计算存储 分布式服务 分布式文件系统 虚拟化 云 容器概念学习
作者
QQ群:852283276
微信:arm80x86
微信公众号:青儿创客基地
B站:主页 https://space.bilibili.com/208826118
参考
系统扩展方式
开源主流分布式文件系统简单介绍
主流分布式文件系统的的应用场景和优缺点?
FastDFS入门一篇就够
用FastDFS一步步搭建文件管理系统
分布式文件系统 - FastDfs简介及工作原理
Hadoop分布式文件系统2-HDFS架构原理
软件定义存储(SDS)的定义及其分类
分布式存储是否会被超融合所取代?
Ceph,TFS,FastDFS,MogileFS,MooseFS,GlusterFS 对比
初识ceph(分布式文件系统)
Ceph概述 部署Ceph集群 Ceph块存储–
ceph的数据存储之路(3) ----- pg选择osd的过程(crush 算法)
深入理解ceph crush(4)—PG至OSD的crush算法源码分析
ceph的pg算法
超融合基础架构
什么是超融合?
Openstack入门篇(十六)之Cinder服务的部署与测试
openstack——cinder服务篇
OpenStack是什么?
8年!我在OpenStack路上走过的坑。。。
openstack介绍–(基础)
十分钟明白什么是容器技术
K8s 一、(1、容器基本概念 2、k8s基本概念 )
5分钟了解容器云和k8s
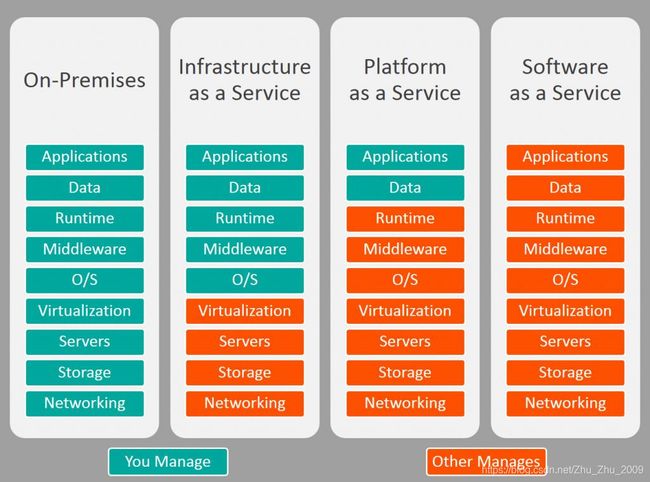
一张图看懂IaaS, PaaS和SaaS的区别
3分钟了解Docker和K8s
基于Kubernetes的私有容器云建设实践
私有容器云与devops流水线
在一台物理机上创建3个虚拟机搭建k8s集群(一)
在一台物理机上创建3个虚拟机搭建k8s集群(二)
虚拟机部署k8s集群
jenkins+k8s+pipeline+sonarqube+docker 实现maven项目自动调度pod构建打包部署
如何基于Kubernetes构建完整的DevOps流水线
DevOps开发运维与持续集成相关知识
分布式服务框架(一)
分布式服务框架gRPC
分布式服务框架设计和实现
服务化实战之 dubbo、dubbox、motan、thrift、grpc等RPC框架比较及选型
浅析分布式系统
分布式架构演变历史
Zookeeper vs Etcd
zookeeper与etcd的对比
分布式服务框架 Zookeeper —— 管理分布式环境中的数据
Raft一致性协议
一致性协议paxos
学习分布式一致性协议:自己实现一个Raft算法
OceanBase的一致性协议为什么选择 paxos而不是raft?
为什么OceanBase不适合银行的三点思考
OceanBase 架构初探
虚拟化技术:KVM与XEN的技术分析
五分钟搞懂Xen、KVM、Qemu间的关系和区别
虚拟化技术中KVM,Xen,Qemu的区别和联系
虚拟化技术:Xen和KVM的对比
AWS将虚拟化技术从XEN切换到KVM ,聊一聊大象转身过程中的技术难点
QEMU,KVM及QEMU-KVM介绍
Edgex Foundry 框架那些事-01
开源边缘计算框架 EdgeX Foundry 介绍
分布式存储与传统存储架构
主流分布式存储技术的对比分析与应用
分布式存储的架构以及存在的问题和解决办法1
分布式存储的架构以及存在的问题和解决办法2
存储扩展方法
Scale Up纵向扩展主要是利用现有的存储系统,通过不断增加存储容量来满足数据增长的需求。但是这种方式只增加了容量,而带宽和计算能力并没有相应的增加。所以,整个存储系统很快就会达到性能瓶颈,需要继续扩展。
Scale-out横向扩展架构的升级通常是以节点为单位,每个节点往往将包含容量、处理能力和I / O带宽。一个节点被添加到存储系统,系统中的三种资源将同时升级。容量增长和性能扩展(即增加额外的控制器)是同时进行。而且,Scale-out架构的存储系统在扩展之后,从用户的视角看起来仍然是一个单一的系统,这一点与我们将多个相互独立的存储系统简单的叠加在一个机柜中是完全不同的。所以scale out方式使得存储系统升级工作大大简化,用户能够真正实现按需购买,降低TCO。
虚拟化
KVM项目逐渐开始成熟。KVM因为其简单的架构,大量复用了Linux内核的逻辑,使得代码简单高效, 得到了业界的一致认可。比XEN更有前景。
QEMU是一个主机上的VMM(virtual machine monitor),通过动态二进制转换来模拟CPU,并提供一系列的硬件模型,使guest os认为自己和硬件直接打交道,其实是同QEMU模拟出来的硬件打交道,QEMU再将这些指令翻译给真正硬件进行操作。通过这种模式,guest os可以和主机上的硬盘,网卡,CPU,CD-ROM,音频设备和USB设备进行交互。但由于所有指令都需要经过QEMU来翻译,因而性能会比较差。KVM负责cpu虚拟化+内存虚拟化,实现了cpu和内存的虚拟化,但kvm并不能模拟其他设备,还必须有个运行在用户空间的工具才行。KVM的开发者选择了比较成熟的开源虚拟化软件QEMU来作为这个工具,QEMU模拟IO设备(网卡,磁盘等),对其进行了修改,最后形成了QEMU-KVM。QEMU模拟其他的硬件,如Network, Disk,同样会影响这些设备的性能。于是又产生了pass through半虚拟化设备virtio_blk, virtio_net,提高设备性能。
Cloud
SaaS:软件即服务
软件即服务(也称为云应用程序服务)代表了云市场中企业最常用的选项。 SaaS利用互联网向其用户提供应用程序,这些应用程序由第三方供应商管理。 大多数SaaS应用程序直接通过Web浏览器运行,不需要在客户端进行任何下载或安装。
PaaS:平台即服务
云平台服务或平台即服务(PaaS)为某些软件提供云组件,这些组件主要用于应用程序。 PaaS为开发人员提供了一个框架,使他们可以基于它创建自定义应用程序。所有服务器,存储和网络都可以由企业或第三方提供商进行管理,而开发人员可以负责应用程序的管理。
IaaS:基础架构即服务
云基础架构服务称为基础架构即服务(IaaS),由高度可扩展和自动化的计算资源组成。 IaaS是完全自助服务,用于访问和监控计算、网络,存储和其他服务等内容,它允许企业按需求和需要购买资源,而不必购买全部硬件。
下面的这个吊毛知乎还禁止从网页上复制文字,都是老外开源的,你搁这儿装啥13呢,搞得好像这三个名词你有专利权一样,
。它最先由美国国家航空航天局(NASA)和 Rackspace 在 2010 年合作研发,现在参与的人员和组织汇集了来自 100 多个国家的超过 9500 名的个人和 850 多个世界上赫赫有名的企业,如 NASA、谷歌、惠普、Intel、IBM、微软等。
企业私有云环境中,VMware 是真正的老大。因此,OpenStack这要做私有云的目标,说好听点,要向 VMware学习;说难听点,就是要替代掉VMware。而 VMware vSphere 提供的只是虚拟化环境,因此 OpenStack 对标的对象我认为应该是 『VMware的 虚拟化功能』+『AWS的 Cloud 功能,主要是云API』。但是,因为一开始 OpenStack 对标的是 AWS,而AWS 是公有云不是私有云,这就导致了后来很多问题的出现,下文会仔细道来。
『VMware 虚拟化』+『AWS Cloud 功能』这两部分中,因为一开始OpenStack 就是对标AWS的,因此 『Cloud』部分应该说做得还是很不错的,或者说克隆的不错。这从用户调查的『为什么组织会选择OpenStack?』部分的答案中也能看出来,即开放平台和API的标准化是第一业务驱动力。
容器的出现,对OpenStack的冲击很大。但是,我们也要看到,容器的出现,并没有使得VMware 和以AWS 为代表的IaaS云服务商叫苦连天。OpenStack该做的不是去抱怨『既生瑜,何生亮』,而应该是反思为什么OpenStack没能做好容器的底层架构。
以 AWS 为例,它有两个容器相关项目,一个是它自研的ECS,这是一个Docker 容器管理服务,容器运行在EC2主机上。另一个是EKS,是一个Kubernetes 运行环境的创建和管理服务。AWS 为了支撑容器,主要做了几件事情:1. 创造了 amazon-ecs-cni-plugin 项目,使得容器可以很好地运行在VPC 中。2. 打通了用户权限,用户可以使用 AWS 的账号登录到 Kubernetes 环境中。3. 实现了一套Docker 容器管理服务,以及K8S管理节点。
反观 OpenStack 对容器的支持,它主要做了几件事情,一是大张旗鼓搞 Magnum 项目,花很大力气做K8S 环境的编排。另一个是有几个网络相关的项目,但是好像也没什么人在用。
结果就是,在OpenStack 环境中,K8S 环境的编排也没做好(当然了,要不要在私有云中做K8S 集群的创建和管理,前面有过讨论),K8S 在OpenStack 环境中也运行不好(因为针对K8S的网络、存储都没怎么搞好)。所以,我认为,是OpenStack 没有及时为 K8S 做好支撑,才导致 K8S 和 OpenStack 的分离之势的。
容器
IT里的容器技术是英文单词Linux Container的直译。container这个单词有集装箱、容器的含义(主要偏集装箱意思)。不过,在中文环境下,咱们要交流要传授,如果翻译成“集装箱技术” 就有点拗口,所以结合中国人的吐字习惯和文化背景,更喜欢用容器这个词。不过,如果要形象的理解Linux Container技术的话,还是得念成集装箱会比较好。我们知道,海边码头里的集装箱是运载货物用的,它是一种按规格标准化的钢制箱子。集装箱的特色,在于其格式划一,并可以层层重叠,所以可以大量放置在特别设计的远洋轮船中(早期航运是没有集装箱概念的,那时候货物杂乱无章的放,很影响出货和运输效率)。有了集装箱,那么这就更加快捷方便的为生产商提供廉价的运输服务。因此,IT世界里借鉴了这一理念。早期,大家都认为硬件抽象层基于hypervisor的虚拟化方式可以最大程度上提供虚拟化管理的灵活性。各种不同操作系统的虚拟机都能通过hypervisor(KVM、XEN等)来衍生、运行、销毁。然而,随着时间推移,用户发现hypervisor这种方式麻烦越来越多。为什么?因为对于hypervisor环境来说,每个虚拟机都需要运行一个完整的操作系统以及其中安装好的大量应用程序。但实际生产开发环境里,我们更关注的是自己部署的应用程序,如果每次部署发布我都得搞一个完整操作系统和附带的依赖环境,那么这让任务和性能变得很重和很低下。
Linux Container容器技术的诞生(2008年)就解决了IT世界里“集装箱运输”的问题。Linux Container(简称LXC)它是一种内核轻量级的操作系统层虚拟化技术。Linux Container主要由Namespace和Cgroup两大机制来保证实现。那么Namespace和Cgroup是什么呢?刚才我们上面提到了集装箱,集装箱的作用当然是可以对货物进行打包隔离了,不让A公司的货跟B公司的货混在一起,不然卸货就分不清楚了。那么Namespace也是一样的作用,做隔离。光有隔离还没用,我们还需要对货物进行资源的管理。同样的,航运码头也有这样的管理机制:货物用什么样规格大小的集装箱,货物用多少个集装箱,货物哪些优先运走,遇到极端天气怎么暂停运输服务怎么改航道等等… 通用的,与此对应的Cgroup就负责资源管理控制作用,比如进程组使用CPU/MEM的限制,进程组的优先级控制,进程组的挂起和恢复等等。
基于上述情况,人们就在想,有没有其他什么方式能让人更加的关注应用程序本身,底层多余的操作系统和环境我可以共享和复用?换句话来说,那就是我部署一个服务运行好后,我再想移植到另外一个地方,我可以不用再安装一套操作系统和依赖环境。这就像集装箱运载一样,我把货物一辆兰博基尼跑车(好比开发好的应用APP),打包放到一容器集装箱里,它通过货轮可以轻而易举的从上海码头(CentOS7.2环境)运送到纽约码头(Ubuntu14.04环境)。而且运输期间,我的兰博基尼(APP)没有受到任何的损坏(文件没有丢失),在另外一个码头卸货后,依然可以完美风骚的赛跑(启动正常)。
Kubernetes 项目所擅长的,是按照用户的意愿和整个系统的规则,完全自动化地处理好容器之间的各种关系。这种功能,就是我们经常听到的一个概念:编排。所以说,Kubernetes 项目的本质,是为用户提供一个具有普遍意义的容器编排工具。不过,更重要的是,Kubernetes 项目为用户提供的不仅限于一个工具。它真正的价值,乃在于提供了一套基于容器构建分布式系统的基础依赖
容器云以容器为资源分割和调度的基本单位,封装整个软件运行时环境,为开发者和系统管理员提供用于构建,发布和运行分布式应用的平台。当容器云专注于资源共享与隔离、容器编排与部署,它更接近传统的IaaS;当容器云渗透到应用支撑与运行时环境时,它更接近与传统的PaaS.
Kubernetes(k8s)是Google开源的容器集群管理系统(谷歌内部:Borg),它主要用于 容器编排 启动容器、自动化部署、扩展和管理容器应用和回收容器。k8s的目标是让部署容器化的应用简单并且高效,k8s提供了应用部署、规划、更新、维护的一种机制!
Kubernetes(k8s)是Google开源的容器集群管理系统,是一个开源的平台,可以实现容器集群的自动化部署、自动扩缩容、维护等功能。
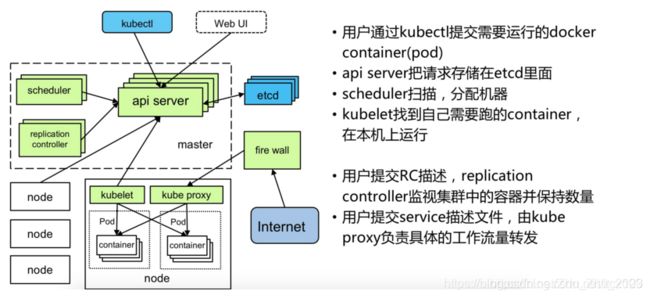
架构上类似于主从结构,master和多Node的关系,其中master主要负责管理集群,提供集群的资源数据访问入口,主要的就是api server、scheduler和replication controller。主要概念有:
- Replication Controlle:实现弹性伸缩、动态扩容和滚动升级的核心,用于制作pod的克隆,提供扩缩容逻辑支持。
- Node:pod在node上运行,包含有pod、container、kubelet、kube proxy.Node是Kubernetes集群操作的单元,用来承载被分配Pod的运行,是Pod运行的宿主机。
- kubelet:负责对Pod对于的容器的创建、启停等任务
- kube-proxy:实现Kubernetes Service的通信与负载均衡机制的重要组件
- Pod:Kurbernetes进行创建、调度和管理的最小单位,它提供了比容器更高层次的抽象,使得部署和管理更加灵活,可以包含一个或多个容器。
- service:一个service有一个IP地址,可以通过这个serviceIP定位具体的pod
自主研发容器编排引擎我们也考虑过,但是经过认真的探讨,自研编排引擎对标三个开源的组件的功能,研发投入需要很多的成本,可能结果并不能达到预期,投入产出比低。另外,容器云作为底层的基础设施,选择更要慎重,如果自研项目失败,可能会离主流的容器技术越来越远,机会成本太高,所以自研的路线也被否定。Kubernetes是我们的最终选择,它当时是1.0.2版本,已经是"Production Ready",我们选择Kubernetes的最主要的原因是它理念的先进,而且非常适合我们公司的主流应用,Java Web应用都是Long time running的任务,Kubernetes的"Replication controller"对它支持非常好。Kubernetes以应用为中心的理念和社区的活跃度更是坚定了我们的选择,历时三个月的技术选型终于落下帷幕,我们决定使用Kubernetes构建我们的私有容器云平台。
SDS
软件定义存储的概念很大。我们所熟知的,存储虚拟化、Server SAN、超融合架构(HCI)都是SDS的一部分。
SNIA之SDS全局示意图
存储管理
将来自服务器本地的闪存盘、机械盘,存储阵列,JBOD等存储资源,通过存储管理协议(如SMI-S等),进行特性描述和虚拟化,构建出存储资源池。
数据服务
存储资源池化后,数据服务即可按照用户对存储服务级别(如金银铜)的要求提供。数据服务包含:空间部署、数据保护、数据可用性、性能、数据安全性。
数据请求
存储资源的使用者,如软件开发人员通过数据管理接口(如CDMI),向SDS发起数据请求。由于SDS开放了丰富的API供调用,因此SDS能够满足用户的数据请求,按照服务级别,提供相应的存储资源。
SDS Control Plane
VMware SPBM (Storage Policy Base Management, 基于存储策略的管理);
OpenStack Cinder 。Cinder是OpenStack云平台的一个组件,用来提供块存储服务;
EMC ViPR。目标是实现EMC存储、异构存储、商用硬件本地存储资源的存储虚拟化(包括互操作性);
ProphetStor (希智)的Federator;
FalconStor(飞康)的 Freestor;
SDS Data Plane
- Based on Commodity Hardware (基于商用的硬件)
参考软件定义存储(SDS)的定义及其分类,超融合架构(HCI)是Server SAN的一个子集。
超融合架构里,比较著名的有: VMware VSAN或EVO:RAIL、EMC ScaleIO、Nutanix、Maxta、SimpliVity、Scale Computing、Pivot3;国内有:华为FusionStorage、志凌海纳SmartX、青云HCI、深信服HCI等;开源的有Open vStorage(类似Nutanix架构);
在Server SAN里,非超融合架构(也即不提供计算资源)的有DELL Fluid Cache、HP StorVirtual、RedHat Inktank Ceph、Microsoft Storage Spaces等,以及达沃时代、StorWind、大道运行SSAN等;还包括分布式文件系统,如GPFS、Lustre、Panasas等;
笔者认为Server SAN在它的原始定义里,应该是一个横向扩展的分布式存储,它至少需要支持3个以上节点。这样,对于那些仅支持两个控制器做为集群的存储,就不在Server SAN这个分类里了。不过,它们依然属于软件定义存储这个大的分类里。这类存储有:DataCore、Nexenta、国内的InfoCore(信核),还有其他支持Solaris ZFS的存储,如开源的FreeNAS、NAS4Free。
分布式存储/分布式文件系统
分布式文件系统设计目标
- 大文件冷数据,比如片库
- 并行读写,高though put,比如HPC 和视频在线编辑
- 海量write once read many 的小文件
- mapreduce 或者ml /dl 任务的输入和输出
数据分布影响到系统的读写时延、负载均衡、可靠性、可用性、并发性能、可扩展性以及数据恢复等方面。通常数据分布有两种方式,partition和replication。
常见开源的分布式文件系统
- GlusterFS
- Cephfs
- Lustre
- HDFS
- mooseFS
- FastDFS
- ContainerFS
技术原理
- 分布式文件系统将数据存储在物理上分散的多个存储节点上,对这些节点的资源进行统一的管理与分配,并向用户提供文件系统访问接口,其主要解决了本地文件系统在文件大小、文件数量、打开文件数等的限制问题。
- 分布式文件系统架构上包含元数据服务器,通常会配置备用主控服务器以便在故障时接管服务,多个存储节点,以及多个客户端,客户端可以是各种应用服务器,也可以是终端用户。
- 元数据服务器管理命名空间,命名空间结构主要分为目录树结构和扁平化结构。元数据服务器还要管理存储节点,可通过轮询存储节点或由存储节点报告心跳的方式实现。
- 元数据可以持久化在元数据服务器上,也可以每次开机由存储节点汇报。
- 除了一些周期性线程任务外,元数据服务器需要服务来自客户端和存储节点的请求,通常的服务模型包括单线程、每请求一线程、线程池,通常配合任务队列。
- 数据服务器负责文件数据在本地的持久化存储,最简单的方式是将客户每个文件数据分配到一个单独的存储节点上作为一个本地文件存储,但这种方式并不能很好的利用分布式文件系统的并行特性,很多文件系统使用固定大小的块来存储数据,典型的块大小为64M。对于小文件的存储,可以将多个文件的数据存储在一个块中,并为块内的文件建立索引,这样可以极大的提高存储空间利用率。
- 用户最终通过文件系统提供的接口来存取数据,linux环境下,最好莫过于能提供POSIX接口的支持,这样很多应用能不加修改的将本地文件存储替换为分布式文件存储,实现文件系统POSIX接口,一种方式时按照VFS接口规范实现文件系统,这种方式需要文件系统开发者对内核有一定的了解;另一种方式是借助FUSE。
Ceph
Ceph 的初创来自Sage Weil 博士的 PhD 论文,论文 “Ceph: A Scalable, High-Performance Distributed File System”详细的阐述了 Ceph 的设计架构(论文网址:https://www.ssrc.ucsc.edu/Papers/weil-osdi06.pdf)。ceph的特性包括:可靠性的、可扩展的、统一的、分布式的存储系统。ceph可以提供对象存储、块存储、和文件系统3种功能。
在Ceph存储中,包含以下几个核心组件,分别是Ceph OSD;Ceph Monitor和Ceph MDS。
Ceph OSD:全称是Object Storage Device,主要功能包括存储数据,处理数据的复制、恢复、回补、平衡数据分布,并将一些相关数据提供给Ceph Monitor,如Ceph OSD心跳等。
Ceph Monitor:Ceph的监控器,主要功能是维护整个集群健康状态,提供一致性的决策,包含Monitor map、OSD map、PG(Placement Group) map和CRUSH map。
Ceph MDS:全称是Ceph Metadata server。主要保存的是Ceph文件系统(File system)的元数据。(Ceph的块存储和对象存储不需要Ceph MDS。Ceph MDS为基于POSIX文件系统的用户提供一些基础命令,如ls,find等命令)。
pg 到OSD的映射的过程算法叫做crush 算法,这个算法是一个伪随机的过程,他可以从所有的OSD中,随机性选择一个OSD集合,但是同一个PG每次随机选择的结果是不变的,也就是映射的OSD集合是固定的。crush 因子:OSDMap管理当前ceph中所有的OSD,OSDMap规定了crush算法的一个范围,在这个范围中选择OSD结合。那么影响crush算法结果的有两种因素,一个就是OSDMap的结构,另外一个就是crush rule。
超融合HCI
超融合基础架构(hyper-converged infrastructure)是一个软件定义的 IT 基础架构,它可虚拟化常见“硬件定义”系统的所有元素。HCI 包含的最小集合是:虚拟化计算(hypervisor),虚拟存储(SDS)和虚拟网络。HCI 通常运行在标准商用服务器之上。超融合特点:全虚拟化、提供了计算资源否则就是分布式存储
DevOps
DevOps(Development和Operations的组合词)是一种重视“软件开发人员(Dev)”和“IT运维技术人员(Ops)”之间沟通合作的文化、运动或惯例。透过自动化“软件交付”和“架构变更”的流程,来使得构建、测试、发布软件能够更加地快捷、频繁和可靠。–维基百科
DevOps(英文Development和Operations的组合)是一组过程、方法与系统的统称,用于促进开发(应用程序/软件工程)、技术运营和质量保障(QA)部门之间的沟通、协作与整合。它的出现是由于软件行业日益清晰地认识到:为了按时交付软件产品和服务,开发和运营工作必须紧密合作。–百度百科
DevOps 的技术栈与工具链
Everything is Code,DevOps 也同样要通过技术工具链完成持续集成、持续交付、用户反馈和系统优化的整合。Elasticbox 整理了 60+ 开源工具与分类,其中包括版本控制&协作开发工具、自动化构建和测试工具、持续集成&交付工具、部署工具、维护工具、监控,警告&分析工具等等,补充了一些国内的服务,可以让你更好的执行实施 DevOps 工作流。
版本控制&协作开发:GitHub、GitLab、BitBucket、SubVersion、Coding、Bazaar
自动化构建和测试:Apache Ant、Maven 、Selenium、PyUnit、QUnit、JMeter、Gradle、PHPUnit
持续集成&交付:Jenkins、Capistrano、BuildBot、Fabric、Tinderbox、Travis CI、flow.ci Continuum、LuntBuild、CruiseControl、Integrity、Gump、Go
容器平台: Docker、Rocket、Ubuntu(LXC)、第三方厂商如(AWS/阿里云)
配置管理:Chef、Puppet、CFengine、Bash、Rudder、Powershell、RunDeck、Saltstack、Ansible
微服务平台:OpenShift、Cloud Foundry、Kubernetes、Mesosphere
服务开通:Puppet、docker Swarm、Vagrant、Powershell、OpenStack Heat
日志管理:Logstash、CollectD、StatsD
监控,警告&分析:Nagios、Ganglia、Sensu、zabbix、ICINGA、Graphite、Kibana
国内存储厂商
成熟的软件生态,一线城市的人才,前沿的技术,这些厂商会不会有一天直接把我们降维打击了呢。。。
QINGCLOUD 青云QingCloud
产品,

解决方案,

SmartX
产品,
解决方案,
XSKY星辰天合
产品,

解决方案,

分布式服务/分布式系统
业界的互联网巨头公司,都有属于自己的分布式服务框架,如阿里巴巴的Dubbo,HSF,腾讯的Tars,京东的JSF,新浪的Motan,都已经是业界非常成熟的解决方案,其中开源的Dubbo和Motan受到了广大开发者的研究对象。
服务治理型
dubbo
dubbox
motan
多语言型
grpc
thrift
avro
Protocol Buffers (google)
分布式服务框架一般可以分为以下几个部分,
(1)RPC基础层:
包括底层通信框架,如NIO框架、通信协议,序列化和反序列化协议,
以及在这几部分上的封装,屏蔽底层通信细节和序列化方式差异
(2)服务发布/消费:
服务提供者根据消费者请求消息中的接口名,方法名,参数列表等信息,通过Java反射,调用本地的接口实现类;
服务消费者将服务提供者发布的接口封装成远程服务调用;
(3)服务调用链:
在服务调用的职责链中,通过在调用链切面的编码完成相关的监控和扩展,如负载均衡,服务调用性能统计,调用完成通知,
失败重发等功能
(4)服务注册中心:
注册中心负责服务的发布和通知,需要支持服务的平滑上线下线等
(5)服务治理中心:
服务治理中心是一个可视化的模块,提供对服务的可视化分析和维护,包括服务运行状态,调用关系和健康度等。最上层是为服务治理的UI界面,提供在线、配置化的治理界面供运维人员使用。SDK层是提供了微服务治理的各种接口,供服务治理Portal调用。最下面的就是被治理的微服务集群,集群各节点会监听服务治理的操作去做实时刷新。例如:修改了流控阈值之后,服务治理服务会把新的流控的阈值刷到服务注册中心,服务提供者和消费者监听到阈值变更之后,获取新的阈值并刷新到内存中,实现实时生效。由于目前服务治理策略数据量不是特别大,所以可以将服务治理的数据放到服务注册中心(例如etcd/ZooKeeper),没有必要再单独做一套。
etcd/ZooKeeper
etcd 使用 RAFT 算法实现的一致性,比 zookeeper 的 ZAB 算法更简单。etcd 没有使用 zookeeper 的树形结构,而是提供了一个分布式的 key-value 存储。
zookeeper 是用 java 开发的,被 Apache 很多项目采用。etcd 是用 go 开发的,主要是被 Kubernetes 采用。zookeeper 非常稳定,是一个著名的分布式协调系统,etcd 是后起之秀,前景广阔。因为 etcd 是用 go 写的,现在还没有很好的 java 客户端库,需要通过 http 方式调用。而 zookeeper 在这方面就成熟很多,对于 java 之外的其他开发语言都有很好的客户端库。具体选择 zookeeper 还是 etcd,需要根据您的需求结合它们各自的特性进行判断,还有您所使用的开发语言。
之前在使用etcd的时候,只是在官网看到了分布式存储,就默认它为一个存储组件,导致了对etcd的误解,这也是第一次用到的时候没有深入了解导致的,在经过和Zookeeper的比较学习之后,发现两者在很多方面有着相同的特性。以前我对Zookeeper也有一定的误解,以为它是一个协调者,一定有管理的功能,可以控制很多东西,但经过这番学习之后,发现其实Zookeeper本质上也是一个存储单元,用于存放配置信息,解决分布式中的读写一致性问题。总的来说,etcd和Zookeeper有相似的功能,做的事情也大同小异,只是可能具体的应用场景不太一样,我目前的了解是Zookeeper主要用于Hadoop组件的协调上,etcd主要用与Kubernetes上对于容器的协调上,两者都是用于存放配置信息等元数据的,随着以后的深入学习,希望可以慢慢把他们的区别理清晰。不得不承认,作为后起之秀,Etcd在watch方面完胜ZooKeeper。从功能的角度来看,Etcd只需要调用一次watch操作就可以捕捉所有的事件,相比ZooKeeper大大简化了客户端开发者的工作量。ZooKeeper的watch获得的channel只能使用一次,而Etcd的watch获得的channel可以被复用,新的事件通知会被不断推送进来,而无需客户端重复进行watch,这种行为也更符合我们对go channel的预期。 ZooKeeper对事件丢失的问题没有解决办法。Etcd则提供了版本号帮助客户端尽量捕捉每一次变化。要注意的是每一次变化都会产生一个新的版本号,而这些版本不会被永久保留。Etcd会根据其版本留存策略定时将超出阈值的旧版本从版本历史中清除。从开发者的角度来看,ZooKeeper是用Java写的,且使用了自己的TCP协议。对于程序员来说不太友好,如果离开了ZooKeeper提供的SDK自己写客户端会有一定的技术壁垒,而ZooKeeper官方只提供了Java和C语言的SDK,其它语言的开发者就只能去寻求第三方库的帮助,比如github.com/samuel/go-zookeeper/zk。另一方面,Etcd是用Go写的,使用了Google的gRPC协议,官方除了提供Go语言的SDK之外,也提供了Java的SDK:https://github.com/etcd-io/jetcd。另外Etcd官方还维护了一个zetcd项目:https://github.com/etcd-io/zetcd,它在Etcd外面套了一个ZooKeeper的壳。让那些ZooKeeper的客户端可以无缝移植到Etcd上。有兴趣的小伙伴可以尝试一下。
Zookeeper 能够很容易的实现集群管理的功能,如有多台 Server 组成一个服务集群,那么必须要一个”总管”知道当前集群中每台机器的服务状态,一旦有机器不能提供服务,集群中其它集群必须知道,从而做出调整重新分配服务策略。同样当增加集群的服务能力时,就会增加一台或多台 Server,同样也必须让”总管”知道。Zookeeper 不仅能够帮你维护当前的集群中机器的服务状态,而且能够帮你选出一个”总管”,让这个总管来管理集群,这就是 Zookeeper 的另一个功能 Leader Election。它们的实现方式都是在 Zookeeper 上创建一个 EPHEMERAL 类型的目录节点,然后每个 Server 在它们创建目录节点的父目录节点上调用 getChildren(String path, boolean watch) 方法并设置 watch 为 true,由于是 EPHEMERAL 目录节点,当创建它的 Server 死去,这个目录节点也随之被删除,所以 Children 将会变化,这时 getChildren 上的 Watch 将会被调用,所以其它 Server 就知道已经有某台 Server 死去了。新增 Server 也是同样的原理。Zookeeper 如何实现 Leader Election,也就是选出一个 Master Server。和前面的一样每台 Server 创建一个 EPHEMERAL 目录节点,不同的是它还是一个 SEQUENTIAL 目录节点,所以它是个 EPHEMERAL_SEQUENTIAL 目录节点。之所以它是 EPHEMERAL_SEQUENTIAL 目录节点,是因为我们可以给每台 Server 编号,我们可以选择当前是最小编号的 Server 为 Master,假如这个最小编号的 Server 死去,由于是 EPHEMERAL 节点,死去的 Server 对应的节点也被删除,所以当前的节点列表中又出现一个最小编号的节点,我们就选择这个节点为当前 Master。这样就实现了动态选择 Master,避免了传统意义上单 Master 容易出现单点故障的问题。
一致性协议
Paxos协议的难以理解的名声似乎跟它本身一样出名。为此,Stanford大学的博士生Diego Ongaro甚至把对Paxos协议的研究作为了博士课题。他在2014年秋天正式发表了博士论文:“CONSENSUS: BRIDGING THEORY AND PRACTICE”,在这篇博士论文中,他给出了分布式一致性协议的一个实现算法,即Raft。由于这篇博士论文很长(257页),可能是为了便于别人阅读和理解,他在博士论文正式发表之前,即2014年初,把Raft相关的部分摘了出来,形成了一篇十多页的文章:“In Search of an Understandable Consensus Algorithm”,即人们俗称的Raft论文。Raft算法给出了分布式一致性协议的一个比较简单的实现,到目前为止并没有人挑战这个算法的正确性。然而,OceanBase却没有采用Raft算法,这并非是OceanBase团队同学不懂Raft,而是Raft的一个根本性的局限对数据库的事务有很大的风险。使用multi paxos可以享受到乱序提交日志带来的可用性和同步性能的提升。而OceanBase选择做,是因为已工程实现稳定的raft,对paxos已经有很深入理解。抖机灵做个比喻,raft与multi paxos就是原子弹与氢弹的关系,解锁multi paxos需要先点满raft,技术难度差一个数量级,而且业界没有可参考的实现。