2020 BAT大厂数据挖掘面试经验:“高频面经”之数据结构与算法篇
注:数据结构与算法为面试基础,基本上所有岗位都有涉及,面试中侧重核心思路阐述和手撕代码。以下试题为作者日常整理的通用高频面经,包含题目,答案与参考文章,欢迎纠正与补充。
其他相应高频面试题可参考如下内容:
2020 BAT大厂数据分析面试经验:“高频面经”之数据分析篇
2020 BAT大厂数据开发面试经验:“高频面经”之大数据研发篇
2020 BAT大厂机器学习算法面试经验:“高频面经”之机器学习篇
2020 BAT大厂深度学习算法面试经验:“高频面经”之深度学习篇
目录
1.什么是链表、队列、堆栈、树图?
2.删除链表中重复的节点(剑指offer 83)
3.两数相加(Leetcode 2)
4.反转链表、环形链表、合并链表
5.创建包含min函数的栈
6.二叉树的最大(最小)树深
7.二叉树的遍历
8.通过前序和中序推后序(重建二叉树)
9.二叉树的最近公共祖先(leetcode 236)
10.电话号码的字母组合(leetcode 17)
11.求1+2+...+n(剑指offer 47)
12.有效括号(leetcode 20)
13.最长公共前缀(leetcode 14)
14.排序算法有哪些?
15.快速排序实现
16.求TopK(堆排序)
17.01背包(动态规划)
18.数据流中的中位数(剑指offer 63)
19.买卖股票的最佳时机(leetcode 121)
20.矩阵中的最短路径(剑指offer 65)
1.什么是链表、队列、堆栈、树图?
链表:创建链表的过程和创建数组的过程不同,不会先划出一块连续的内存。因为链表中的数据是不连续的,链表在存储数据的内存中有两块区域,一块区域用来存储数据,一块区域用来记录下一个数据保存在哪里(指向下一个数据的指针)。当有数据进入链表时候,会根据指针找到下一个存储数据的位置,然后把数据保存起来,然后再指向下一个存储数据的位置。这样链表就把一些碎片空间利用起来了,虽然链表是线性表,但是并不会按线性的顺序存储数据。

队列:队列是一种先进先出的数据结构,数组和链表也都可以生成队列。当数据进入到队列中时也是先进入的在下面后进入的再上面,但是出队列的时候是先从下面出,然后才是上面的数据出,最晚进入的队列的,最后出。

堆:堆是一颗完全二叉树。在这棵树中,所有父节点都满足大于等于其子节点的堆叫大根堆。所有父节点都满足小于等于其子节点的堆叫小根堆。堆虽然是一颗树,但是通常存放在一个数组中,父节点和孩子节点的父子关系通过数组下标来确定。
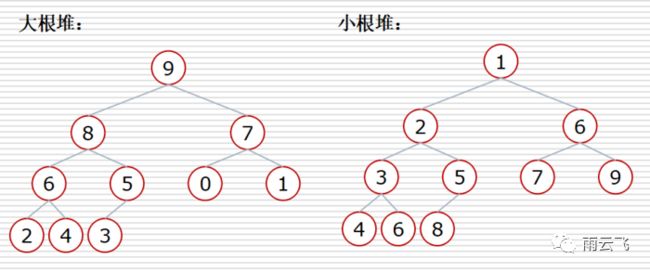
栈:栈是一种先进后出的数据结构,数组和链表都可以生成栈。当数据进入到栈时会按照规则压入到栈的底部,再次进入的数据会压在第一次的数据上面,以此类推,在取出栈中的数据的时候会先取出最上面的数据,所以是先进后出。
由于数组和链表都可以组成栈,所以操作特点就需要看栈是由数组还是链表生成的了,然后就会继承相应的操作特点。

树: 此处树特指二叉树(BinaryTree)。二叉树是n(n>=0)个结点的有限集合,该集合或者为空集(空二叉树),或者由一个根结点和两棵互不相交的、分别称为根结点的左子树和右子树的二叉树组成。二叉树的特点:
-
每个结点最多有两棵子树。(注意:不是都需要两棵子树,而是最多可以是两棵,没有子树或者有一棵子树也都是可以的。)
-
左子树和右子树是有顺序的,次序不能颠倒。
-
即使树中某结点只有一棵子树,也要区分它是左子树还是右子树,下面是完全不同的二叉树:
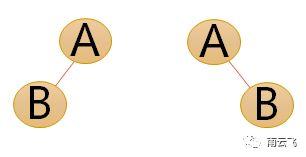
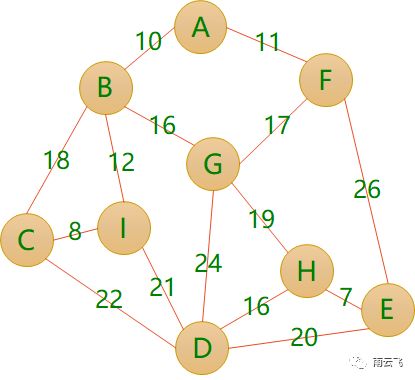
图:图(Graph)是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E),其中,G表示一个图,V是图G中顶点的集合,E是图G中边的集合。图有各种形状和大小。边可以有权重(weight),即每一条边会被分配一个正数或者负数值。
参考链接:
https://www.cnblogs.com/jimoer/p/8783604.html
2.删除链表中重复的节点(剑指offer 83)
递归解法:
# -*- coding:utf-8 -*-# class ListNode:# def __init__(self, x):# self.val = x# self.next = Noneclass Solution: # 递归def deleteDuplication(self, pHead):# write code hereif pHead == None:return Noneif pHead.next == None:return pHeadif pHead.val != pHead.next.val:pHead.next = self.deleteDuplication(pHead.next)return pHead # 后面的节点递归结束后,返回pHead即可else:tempNode = pHeadwhile tempNode and tempNode.val == pHead.val:tempNode = tempNode.nextreturn self.deleteDuplication(tempNode)# 重复节点都不留,不保留pHead,直接返回下一个不同节点的递归结点。
循环解法:
# -*- coding:utf-8 -*-# class ListNode:# def __init__(self, x):# self.val = x# self.next = Noneclass Solution:def deleteDuplication(self, pHead):# write code herefirst = ListNode(-1) # 为了避免重复,在链表开始之前新建一个头结点。first.next = pHeadcurr = pHead # 作为遍历链表的指针pre = first # 记录不重复节点之前的最后信息while curr and curr.next:if curr.val != curr.next.val: # 当前节点不重复,继续往下走curr = curr.nextpre = pre.nextelse: # 如果重复,找到不重复节点为止。val = curr.valwhile curr and curr.val == val:curr = curr.nextpre.next = curr# 这里直接令pre.next等于第一个与当前元素不重复的节点即可,# 不用管这个节点也是重复节点,因为pre一定不重复,且被固定了下来,# 是不变的,如果这个节点也是重复节点,pre.next会再次更新。return first.next
参考链接:
https://blog.csdn.net/ggdhs/article/details/90447401
3.两数相加(Leetcode 2)
给出两个非空的链表用来表示两个非负的整数。其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储一位数字。如果,我们将这两个数相加起来,则会返回一个新的链表来表示它们的和。
您可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例:
输入:(2 -> 4 -> 3) + (5 -> 6 -> 4)
输出:7 -> 0 -> 8
原因:342 + 465 = 807
# Definition for singly-linked list.# class ListNode:# def __init__(self, x):# self.val = x# self.next = Noneclass Solution:def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode:result = ListNode(0)result_tail = resultcarry = 0while l1 or l2 or carry:v1 = l1.val if l1 else 0v2 = l2.val if l2 else 0num = v1 + v2 + carrycarry = num // 10result_tail.next = ListNode(num % 10)result_tail = result_tail.nextl1 = l1.next if l1 else Nonel2 = l2.next if l2 else Nonereturn result.next
4.反转链表、环形链表、合并链表
反转链表(Leetcode 206):
# Definition for singly-linked list.# class ListNode:# def __init__(self, x):# self.val = x# self.next = Noneclass Solution:def reverseList(self, head):if not head:return Nonelast = Nonewhile head:tmp = head.nexthead.next = lastlast = headhead = tmpreturn last
环形链表(leetcode 141):
# Definition for singly-linked list.# class ListNode(object):# def __init__(self, x):# self.val = x# self.next = Noneclass Solution(object):def hasCycle(self, head):""":type head: ListNode:rtype: bool"""if head is None or head.next is None or head.next.next is None:return Falseslow = head.nextfast = head.next.nextwhile slow != fast and fast is not None and fast.next is not None:slow = slow.nextfast = fast.next.nextif fast == slow:return Trueelse:return False
合并链表(leetcode 21):
class Solution(object):def mergeTwoLists(self, l1, l2):""":type l1: ListNode:type l2: ListNode:rtype: ListNode"""if l1 == None:return l2if l2 == None:return l1dummy = ListNode(-1)cur = dummywhile l1 and l2:if l1.val < l2.val:cur.next = l1l1 = l1.nextelse:cur.next = l2l2 = l2.nextcur = cur.nextif l1:cur.next = l1else:cur.next = l2return dummy.next
5.创建包含min函数的栈
# -*- coding:utf-8 -*-class Solution:def __init__(self):self.stack = []self.minstack = []self.minm = float('inf')def push(self, node):# write code hereif node < self.minm:self.minm = nodeself.minstack.append(self.minm)self.stack.append(node)def pop(self):# write code hereif self.stack != []:if self.stack[-1] == self.minm:self.minstack.pop()self.stack.pop(-1)def top(self):# write code hereif self.stack != []:return self.stack[-1]else:return Nonedef min(self):# write code herereturn self.minstack[-1]
6.二叉树的最大(最小)树深
二叉树的最大树深:
class Solution:def maxDepth(self, root):""":type root: TreeNode:rtype: int"""if root is None:return 0else:left_height = self.maxDepth(root.left)right_height = self.maxDepth(root.right)return max(left_height, right_height) + 1
二叉树的最小树深:
# Definition for singly-linked list.# class ListNode:# def __init__(self, x):# self.val = x# self.next = Noneclass Solution:def minDepth(self, root):""":type root: TreeNode:rtype: int"""# 边界条件if not root:return 0if not root.left and root.right is not None:return self.minDepth(root.right)+1if root.left is not None and not root.right:return self.minDepth(root.left)+1# 递归求解左子树和右子树最小深度left = self.minDepth(root.left)+1right = self.minDepth(root.right)+1return min(left,right)
7.二叉树的遍历
二叉树的层次遍历:
# Definition for a binary tree node.# class TreeNode(object):# def __init__(self, x):# self.val = x# self.left = None# self.right = Noneclass Solution(object):def levelOrder(self, root):""":type root: TreeNode:rtype: List[List[int]]"""queue = [root]res = []if not root:return []while queue:templst = []templen = len(queue)for i in range(templen):temp = queue.pop(0)templst.append(temp.val)if temp.left:queue.append(temp.left)if temp.right:queue.append(temp.right)res.append(templst)return res
二叉树的前(中、后)序遍历:
# Definition for a binary tree node.# class TreeNode(object):# def __init__(self, x):# self.val = x# self.left = None# self.right = Noneclass Solution(object):def preorderTraversal(self, root):""":type root: TreeNode:rtype: List[int]"""if not root:return []res = []# 前序遍历# -----------------------------------------------res.append(root.val)res.extend(self.preorderTraversal(root.left))res.extend(self.preorderTraversal(root.right))# -----------------------------------------------# 中序遍历# -----------------------------------------------# res.extend(self.preorderTraversal(root.left))# res.append(root.val)# res.extend(self.preorderTraversal(root.right))# -----------------------------------------------# 后序遍历# -----------------------------------------------# res.extend(self.preorderTraversal(root.left))# res.extend(self.preorderTraversal(root.right))# res.append(root.val)# -----------------------------------------------return res
8.通过前序和中序推后序(重建二叉树)
题目:输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序列{4,7,2,1,5,3,8,6},则重建二叉树并返回。
class TreeNode:def __init__(self, x):self.val = xself.left = Noneself.right = Noneclass Solution:# 返回构造的TreeNode根节点def reConstructBinaryTree(self, pre, tin):# write code hereif len(pre)==0:return Noneroot=TreeNode(pre[0])TinIndex=tin.index(pre[0])root.left=self.reConstructBinaryTree(pre[1:TinIndex+1], tin[0:TinIndex])root.right=self.reConstructBinaryTree(pre[TinIndex+1:], tin[TinIndex+1:])return rootdef PostTraversal(self,root): #后序遍历if root != None:self.PostTraversal(root.left)self.PostTraversal(root.right)print(root.val)
参考链接:
https://blog.csdn.net/songyunli1111/article/details/80138757
9.二叉树的最近公共祖先(leetcode 236)
class Solution:def lowestCommonAncestor(self, root, A, B):# A&B=>LCA# !A&!B=>None# A&!B=>A# B&!A=>B# 若root为空或者root为A或者root为B,说明找到了A和B其中一个if(root is None or root==A or root==B):return rootleft=self.lowestCommonAncestor(root.left,A,B)right=self.lowestCommonAncestor(root.right,A,B)# 若左子树找到了A,右子树找到了B,说明此时的root就是公共祖先if left and right :return root# 若左子树是none右子树不是,说明右子树找到了A或Bif not left:return right# 若右子树是none左子树不是,说明左子树找到了A或Bif not right:return leftreturn None
10.电话号码的字母组合(leetcode 17)
class Solution:def letterCombinations(self, digits: str) -> List[str]:if not digits:return []L1 = [""]L2 = []h = {"2": "abc", "3": "def", "4": "ghi", "5": "jkl", "6": "mno","7": "pqrs", "8": "tuv", "9": "wxyz"}for char in digits:L1 = [each + i for each in L1 for i in h[char]]return L1
11.求1+2+...+n(剑指offer 47)
要求:不能使用乘除法、for、while、if、else、switch、case等关键字以及条件判断语句(A?B:C)
思路:使用递归f(n) = f(n-1) + n, 但是不能使用if进行递归出口的控制,因此利用python中and的属性,即and判断都为真的话输出and后面的那个数字
class Solution:def Sum_Solution(self, n):# write code hereans = (n>0) and nreturn ans and self.Sum_Solution(n-1)+ans
12.有效括号(leetcode 20)
class Solution:def isValid(self, s):""":type s: str:rtype: bool"""leftP = '([{'rightP = ')]}'stack = []for char in s:if char in leftP:stack.append(char)if char in rightP:if not stack:return Falsetmp = stack.pop()if char == ')' and tmp != '(':return Falseif char == ']' and tmp != '[':return Falseif char == '}' and tmp != '{':return Falsereturn stack == []
13.最长公共前缀(leetcode 14)
class Solution(object):def longestCommonPrefix(self, strs):""":type strs: List[str]:rtype: str"""if not strs:return ""for i in range(len(strs[0])):for str in strs:if len(str) <= i or strs[0][i] != str[i]:return strs[0][:i]return strs[0]
14.排序算法有哪些?

参考链接:
https://blog.csdn.net/wfq784967698/article/details/79551476
15.快速排序实现
def quick_sort(alist, start, end):"""快速排序"""if start >= end: # 递归的退出条件returnmid = alist[start] # 设定起始的基准元素low = start # low为序列左边在开始位置的由左向右移动的游标high = end # high为序列右边末尾位置的由右向左移动的游标while low < high:# 如果low与high未重合,high(右边)指向的元素大于等于基准元素,则high向左移动while low < high and alist[high] >= mid:high -= 1alist[low] = alist[high] # 走到此位置时high指向一个比基准元素小的元素,将high指向的元素放到low的位置上,此时high指向的位置空着,接下来移动low找到符合条件的元素放在此处# 如果low与high未重合,low指向的元素比基准元素小,则low向右移动while low < high and alist[low] < mid:low += 1alist[high] = alist[low] # 此时low指向一个比基准元素大的元素,将low指向的元素放到high空着的位置上,此时low指向的位置空着,之后进行下一次循环,将high找到符合条件的元素填到此处# 退出循环后,low与high重合,此时所指位置为基准元素的正确位置,左边的元素都比基准元素小,右边的元素都比基准元素大alist[low] = mid # 将基准元素放到该位置,# 对基准元素左边的子序列进行快速排序quick_sort(alist, start, low - 1) # start :0 low -1 原基准元素靠左边一位# 对基准元素右边的子序列进行快速排序quick_sort(alist, low + 1, end) # low+1 : 原基准元素靠右一位 end: 最后
参考链接:
https://blog.csdn.net/weixin_43250623/article/details/88931925
16.求TopK(堆排序)
class Solution:def GetLeastNumbers_Solution(self, tinput, k):n = len(tinput)if k <= 0 or k > n:return list()# 建立大顶堆for i in range(int(k / 2) - 1, -1, -1):self.heapAjust(tinput, i, k - 1)for i in range(k, n):if tinput[i] < tinput[0]:tinput[0], tinput[i] = tinput[i], tinput[0]# 调整前k个数self.heapAjust(tinput, 0, k - 1)print(tinput[:k])def heapAjust(self, nums, start, end):temp = nums[start]# 记录较大的那个孩子下标child = 2 * start + 1while child <= end:# 比较左右孩子,记录较大的那个if child + 1 <= end and nums[child] < nums[child + 1]:# 如果右孩子比较大,下标往右移child += 1# 如果根已经比左右孩子都大了,直接退出if temp >= nums[child]:break# 如果根小于某个孩子,将较大值提到根位置nums[start] = nums[child]# nums[start], nums[child] = nums[child], nums[start]# 接着比较被降下去是否符合要求,此时的根下标为原来被换上去的那个孩子下标start = child# 孩子下标也要下降一层child = child * 2 + 1# 最后将一开始的根值放入合适的位置(如果前面是交换,这句就不要)nums[start] = temp
17.01背包(动态规划)
import numpy as np# 0-1 背包def oneZeroPack(w,v,c):dp = np.zeros((len(w),(c+1)),dtype=np.int32)for i in range(len(w)):for j in range(c+1):if i == 0:dp[i][j] = v[i] if j >= w[i] else 0else:if j >= w[i]:dp[i][j] = max(dp[i-1][j-w[i]]+v[i], dp[i-1][j])else:dp[i][j] = dp[i-1][j]return dp[-1][-1]# 0-1 背包省空间的办法def oneZeroPack2(w,v,c):dp = np.array([0]*(c+1),dtype=np.int32)for i in range(len(w)):for j in range(c,-1,-1):if j >= w[i]:dp[j] = max(dp[j-w[i]]+v[i], dp[j])return dp[-1]
18.数据流中的中位数(剑指offer 63)
限制:n个数组无法完全放在内存中
# -*- coding:utf-8 -*-import heapq# -*- coding:utf-8 -*-class Solution:def __init__(self):self.nums = []def Insert(self, num):# write code hereself.nums.append(num)def GetMedian(self,n=None):# write code hereself.nums.sort()if len(self.nums)%2 == 0:res = (self.nums[len(self.nums)/2]+self.nums[len(self.nums)/2-1])/2.0else:res = self.nums[len(self.nums)//2]return res
19.买卖股票的最佳时机(leetcode 121)
# DC分治算法def max_profit_dc(prices):len_prices = len(prices)if len_prices <= 1: # 边界条件return 0mid = len_prices//2prices_left = prices[:mid]prices_right = prices[mid:]maxProfit_left = max_profit_dc(prices_left) # 递归求解左边序列maxProfit_right = max_profit_dc(prices_right) # 递归求解右边序列maxProfit_left_right = max(prices_right) - min(prices_left) #跨界情况return max(maxProfit_left,maxProfit_right,maxProfit_left_right)
20.矩阵中的最短路径(剑指offer 65)
class Solution:def hasPath(self, matrix, rows, cols, path):assistMatrix = [True]*rows*colsfor i in range(rows):for j in range(cols):if(self.hasPathAtAStartPoint(matrix,rows,cols, i, j, path, assistMatrix)):return Truereturn Falsedef hasPathAtAStartPoint(self, matrix, rows, cols, i, j, path, assistMatrix):if not path:return Trueindex = i*cols+jif i<0 or i>=rows or j<0 or j>=cols or matrix[index]!=path[0] or assistMatrix[index]==False:return FalseassistMatrix[index] = Falseif(self.hasPathAtAStartPoint(matrix,rows,cols,i+1,j,path[1:],assistMatrix) orself.hasPathAtAStartPoint(matrix,rows,cols,i-1,j,path[1:],assistMatrix) orself.hasPathAtAStartPoint(matrix,rows,cols,i,j-1,path[1:],assistMatrix) orself.hasPathAtAStartPoint(matrix,rows,cols,i,j+1,path[1:],assistMatrix)):return TrueassistMatrix[index] = Truereturn False
其他相应高频面试题可参考如下内容:
2020 BAT大厂数据分析面试经验:“高频面经”之数据分析篇
2020 BAT大厂数据开发面试经验:“高频面经”之大数据研发篇
2020 BAT大厂机器学习算法面试经验:“高频面经”之机器学习篇
2020 BAT大厂深度学习算法面试经验:“高频面经”之深度学习篇
欢迎关注作者微信公众号:学习号,涉及数据分析与挖掘、数据结构与算法、大数据与机器学习等内容
