Pytorch:基于VGG16的迁移学习实现“猫狗大战”
目录
- 前言
- 步骤
- Python 实现
-
- 1.预处理工作
- 2.改进VGG16模型
- 3.模型训练和验证
- 4.调整参数
- 5.测试模型
- 完整代码
- 总结
前言
VGG是由Simonyan 和Zisserman在文献《Very Deep Convolutional Networks for Large Scale Image Recognition》中提出卷积神经网络模型,其名称来源于作者所在的牛津大学视觉几何组(Visual Geometry Group)的缩写。
该模型参加2014年的 ImageNet图像分类与定位挑战赛,取得了优异成绩:在分类任务上排名第二,在定位任务上排名第一。
VGG16的网络结构如下图所示:
Kaggle 于2013年举办的猫狗大战比赛,判断一张输入图像是“猫”还是“狗”。该教程使用在 ImageNet 上预训练 的 VGG16 网络进行测试。因为原网络的分类结果是1000类,所以这里进行迁移学习,对原网络进行 fine-tune (即固定前面若干层,作为特征提取器,只重新训练最后几层)。
步骤
- 从AI研习社练习赛的网站上下载用于训练、验证和测试的数据集
- 改进VGG16模型,利用训练数据集训练新的模型
- 使用验证数据集对新模型进行验证,并调整参数
- 用测试数据集得到最终结果,上传到练习赛的网站查看排名。
Python 实现
1.预处理工作
- 判断是否有GPU
# 判断是否存在GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
- 数据存放也需要的进行一定更改
原始的目录存放格式如下:
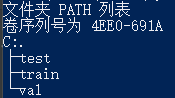
更改后的目录结构:
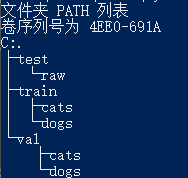
# 数据存放目录
data_dir = './data/cat_dog'
# 在train数据集中创建cats和dogs子文件夹,方便ImageFolder的读取
train_dir = os.path.join(data_dir, 'train')
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')
list_dir = os.listdir(train_dir)
os.mkdir(train_cats_dir)
os.mkdir(train_dogs_dir)
for i in list_dir:
if 'cat' in i:
shutil.copyfile(os.path.join(train_dir, i), os.path.join(train_cats_dir, i))
else:
shutil.copyfile(os.path.join(train_dir, i), os.path.join(train_dogs_dir, i))
# 在val数据集中创建cats和dogs子文件夹,方便ImageFolder的读取
val_dir = os.path.join(data_dir, 'val')
val_cats_dir = os.path.join(val_dir, 'cats')
val_dogs_dir = os.path.join(val_dir, 'dogs')
list_dir = os.listdir(val_dir)
os.mkdir(val_cats_dir)
os.mkdir(val_dogs_dir)
for i in list_dir:
if 'cat' in i:
shutil.copyfile(os.path.join(val_dir, i), os.path.join(val_cats_dir, i))
else:
shutil.copyfile(os.path.join(val_dir, i), os.path.join(val_dogs_dir, i))
# 在test数据集中创建raw子文件夹,方便ImageFolder的读取
test_dir = os.path.join(data_dir, 'test')
test_raw_dir = os.path.join(test_dir, 'raw')
list_dir = os.listdir(test_dir)
os.mkdir(test_raw_dir)
for i in list_dir:
filename = ''.join(i.zfill(8))
shutil.copyfile(os.path.join(test_dir, i), os.path.join(test_raw_dir, filename))
- 定义数据集的loader
# 读取三个数据集
transform = transforms.Compose([
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
data_sets = {
'train': datasets.ImageFolder(train_dir, transform),
'val': datasets.ImageFolder(val_dir, transform),
'test': datasets.ImageFolder(test_dir, transform)}
# data_sets的行数
data_set_sizes = {
x: len(data_sets[x]) for x in ['train', 'val', 'test']}
# 三个数据集的loader
train_loader = torch.utils.data.DataLoader(data_sets['train'],
batch_size=10,
shuffle=True,
num_workers=8)
val_loader = torch.utils.data.DataLoader(data_sets['val'],
batch_size=10,
shuffle=False,
num_workers=8)
test_loader = torch.utils.data.DataLoader(data_sets['test'],
batch_size=10,
shuffle=False,
num_workers=8)
2.改进VGG16模型
- 固定前面15层的参数,调整最后一层参数,再加上Softmax函数
# 根据VGG16创建新模型
new_model = models.vgg16(pretrained=True)
# 固定前面15层的参数
for param in new_model.parameters():
param.requires_grad = False
# 改变原来的16层
new_model.classifier._modules['6'] = nn.Linear(4096, 2)
new_model.classifier._modules['7'] = nn.LogSoftmax(dim=1)
new_model = new_model.to(device)
- 确定损失函数、学习率、优化器
# 创建损失函数和优化器
# 损失函数 NLLLoss() 的 输入 是一个对数概率向量和一个目标标签.
# 它不会为我们计算对数概率,适合最后一层是log_softmax()的网络.
criterion = nn.NLLLoss()
# 学习率
lr = 0.001
# 随机梯度下降
optimizer = torch.optim.SGD(new_model.classifier[6].parameters(), lr=lr)
3.模型训练和验证
- 定义训练模型的函数
# 训练模型
def train_model(device, model, dataloader, size, epochs, criterion, optimizer):
model.train()
for epoch in range(epochs):
running_loss = 0.0
running_corrects = 0
for inputs, classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs, classes)
optimizer.zero_grad()
loss.backward()
optimizer.step()
_, preds = torch.max(outputs.data, 1)
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc))
print('Finish train')
- 定义验证模型的函数
def val_model(device, model, dataloader, size, criterion):
model.eval()
running_loss = 0.0
running_corrects = 0
for inputs, classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs, classes)
_, preds = torch.max(outputs.data, 1)
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc))
print('Finish validate')
torch.save(model, './data/model1.pth')
- 调用训练函数和验证函数,训练10次并验证一次,然后将模型model1输出到指定位置。
# 模型训练
train_model(device, new_model, train_loader, data_set_sizes['train'], 10, criterion, optimizer)
# 模型验证
val_model(device, new_model, val_loader, data_set_sizes['val'], criterion)
- 结果显示如下:

可以看出损失不断下降,准确率不断上升,并且达到了97%以上
4.调整参数
为了使结果更精确一点,我们微调一下参数,将batch_size从10更改为100,然后再次训练和验证,将模型model2输出到指定位置。
# 三个数据集的loader
train_loader = torch.utils.data.DataLoader(data_sets['train'],
batch_size=100,
shuffle=True,
num_workers=8)
val_loader = torch.utils.data.DataLoader(data_sets['val'],
batch_size=100,
shuffle=False,
num_workers=8)
test_loader = torch.utils.data.DataLoader(data_sets['test'],
batch_size=100,
shuffle=False,
num_workers=8)
调整后效果如下:
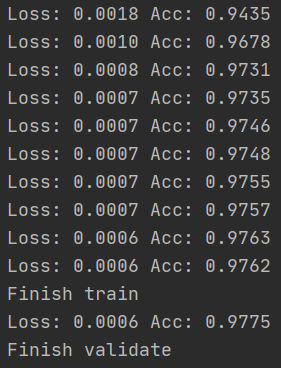
准确率有了略微的上升
5.测试模型
- 定义测试模型函数,将第二次的model2导入测试,结果导出到指定格式的csv文件中。
def test_model(device, path, dataloader):
model = torch.load(path)
model.eval()
total_preds = []
for inputs, classes in dataloader:
inputs = inputs.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs.data, 1)
total_preds.extend(preds)
with open("./data/result.csv", 'a+') as f:
for i in range(2000):
f.write("{},{}\n".format(i, total_preds[i]))
- 将导出的csv文件上传到AI研习社的网站,查看评分

完整代码
import shutil
import os
import torch
import torch.nn as nn
from torchvision import models, transforms, datasets
import torch.utils.data
# 训练模型
def train_model(device, model, dataloader, size, epochs, criterion, optimizer):
model.train()
for epoch in range(epochs):
running_loss = 0.0
running_corrects = 0
for inputs, classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs, classes)
optimizer.zero_grad()
loss.backward()
optimizer.step()
_, preds = torch.max(outputs.data, 1)
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc))
print('Finish train')
def val_model(device, model, dataloader, size, criterion):
model.eval()
running_loss = 0.0
running_corrects = 0
for inputs, classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs, classes)
_, preds = torch.max(outputs.data, 1)
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc))
print('Finish validate')
torch.save(model, './data/model2.pth')
def test_model(device, path, dataloader):
model = torch.load(path)
model.eval()
total_preds = []
for inputs, classes in dataloader:
inputs = inputs.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs.data, 1)
total_preds.extend(preds)
with open("./data/result.csv", 'a+') as f:
for i in range(2000):
f.write("{},{}\n".format(i, total_preds[i]))
def main():
# 判断是否存在GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 数据存放目录
data_dir = './data/cat_dog'
# 在train数据集中创建cats和dogs子文件夹,方便ImageFolder的读取
train_dir = os.path.join(data_dir, 'train')
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')
list_dir = os.listdir(train_dir)
os.mkdir(train_cats_dir)
os.mkdir(train_dogs_dir)
for i in list_dir:
if 'cat' in i:
shutil.copyfile(os.path.join(train_dir, i), os.path.join(train_cats_dir, i))
else:
shutil.copyfile(os.path.join(train_dir, i), os.path.join(train_dogs_dir, i))
# 在val数据集中创建cats和dogs子文件夹,方便ImageFolder的读取
val_dir = os.path.join(data_dir, 'val')
val_cats_dir = os.path.join(val_dir, 'cats')
val_dogs_dir = os.path.join(val_dir, 'dogs')
list_dir = os.listdir(val_dir)
os.mkdir(val_cats_dir)
os.mkdir(val_dogs_dir)
for i in list_dir:
if 'cat' in i:
shutil.copyfile(os.path.join(val_dir, i), os.path.join(val_cats_dir, i))
else:
shutil.copyfile(os.path.join(val_dir, i), os.path.join(val_dogs_dir, i))
# 在test数据集中创建raw子文件夹,方便ImageFolder的读取
test_dir = os.path.join(data_dir, 'test')
test_raw_dir = os.path.join(test_dir, 'raw')
list_dir = os.listdir(test_dir)
os.mkdir(test_raw_dir)
for i in list_dir:
filename = ''.join(i.zfill(8))
shutil.copyfile(os.path.join(test_dir, i), os.path.join(test_raw_dir, filename))
# 读取三个数据集
transform = transforms.Compose([
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
data_sets = {
'train': datasets.ImageFolder(train_dir, transform),
'val': datasets.ImageFolder(val_dir, transform),
'test': datasets.ImageFolder(test_dir, transform)}
# data_sets的行数
data_set_sizes = {
x: len(data_sets[x]) for x in ['train', 'val', 'test']}
# 三个数据集的loader
train_loader = torch.utils.data.DataLoader(data_sets['train'],
batch_size=100,
shuffle=True,
num_workers=8)
val_loader = torch.utils.data.DataLoader(data_sets['val'],
batch_size=100,
shuffle=False,
num_workers=8)
test_loader = torch.utils.data.DataLoader(data_sets['test'],
batch_size=100,
shuffle=False,
num_workers=8)
# 根据VGG16创建新模型
new_model = models.vgg16(pretrained=True)
# 固定前面15层的参数
for param in new_model.parameters():
param.requires_grad = False
# 改变原来的16层
new_model.classifier._modules['6'] = nn.Linear(4096, 2)
new_model.classifier._modules['7'] = nn.LogSoftmax(dim=1)
new_model = new_model.to(device)
# 创建损失函数和优化器
# 损失函数 NLLLoss() 的 输入 是一个对数概率向量和一个目标标签.
# 它不会为我们计算对数概率,适合最后一层是log_softmax()的网络.
criterion = nn.NLLLoss()
# 学习率
lr = 0.001
# 随机梯度下降
optimizer = torch.optim.SGD(new_model.classifier[6].parameters(), lr=lr)
# 模型训练
train_model(device, new_model, train_loader, data_set_sizes['train'], 10, criterion, optimizer)
# 模型验证
val_model(device, new_model, val_loader, data_set_sizes['val'], criterion)
# 模型测试
test_model(device, './data/model2.pth', test_loader)
if __name__ == '__main__':
main()
总结
通过此次的项目,可以得知基于VGG16的迁移学习实现逻辑回归是十分有效的,并且可以通过适当调整batch_size的参数来获得更高的准确率。