目前手机SOC的性能越来越少,很多程序员在终端程序的开发过程中也不太注意性能方面的优化,尤其是不注意对齐和分支优化,但是这两种问题一旦出现所引发的问题,是非常非常隐蔽难查的,不过好在项目中用到了移动端的性能排查神器友盟U-APM工具的支持下,最终几个问题得到了圆满解决。
我们先来看对齐的问题,对齐在没有并发竞争的情况下不会有什么问题,编译器一般都会帮助程序员按照CPU字长进行对齐,但这在终端多线程同时工作的情况下可能会隐藏着巨大的性能问题,在多线程并发的情况下,即使没有共享变量,也可能会造成伪共享,由于具体的代码涉密,因此我们来看以下抽象后的代码。
public class Main {
public static void main(String[] args) {
final MyData data = new MyData();new Thread(new Runnable() {
public void run() {
data.add(0);
}
}).start();
new Thread(new Runnable() {
public void run() {
data.add(0);
}
}).start();
try{
Thread.sleep(100);
} catch (InterruptedException e){
e.printStackTrace();
}
long[][] arr=data.Getitem();
System.out.println("arr0 is "+arr[0]+"arr1 is"+arr[1]);
}}
class MyData {
private long[] arr={0,0};
public long[] Getitem(){
return arr;
}
public void add(int j){
for (;true;){
arr[j]++;
}
}
}
在这段代码中,两个子线程执行类似任务,分别操作arr数组当中的两个成员,由于两个子线程的操作对象分别是arr[0]和arr[1]并不存在交叉的问题,因此当时判断判断不会造成并发竞争问题,也没有加synchronized关键字。
但是这段程序却经常莫名的卡顿,后来经过多方的查找,并最终通过友盟的卡顿分析功能我们最终定位到了上述代码段,发现这是一个由于没有按照缓存行进行对齐而产生的问题,这里先将修改完成后的伪代码向大家说明一下:
public class Main {
public static void main(String[] args) {
final MyData data = new MyData();new Thread(new Runnable() {
public void run() {
data.add(0);
}
}).start();
new Thread(new Runnable() {
public void run() {
data.add(0);
}
}).start();
try{
Thread.sleep(10);
} catch (InterruptedException e){
e.printStackTrace();
}
long[][] arr=data.Getitem();
System.out.println("arr0 is "+arr0+"arr1 is"+arr1);
}}
class MyData {
private long[][] arr={{0,0,0,0,0,0,0,0,0},{0,0}};
public long[][] Getitem(){
return arr;
}
public void add(int j){
for (;true;){
arrj++;
}
}
}
可以看到整体程序没有作何变化,只是将原来的数组变成了二维数组,其中除了第一个数组中除arr0元素外,其余arr0-a0元素除完全不起作何与程序运行有关的作用,但就这么一个小小的改动,却带来了性能有了接近20%的大幅提升,如果并发更多的话提升幅度还会更加明显。
缓存行对齐排查分析过程
首先我们把之前代码的多线程改为单线程串行执行,结果发现效率与原始的代码一并没有差很多,这就让我基本确定了这是一个由伪共享引发的问题,但是我初始代码中并没有变量共享的问题,所以这基本可以判断是由于对齐惹的祸。
现代的CPU一般都不是按位进行内存访问,而是按照字长来访问内存,当CPU从内存或者磁盘中将读变量载入到寄存器时,每次操作的最小单位一般是取决于CPU的字长。比如8位字是1字节,那么至少由内存载入1字节也就是8位长的数据,再比如32位CPU每次就至少载入4字节数据, 64位系统8字节以此类推。那么以8位机为例咱们来看一下这个问题。假如变量1是个bool类型的变量,它占用1位空间,而变量2为byte类型占用8位空间,假如程序目前要访问变量2那么,第一次读取CPU会从开始的0x00位置读取8位,也就是将bool型的变量1与byte型变量2的高7位全部读入内存,但是byte变量的最低位却没有被读进来,还需要第二次的读取才能把完整的变量2读入。
也就是说变量的存储应该按照CPU的字长进行对齐,当访问的变量长度不足CPU字长的整数倍时,需要对变量的长度进行补齐。这样才能提升CPU与内存间的访问效率,避免额外的内存读取操作。但在对齐方面绝大多数编译器都做得很好,在缺省情况下,C编译器为每一个变量或是数据单元按其自然对界条件分配空间边界。也可以通过pragma pack(n)调用来改变缺省的对界条件指令,调用后C编译器将按照pack(n)中指定的n来进行n个字节的对齐,这其实也对应着汇编语言中的.align。那么为什么还会有伪共享的对齐问题呢?
现代CPU中除了按字长对齐还需要按照缓存行对齐才能避免并发环境的竞争,目前主流ARM核移动SOC的缓存行大小是64byte,因为每个CPU都配备了自己独享的一级高速缓存,一级高速缓存基本是寄存器的速度,每次内存访问CPU除了将要访问的内存地址读取之外,还会将前后处于64byte的数据一同读取到高速缓存中,而如果两个变量被放在了同一个缓存行,那么即使不同CPU核心在分别操作这两个独立变量,而在实际场景中CPU核心实际也是在操作同一缓存行,这也是造成这个性能问题的原因。
Switch的坑
但是处理了这个对齐的问题之后,我们的程序虽然在绝大多数情况下的性能都不错,但是还是会有卡顿的情况,结果发现这是一个由于Switch分支引发的问题。
switch是一种我们在java、c等语言编程时经常用到的分支处理结构,主要的作用就是判断变量的取值并将程序代码送入不同的分支,这种设计在当时的环境下非常的精妙,但是在当前最新的移动SOC环境下运行,却会带来很多意想不到的坑。
出于涉与之前密的原因一样,真实的代码不能公开,我们先来看以下这段代码:
public class Main {
public static void main(String[] args) {
long now=System.currentTimeMillis(); int max=100,min=0;
long a=0;
long b=0;
long c=0;
for(int j=0;j<10000000;j++){
int ran=(int)(Math.random()*(max-min)+min);
switch(ran){
case 0:
a++;
break;
case 1:
a++;
break;
default:
c++;
}
}
long diff=System.currentTimeMillis()-now;
System.out.println("a is "+a+"b is "+b+"c is "+c);
}}
其中随机数其实是一个rpc远程调用的返回,但是这段代码总是莫名其妙的卡顿,为了复现这个卡顿,定位到这个代码段也是通过友盟U-APM的卡顿分析找到的,想复现这个卡顿只需要我们再稍微把max范围由调整为5。
public class Main {
public static void main(String[] args) {
long now=System.currentTimeMillis(); int max=5,min=0;
long a=0;
long b=0;
long c=0;
for(int j=0;j<10000000;j++){
int ran=(int)(Math.random()*(max-min)+min);
switch(ran){
case 0:
a++;
break;
case 1:
a++;
break;
default:
c++;
}
}
long diff=System.currentTimeMillis()-now;
System.out.println("a is "+a+"b is "+b+"c is "+c);
}}
那么运行时间就会有30%的下降,不过从我们分析的情况来看,代码一平均每个随机数有97%的概念要行2次判断才能跳转到最终的分支,总体的判断语句执行期望为20.97+10.03约等于2,而代码二有30%的概念只需要1次判断就可以跳转到最终分支,总体的判断执行期望也就是0.31+0.62=1.5,但是代码二却反比代码一还慢30%。也就是说在代码逻辑完全没变只是返回值范围的概率密度做一下调整,就会使程序的运行效率大大下降,要解释这个问题要从指令流水线说起。
指令流水线原理
我们知道CPU的每个动作都需要用晶体震荡而触发,以加法ADD指令为例,想完成这个执行指令需要取指、译码、取操作数、执行以及取操作结果等若干步骤,而每个步骤都需要一次晶体震荡才能推进,因此在流水线技术出现之前执行一条指令至少需要5到6次晶体震荡周期才能完成

为了缩短指令执行的晶体震荡周期,芯片设计人员参考了工厂流水线机制的提出了指令流水线的想法,由于取指、译码这些模块其实在芯片内部都是独立的,完成可以在同一时刻并发执行,那么只要将多条指令的不同步骤放在同一时刻执行,比如指令1取指,指令2译码,指令3取操作数等等,就可以大幅提高CPU执行效率:

以上图流水线为例 ,在T5时刻之前指令流水线以每周期一条的速度不断建立,在T5时代以后每个震荡周期,都可以有一条指令取结果,平均每条指令就只需要一个震荡周期就可以完成。这种流水线设计也就大幅提升了CPU的运算速度。
但是CPU流水线高度依赖指指令预测技术,假如在流水线上指令5本是不该执行的,但却在T6时刻已经拿到指令1的结果时才发现这个预测失败,那么指令5在流水线上将会化为无效的气泡,如果指令6到8全部和指令5有强关联而一并失效的话,那么整个流水线都需要重新建立。
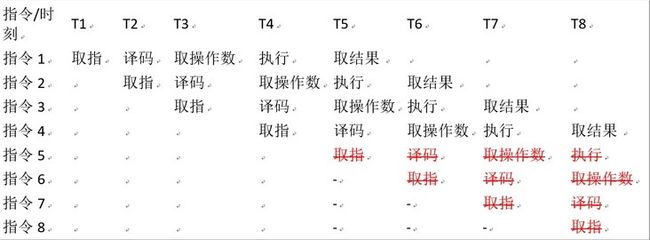
所以可以看出例子当中的这个效率差完全是CPU指令预测造成的,也就是说CPU自带的机制就是会对于执行概比较高的分支给出更多的预测倾斜。
处理建议-用哈希表替代switch
我们上文也介绍过哈希表也就是字典,可以快速将键值key转化为值value,从某种程度上讲可以替换switch的作用,按照第一段代码的逻辑,用哈希表重写的方案如下:
import java.util.HashMap;
public class Main {
public static void main(String[] args) {
long now=System.currentTimeMillis(); int max=6,min=0;
HashMap
hMap.put(0,0);
hMap.put(1,0);
hMap.put(2,0);
hMap.put(3,0);
hMap.put(4,0);
hMap.put(5,0);
for(int j=0;j<10000000;j++){
int ran=(int)(Math.random()*(max-min)+min);
int value = hMap.get(ran)+1;
hMap.replace(ran,value);
}
long diff=System.currentTimeMillis()-now;
System.out.println(hMap);
System.out.println("time is "+ diff);
}}
上述这段用哈希表的代码虽然不如代码一速度快,但是总体非常稳定,即使出现代码二的情况也比较平稳。
经验总结
一、有并发的终端编程一定要注意按照缓存行(64byte)对齐,不按照缓存行对齐的代码就是每增加一个线程性能会损失20%。
二、重点关注switch、if-else分支的问题,一旦条件分支的取值条件有所变化,那么应该首选用哈希表结构,对于条件分支进行优化。
三、选择一款好用的性能监测工具,如:友盟U-APM,不仅免费且捕获类型较为全面,推荐大家使用。
作者:马占杰