Python多线程Threading
目录
Python并发编程简介
1.为什么要引入并发编程?
2.有哪些程序提速的方法?
3.python对并发编程的支持
怎样选择多线程Thread、多进程Process、多协程Coroutine
1.什么是CPU密集型计算、IO密集型计算?
2.多线程、多进程、多协程的对比
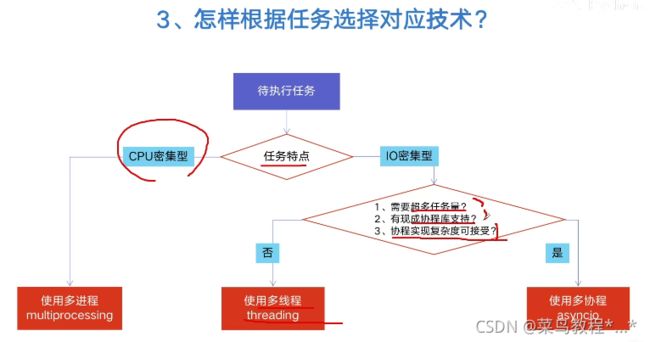
3.怎样根据任务选择对应技术?
Python速度慢的罪魁祸首,全局解释器锁GIL
1.python速度慢的两大原因
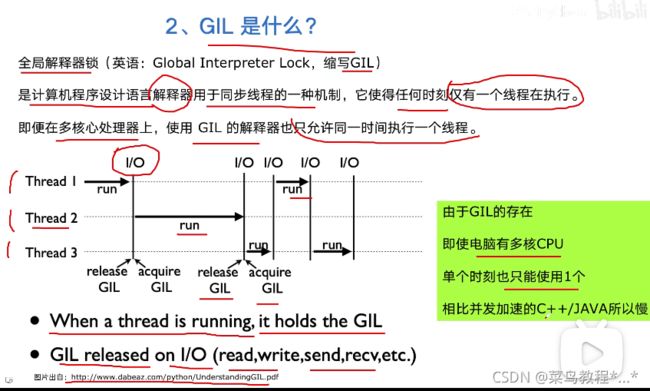
2.GIL是什么?
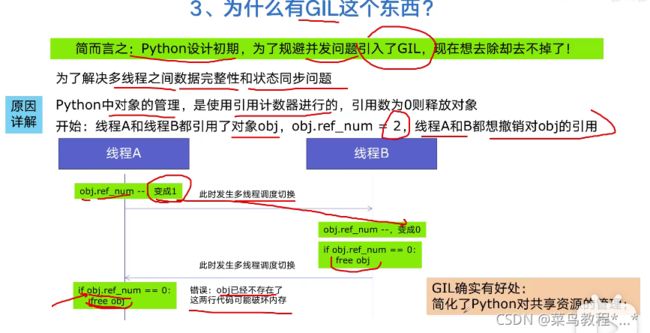
3.为什么有GIL这个东西?
4.怎样规避GIL带来的限制?
使用多线程,Python多线程被加速10倍
1.Python创建多线程的方法
2.改写爬虫程序,编程多线程爬取
3.速度对比:单线程爬虫VS多线程爬虫
Python实现生产者消费者模式多线程爬虫!
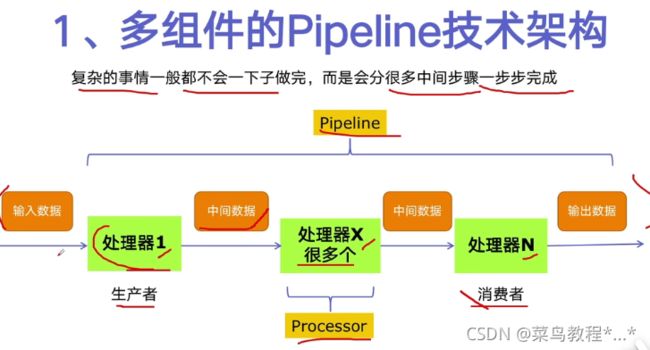
1.多组件的Pipeline技术架构
2.生产者消费者爬虫的架构
3.多线程数据通信的queue.Queue
4.代码编写实现生产者消费者爬虫
Python线程安全问题及解决方案
1.线程安全概念介绍
2.Lock用于解决线程安全问题
3.实例代码演示问题以及解决方案
好用的线程池ThreadPoolExecutor
1.线程池的原理
2.使用线程池的好处
3.ThreadPoolExecutor的使用语法
4.使用线程池改造爬虫程序
在web服务器中使用线程池加速
1.web服务的架构以及特点
2.使用线程池ThreadPoolExecutor加速
3.代码Flask实现web服务并加速实现
使用多进程multiprocessing加速程序的运行
1.有了多线程threading,为什么还要用多进程multiprocessing
2.多进程multiprocessing知识梳理
3.代码实战:单线程、多线程、多进程对比CPU密集计算速度
在Flask服务中使用进程池加速
Python异步IO实现并发爬虫
在异步IO中使用信号量控制爬虫并发度
使用subprocess启动电脑任意程序听歌、解压缩、自动下载等等
Python并发编程简介
1.为什么要引入并发编程?
场景1:一个网络爬虫,按顺序爬取了1小时,采用并发下载减少到20分钟!
场景2:一个APP应用,优化前每次打开页面需要3秒钟,采用异步并发提升到每次200毫秒;
2.有哪些程序提速的方法?

3.python对并发编程的支持

怎样选择多线程Thread、多进程Process、多协程Coroutine
1.什么是CPU密集型计算、IO密集型计算?

2.多线程、多进程、多协程的对比

3.怎样根据任务选择对应技术?
Python速度慢的罪魁祸首,全局解释器锁GIL
1.python速度慢的两大原因

2.GIL是什么?
3.为什么有GIL这个东西?
4.怎样规避GIL带来的限制?

使用多线程,Python多线程被加速10倍
1.Python创建多线程的方法

2.改写爬虫程序,编程多线程爬取
blog_spider.py
import requests
urls=[f"https://www.cnblogs.com/#p{page}"
for page in range(1,50+1)
]
def craw(url):
r=requests.get(url)
print(url,len(r.text))
craw(urls[0])multi_thread_craw.py
import blog_spider
import threading
import time
def single_thread():
print("single_thread begin")
for url in blog_spider.urls:
blog_spider.craw(url)
print("single_thread end")
def multi_thread():
print("single_thread begin")
threads=[]
for url in blog_spider.urls:
threads.append(
threading.Thread(target=blog_spider.craw,args=(url,))
)
for thread in threads:
thread.start()
for thread in threads:
thread.join()
print("single_thread end")
if __name__=='__main__':
start=time.time()
single_thread()
end=time.time()
print("single thread cost:",end-start)
start = time.time()
multi_thread()
end = time.time()
print("multi thread cost:", end - start)3.速度对比:单线程爬虫VS多线程爬虫
Python实现生产者消费者模式多线程爬虫!
1.多组件的Pipeline技术架构
2.生产者消费者爬虫的架构

3.多线程数据通信的queue.Queue

4.代码编写实现生产者消费者爬虫
Python线程安全问题及解决方案
1.线程安全概念介绍
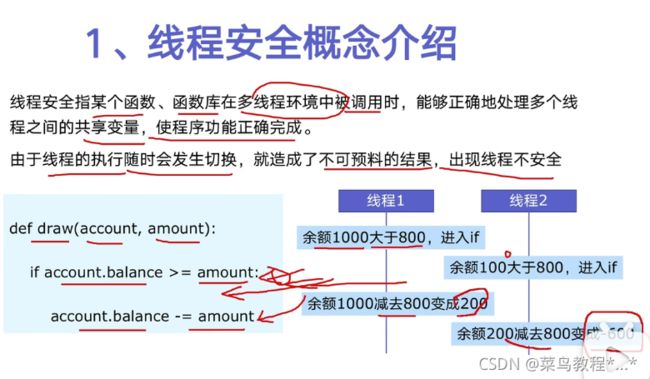
2.Lock用于解决线程安全问题

3.实例代码演示问题以及解决方案
好用的线程池ThreadPoolExecutor
1.线程池的原理
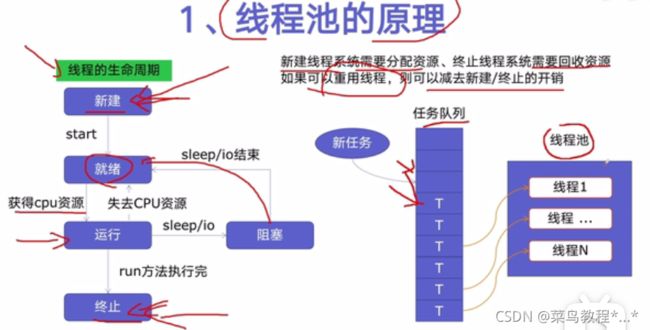
2.使用线程池的好处

3.ThreadPoolExecutor的使用语法

4.使用线程池改造爬虫程序
在web服务器中使用线程池加速
1.web服务的架构以及特点

2.使用线程池ThreadPoolExecutor加速

3.代码Flask实现web服务并加速实现
import flask
import json
import time
from concurrent.futures import ThreadPoolExecutor
app=flask.Flask(__name__)
pool=ThreadPoolExecutor()
def read_file():
time.sleep(0.1)
return "file result"
def read_db():
time.sleep(0.2)
return "db result"
def read_api():
time.sleep(0.3)
return "api result"
@app.route("/")
def index():
result_file=pool.submit(read_file)
result_db=pool.submit(read_db)
result_api=pool.submit(read_api)
return json.dumps({
"result_file":result_file.result(),
"result_db":result_db.result(),
"result_api":result_api.result(),
})
if __name__=='__main__':
app.run()使用多进程multiprocessing加速程序的运行
1.有了多线程threading,为什么还要用多进程multiprocessing
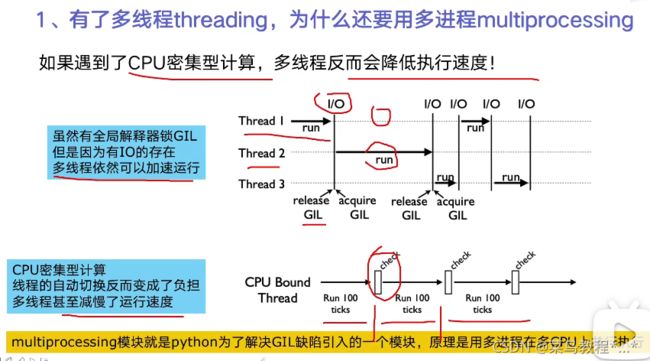
2.多进程multiprocessing知识梳理

3.代码实战:单线程、多线程、多进程对比CPU密集计算速度
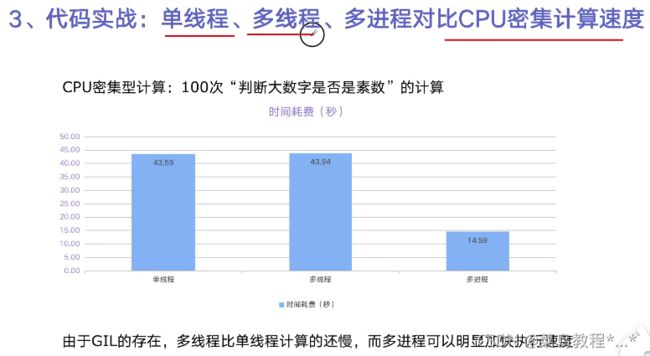
import math
import time
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
PRIMES=[112272535095293]*100
def is_prime(n):
if n<2:
return False
if n==2:
return True
if n%2==0:
return False
sqrt_n=int(math.floor(math.sqrt(n)))
for i in range(3,sqrt_n+1,2):
if n%i==0:
return False
return True
def single_thread():
for number in PRIMES:
is_prime(number)
def multi_thread():
with ThreadPoolExecutor() as pool:
pool.map(is_prime,PRIMES)
def multi_process():
with ProcessPoolExecutor() as pool:
pool.map(is_prime,PRIMES)
if __name__=="__main__":
start=time.time()
single_thread()
end=time.time()
print("single_thread,cost:",end-start,"seconds")
start=time.time()
multi_thread()
end=time.time()
print("multi_thread,cost:",end-start,"seconds")
start=time.time()
multi_process()
end=time.time()
print("multi_process,cost:",end-start,"seconds")在Flask服务中使用进程池加速
import flask
import math
import json
from concurrent.futures import ProcessPoolExecutor
process_pool=ProcessPoolExecutor()
app=flask.Flask()
def is_prime(n):
if n<2:
return False
if n==2:
return True
if n%2==0:
return False
sqrt_n=int(math.floor(math.sqrt(n)))
for i in range(3,sqrt_n+1,2):
if n%i==0:
return False
return True
@app.route("/is_prime/")
def api_is_prime(numbers):
number_list=[int(x) for x in numbers.split(",")]
results=process_pool.map(is_prime,number_list)
return json.dumps(dict(zip(number_list,results)))
if __name__=="__main__":
process_pool=ProcessPoolExecutor()
app.run() Python异步IO实现并发爬虫
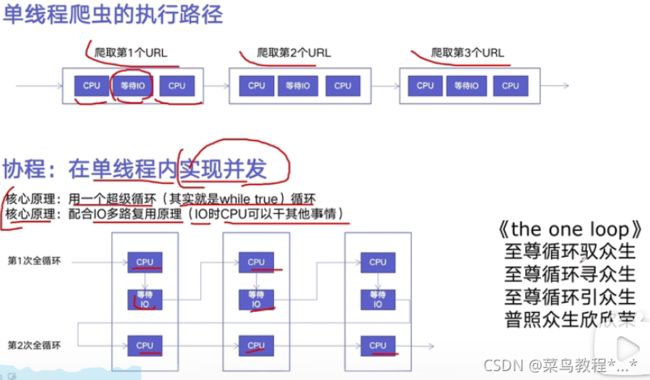
 在异步IO中使用信号量控制爬虫并发度
在异步IO中使用信号量控制爬虫并发度
 使用subprocess启动电脑任意程序听歌、解压缩、自动下载等等
使用subprocess启动电脑任意程序听歌、解压缩、自动下载等等

