面试题:说说你对泛型的理解?
面试考察点
考察目的:了解求职者对于Java基础知识的掌握程度。
考察范围:工作1-3年的Java程序员。
背景知识
Java中的泛型,是JDK5引入的一个新特性。
它主要提供的是编译时期类型的安全检测机制。这个机制允许程序在编译时检测到非法的类型,从而进行错误提示。
这样做的好处,一方面是告诉开发者当前方法接收或返回的参数类型,另一方面是避免程序运行时的类型转换错误。
泛型的设计推演
举一个比较简单的例子,首先我们来看一下ArrayList这个集合,部分代码定义如下。
public class ArrayList{
transient Object[] elementData; // non-private to simplify nested class access
}
在ArrayList中,存储元素所使用的结构是一个Object[]对象数组。意味着可以存储任何类型的数据。
当我们使用这个ArrayList来做下面这个操作时。
public class ArrayExample {
public static void main(String[] args) {
ArrayList al=new ArrayList();
al.add("Hello World");
al.add(1001);
String str=(String)al.get(1);
System.out.println(str);
}
}
运行程序后,会得到如下的执行结果
Exception in thread "main" java.lang.ClassCastException: java.lang.Integer cannot be cast to java.lang.String
at org.example.cl06.ArrayExample.main(ArrayExample.java:11)
这种类型转换错误,相信大家在开发中有遇到过,总的来说,在没有泛型的情况下,会有两个比较严重的问题
- 需要对类型进行强制转换
- 使用不方便,容易出错
怎么解决上面这个问题呢?要解决这个问题,就得思考这个问题背后的需求是什么?
我简单总结两点:
- 要能支持不同类型的数据存储
- 还需要保证存储数据类型的统一性
基于这两个点不难发现,对于一个数据容器中要存储什么类型的数据,其实是由开发者自己决定的。因此,为了解决这个问题,在JDK5中就引入了泛型的机制。
其定义形式是:ArrayList,它相当于给ArrayList提供了一个类型输入的模板E,E可以是任意类型的对象,它的定义方式如下。
public class ArrayList{
transient E[] elementData; // non-private to simplify nested class access
}
在ArrayList这个类的定义中,使用<>语法,并传入一个用来表示任意类型的对象E,这个E可以随便定义,你可以定义成A、B、C都可以。
接着,把用来存储元素的数组elementData的类型,设置为E类型。
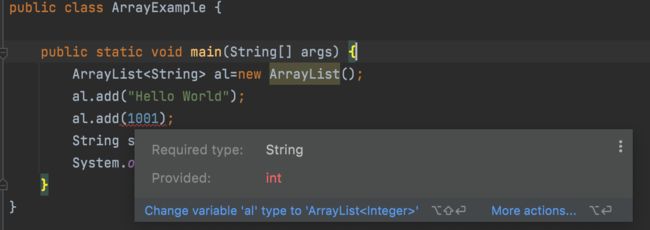
有了这个配置之后,ArrayList这个容器中,你想存储什么类型的数据,是由使用者自己决定,比如我希望ArrayList只存储String类型,那么它可以这么实现
public class ArrayExample {
public static void main(String[] args) {
ArrayList al=new ArrayList();
al.add("Hello World");
al.add(1001);
String str=(String)al.get(1);
System.out.println(str);
}
}
在定义ArrayList时,传入一个String类型,这样写意味着后续往ArrayList这个实例对象al中添加元素,必须是String类型,否则会提示如下的语法错误。
同理,如果需要保存其他类型的数据,可以这么写:
- ArrayList
- ArrayList
总结:所谓泛型定义,其实本质上就是一种类型模板,在实际开发中,我们把一个容器或者一个对象中需要保存的属性的类型,通过模板定义的方式,给到调用者来决定,从而保证了类型的安全性。
泛型的定义
泛型定义可以从两个维度来说明:
- 泛型类
- 泛型方法
泛型类
泛型类指的是在类名后面添加一个或多个类型参数,一个泛型参数,也被称为一个类型变量,是用于指定一个泛型类型名称的标识符。因为他们接受一个或多个参数,这些类被称为参数化的类或参数化的类型。
类型变量的表示标记,常用的是:E(element),T(type)、K(key),V(value),N(number)等,这只是一个表示符号,可以是任何字符,没有强制要求。
下面的代码是关于泛型类的定义。
该类接收一个T标记符的类型参数,该类中有一个成员变量,使用T类型。
public class Response {
private T data;
public T getData() {
return data;
}
public void setData(T data) {
this.data = data;
}
}
使用方式如下:
public static void main(String[] args) {
Response res=new Response<>();
res.setData("Hello World");
}
泛型方法
泛型方法是指指定方法级别的类型参数,这个方法在调用时可以接收不同的参数类型,根据传递给泛型方法的参数类型,编译器适当地处理每一个方法调用。
下面的代码表示泛型方法的定义,用到了JDK提供的反射机制,来生成动态代理类。
public interface IHelloWorld {
String say();
}
定义getProxy方法,它用来生成动态代理对象,但是传递的参数类型是T,也就是说,这个方法可以完成任意接口的动态代理实例的构建。
在这里,我们针对IHelloWorld这个接口,构建了动态代理实例,代码如下。
public class ArrayExample implements InvocationHandler {
public T getProxy(Class clazz){
// clazz 不是接口不能使用JDK动态代理
return (T) Proxy.newProxyInstance(clazz.getClassLoader(), new Class[]{ clazz }, ArrayExample.this);
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
return "Hello World";
}
public static void main(String[] args) {
IHelloWorld hw=new ArrayExample().getProxy(IHelloWorld.class);
System.out.println(hw.say());
}
}
运行结果:
Hello World
关于泛型方法的定义规则,简单总结如下:
- 所有泛型方法的定义,都有一个用
<>表示的类型参数声明,这个类型参数声明部分在方法返回类型之前。 - 每一个类型参数声明部分包含一个或多个类型参数,参数间用逗号隔开。一个泛型参数,也被称为一个类型变量,是用于指定一个泛型类型名称的标识符。
- 类型参数能被用来声明返回值类型,并且能作为泛型方法得到的实际参数类型的占位符
- 泛型方法体的声明和其他方法一样。注意类型参数只能代表引用型类型,不能是原始类型(像 int、double、char 等)。##
多类型变量定义
上在我们只定义了一个泛型变量T,那如果我们需要传进去多个泛型要怎么办呢?
我们可以这么写:
public class Response {
}
每一个参数声明符号代表一种类型。
注意,在多变量类型定义中,泛型变量最好是定义成能够简单理解具有含义的字符,否则类型太多,调用者比较容易搞混。
有界类型参数
在有些场景中,我们希望传递的参数类型属于某种类型范围,比如,一个操作数字的方法可能只希望接受Number或者Number子类的实例,怎么实现呢?
泛型通配符上边界
上边界,代表类型变量的范围有限,只能传入某种类型,或者它的子类。
我们可以在泛型参数上,增加一个extends关键字,表示该泛型参数类型,必须是派生自某个实现类,示例代码如下。
public class TypeExample {
private T t;
public T getT() {
return t;
}
public void setT(T t) {
this.t = t;
}
public static void main(String[] args) {
TypeExample t=new TypeExample<>();
}
}
上述代码,声明了一个泛型参数T,该泛型参数必须是继承Number这个类,表示后续实例化TypeExample时,传入的泛型类型应该是Number的子类。
所以,有了这个规则后,上面这个测试代码,会提示java: 类型参数java.lang.String不在类型变量T的范围内错误。
泛型通配符下边界
下边界,代表类型变量的范围有限,只能传入某种类型,或者它的父类。
我们可以在泛型参数上,增加一个super关键字,可以设定泛型通配符的上边界。实例代码如下。
public class TypeExample {
private T t;
public T getT() {
return t;
}
public void setT(T t) {
this.t = t;
}
public static void say(TypeExample te){
System.out.println("say: "+te.getT());
}
public static void main(String[] args) {
TypeExample te=new TypeExample<>();
TypeExample te2=new TypeExample<>();
say(te);
say(te2);
}
}
在say方法上声明TypeExample te,表示传入的TypeExample的泛型类型,必须是Number以及Number的父类类型。
在上述代码中,运行时会得到如下错误:
java: 不兼容的类型: org.example.cl06.TypeExample无法转换为org.example.cl06.TypeExample
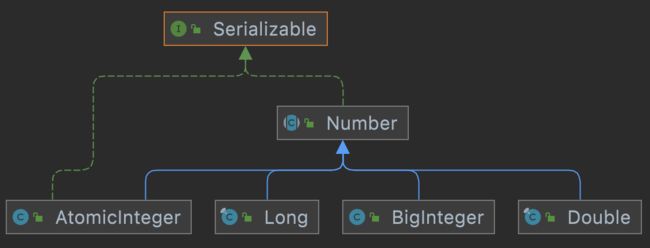
如下图所示,表示Number这个类的类关系图,通过super关键字限定后,只能传递Number以及父类Serializable。
类型通配符?
类型通配符一般是使用 ? 代替具体的类型参数。例如 List 在逻辑上是 List ,List 等所有 List<具体类型实参> 的父类。
来看下面这段代码的定义,在say方法中,接受一个TypeExample类型的参数,并且泛型类型是,代表接收任何类型的泛型类型参数。
public class TypeExample {
private T t;
public T getT() {
return t;
}
public void setT(T t) {
this.t = t;
}
public static void say(TypeExample te){
System.out.println("say: "+te.getT());
}
public static void main(String[] args) {
TypeExample te1=new TypeExample<>();
te1.setT(1111);
TypeExample te2=new TypeExample<>();
te2.setT("Hello World");
say(te1);
say(te2);
}
}
运行结果如下
say: 1111
say: Hello World
同样,类型通配符的参数,也可以通过extends来做限定,比如:
public class TypeExample {
private T t;
public T getT() {
return t;
}
public void setT(T t) {
this.t = t;
}
public static void say(TypeExample te){ //修改,增加extends
System.out.println("say: "+te.getT());
}
public static void main(String[] args) {
TypeExample te1=new TypeExample<>();
te1.setT(1111);
TypeExample te2=new TypeExample<>();
te2.setT("Hello World");
say(te1);
say(te2);
}
}
由于say方法中的参数TypeExample,在泛型类型定义中使用了,所以后续在传递参数时,泛型类型必须是Number的子类型。
因此上述代码运行时,会提示如下错误:
java: 不兼容的类型: org.example.cl06.TypeExample无法转换为org.example.cl06.TypeExample
注意: 构建泛型实例时,如果省略了泛型类型,则默认是通配符类型,意味着可以接受任意类型的参数。
泛型的继承
泛型类型参数的定义,是允许被继承的,比如下面这种写法。
表示子类SayResponse和父类Response使用同一种泛型类型。
public class SayResponse extends Response{
private T ox;
}
JVM是如何实现泛型的?
在JVM中,采用了类型擦除Type erasure generics)的方式来实现泛型,简单来说,就是泛型只存在.java源码文件中,一旦编译后就会把泛型擦除.
我们来看ArrayExample这个类,编译之后的字节指令。
public class ArrayExample implements InvocationHandler {
public T getProxy(Class clazz){
// clazz 不是接口不能使用JDK动态代理
return (T) Proxy.newProxyInstance(clazz.getClassLoader(), new Class[]{ clazz }, ArrayExample.this);
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
return "Hello World";
}
public static void main(String[] args) {
IHelloWorld hw=new ArrayExample().getProxy(IHelloWorld.class);
System.out.println(hw.say());
}
}
通过javap -v ArrayExample.class查看字节指令如下。
public T getProxy(java.lang.Class);
descriptor: (Ljava/lang/Class;)Ljava/lang/Object;
flags: ACC_PUBLIC
Code:
stack=5, locals=2, args_size=2
0: aload_1
1: invokevirtual #2 // Method java/lang/Class.getClassLoader:()Ljava/lang/ClassLoader;
可以看到,getProxy在编译之后,泛型T已经被擦除了,参数类型替换成了java.lang.Object.
并不是所有类型都会转换为java.lang.Object,比如如果是 ,则参数类型是java.lang.String。
同时,为了保证IHelloWorld hw=new ArrayExample().getProxy(IHelloWorld.class);这段代码的准确性,编译器还会在这里插入一个类型转换的机制。
下面这个代码是ArrayExample.class反编译之后的呈现。
IHelloWorld hw = (IHelloWorld)(new ArrayExample()).getProxy(IHelloWorld.class);
System.out.println(hw.say());
泛型类型擦除实现带来的缺陷
擦除方式实现泛型,还是会存在一些缺陷的,简单举几个案例说明。
不支持基本类型
由于泛型类型擦除后,变成了java.lang.Object类型,这种方式对于基本类型如int/long/float等八种基本类型来说,就比较麻烦,因为Java无法实现基本类型到Object类型的强制转换。
ArrayList list=new ArrayList();
如果这么写,会得到如下错误
java: 意外的类型
需要: 引用
找到: int
所以,在泛型定义中,只能使用引用类型。
但是作为引用类型,如果保存基本类型的数据时,又会涉及到装箱和拆箱的过程。比如
List list = new ArrayList();
list.add(10); // 1
int num = list.get(0); // 2
在上述代码中,声明了一个List泛型类型的集合,
在标记1的位置,添加了一个int类型的数字10,这个过程中,会涉及到装箱操作,也就是把基本类型int转换为Integer.
在标记2的位置,编译器首先要把Object转换为Integer类型,接着再进行拆箱,把Integer转换为int。因此上述代码等同于
List list = new ArrayList();
list.add(Integer.valueOf(10));
int num = ((Integer) list.get(0)).intValue();
增加了一些执行步骤,对于执行效率来说还是会有一些影响。
运行期间无法获取泛型实际类型
由于编译之后,泛型就被擦除,所以在代码运行期间,Java 虚拟机无法获取泛型的实际类型。
下面这段代码,从源码上两个 List 看起来是不同类型的集合,但是经过泛型擦除之后,集合都变为 ArrayList。所以 if语句中代码将会被执行。
public static void main(String[] args) {
ArrayList li = new ArrayList<>();
ArrayList lf = new ArrayList<>();
if (li.getClass() == lf.getClass()) { // 泛型擦除,两个 List 类型是一样的
System.out.println("类型相同");
}
}
运行结果:
类型相同
这就使得,我们在做方法重载时,无法根据泛型类型来定义重写方法。
也就是说下面这种方式无法实现重写。
public void say(List a){}
public void say(List b){}
另外还会给我们在实际使用中带来一些限制,比如说我们没办法直接实现以下代码
public void say(T a){
if(a instanceof T){
}
T t=new T();
}
上述代码会存在编译错误。
既然通过擦除的方式实现泛型有这么多缺陷,那为什么要这么设计呢?
要回答这个问题,需要知道泛型的历史,Java的泛型是在Jdk 1.5 引入的,在此之前Jdk中的容器类等都是用Object来保证框架的灵活性,然后在读取时强转。但是这样做有个很大的问题,那就是类型不安全,编译器不能帮我们提前发现类型转换错误,会将这个风险带到运行时。 引入泛型,也就是为解决类型不安全的问题,但是由于当时java已经被广泛使用,保证版本的向前兼容是必须的,所以为了兼容老版本jdk,泛型的设计者选择了基于擦除的实现。
问题解答
面试题:说说你对泛型的理解?
回答: 泛型是JDK5提供的一个新特性。它主要提供的是编译时期类型的安全检测机制。这个机制允许程序在编译时检测到非法的类型,从而进行错误提示。
问题总结
深入理解Java泛型是程序员最基础的必备技能,虽然面试很卷,但是实力仍然很重要。
关注[跟着Mic学架构]公众号,获取更多精品原创