Python-爬虫教程-拉取微博热搜数据
作为一名小可爱(神经病)
一定要有自己的觉悟
在手点一个按钮
和
花费半天写个脚本拉取
可以达到同样效果的情况下
当然要选择后者
这才是小可爱(神经病)的最后倔强
众所周知
微博热搜榜是个牛马蛇神打团战的地方
所以,我来抓人了
emmmm
抓包了
抓包获取微博热搜
一、环境
window10,Python3(需要库requests和re,可以使用pip install ***下载库)
二、抓取分析
1、打开微博热搜的网页,按F12获取可以看到源代码(最好使用chrome浏览器)

2、查看红框内数据组织形式

3、编写对应的正则表达式,获取红框中的内容。以上图为例,正则表达式可以写成:
pattern = '.*?'
4、编写脚本
# -*- encoding:utf-8 -*-
import requests
import re
import datetime
def GetWeiboRealtimeHotInfos():
hotUrl = "https://s.weibo.com/top/summary?cate=realtimehot"
res = requests.get(hotUrl) # 抓取内容
res.raise_for_status() # 检测抓取内容是否正常
#print(res.text)
# encoding代表Head中的编码方式 apparent_encoding代表Body中编码方式
# 当出现乱码时,apparent_encoding编码方式更准确
res.encoding = res.apparent_encoding
strInfo = "\n" + str(datetime.datetime.now().year) + "年" + str(datetime.datetime.now().month) + \
"月" + str(datetime.datetime.now().day) + "日" + str(datetime.datetime.now().hour) + "时 " + "微博热搜:\n"
pattern = '.*?'
re_result = re.findall(pattern, res.text)
print(re_result)
def main() :
GetWeiboRealtimeHotInfos()
main()
5、分析下结果,确实有数据了,但是阅读性太差。本着能动手绝对不BB的原则,我们得对结果做下过滤。
所以,我们再添加两个正则表大会,获取其中的网址链接和文字内容。然后设置一个最大显示条数。动手!
# -*- encoding:utf-8 -*-
import requests
import re
import datetime
def GetWeiboRealtimeHotInfos(maxCount=10) :
headUrl = "https://s.weibo.com/"
hotUrl = "https://s.weibo.com/top/summary?cate=realtimehot"
res = requests.get(hotUrl) # 抓取内容
res.raise_for_status() # 检测抓取内容是否正常
#print(res.text)
# encoding代表Head中的编码方式 apparent_encoding代表Body中编码方式
# 当出现乱码时,apparent_encoding编码方式更准确
res.encoding = res.apparent_encoding
strInfo = "\n" + str(datetime.datetime.now().year) + "年" + str(datetime.datetime.now().month) + \
"月" + str(datetime.datetime.now().day) + "日" + str(datetime.datetime.now().hour) + "时 " + "微博热搜:\n"
pattern = '.*?'
re_result = re.findall(pattern, res.text)
for i, result in enumerate(re_result) :
pattern = '>(.*?)<'
result_text = re.findall(pattern, result)
if len(result_text) > 0 :
strInfo = strInfo + result_text[0] + "\n"
#print(result_text)
pattern = ' 0 :
strInfo = strInfo + headUrl + result_url[0] + "\n"
#print(headUrl + result_url[0])
if i >= maxCount-1 :
break
return strInfo
def main() :
print(GetWeiboRealtimeHotInfos())
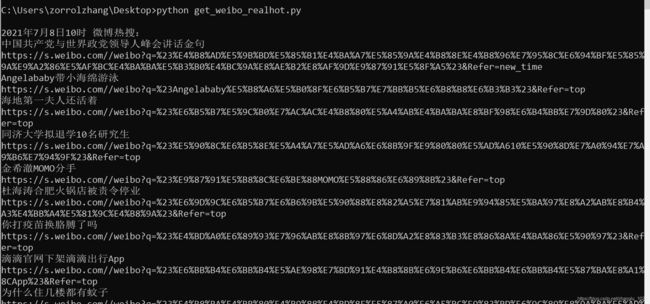
main()抓取结果如图:

百度搜"微博热搜"多费事
写个脚本
只需要三个小时
NICE!!!
