策略整合并模板化 | 从零实现AI量化回测平台 #5
今天的核心任务要走通机器学习模型,在金融标注数据的应用。
昨天我们已经完成数据集的分割。
数据集准备好了之后,进入模型训练。
def fit(self, df,
num_boost_round=1000,
early_stopping_rounds=50,
verbose_eval=20,
evals_result=dict(),
**kwargs):
dtrain, dvalid = self._prepare_data(df, '2016-01-01')
params = {"objective": 'mse', "verbosity": -1}
self.model = lgb.train(
params,
dtrain,
num_boost_round=num_boost_round,
valid_sets=[dtrain, dvalid],
valid_names=["train", "valid"],
early_stopping_rounds=early_stopping_rounds,
verbose_eval=verbose_eval,
evals_result=evals_result,
**kwargs
)
evals_result["train"] = list(evals_result["train"].values())[0]
evals_result["valid"] = list(evals_result["valid"].values())[0]
然后就是预测得分。
def predict(self):
if self.model is None:
raise ValueError("model is not fitted yet!")
return pd.Series(self.model.predict(self.df_valid['feature'].values), index=self.df_valid.index)
模型的训练与预测的代码非常简洁,与sklearn的api相类似,就是把设定相关参数,然后总能得到结果,但结果有没有效就未可知了,这一步只能算是走通了流程而已。
机器学习模型难处不在于模型的应用,而在于理解模型,参数调优,数据预处理,特征工程这些。
先来了解一下lightGBM。
说lightGBM前,一定要提GBDT(Gradient Boosting Decision Tree,梯度提升决策树),因为lightGBM只是GBDT的一种实现。
GBDT主要思想是利用弱分类器(决策树)迭代训练以得到最优模型,该模型具有训练效果好、不易过拟合等优点。
在LightGBM提出之前,最有名的GBDT工具就是XGBoost。相比于XGBoost,LightGBM在不损失准确性的前提下,加速了训练过程。
基础组件均已“成型”,再来思考一个平台整合的事情。
1、GUI界面输入task的参数,以及task可以持久化的参数,生成yaml文件。
2、读取gui界面动态参数以及yaml的文件配置,生成任务。可一次加载多个任务。
3、Task加Runtime Config生成TaskConfig交给回测引擎。
可以内置常用的策略模板,比如“买入并持有(定期再平衡)”、“按规则——轮动模型”、“机器学习——轮动模型”,并不需要开放algo级别的能力。
4、回测引擎根据任务特点,技术分析型是直接loop出结果;机器学习型的训练模型并预测得到pred_score后,运行loop。
5、回测结果持有化供分析。
6、加载持有化的回测结果,可视化回测结果。
这三段是独立通过“持久化”的中间态文件来交换信息,可以复用,在开发上也便于调试。
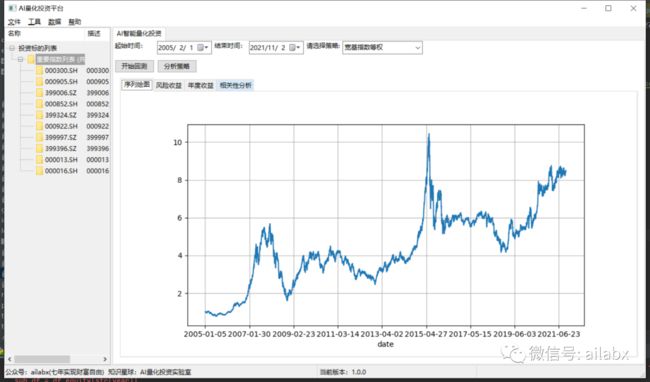

三大宽基指数,等权组合加年度再平衡,年化可以达到14%,当然最大回撤比较大。
在自研的algo模块的基础上,封装出常用的策略模板。
class StrategyBuyHold(Strategy):
#params={period=1...N,可选;}
def __init__(self, name, params={}):
algo_period = None
if 'period' in params.keys():
algo_period = RunPeriod(period=params['period'])
else:
algo_period = RunOnce()
algo_list = [
algo_period,
SelectAll(),
WeightEqually()
]
super(StrategyBuyHold, self).__init__(name,algo_list)
这个策略仅需要一个参数:period,默认值是None。
task = {
'name': '三大指数,年度再平衡',
'strategy': 'buy&hold',
'params': {
'period': 252,
}
}
轮动策略也比较简单:
class StrategyRolling(Strategy):
def __init__(self, name, params={}):
algo_list = [
SelectBySignal(signal_buy=params['signal_buy'],signal_sell=params['signal_sell']),
SelectTopK(K=params['K'], col=params['sort_by']),
WeightEqually()
]
super(StrategyRolling, self).__init__(name,algo_list=algo_list)
参数配置如下:
task_mom = {
'name': '三大指数-动量轮动',
'strategy': 'rolling',
'params': {
'K': 2,
'sort_by': '五日动量'
}
}
知识星球:AI量化投资实验室,交流最前沿人工智能与量化投资的资讯与技术。