使用scrapy爬取企查查公司工商信息
前言
本文使用python中爬虫框架scrapy爬取企查查公司工商信息,代码禁止商用,纯属交流学习使用,希望看到这篇文章并且觉得对ta有帮助的人,以后也能同样将心得知识分享出来
第一部分
自动化登录
由于不登录,会一直弹出登录的信息,比较烦,所以在正式程序前,先写一个登录程序,企查查的一个优点就是它的cookie值不过期,所以登录后,拿到cookie信息,然后存储为json文件,就可以在后续的程序中使用
import json
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.chrome.options import Options
from selenium.webdriver import ChromeOptions
import time
def normalLogin():
# 无可视化操作
#chrome_options = Options()
#chrome_options.add_argument('--headless')
#chrome_options.add_argument('-disable-gpu')
# 实现让selenium规避被检测的风险
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
# 当前路径下一定要安装谷歌驱动器,或者输入正确的谷歌驱动器位置
browser = webdriver.Chrome(executable_path='./chromedriver.exe', options=option)
# 通过浏览器的dev_tool在get页面将.webdriver属性设置为"undefined"
browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument",{
"source":"""Object.defineProperty(navigator, 'webdriver', {get: () => undefined})""",
})
browser.get('https://www.qichacha.com/g_AH')
browser.maximize_window()
time.sleep(2)
page_login_click = browser.find_element_by_xpath('//a[@class="navi-btn"]/span')
page_login_click.click()
time.sleep(4)
print("打印实时信息")
try:
login_click = browser.find_element_by_id("normalLogin")
except:
login_click = browser.find_element_by_class_name("active")
finally:
login_click.click()
time.sleep(4) # 延时4秒
# 获取滑块的大小
span = browser.find_element_by_id("nc_2_n1z")
span_size = span.size
print("滑块大小为: ", span_size)
# 获取滑块的位置
button = browser.find_element_by_id("nc_2_n1z")
button_location = button.location
print(button_location)
x_location = span_size["width"]
y_location = button_location["y"]
action = ActionChains(browser)
source = browser.find_element_by_id("nc_2_n1z")
action.click_and_hold(source).perform()
action.move_by_offset(308, 0)
action.release().perform()
time.sleep(1)
# 模拟登录
print("登录操作开始")
username_input = browser.find_element_by_id("nameNormal")
username_input.send_keys('你的用户名')
password_input = browser.find_element_by_id("pwdNormal")
password_input.send_keys('你的密码')
time.sleep(2)
# 如果定位的标签存在于iframe中,那么必须通过switch_to.frame对标签定位
# 使用动作链来进行滑块登录操作
login = browser.find_element_by_xpath('//button[@type="submit"]/b')
login.click()
cookies = browser.get_cookies()
browser.close()
# 在当前文件夹中存储cookie为json格式
with open('./cookie03.json', mode='w', encoding='utf-8') as fp:
json_data = json.dump(cookies, fp)
获取城市url
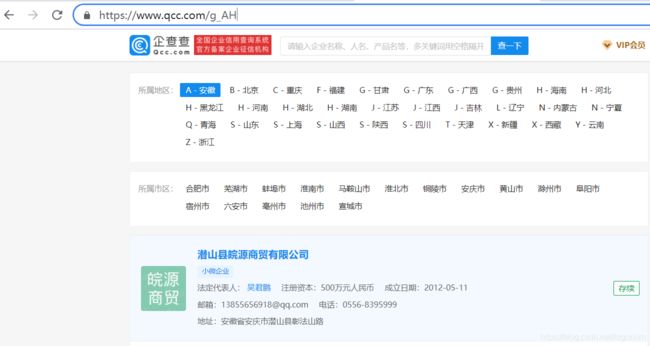
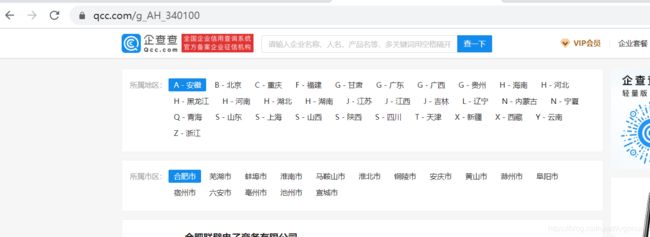
我们可以观察得到每个省份都是主网址+省份缩写,进一步观察可以发现各个城市企业信息也是主网址+省份+城市代码,所以就可以写一个小的python文件先把城市信息得到,并且也存储到本地csv文件中,这个步骤存储到本地,主要是为了省时间,直接从本地读取,肯定比从网站上爬取下载快一些
import requests
import setting
from lxml import etree
import csv
# 获取城市链接,运行一次,直接将各个省份的城市url保存为csv文件
def get_city_url():
# 导入伪装头
headers = setting.HEADERS
# 导入cookie
dic_cookie = 'xxxxxxxx请自行将自己的cookie值填入其中'
# 获取已经爬到的省份链接
province_list_urls = []
with open('./province.csv', mode='r+', encoding='utf-8-sig', newline='') as fp:
for url in fp:
province_list_urls.append(url.strip().split(','))
province_list_urls = province_list_urls[0]
city_list_urls = []
for province_url in province_list_urls:
html = requests.get(url=province_url, cookies=dic_cookie, headers=headers, timeout=5).text
tree = etree.HTML(html)
href_lists = tree.xpath('//div[@class="col-md-12 no-padding-right"]/div[2]/div[@class="pills m-t"]/div[2]/a')
for href in href_lists:
city_url = href.xpath('./@href')[0]
start_url = 'https://www.qcc.com'
start_url += city_url
city_list_urls.append(start_url)
print(city_list_urls)
# 直接存储下来,这编码写utf-8-sig是因为存储csv文件时可能会出现乱码
with open('./city.csv', mode='w+', encoding='utf-8-sig', newline='') as fp:
writer = csv.writer(fp)
writer.writerow(city_list_urls)
# return city_list_urls
if __name__ == '__main__':
get_city_url()
scrapy框架撰写主要程序
我觉得应该大部分人都会用scrapy创建程序吧,我就不在这里在说一遍啦
spider文件
spider文件中主要写页面解析逻辑,我分成了两部分,第一部分,是写最开始的初始页面获取的公司信息,第二部分是具体公司的某些具体信息,最开始的参数是设置selenium的参数,因为中间涉及到了一个企查查的滑动反爬,但是据说直接放在中间件中会严重影响爬取速度,所以在spider中设置
import requests
import scrapy
from ..items import QichachacompanyItem
from ..items import QichachadetailItem
import time
import random
import re
import json
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
# selenium相关库
from selenium.webdriver import ChromeOptions
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.chrome.options import Options
from scrapy.downloadermiddlewares.retry import RetryMiddleware
from scrapy import signals
from pydispatch import dispatcher
# asw_sc__v2,这个参数是一个setcookie的参数,参照某个博主的博客能解析出来,但是暂时我还没用上
from qichacha.setcookie import get_unsbox, get_hexxor
class QichachaspiderSpider(scrapy.Spider):
# 这个count用于计算爬取的公司记录个数
count = 0
# 这个detail_count用于计算爬取的公司详细记录个数
detail_count = 0
# 这个用于计算爬取一级页面个数
preview_count = 0
def __init__(self):
ua = UserAgent()
# 无可视化操作
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('-disable-gpu')
chrome_options.add_argument('User-Agent={}'.format(ua.random))
# 实现让selenium规避被检测的风险
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option("useAutomationExtension", False)
option.add_experimental_option("prefs", {
"profile.managed_default_content_settings.images": 2})
# 当前路径下一定要安装谷歌驱动器,或者输入正确的谷歌驱动器位置
self.browser = webdriver.Chrome(executable_path='d:\Program Files\chromedriver.exe', options=option)
# self.browser = webdriver.Chrome(executable_path=r'/usr/local/bin/chromedriver', chrome_options= chrome_options, options=option)
# 通过浏览器的dev_tool在get页面将.webdriver属性设置为"undefined"
self.browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})""",
})
self.browser.set_script_timeout(25)
super().__init__()
# 设置信号量,当收到关闭的信号时,调用mySpiderCloseHandle方法,关闭chrome
dispatcher.connect(receiver=self.mySpiderCloseHandle,
signal=signals.spider_closed)
# 用于计算错误二级页面(detail)的个数
self.err_detail_count = 0
# 用于计算错误一级页面(preview)的个数
self.err_pre_count = 0
# 用于计算405错误出现次数
self.err_405_count = 0
# 信号量处理函数:关闭chrome浏览器
def mySpiderCloseHandle(self, spider):
print(f"mySpiderCloseHandle: enter ")
self.browser.quit()
cnt = 0
name = 'qichachaspider'
# allowed_domains = ['www.qichacha.com']
# start_urls = ['http://www.qichacha.com/']
base_url = 'https://www.qichacha.com/g_AH'
city_list_urls = []
with open('d:\Program Files\city.csv', mode='r+', encoding='utf-8-sig', newline='') as fp:
for url in fp:
city_list_urls.append(url.strip().split(','))
city_list_urls = city_list_urls[0]
def start_requests(self):
# 这是通过循环获得不同城市的url,然后通过页码拼接,获取每个城市每一页的url,列表中的数值可以去掉也可以改成其他的,这里的逻辑是获取全国每个城市500页的公司信息
for city_url in self.city_list_urls[::]:
for page in range(1, 501):
url = city_url + '_' + str(page)
print('Starting request for url {}'.format(url))
# 此处计算用于后续判断是否进入验证页面
self.preview_count += 1
yield scrapy.Request(
url=url,
meta={
'url': url, 'usedSelenium': True},
callback=self.parse_page,
)
def parse_page(self, response):
company_urls = []
item_company = QichachacompanyItem()
url = response.meta['url']
print('开始爬虫,首先爬取preview页面的10个数据! ! !')
try:
content_list = response.xpath('//div[@class="col-md-9 no-padding"]/div[2]/section/table/tbody/tr')
if content_list != []:
for message in content_list:
item_company['company_name'] = message.xpath('./td[2]/a/text()').extract_first().replace('\n', '').replace(' ', '')
start_url = 'https://www.qcc.com'
company_url = message.xpath('./td[2]/a/@href').extract_first()
company_url = company_url.split('/')[2]
start_url = start_url + '/cbase/' + company_url
item_company['company_url'] = start_url
company_urls.append(start_url)
# 可能出现不含有企业规模的标签,故会报错,所以此处需要进行一个判断
company_size = message.xpath('./td[2]/div/span/text()')
if company_size is not None:
item_company['company_size'] = company_size.extract_first()
item_company['company_Repre'] = message.xpath('./td[2]/p[1]/text()').extract_first().replace('\n', '').replace(' ', '') + ':' + \
message.xpath('./td[2]/p[1]/a/text()').extract_first().replace('\n', '').replace(' ', '')
item_company['company_money'] = message.xpath('./td[2]/p[1]/span[1]/text()').extract_first().replace('\n', '').replace(' ', '')
item_company['company_datetime'] = message.xpath('./td[2]/p[1]/span[2]/text()').extract_first().replace('\n', '').replace(' ', '')
item_company['company_email'] = message.xpath('./td[2]/p[2]/text()').extract_first().replace('\n', '').replace(' ', '')
item_company['company_phonenumber'] = message.xpath('./td[2]/p[2]/span/text()').extract_first().replace('\n', '').replace(' ', '')
item_company['company_address'] = message.xpath('./td[2]/p[3]/text()').extract_first().replace('\n', '').replace(' ', '')
item_company['company_status'] = message.xpath('./td[3]/span/text()').extract_first().replace('\n', '').replace(' ', '')
item_company['failed_urls'] = ''
self.count += 1
print("总共获取的一级页面数据为: {}, 失败爬取: {}".format(self.count, self.err_pre_count))
yield item_company
if item_company['company_status'] != '注销' and self.preview_count % 5 == 0:
yield scrapy.Request(
url=start_url,
meta={
'url': start_url, 'usedSelenium': True},
callback=self.parse_company,
)
elif item_company['company_status'] != '注销':
yield scrapy.Request(
url=start_url,
meta={
'url': start_url,},
callback=self.parse_company,
)
# time.sleep(random.randint(3, 6))
else:
print('获取页面信息为空')
self.err_pre_count += 1
failed_urls.append(url)
print('失败的url是{}, {}'.format(failed_urls, url))
item_company['failed_urls'] = failed_urls
error = re.findall('.*?(.*?) .*?', response.text, re.S)[0]
print('error 的值是{}'.format(error))
yield item_company
if error == '405错误页面':
self.err_405_count += 1
if self.err_405_count % 10 == 0:
print('出现了{}次405错误,建议睡眠10分钟'.format(self.err_405_count))
time.sleep(600)
except Exception as e:
self.err_pre_count += 1
if self.err_pre_count% 10 == 0:
print('频繁出错啦,休息5分钟')
time.sleep(300)
print('错误信息: {}'.format(e))
def parse_company(self, response):
print('打印公司详细信息')
url = response.meta['url']
failed_detail_urls = []
item = QichachadetailItem()
try:
item['detail_name'] = response.xpath('//table[@class="ntable"]/tr[1]/td[4]/text()').extract_first().replace('\n', '').replace(' ', '')
item['detail_cardcode'] = response.xpath('//table[@class="ntable"]/tr[1]/td[2]/text()').extract_first()
if item['detail_cardcode'] is not None:
item['detail_cardcode'] = item['detail_cardcode'].replace('\n', '').replace(' ', '')
item['detail_scale'] = response.xpath('//table[@class="ntable"]/tr[6]/td[2]/text()').extract_first().replace('\n', '').replace(' ', '')
item['detail_type'] = response.xpath('//table[@class="ntable"]/tr[5]/td[2]/text()').extract_first().replace('\n', '').replace(' ', '')
# 判断是否为个体工商户,如果是则不进行处理,如果不是则进行处理
if item['detail_type'] != '个体工商户':
taglist = response.xpath('//div[@class="company-data"]/section[4]/div[@class="tablist"]/div[2]/table/tbody/tr')
shareholders = []
shareholder = {
}
if taglist != []:
for tr in taglist:
name = tr[2].xpath('./div/span[2]/span/a/text()').extract_first()
proportion = tr[3].xpath('./text()').extract_first()
if name != [] and proportion != []:
shareholder = {
'股东姓名': name,
'所占股份': proportion
}
shareholders.append(shareholder)
else:
item['shareholders'] = shareholders
item['failed_detail_urls'] = ''
self.detail_count += 1
#print(item['detail_name'], item['detail_cardcode'], item['detail_scale'], item['detail_type'], item['shareholders'])
print('爬取的公司详细记录为{}个, 错误个数为{}个'.format(self.detail_count, self.err_detail_count))
yield item
else:
print("{}公司为个体工商户,不需要获取详细信息, 且不进行存储".format(item['detail_name']))
except Exception as e:
failed_detail_urls.append(url)
print('详情页获取错误, 错误原因为{}'.format(e))
print('失败的url是 {}'.format(url))
# print('详情页的response是{}, response.text is {}'.format(response, response.text))
item['failed_detail_urls'] = failed_detail_urls
self.err_detail_count += 1
if self.err_detail_count % 500 == 0:
print('频繁触发各种错误,所以睡眠10分钟')
time.sleep(600)
# 此处会触发两种反爬机制,第一种是返回405错误,第二种是返回setcookie,
# 通过分析js源代码可以得知,若返回数据为十六进制的乱码,则有可能是进行了js混淆变量以及混淆函数,返回acw_sc_v2
yield item
def parser_error(self, response):
pass
def Error_info(self, response):
print('未获取信息')
middleware中间件设置
我的中间件总共分成了五个部分,第一个是代理头的设置,这里用的是python中的第三方库fake-useragent,第二个是代理ip的设置,这个设置是我从获取的网站上每10秒钟才能获取一次,一次10个,第三个是cookie设置,必须携带cookie进行访问,不然就会报错,第四个部分就是滑动设置,这是在爬取过程中一定会触发的一个反爬,第五个部分是捕捉异常处理
from scrapy import signals
from itemadapter import is_item, ItemAdapter
from scrapy import signals
import random
import RandomProxy
import requests
from selenium.webdriver import ChromeOptions
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
import csv
from scrapy.http import HtmlResponse
IP_SWITCH_IN_SEC = 11
from fake_useragent import UserAgent
import json
class RandomUserAgentDownloaderMiddleware(object):
def process_request(self, request, spider):
ua = UserAgent()
request.headers['User-Agent'] = ua.random
# ip
class RandomProxyderMiddleware():
def __init__(self, ip=''):
self.ip = ip
self.last_time = int(time.time())
self.ip_pool = []
def process_request(self, request, spider):
# within 5 sec
if int(time.time()) - self.last_time < IP_SWITCH_IN_SEC and len(self.ip_pool) > 0:
# randomly select an ip
ip_random = self.ip_pool[random.randrange(0, 9)]
print('当前使用的ip是: ' + ip_random)
request.meta['proxy'] = 'http://' + ip_random
return
# every other 10 second
self.last_time = int(time.time())
ip_pool = RandomProxy.get_proxy()
self.ip_pool = ip_pool
# randomly select an ip
ip_random = self.ip_pool[random.randrange(0, 9)]
print('当前使用的ip是: ' + ip_random)
request.meta['proxy'] = 'http://' + ip_random
import os
from qichacha.setcookie import get_hexxor, get_unsbox
import re
class CookieDownloaderMiddleware():
def process_request(self, request, spider):
# 走一个循环,从保存的文件中取出cookie信息,有几个账号就保存了几个文件,循环的范围为账号的个数
cookie_path = os.path.abspath('cookie')
# with open('/home/Argonum/qichacha/qichacha/cookie/cookie.json') as fp:
cookie_list = []
for i in range(5):
with open(cookie_path + r'\cookie0{}.json'.format(i)) as fp:
dic_cookie = json.load(fp)
cookies = ''
for cookie in dic_cookie:
str_cookie = '{0}={1};'
str_cookie = str_cookie.format(cookie['name'], cookie['value'])
cookies += str_cookie
cookie_list.append(cookies)
request.cookies = {
'cookie': random.choice(cookie_list)}
class SeleniumVerifyMiddleware():
def process_request(self, request, spider):
# Middleware中会传递进来一个spider,这就是我们的spider对象,从中可以获取__init__时的chrome相关元素
'''
用chrome抓取页面
:param request: Request请求对象
:param spider: Spider对象
:return: HtmlResponse响应
'''
print(f"chrome正在获取页面")
usedSelenium = request.meta.get('usedSelenium', False)
if usedSelenium:
try:
time.sleep(random.randrange(2, 4) * random.random())
spider.browser.get(request.meta['url'])
try:
check_login = spider.browser.find_element_by_xpath('//div[@class="col-sm-4 loginBoxBorder"]')
# if check_login is not None:
check_span = spider.browser.find_element_by_xpath('//div[@id="nc_1_n1t"]/span[@class="nc_iconfont btn_slide"]')
check_action = ActionChains(spider.browser)
check_action.click_and_hold(check_span).perform()
y = random.randrange(-5, 5) * random.random()
def distance_tracks():
distance_list = []
distance = 260
total = 0
while True:
x = random.randrange(10, 100)
total += x
if distance - total <= 260 and distance - total > 0:
distance_list.append(x)
else:
x = x + distance -total
distance_list.append(x)
break
return distance_list
distance_list = distance_tracks()
for x in distance_list:
check_action.move_by_offset(xoffset=x, yoffset=y)
#check_action.move_by_offset(260, 0)
check_action.release().perform()
check_div = spider.browser.find_element_by_xpath('//div[@class="m-l-lg m-r-lg m-b-xl"]/button[@id="verify"]')
check_div.click()
time.sleep(1)
# print('selenium finished picture verification for {}'.format(request.meta['url']))
content = spider.browser.page_source.encode("utf-8")
error = re.findall('.*?(.*?) .*?', content, re.S)[0]
return HtmlResponse(url=request.meta['url'], status=200, request=request, body=content, encoding='utf-8')
except Exception as e:
print('跳过验证,原因为{}'.format(e))
content = spider.browser.page_source.encode("utf-8")
return HtmlResponse(url=request.meta['url'], status=200, request=request, body=content, encoding="utf-8")
except Exception as e:
print('错误错误, 错误原因为{}'.format(e))
if e == 'Message: no such window: target window already closed':
print('个人认为是服务器崩溃,所以休息10分钟,保证后续数据可以顺利爬取到')
time.sleep(600)
return HtmlResponse(url=request.meta['url'], status=500, request=request)
else:
print('直接跳过验证,未进入验证页面,进入parse_company进行处理')
# 处理异常这里我是借鉴的其他大佬的代码,不过后面我发现我有没有这部分都没关系,并不影响啥,异常我自己的代码就会打印出来
from twisted.internet import defer
from twisted.internet.error import TimeoutError, DNSLookupError, ConnectionRefusedError, ConnectionDone, ConnectError, ConnectionLost, TCPTimedOutError
from scrapy.http import HtmlResponse
from twisted.web.client import ResponseFailed
from scrapy.core.downloader.handlers.http11 import TunnelError
from scrapy import signals
class ExceptionDownloaderMiddleware:
ALL_EXCEPTIONS = (defer.TimeoutError, TimeoutError, DNSLookupError,
ConnectionRefusedError, ConnectionDone, ConnectError,
ConnectionLost, TCPTimedOutError, ResponseFailed,
IOError, TunnelError)
# 处理响应
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# 返回一个响应对象,或者一个请求对象,又或者是忽略该请求
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# 在下载处理程序或process_request()时调用
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
# 当出现异常时首先会进入到这儿,然后process_response()
#捕获几乎所有的异常
# 此时返回的 status为200
if isinstance(exception, self.ALL_EXCEPTIONS):
#在日志中打印异常类型
print('========异常:========== {}'.format(exception))
#随意封装一个response,返回给spider
response = HtmlResponse(url='exception',encoding='utf-8',body='{}')
return response
#打印出未捕获到的异常
print('========not contained exception: ========{}'.format(exception))
item设置
item中间主要是两个类,一个存储初始页面公司信息,一个存储具体页面公司信息
import scrapy
from scrapy import Field
class QichachacompanyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
company_name = scrapy.Field()
company_url = scrapy.Field()
company_size = scrapy.Field()
company_Repre = scrapy.Field()
company_money = scrapy.Field()
company_datetime = scrapy.Field()
company_email = scrapy.Field()
company_phonenumber = scrapy.Field()
company_address = scrapy.Field()
company_status = scrapy.Field()
failed_urls = scrapy.Field()
class QichachadetailItem(scrapy.Item):
detail_name = scrapy.Field()
detail_cardcode = scrapy.Field()
detail_scale = scrapy.Field()
detail_type = scrapy.Field()
shareholders = scrapy.Field()
failed_detail_urls = scrapy.Field()
pipline文件
因为我是存储到本地csv文件的,所以俺也没有写过存储到数据库,根据我的存储逻辑,会有四个文件,两个存储正确数据的文件,两个存储失败页面的网址
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import scrapy
from itemadapter import ItemAdapter
import json
import codecs
import csv
from .settings import *
from items import QichachacompanyItem
from items import QichachadetailItem
import sqlite3
class QichachaPipeline(object):
def __init__(self):
self.file_company = codecs.open('./company.csv', 'a', 'utf-8-sig')
# 设置第一行的字段名
self.filenames_company = ['公司名称', '公司网址', '公司规模', '公司法人',
'注册资金', '注册时间', '电子邮箱',
'电话号码', '公司地址', '经营状态']
self.writer_company = csv.writer(self.file_company)
self.writer_company.writerow(self.filenames_company)
# 设置第二个表格详细公司数据数据
self.file_detail = codecs.open('./detail.csv', 'a', 'utf-8-sig')
# 设置第一行的字段名
self.filenames_detail = ['公司名称', '统一社会信用代码', '经营范围', '公司类型', '股东信息',]
self.writer_detail = csv.writer(self.file_detail)
self.writer_detail.writerow(self.filenames_detail)
# 设置第三个表格失败的网址数据
self.file_failed_urls = codecs.open('./failedurl.csv', 'a', 'utf-8-sig')
self.writer_failed_urls = csv.writer(self.file_failed_urls)
# 设置第四个表格失败的详情页网址数据
self.file_failed_detail_urls = codecs.open('./faileddetailurl.csv', 'a', 'utf-8-sig')
self.writer_failed_detail_urls = csv.writer(self.file_failed_detail_urls)
def process_item(self, item, spider):
try:
if item['company_name'] != '':
# 获取的数据存储到正常公司表格中
row = [item['company_name'], item['company_url'], item['company_size'],
item['company_Repre'], item['company_money'], item['company_datetime'],
item['company_email'], item['company_phonenumber'], item['company_address'],
item['company_status']]
self.writer_company.writerow(row)
except:
# 获取的数据存储到正常公司详情页表格中
try:
row = [item['detail_name'], item['detail_cardcode'], item['detail_scale'],
item['detail_type'], item['shareholders'], ]
self.writer_detail.writerow(row)
except:
try:
# 失败的数据存储到failed_detail_urls中
url = [ item['failed_detail_urls']]
if url != '' or url != "":
self.writer_failed_detail_urls.writerow(url)
except:
# 失败的数据存储到failed_urls中
url = [item['failed_urls']]
if url != "" or url != '':
self.writer_failed_urls.writerow(url)
return item
def spider_closed(self, spider):
self.file_company.close()
self.file_detail.close()
self.file_failed_urls.close()
self.file_failed_detail_urls.close()
settings设置
settings中主要是一个中间件的设置,其实有看过scrapy打印的日志的人就会发现,scrapy中的中间件是有顺序的,按照编号往下排就好了,设置中的请求头建议自己按照自己的需求去网站上复制粘贴
# Scrapy settings for qichacha project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
import time
import random
BOT_NAME = 'qichacha'
SPIDER_MODULES = ['qichacha.spiders',]
NEWSPIDER_MODULE = 'qichacha.spiders'
# sqlite 配置
# selenium参数设置
# selenium浏览器超时时间设置
# SELENIUM_TIMEOUT = 25
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36 Edg/90.0.818.66'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 10
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = time.sleep(random.uniform(10, 20))
DOWNLOAD_DELAY = 2
# The download delay setting will honor only one of:
CONCURRENT_REQUESTS_PER_DOMAIN = 10
# CONCURRENT_REQUESTS_PER_IP = 16
#CONCURRENT_REQUESTS_PER_DOMAIN = 100
#CONCURRENT_REQUESTS_PER_IP = 100
# 重试次数,如果碰到TCP连接错误,则不进行重试
#RETRY_ENABLED = False
# 设置下载超时时间,如果访问一个页面超过10秒没有响应,则放弃
#DOWNLOAD_TIMEOUT = 5
# Disable cookies (enabled by default)
COOKIES_ENABLED = True
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'accept-encoding': 'gzip, deflate, br',
'sec-ch-ua':'" Not A;Brand";v="99", "Chromium";v="90", "Microsoft Edge";v="90"',
'sec-ch-ua-mobile': '?0',
'referer': 'https://www.qcc.com/',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'qichacha.middlewares.QichachaSpiderMiddleware': 543,
# 'qichacha.middlewares.SeleniumVerifyMiddleware': 544,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'qichacha.middlewares.QichachaDownloaderMiddleware': 543,
'qichacha.middlewares.RandomUserAgentDownloaderMiddleware':545,
'qichacha.middlewares.CookieDownloaderMiddleware':546,
#'qichacha.middlewares.RandomProxyderMiddleware':544,
'qichacha.middlewares.SeleniumVerifyMiddleware': 547,
'qichacha.middlewares.ExceptionDownloaderMiddleware':548,
'scrapy.contrib.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': None,
}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'qichacha.pipelines.QichachaPipeline': 300,
# 'qichacha.pipelines.SqlitePipeline': 301,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
FEED_EXPORT_ENCODING = 'gb18030'
ps:以上程序可以正常运行,获取速度大约在一小时1000条数据左右,如果不需要具体页面的数据,可能运行速度会更快,我好像后期还改了几个参数,可以提高运行速度,但是我忘了。如果网站进行改版了,逻辑还是可行的。有问题也不要找我交流了,我还挺懒散的,碰到问题就百度谷歌吧。