
# 将AlphaDropout设置为0.3似乎比0.5效果更好
#############################################################################
#Full Con 1
Xm = Flatten(data_format=data_format)(Xm)
Xm = Dense(128, activation='selu', kernel_initializer='glorot_normal', name="dense1")(Xm)
Xm = AlphaDropout(0.3)(Xm)
#Full Con 2
Xm = Dense(len(classes), kernel_initializer='glorot_normal', name="dense2")(Xm)
#SoftMax
Xm = Activation('softmax')(Xm)
#Create Model
model = Model.Model(inputs=Xm_input,outputs=Xm)
adam = keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False)
model.compile(loss='categorical_crossentropy', optimizer=adam)
model.summary()训练代码:
"""训练模型"""
#############################################################################
# 当val_loss连续10次迭代不再减小或总迭代次数大于100时停止
# 将最小验证损失的模型保存
#############################################################################
print(tf.test.gpu_device_name())
filepath = 'drive/RadioModulationRecognition/Models/ResNet_Model_72w.h5'
history = model.fit(X_train,
Y_train,
batch_size=1000,
epochs=100,
verbose=2,
validation_data=(X_test, Y_test),
#validation_split = 0.3,
callbacks = [
keras.callbacks.ModelCheckpoint(filepath, monitor='val_loss', verbose=0, save_best_only=True, mode='auto'),
keras.callbacks.EarlyStopping(monitor='val_loss', patience=10, verbose=0, mode='auto')
])
# we re-load the best weights once training is finished
model.load_weights(filepath)由于硬件限制,无法将250多万条的数据都拿来训练,所以我从完整数据集中按照分层抽样的规则抽取出部分数据(约74w条)组成训练集和测试集,并且与论文一中提供的代码一样使用3×2大小(或者2×3)的卷积核,训练完成后的模型在测试集上的分类准确率最高达到了94.3%,模型在测试集上的分类准确率随信噪比的变化如图5所示。而图6所示的是作者对比不同数据集大小所训练的模型效果图,可以看出,当数据量为72w时达到94.3%的准确率是符合预期的,如果使用完整数据集可以使准确率更高。源码已发布到github:ResNet-for-Radio-Recognition
 图5 模型分类准确率虽snr变化图
图5 模型分类准确率虽snr变化图
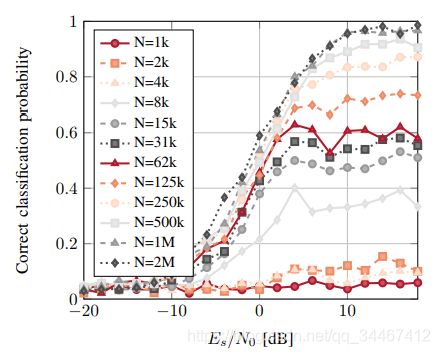 图6 不同数据集大小训练的模型表现对比图
图6 不同数据集大小训练的模型表现对比图
值得注意的是,论文中指出使用的ResNet模型包含23w个参数,而我在早期的代码中使用3*2的卷积核构建的模型同样有23w个可训练参数,依此来看,作者使用的卷积核大小应该是3*2。我在Colaboratory平台上训练模型,迭代一次需要488秒,整个训练下来花了7-8个小时,可以说是非常慢了。而我之后也进行了优化,减少了训练参数,也减少了大量的训练时间。
3. 自己的改进
之前提到的,使用神经网络对信号调制进行分类,就是借鉴了图像分类的思想。而一张图片的维度一般是width*height*channel,对应到无线电的IQ信号就是:1024*2*1,即将IQ信号数据看成是单个通道的1024*2大小的“图片”,1024*2的数据再经过一个2*2的max pooling后维度变为512*1,之后使用的应该时3*1大小的卷积核而非3*2(卷积核的维度不应该比数据还大),因此,我考虑将除了第一个residual_stack单元之外的其余residual_stack单元中卷积核设置为3*1大小,这样可以大大减少参数数量。
对比两种实现方式,作者指出论文中的模型拥有23w个参数,而改进后的模型只有14w个参数,迭代一次的时间从488s下降至171s,而准确率反而略有提升。两种实现代码分别是ResNet_Model.ipynb(改进前)和ResNet_incomplete_dataset.ipynb(改进后)。注意,ResNet_Model.ipynb只是早期对论文的粗略实现,仅模型部分有参考价值,主要代码还是见改进后的版本。
当然,上述的所谓“改进”纯粹主观想法,因为作者并未提供源代码,而“改进前”的模型也是博主自己构建,但从参数数量来看,14w的可训练参数量相对于23w的训练参数的确有很大下降,而且经过验证准确率也的确不受影响,说明改进和优化是有的,只是改进的量无法确定。
4、真实数据测试
博主使用过真实信号源和接收机测试过模型,的确模型是可用的,且高信噪比下准确率的确很高,这依归功于仿真数据集做得比较好,但是有一个致命的缺点!!!!准确率严重依赖信号源的参数!也就是说,模型只有在信号源设置成与生成仿真数据集相同参数的情况下才可用,但在非合作式通信情况下,不可能知道信号源参数,所以,尽管模型训练和测试效果很好,但是应用到真实通信环境是一个很大的问题。
再解释一下:不同的调制产生的信号其IQ数据会表现出不同的形状特征,神经网络模型通过这种不同的特征来识别调制方式,但致命的是,同一调制下不同调制参数也会产生不同的形状特征,如不同的调制深度、符号率等,所以当真实信号的调制参数与数据集的参数不一样时,模型就难以识别。下图表示两个不同的符号率产生的同一调制信号,从形状上来看,300ks/s的信号显得更为”密集“。目前我尚未找到彻底的解决办法,如有想法或思路的同僚还请告知。
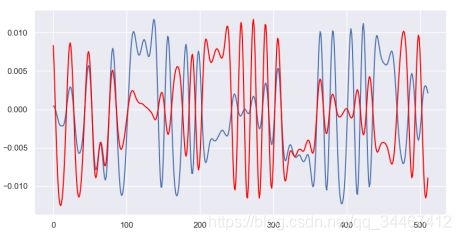 符号率为150kS/s时的IQ图
符号率为150kS/s时的IQ图
 符号率为300kS/s时的IQ图
符号率为300kS/s时的IQ图