【人工智能项目】- 深度学习实现猫狗大战
【人工智能项目】- 深度学习实现猫狗大战

本次实现猫狗大战,实质上就是猫狗的二分类任务。
环境
!nvidia-smi
Mon Jun 22 04:24:29 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.36.06 Driver Version: 418.67 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 00000000:00:04.0 Off | 0 |
| N/A 38C P8 26W / 149W | 0MiB / 11441MiB | 0% Default |
| | | ERR! |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
!unzip cats_and_dogs.zip
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import os
import time
import datetime
import sys
import glob
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.utils import class_weight as cw
from keras import Sequential
from keras.models import Model
from keras.layers import LSTM,Activation,Dense,Dropout,Input,Embedding,BatchNormalization,Add,concatenate,Flatten
from keras.layers import Conv1D,Conv2D,Convolution1D,MaxPool1D,SeparableConv1D,SpatialDropout1D,GlobalAvgPool1D,GlobalMaxPool1D,GlobalMaxPooling1D
from keras.layers.pooling import _GlobalPooling1D
from keras.layers import MaxPooling2D,GlobalMaxPooling2D,GlobalAveragePooling2D
from keras.optimizers import RMSprop,Adam
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
from keras.utils import to_categorical
from keras.callbacks import EarlyStopping
from keras.callbacks import ModelCheckpoint
from keras.callbacks import ReduceLROnPlateau
from keras import __version__
from keras.applications.inception_v3 import InceptionV3, preprocess_input
from keras.models import Model
from keras.layers import Dense, GlobalAveragePooling2D
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import Adam
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")
/usr/local/lib/python3.6/dist-packages/statsmodels/tools/_testing.py:19: FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.
import pandas.util.testing as tm
Using TensorFlow backend.
读取数据
img_width,img_height = 299, 299 #修正 InceptionV3 的尺寸参数
epochs = 5
batch_size = 32
fc_size = 1024
def get_nb_files(directory):
"""Get number of files by searching directory recursively"""
if not os.path.exists(directory):
return 0
cnt = 0
for r, dirs, files in os.walk(directory):
for dr in dirs:
cnt += len(glob.glob(os.path.join(r, dr + "/*"))) # glob模块是用来查找匹配文件的,后面接匹配规则。
return cnt
# 定义增加最后一个全连接层的函数
def add_new_last_layer(base_model, nb_classes):
"""Add last layer to the convnet
Args:
base_model: keras model excluding top
nb_classes: # of classes
Returns:
new keras model with last layer
"""
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(fc_size, activation='relu')(x) #new FC layer, random init
predictions = Dense(nb_classes, activation='softmax')(x) #new softmax layer
model = Model(inputs=base_model.input, outputs=predictions)
return model
# 定义微调函数
def setup_to_finetune(model):
"""Freeze the bottom NB_IV3_LAYERS and retrain the remaining top layers.
note: NB_IV3_LAYERS corresponds to the top 2 inception blocks in the inceptionv3 arch
Args:
model: keras model
"""
# for layer in model.layers[:NB_IV3_LAYERS_TO_FREEZE]:
# layer.trainable = False
for layer in model.layers[:]:
layer.trainable = True
model.compile(optimizer=Adam(lr=0.0001), loss='categorical_crossentropy', metrics=['accuracy'])
train_dir= "./train"
valid_dir = "./validation"
nb_classes = len(glob.glob(train_dir + "/*"))
# nb_val_samples = get_nb_files(val_dir)
epochs = int(epochs)
batch_size = int(batch_size)
train_data = ImageDataGenerator(
# 浮点数,剪切强度(逆时针方向的剪切变换角度)
shear_range=0.1,
# 随机缩放的幅度,若为浮点数,则相当于[lower,upper] = [1 - zoom_range, 1+zoom_range]
zoom_range=0.1,
# 浮点数,图片宽度的某个比例,数据提升时图片水平偏移的幅度
width_shift_range=0.1,
# 浮点数,图片高度的某个比例,数据提升时图片竖直偏移的幅度
height_shift_range=0.1,
# 布尔值,进行随机水平翻转
horizontal_flip=True,
# 布尔值,进行随机竖直翻转
vertical_flip=True,
# 在 0 和 1 之间浮动。用作验证集的训练数据的比例
# validation_split=0.3
)
# 接下来生成验证集,可以参考训练集的写法
validation_data = ImageDataGenerator(
# 浮点数,剪切强度(逆时针方向的剪切变换角度)
shear_range=0.1,
# 随机缩放的幅度,若为浮点数,则相当于[lower,upper] = [1 - zoom_range, 1+zoom_range]
zoom_range=0.1,
# 浮点数,图片宽度的某个比例,数据提升时图片水平偏移的幅度
width_shift_range=0.1,
# 浮点数,图片高度的某个比例,数据提升时图片竖直偏移的幅度
height_shift_range=0.1,
# 布尔值,进行随机水平翻转
horizontal_flip=True,
# 布尔值,进行随机竖直翻转
vertical_flip=True,
)
train_generator = train_data.flow_from_directory(
# 提供的路径下面需要有子目录
train_dir,
# 整数元组 (height, width),默认:(256, 256)。 所有的图像将被调整到的尺寸。
target_size=(299,299),
# 一批数据的大小
batch_size=batch_size,
# "categorical", "binary", "sparse", "input" 或 None 之一。
# 默认:"categorical",返回one-hot 编码标签。
class_mode='categorical',
seed=0)
validation_generator = train_data.flow_from_directory(
valid_dir,
target_size=(299,299),
batch_size=batch_size,
class_mode='categorical',
seed=0)
Found 1800 images belonging to 2 classes.
Found 600 images belonging to 2 classes.
模型准备
# 准备跑起来,首先给 base_model 和 model 赋值,迁移学习和微调都是使用 InceptionV3 的 notop 模型(看 inception_v3.py 源码,此模型是打开了最后一个全连接层),利用 add_new_last_layer 函数增加最后一个全连接层。
base_model = InceptionV3(weights="imagenet", include_top=False) # include_top=False excludes final FC layer
model = add_new_last_layer(base_model, nb_classes)
print("开始微调:\n")
# fine-tuning
setup_to_finetune(model)
Downloading data from https://github.com/fchollet/deep-learning-models/releases/download/v0.5/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5
87916544/87910968 [==============================] - 1s 0us/step
开始微调:
model.summary()
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, None, None, 3 0
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, None, None, 3 864 input_1[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, None, None, 3 96 conv2d_1[0][0]
__________________________________________________________________________________________________
activation_1 (Activation) (None, None, None, 3 0 batch_normalization_1[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, None, None, 3 9216 activation_1[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, None, None, 3 96 conv2d_2[0][0]
__________________________________________________________________________________________________
activation_2 (Activation) (None, None, None, 3 0 batch_normalization_2[0][0]
__________________________________________________________________________________________________
conv2d_3 (Conv2D) (None, None, None, 6 18432 activation_2[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, None, None, 6 192 conv2d_3[0][0]
__________________________________________________________________________________________________
activation_3 (Activation) (None, None, None, 6 0 batch_normalization_3[0][0]
__________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, None, None, 6 0 activation_3[0][0]
__________________________________________________________________________________________________
conv2d_4 (Conv2D) (None, None, None, 8 5120 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, None, None, 8 240 conv2d_4[0][0]
__________________________________________________________________________________________________
global_average_pooling2d_1 (Glo (None, 2048) 0 mixed10[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 1024) 2098176 global_average_pooling2d_1[0][0]
__________________________________________________________________________________________________
dense_2 (Dense) (None, 2) 2050 dense_1[0][0]
==================================================================================================
Total params: 23,903,010
Trainable params: 23,868,578
Non-trainable params: 34,432
__________________________________________________________________________________________________
print("Setting Callbacks")
checkpoint = ModelCheckpoint("model.h5",
monitor="val_loss",
save_best_only=True,
mode="min")
early_stopping = EarlyStopping(monitor="val_loss",
patience=3,
verbose=1,
restore_best_weights=True,
mode="min")
reduce_lr = ReduceLROnPlateau(monitor="val_loss",
factor=0.6,
patience=2,
verbose=1,
mode="min")
callbacks=[checkpoint,early_stopping,reduce_lr]
Setting Callbacks
训练
history_ft = model.fit_generator(
train_generator,
steps_per_epoch=1800 // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=600 // batch_size,
callbacks=callbacks)
Epoch 1/20
56/56 [==============================] - 139s 2s/step - loss: 0.1774 - accuracy: 0.9259 - val_loss: 0.0389 - val_accuracy: 0.9358
Epoch 2/20
56/56 [==============================] - 99s 2s/step - loss: 0.0824 - accuracy: 0.9729 - val_loss: 0.1625 - val_accuracy: 0.9648
Epoch 3/20
56/56 [==============================] - 98s 2s/step - loss: 0.0448 - accuracy: 0.9825 - val_loss: 0.0261 - val_accuracy: 0.9577
Epoch 4/20
56/56 [==============================] - 98s 2s/step - loss: 0.0432 - accuracy: 0.9898 - val_loss: 0.1232 - val_accuracy: 0.9789
Epoch 5/20
56/56 [==============================] - 97s 2s/step - loss: 0.0311 - accuracy: 0.9893 - val_loss: 0.1762 - val_accuracy: 0.9366
Epoch 00005: ReduceLROnPlateau reducing learning rate to 5.999999848427251e-05.
Epoch 6/20
56/56 [==============================] - 96s 2s/step - loss: 0.0182 - accuracy: 0.9926 - val_loss: 0.4272 - val_accuracy: 0.9630
Restoring model weights from the end of the best epoch
Epoch 00006: early stopping
展示
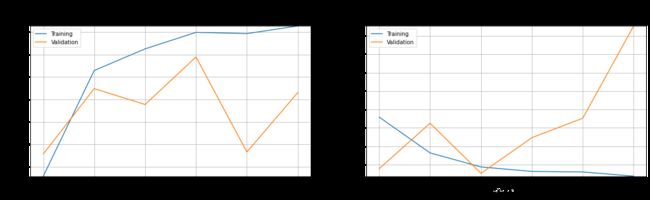
# 画曲线
def plot_performance(history=None,figure_directory=None,ylim_pad=[0,0]):
xlabel="Epoch"
legends=["Training","Validation"]
plt.figure(figsize=(20,5))
y1=history.history["accuracy"]
y2=history.history["val_accuracy"]
min_y=min(min(y1),min(y2))-ylim_pad[0]
max_y=max(max(y1),max(y2))+ylim_pad[0]
plt.subplot(121)
plt.plot(y1)
plt.plot(y2)
plt.title("Model Accuracy\n",fontsize=17)
plt.xlabel(xlabel,fontsize=15)
plt.ylabel("Accuracy",fontsize=15)
plt.ylim(min_y,max_y)
plt.legend(legends,loc="upper left")
plt.grid()
y1=history.history["loss"]
y2=history.history["val_loss"]
min_y=min(min(y1),min(y2))-ylim_pad[1]
max_y=max(max(y1),max(y2))+ylim_pad[1]
plt.subplot(122)
plt.plot(y1)
plt.plot(y2)
plt.title("Model Loss:\n",fontsize=17)
plt.xlabel(xlabel,fontsize=15)
plt.ylabel("Loss",fontsize=15)
plt.ylim(min_y,max_y)
plt.legend(legends,loc="upper left")
plt.grid()
plt.show()
plot_performance(history_ft)
import numpy as np
import pandas as pd
import os
import random
import matplotlib.pyplot as plt
from keras import regularizers
from PIL import Image
from tensorflow.keras.preprocessing import image
import glob
# Image processing
from PIL import Image, ImageFile
from keras.preprocessing import image
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from keras.layers import Dropout
from keras.layers import BatchNormalization
from keras.callbacks import EarlyStopping
import keras.backend as K
from keras.models import Sequential
from keras.layers import Dense, Conv2D, MaxPool2D, Flatten
from keras.layers import Activation, Dense
from keras.utils.np_utils import to_categorical
from keras.optimizers import SGD, Adam, Adagrad, RMSprop
from sklearn.metrics import confusion_matrix
import seaborn as sns
import tensorflow as tf
from keras.models import load_model
from keras.preprocessing import image
from sklearn.metrics import accuracy_score
true=[]
pred=[]
garbage_types = ['cats','dogs']
labels = {
0:'cats',1:'dogs'}
model_path = 'model.h5'
model = load_model(model_path)
for garbage in garbage_types:
files = glob.glob("./test/" + str(garbage) + "/*.jpg")
for myFile in files:
t = list(labels.keys())[list(labels.values()).index(str(garbage))]
true.append(t)
img = image.load_img(myFile,target_size=(224,224))
input_image = image.img_to_array(img)
# 加载模型,加载请注意 model_path 是相对路径, 与当前文件同级。
# 如果你的模型是在 results 文件夹下的 dnn.h5 模型,则 model_path = 'results/dnn.h5'
# -------------------------- 实现模型预测部分的代码 ---------------------------
# expand_dims的作用是把img.shape转换成(1, img.shape[0], img.shape[1], img.shape[2])
x = np.expand_dims(img, axis=0)
# 模型预测
y = model.predict(x)
predict = labels[np.argmax(y)]
pred.append(np.argmax(y))
acc = accuracy_score(true,pred)
print(acc)
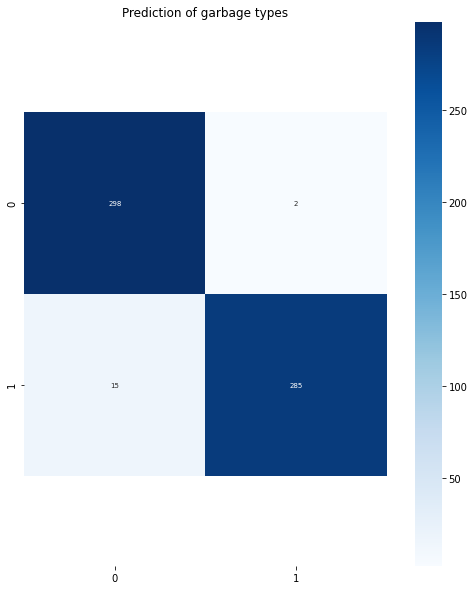
con_matrix = confusion_matrix(true, pred,
labels=[0, 1])
plt.figure(figsize=(10, 10))
plt.title('Prediction of garbage types')
plt.ylabel('True label')
plt.xlabel('Predicted label')
# plt.show(sns.heatmap(con_matrix, annot=True, fmt="d",annot_kws={"size": 7},cmap='Blues',square=True))
ax = sns.heatmap(con_matrix, annot=True, fmt="d", annot_kws={
"size": 7}, cmap='Blues', square=True)
bottom, top = ax.get_ylim()
ax.set_ylim(bottom + 0.5, top - 0.5)
plt.show()
0.9716666666666667
小结
本次就用迁移学习的方式完成猫狗二分类任务,很简单的任务。
瓷们,还是点赞收藏评论走起来!!!
