Hive内置函数与常用函数汇总
目录
Hive内置函数汇总
字符函数(字符串操作)
数学函数
集合函数
类型转换函数
日期函数
条件函数
聚合函数
表生成函数
辅助功能类函数
数据屏蔽函数(从Hive 2.1.0开始)
Hive常用函数总结
1.字符串操作函数
字符串长度函数:length(string str)
字符串反转函数:reverse(string str)
字符串连接函数:concat(string|binary A, string|binary B...)
带分隔符字符串连接函数:concat_ws(string SEP, string A, string B...)
字符串截取函数:substr(string A, int start) | substring(string A, int start)
字符串转大写函数:upper(string A) | ucase(string A)
字符串转小写函数:lower(string A) | lcase(string A)
去空格函数:trim(string str)
左边去空格函数:ltrim(string str)
右边去空格函数:rtrim(string str)
分割字符串函数: split(string str, string pat)
重复字符串函数:repeat(string str, int n)
左补足函数:lpad(string str, int len, string pad)
右补足函数:rpad(string str, int len, string pad)
空格字符串函数: space(int n)
2.正则匹配函数
正则替换函数:regexp_replace(string A, string B, string C)
正则解析函数:regexp_extract(string subject, string pattern, int index)
3.解析函数
URL解析函数:parse_url(string urlString, string partToExtract [, string keyToExtract])
json解析函数:get_json_object(string json_string, string path)
4.聚合函数:
5.日期函数
获取年、月、日、小时、分钟、秒、当年第几周
获取当前时间:
next_day(date, week)
last_day(date)
add_months( date, n )
datediff(string enddate, string startdate)
to_char(date,format)
date_add(string startdate, int days)
date_sub(string startdate, int days)
to_date:日期时间转日期
6.开窗函数--窗口函数与分析函数
OVER从句
窗口聚合函数
窗口分析函数
窗口排序函数
7.Hive行列转换函数
行转列(一对多)
列转行(多对一)
8.高级聚合
(1).GROUPING SETS
(2).Grouping_ID函数
(3).ROLLUP和CUBE
(4).GROUPING
9.其他函数
空值转换函数: nvl(x,y)
首字符ascii函数: ascii(string str)
集合查找函数: find_in_set(string str, string strList)
位置查找函数: instr((string,str[,start][,appear])
mod(n1,n2)
[官网地址]
Hive内置函数汇总
字符函数(字符串操作)
| 返回值类型 |
函数名称(参数) |
函数说明 |
| int |
ascii(string str) |
返回str中首个ASCII字符串的整数值 |
| string |
base64(binary bin) |
将二进制bin转换成64位的字符串 |
| string |
concat(string|binary A, string|binary B...) |
对二进制字节码或字符串按次序进行拼接 |
| array |
context_ngrams(array |
与ngram类似,但context_ngram()允许你预算指定上下文(数组)来去查找子序列,具体看StatisticsAndDataMining |
| string |
concat_ws(string SEP, string A, string B...) |
与concat()类似,但使用指定的分隔符喜进行分隔 |
| string |
concat_ws(string SEP, array |
拼接数组中元素并用指定分隔符分隔 |
| string |
decode(binary bin, string charset) |
使用指定的字符集charset将二进制值bin解码成字符串,支持的字符集有:'US-ASCII', 'ISO-8859-1', 'UTF-8', 'UTF-16BE', 'UTF-16LE', 'UTF-16',如果任意输入参数为NULL都将返回NULL |
| binary |
encode(string src, string charset) |
使用指定的字符集charset将字符串编码成二进制值,支持的字符集有:'US-ASCII', 'ISO-8859-1', 'UTF-8', 'UTF-16BE', 'UTF-16LE', 'UTF-16',如果任一输入参数为NULL都将返回NULL |
| int |
find_in_set(string str, string strList) |
返回以逗号分隔的字符串中str出现的位置,如果参数str为逗号或查找失败将返回0,如果任一参数为NULL将返回NULL. |
| string |
format_number(number x, int d) |
将数值x的小数位格式化成d位,四舍五入. |
| string |
get_json_object(string json_string, string path) |
从指定路径上的JSON字符串抽取出JSON对象,并返回这个对象的JSON格式,如果输入的JSON是非法的将返回NULL,注意此路径上JSON字符串只能由数字,字母, 下划线组成且不能有大写字母和特殊字符,且key不能由数字开头,这是由于Hive对列名的限制 |
| boolean |
in_file(string str, string filename) |
如果文件名为filename的文件中有一行数据与字符串str匹配成功就返回true |
| int |
instr(string str, string substr) |
查找字符串str中子字符串substr出现的位置,如果查找失败将返回0,如果参数为Null将返回null.注意位置为从1开始. |
| int |
length(string A) |
返回字符串的长度 |
| int |
locate(string substr, string str[, int pos]) |
查找字符串str中的pos位置后字符串substr第一次出现的位置 |
| string |
lower(string A) lcase(string A) |
将字符串A的所有字母转换成小写字母 |
| string |
lpad(string str, int len, string pad) |
从左边开始对字段使用字符串pad填充,最终len长度为止,如果字符串str本身长度比len大的话,将去掉多余的部分 |
| string |
ltrim(string A) |
去掉字符串A前面的空格 |
| array |
ngrams(array |
返回出现次数TOP K的的子序列,n表示子序列的长度 |
| string |
parse_url(string url, string partToExtract [, string keyToExtract]) |
返回从URL中抽取指定部分的内容,参数url是URL字符串,而参数partToExtract是要抽取的部分,这个参数包含(HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, and USERINFO,例如:parse_url('http://baidu.com/path1/p.php?k1=v1&k2=v2', 'HOST') ='baidu.com',如果参数partToExtract值为QUERY则必须指定第三个参数key. 如:parse_url('http://baidu.com/path1/p.php?k1=v1&k2=v2','QUERY','k1') ='v1' |
| string |
printf(String format, Obj... args) |
按照printf风格格式输出字符串 |
| string |
A regexp B |
功能与RLIKE相同,用于条件过滤 |
| string |
regexp_extract(string subject, string pattern, int index) |
抽取字符串subject中符合正则表达式pattern的第index个部分的子字符串,注意转义字符的使用,如第二个参数使用'\s'将被匹配到s,'\\s'才是匹配空格 |
| string |
regexp_replace(string a, string b, string c) |
按照Java正则表达式b将字符串a中符合条件的部分成c所指定的字符串,如果c为空,则将符合正则的部分将被去掉。 如:regexp_replace("foobar","oo|ar", "")='fb' .注意转义字符的使用. |
| string |
repeat(string str, int n) |
重复输出n次字符串str |
| string |
reverse(string A) |
反转字符串 |
| string |
rpad(string str, int len, string pad) |
从右边开始对字符串str使用字符串pad填充到len长度为止,如果字符串str本身长度比len大的话,将去掉多余的部分 |
| string |
rtrim(string A) |
去掉字符串后面出现的空格 |
| array |
sentences(string str, string lang, string locale) |
字符串str将被转换成单词数组,如:sentences('Hello mm! How are you?') =(("Hello","mm"),("How","are","you")) |
| string |
space(int n) |
返回n个空格 |
| array |
split(string str, string pat) |
按照正则表达式pat来分割字符串str,并将分割后的数组字符串的形式返回 |
| map |
str_to_map(text[, delimiter1, delimiter2]) |
将字符串str按照指定分隔符转换成Map,第一个参数是需要转换字符串,第二个参数是键值对之间的分隔符,默认为逗号;第三个参数是键值之间的分隔符,默认为"=" |
| string |
substr(string|binary A, int start) substring(string|binary A, int start) |
对于字符串A,从start位置开始截取字符串并返回 |
| string |
substr(string|binary A, int start, int len) , substring(string|binary A, int start, int len) |
对于二进制/字符串A,从start位置开始截取长度为length的字符串并返回 |
| string |
substring_index(string A, string delim, int count) |
截取第count分隔符之前的字符串,如count为正则从左边开始截取,如果为负则从右边开始截取 |
| string |
translate(string|char|varchar input, string|char|varchar from, string|char|varchar to) |
将input出现在from中的字符串替换成to中的字符串 如:translate("MOBIN","BIN","M")="MOM" |
| string |
trim(string A) |
将字符串A前后出现的空格去掉 |
| string |
Lower(string A) 或lcase(string A) |
将字符串A中的字母转换成小写字母 |
| string |
upper(string A) 或ucase(string A) |
将字符串A中的字母转换成大写字母 |
| string |
initcap(string A) |
将字符串A转换第一个字母大写其余字母的字符串 |
| int |
levenshtein(string A,string B) |
计算两个字符串之间的差异大小 如:levenshtein('kitten', 'sitting') = 3 |
| string |
soundex(string A) |
将普通字符串转换成soundex字符串 |
| binary |
unbase64(string str) |
将64位的字符串转换二进制值 |
数学函数
| 返回值类型 |
函数名称(参数) |
函数说明 |
| DOUBLE |
round(DOUBLE a) |
返回对a四舍五入的BIGINT值 |
| DOUBLE |
round(DOUBLE a, INT d) |
返回DOUBLE型d的保留n位小数的DOUBLE型的近似值 |
| DOUBLE |
bround(DOUBLE a) |
银行家舍入法(1~4:舍,6~9:进,5->前位数是偶:舍,5->前位数是奇:进) |
| DOUBLE |
bround(DOUBLE a, INT d) |
银行家舍入法,保留d位小数 |
| BIGINT |
floor(DOUBLE a) |
向下取整,最数轴上最接近要求的值的左边的值 如:6.10->6 -3.4->-4 |
| BIGINT |
ceil(DOUBLE a), ceiling(DOUBLE a) |
求其不小于小给定实数的最小整数如:ceil(6) = ceil(6.1)= ceil(6.9) = 6 |
| DOUBLE |
rand(), rand(INT seed) |
每行返回一个DOUBLE型随机数,seed是随机因子 |
| DOUBLE |
exp(DOUBLE|DECIMAL a) |
返回e的a幂次方, a可为小数 |
| DOUBLE |
ln(DOUBLE|DECIMAL a) |
以自然数为底d的对数,a可为小数 |
| DOUBLE |
log10(DOUBLE|DECIMAL a) |
以10为底d的对数,a可为小数 |
| DOUBLE |
log2(DOUBLE|DECIMAL a) |
以2为底数d的对数,a可为小数 |
| DOUBLE |
log(DOUBLE|DECIMAL base, DOUBLE|DECIMAL a) |
以base为底的对数,base 与 a都是DOUBLE类型 |
| DOUBLE |
pow(DOUBLE a, DOUBLE p), power(DOUBLE a, DOUBLE p) |
计算a的p次幂 |
| DOUBLE |
sqrt(DOUBLE a), sqrt(DECIMAL a) |
计算a的平方根 |
| STRING |
bin(BIGINT a) |
计算STRING类型二进制a的STRING类型 |
| STRING |
hex(BIGINT|STRING|BINARY a) |
计算a的STRING类型,若a为STRING类型就转换成字符相对应的十六进制 |
| BINARY |
unhex(STRING a) |
hex的逆方法 |
| STRING |
conv(BIGINT|STRING num, INT from_base, INT to_base) |
将GIGINT/STRING类型的num从from_base进制转换成to_base进制 |
| DOUBLE |
abs(DOUBLE a) |
计算a的绝对值 |
| INT or DOUBLE |
pmod(INT|DOUBLE a, INT|DOUBLE b) |
a对b取模 |
| DOUBLE |
sin(DOUBLE|DECIMAL a) |
求a的正弦值 |
| DOUBLE |
asin(DOUBLE|DECIMAL a) |
求d的反正弦值 |
| DOUBLE |
cos(DOUBLE|DECIMAL a) |
求余弦值 |
| DOUBLE |
acos(DOUBLE|DECIMAL a) |
求反余弦值 |
| DOUBLE |
tan(DOUBLE|DECIMAL a) |
求正切值 |
| DOUBLE |
atan(DOUBLE|DECIMAL a) |
求反正切值 |
| DOUBLE |
degrees(DOUBLE|DECIMAL a) |
奖弧度值转换角度值 |
| DOUBLE |
radians(DOUBLE|DECIMAL a) |
将角度值转换成弧度值 |
| INT or DOUBLE |
positive(INT|DOUBLE a) |
返回a |
| INT or DOUBLE |
negative(INT|DOUBLE a) |
返回a的相反数 |
| DOUBLE or INT |
sign(DOUBLE|DECIMAL a) |
如果a是正数则返回1.0,是负数则返回-1.0,否则返回0.0 |
| DOUBLE |
e() |
数学常数e |
| DOUBLE |
pi() |
数学常数pi |
| BIGINT |
factorial(INT a) |
求a的阶乘 |
| DOUBLE |
cbrt(DOUBLE a) |
求a的立方根 |
| INT BIGINT |
shiftleft(TINYINT|SMALLINT|INT a,INT b) shiftleft(BIGINT a, INT b) |
按位左移 |
| INT BIGINT |
shiftright(TINYINT|SMALLINT|INT a, INTb) shiftright(BIGINT a, INT b) |
按拉右移 |
| INT BIGINT |
shiftrightunsigned(TINYINT|SMALLINT|INTa, INT b), shiftrightunsigned(BIGINT a, INT b) |
无符号按位右移(<<<) |
| T |
greatest(T v1, T v2, ...) |
求最大值 |
| T |
least(T v1, T v2, ...) |
求最小值 |
集合函数
| 返回值类型 |
函数名称(参数) |
函数说明 |
||
| int |
size(Map |
求map的长度 |
||
| int |
size(Array |
求数组的长度 |
||
| array |
map_keys(Map |
返回map中的所有key |
||
| array |
map_values(Map |
返回map中的所有value |
||
| boolean |
array_contains(Array |
如该数组Array |
||
| array |
sort_array(Array |
按自然顺序对数组进行排序并返回 |
|
|
类型转换函数
| 返回值类型 |
函数名称(参数) |
函数说明 |
| binary |
binary(string|binary) |
将输入的值转换成二进制 |
|
|
cast(expr as |
将expr转换成type类型. 如:cast("1" as BIGINT) 将字符串1转换成了BIGINT类型,如果转换失败将返回NULL |
日期函数
| 返回值类型 |
函数名称(参数) |
函数说明 |
| string |
from_unixtime(bigint unixtime[, string format]) |
将时间的秒值转换成format格式(format可为"yyyy-MM-dd hh:mm:ss","yyyy-MM-dd hh","yyyy-MM-dd hh:mm"等等)如from_unixtime(1250111000,"yyyy-MM-dd") 得到2009-03-12 |
| bigint |
unix_timestamp() |
获取本地时区下的时间戳(秒值) |
| bigint |
unix_timestamp(string date) |
将格式为yyyy-MM-dd HH:mm:ss的时间字符串转换成时间戳(秒值) |
| bigint |
unix_timestamp(string date, string pattern) |
将指定时间字符串格式字符串转换成Unix时间戳,如果格式不对返回0 .如:unix_timestamp('2009-03-20', 'yyyy-MM-dd') = 1237532400 unix_timestamp('20090320', 'yyyyMMdd') = 1237532400 |
| string |
to_date(string timestamp) |
返回时间字符串的日期部分 |
| int |
year(string date) |
返回时间字符串的年份部分 |
| Int |
quarter(date/timestamp/string a) |
返回季度(从Hive 1.3.0开始) |
| int |
month(string date) |
返回时间字符串的月份部分 |
| int |
day(string date) , dayofmonth(date) |
返回时间字符串的天 |
| int |
hour(string date) |
返回时间字符串的小时 |
| int |
minute(string date) |
返回时间字符串的分钟 |
| int |
second(string date) |
返回时间字符串的秒 |
| int |
weekofyear(string date) |
返回时间字符串位于一年中的第几个周内. 如weekofyear("1970-11-01 00:00:00") = 44, weekofyear("1970-11-01") = 44 |
| int |
datediff(string enddate, string startdate) |
计算开始时间startdate到结束时间enddate相差的天数 |
| string |
date_add(string startdate, int days) |
从开始时间startdate加上days |
| string |
date_sub(string startdate, int days) |
从开始时间startdate减去days |
| string |
date_format(date/timestamp/string ts, string fmt) |
按指定格式返回时间date 如:date_format("2016-06-22","MM-dd")=06-22 |
| timestamp |
from_utc_timestamp(timestamp, string timezone) |
如果给定的时间戳并非UTC,则将其转化成指定的时区下时间戳 |
| timestamp |
to_utc_timestamp(timestamp, string timezone) |
如果给定的时间戳指定的时区下时间戳,则将其转化成UTC下的时间戳 |
| date |
current_date() |
返回当前时间日期 |
| timestamp |
current_timestamp() |
返回当前时间戳 |
| string |
add_months(string dt, int n) |
返回当前时间dt下再增加n个月的日期 |
| string |
next_day(string start_date, string day_of_week) |
返回当前时间的下一个星期X所对应的日期 如:next_day('2015-01-14', 'TU') = 2015-01-20 以2015-01-14为开始时间,其下一个星期二所对应的日期为2015-01-20 |
| string |
last_day(string date) |
返回这个月的最后一天的日期,忽略时分秒部分 |
| string |
trunc(string date, string format) 或 trunc(n1, n2) |
截断函数,可截断日期或数字。 当第一个参数为string类型的时间字段时返回时间的最开始年份或月份。此时第二个参数format所支持的格式(不分大小写)为: YEAR/YYYY/YY/Y(截取本年第一天); MONTH/MON/MM(截取本月第一天); DD(截取本周第一天);D(截取到今天); HH(截取到小时); MI(截取到分钟); SS(截取到秒); 如trunc("2016-06-26","MM")=2016-06-01, trunc("2016-06-26","YY")=2016-01-01, trunc("2016-06-26 12:30:45","DD")=2016-06-26 00:00:00。 当第一个参数是数字类型的数值时第二个参数取整数,省略时从小数点处开始截断。例如: trunc(12345.6789)=12345 trunc(12345.6789,2)=12345.67 trunc(12345.6789,-2)=12300 |
| double |
months_between(date1, date2) |
返回date1与date2之间相差的月份,如date1>date2,则返回正,如果date1 |
条件函数
| 返回值类型 |
函数名称(参数) |
函数说明 |
| T |
if(boolean a, T v1, T v1) |
如果条件a为true就返回v1,否则返回v2,(v1,v2为泛型) |
| T |
nvl(T value, T default_value) |
如果value值为NULL就返回default_value,否则返回value |
| T |
COALESCE(T v1, T v2, ...) |
返回第一非null的值,如果全部都为NULL就返回NULL 如:COALESCE (NULL,44,55)=44/strong> |
| T |
CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END |
如果a=b就返回c,a=d就返回e,否则返回f.如CASE 4 WHEN 5 THEN 5 WHEN 4 THEN 4 ELSE 3 END将返回4 |
| T |
CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END |
如果a=ture就返回b,c= ture就返回d,否则返回e 如:CASE WHEN 5>0 THEN 5 WHEN 4>0 THEN 4 ELSE 0 END 将返回5;CASE WHEN 5<0 THEN 5 WHEN 4<0 THEN 4 ELSE 0 END 将返回0 |
| boolean |
isnull( a ) |
如果a为null就返回true,否则返回false |
| boolean |
isnotnull ( a ) |
如果a为非null就返回true,否则返回false |
聚合函数
| 返回值类型 |
函数名称(参数) |
函数说明 |
| BIGINT |
count(*) ; count(expr) 或count(1); count(DISTINCT expr[, expr...]) |
统计总行数,包括含有NULL值的行; 统计提供非NULL的expr表达式值的行数; 统计提供非NULL且去重后的expr的行数 |
| DOUBLE |
sum(col), sum(DISTINCT col) |
sum(col),表示求指定列的和,sum(DISTINCT col)表示求去重后的列的和 |
| DOUBLE |
avg(col), avg(DISTINCT col) |
avg(col),表示求指定列的平均值,avg(DISTINCT col)表示求去重后的列平均值 |
| DOUBLE |
min(col) |
求指定列的最小值 |
| DOUBLE |
max(col) |
求指定列的最大值 |
| DOUBLE |
variance(col)或var_pop(col) |
求指定列数值的方差 |
| DOUBLE |
var_samp(col) |
求指定列数值的样本方差 |
| DOUBLE |
stddev_pop(col) |
求指定列数值的标准偏差 |
| DOUBLE |
stddev_samp(col) |
求指定列数值的样本标准偏差 |
| DOUBLE |
covar_pop(col1, col2) |
求指定列数值的协方差 |
| DOUBLE |
covar_samp(col1, col2) |
求指定列数值的样本协方差 |
| DOUBLE |
corr(col1, col2) |
返回两列数值的相关系数 |
| DOUBLE |
percentile(BIGINT col, p) |
返回col的p%分位数(p∈(0,1)p∈(0,1)) |
| DOUBLE |
percentile_approx(DOUBLE col, p [,B]) |
近似中位数函数,求近似的第pth个百分位数,p必须介于0和1之间,返回类型为double,但是col字段支持浮点类型。参数B控制内存消耗的近似精度,B越大,结果的准确度越高。默认为10,000。当col字段中的distinct值的个数小于B时,结果为准确的百分位数 |
| ARRAY |
collect_set(col) |
返回去重后的集合. |
| ARRAY |
collect_list(col) |
返回不去重的集合(从Hive 0.13.0开始) |
| INT |
ntile(INT x) |
将一个有序分区划分为x组,称为bucket,并为分区中的每一行分配一个桶号。这可以方便地计算三元组、四分位数、十分位数、百分位数和其他常见的汇总统计数据。(截至Hive 0.11.0) |
表生成函数
| 返回值类型 |
函数名称(参数) |
函数说明 |
| T |
explode(array<TYPE> a) |
每行对应数组中的一个元素 |
| Tkey,Tvalue |
explode(MAP |
每行对应每个map键-值,其中一个字段是map键,另一个字段是map值 |
| Int,T |
posexplode(ARRAY) |
在explode的基础上返回各元素在数组中的索引值(从0开始) |
| N rows |
stack(INT n, v_1, v_2, ..., v_k) |
把M列转换成N行,每行有M/N个字段,其中n必须是个常数 |
| tuple |
json_tuple(jsonStr, k1, k2, ...) |
从一个JSON字符串中获取多个键并作为一个元组返回,与get_json_object不同的是此函数能一次获取多个键值;同一个row,只解析一次. |
| tuple |
parse_url_tuple(url, p1, p2, ...) |
返回从URL中抽取指定N部分的内容,参数url是URL字符串,而参数p1,p2,....是要抽取的部分,这个参数包含HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, USERINFO, QUERY: |
|
|
inline(ARRAY |
将结构体数组提取出来并插入到表中 |
辅助功能类函数
| 返回值类型 |
函数名称(参数) |
函数说明 |
| string |
md5(STRING|BINARY A) |
计算字符串或二进制文件的MD5 128位校验和(从Hive 1.3.0开始)。该值作为一个由32位十六进制数字组成的字符串返回,如果参数为NULL,则返回NULL。例如: md5('123456')= 'e10adc3949ba59abbe56e057f20f883e' |
|
|
reflect(class, method[, arg1[, arg2..]]) |
通过使用反射匹配参数签名来调用Java方法。(从Hive 0.7.0开始) 参数1:Java中的类名; 参数2:Java类中的静态方法; 后续参数(若有):字段(方法所需参数) |
| Int |
hash(a1[, a2...]) |
返回参数的哈希值 |
|
|
java_method(class, method[, arg1[, arg2..]]) |
反射的同义词 |
| string |
current_user() |
从配置的authenticator管理器返回当前用户名(从Hive 1.2.0开始)。可以与连接时提供的用户相同,但是对于某些身份验证管理器情况可能有所不同 |
| string |
logged_in_user() |
从会话状态返回当前(连接到Hive时提供的)用户名(从Hive 2.2.0开始). |
| string |
current_database() |
返回当前数据库名称(截至Hive 0.13.0) |
| string |
sha1(string/binary), sha(string/binary) |
(从Hive 1.3.0开始) 计算字符串或二进制文件的SHA-1摘要,并以十六进制字符串的形式返回值.示例:sha1('ABC') = '3c01bdbb26f358bab27f267924aa2c9a03fcfdb8'。 string sha2(string/binary, int)计算SHA-2哈希函数家族(SHA-224、SHA-256、SHA-384和SHA-512)。第一个参数是要散列的字符串或二进制文件。第二个参数表示结果所需的位长,它的值必须是224、256、384、512或0(等于256)。从Java 8开始支持SHA-224。如果参数为NULL或哈希长度不是允许的值之一,则返回值为NULL。示例:sha2('ABC',256) = 'b5d4045c3f466fa91fe2cc6abe79232a1a57cdf104f7a26e716e0a1e2789df78'。 |
| binary |
aes_encrypt(input string/binary, key string/binary) |
使用AES加密输入(从Hive 1.3.0开始)。可以使用128、192或256位的密钥长度。如果安装了Java Cryptography Extension (JCE)无限强度管辖策略文件,则可以使用192和256位密钥。如果参数为NULL或键长度不是允许的值之一,则返回值为NULL。示例: base64(aes_encrypt('ABC','1234567890123456'))=' y6Ss+zCYObpCbgfWfyNWTw==') |
| binary |
aes_decrypt(input binary, key string/binary) |
使用AES解密输入(从Hive 1.3.0开始)。可以使用128、192或256位的密钥长度。如果安装了Java Cryptography Extension (JCE)无限强度管辖策略文件,则可以使用192和256位密钥。如果参数为NULL或键长度不是允许的值之一,则返回值为NULL。示例: aes_decrypt(unbase64('y6Ss+zCYObpCbgfWfyNWTw=='),'1234567890123456')='ABC' |
| string |
version() |
返回Hive版本(从Hive 2.1.0开始)。字符串包含两个字段,第一个是构建号,第二个是构建散列。例如:"select version();"可能返回"2.1.0.2.5.0.0-1245 r027527b9c5ce1a3d7d0b6d2e6de2378fb0c39232"。实际的结果将取决于你的构建 |
数据屏蔽函数(从Hive 2.1.0开始)
| 返回值类型 |
函数名称(参数) |
函数说明 |
| string |
mask(string str[, string upper[, string lower[, string number]]]) |
返回一个隐藏的str版本。默认情况下,大写字母转换为"X",小写字母转换为"X",数字转换为"n"。例如,mask("abcd-EFGH-8765-4321")将返回xxxx-XXXX-nnnn-nnnn。你可以通过提供额外的参数来覆盖掩码中使用的字符:第二个参数控制大写字母的掩码字符,第三个参数控制小写字母,第四个参数控制数字。例如,mask("abcd-efgh-8765-4321","U","l","#")导致llll-UUUU-########。 |
| string |
mask_first_n(string str[, int n]) |
返回一个带前n个值屏蔽的str屏蔽版本。大写字母转换为"X",小写字母转换为"X",数字转换为"n"。例如,mask_first_n("1234-5678-8765-4321",4)的结果是nnnn-5678-8765-4321。 |
| string |
mask_last_n(string str[, int n]) |
返回一个带最后n个值屏蔽的str屏蔽版本。大写字母转换为"X",小写字母转换为"X",数字转换为"n"。例如: mask_last_n("1234-5678-8765-4321",4)生成1234-5678-8765-nnnn。 |
| string |
mask_show_first_n(string str[, int n]) |
返回str的掩码版本,显示未掩码的前n个字符。大写字母转换为"X",小写字母转换为"X",数字转换为"n"。例如,mask_show_first_n("1234-5678-8765-4321",4)生成1234-nnnn-nnnn-nnnn -nnnn。 |
| string |
mask_show_last_n(string str[, int n]) |
返回str的掩码版本,显示最后n个未掩码的字符。大写字母转换为"X",小写字母转换为"X",数字转换为"n"。例如,mask_show_last_n("1234-5678-8765-4321",4)的结果是nnnn-nnnn-nnnn-4321。 |
| string |
mask_hash(string|char|varchar str) |
返回基于str的散列值。散列是一致的,可以用于跨表连接带屏蔽的值。对于非字符串类型,此函数返回null。 |
Hive常用函数总结
1.字符串操作函数
字符串长度函数:length(string str)
返回字符串A的长度;返回值为int类型。
注意:impala中length以字节为单位,一个汉字占3个字节.
举例:hive> select length('abcedfg') ;
7
字符串反转函数:reverse(string str)
返回字符串A的反转结果
举例:hive> select reverse('abcedfg') ;
gfdecba
字符串连接函数:concat(string|binary A, string|binary B...)
作用:将多个字符串连接成一个字符串。
语法:concat(str1, str2,...)
返回结果为连接参数产生的字符串,如果有任何一个参数为null,则返回值为null.
举例:hive> select concat('foo', 'bar') ;
'foobar'
带分隔符字符串连接函数:concat_ws(string SEP, string A, string B...)
作用:返回两输入字符串以指定分隔符连接后的结果。
SEP表示各个字符串间的分隔符,可以一次性指定分隔符~(concat_ws就是concat with separator),但是分隔符不能为null,如果为null则返回结果为null。
举例:hive> select concat_ws(',','abc','def','gh') ;
abc,def,gh
字符串截取函数:substr(string A, int start) | substring(string A, int start)
说明:返回字符串A从start位置到结尾的字符串,下标从1开始。
举例:hive> select substr('abcde',3) ;
cde
hive> select substring('abcde',3) ;
cde
hive> select substr('abcde',-1) ;
e
字符串转大写函数:upper(string A) | ucase(string A)
返回字符串A的大写格式
举例:hive> select upper('abSEd') ;
ABSED
hive> select ucase('abSEd') ;
ABSED
字符串转小写函数:lower(string A) | lcase(string A)
返回字符串A的小写格式
举例:hive> select lower('abSEd') ;
absed
hive> select lcase('abSEd') ;
absed
去空格函数:trim(string str)
去除字符串两边的空格
举例:hive> select trim(' abc ') ;
abc
左边去空格函数:ltrim(string str)
去除字符串左边的空格
举例:hive> select ltrim(' abc ') ;
abc
右边去空格函数:rtrim(string str)
去除字符串右边的空格
举例:hive> select rtrim(' abc ') ;
abc
分割字符串函数: split(string str, string pat)
作用: 按照pat字符串分割str,返回分割后的字符串数组
举例:hive> select split('abtcdtef','t') ;
["ab","cd","ef"]
重复字符串函数:repeat(string str, int n)
返回重复n次后的str字符串
举例:hive> select repeat('abc',5) ;
abcabcabcabcabc
左补足函数:lpad(string str, int len, string pad)
作用:用pad将str进行左补足到len位,如果str自身长度超过len,则将str从做开始截取到len位。与GP、ORACLE不同,pad 不能默认。
举例:hive> select lpad('abc',10,'td') ;
tdtdtdtabc
hive> select lpad('abcabcabcabcabc',10,'td') ;
abcabcabca
右补足函数:rpad(string str, int len, string pad)
作用:用pad将str进行右补足到len位,如果str自身长度超过len,则将str从做开始截取到len位。
举例:hive> select rpad('abc',10,'td') ;
abctdtdtdt
空格字符串函数: space(int n)
作用:返回长度为n的空字符串
举例:hive> select space(10) ;
hive> select length(space(10)) ;
10
2.正则匹配函数
正则替换函数:regexp_replace(string A, string B, string C)
说明:将字符串A中的符合java正则表达式B的部分替换为C。
注意,在有些情况下要使用转义字符.
\\d表示匹配所有数字;\\D表示匹配所有非数字
举例:hive> select regexp_replace('foobar','oo|ar', '') ;
fb
正则解析函数:regexp_extract(string subject, string pattern, int index)
作用:将字符串subject按照pattern正则表达式的规则拆分,返回index指定的字符。
第三个参数index: 0 显示与之匹配的整个字符串;1 显示第一个括号里面的;2 显示第二个括号里面的字段...
注意,在有些情况下要使用转义字符。
举例:hive> select regexp_extract('foothebar', 'foo(.*?)(bar)', 1) ;
the
hive> select regexp_extract('foothebar', 'foo(.*?)(bar)', 2) ;
bar
hive> select regexp_extract('foothebar', 'foo(.*?)(bar)', 0) ;
foothebar
3.解析函数
URL解析函数:parse_url(string urlString, string partToExtract [, string keyToExtract])
说明:返回URL中指定的部分。
partToExtract的有效值为:HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, USERINFO.
示例:hive> select parse_url('http://baidu.com/aaa/bbb/?k1=v1’, 'HOST') ;
结果: baidu.com
hive> select parse_url('http://baidu.com/aaa/bbb/?k1=v1’, ‘PATH’) ;
结果: /aaa/bbb
hive> select parse_url('http://baidu.com/aaa/bbb/?k1=v1’,'QUERY','k1’) ;
结果: v1
json解析函数:get_json_object(string json_string, string path)
说明:解析json格式的字符串json_string,返回path指定的内容(String类型)。如果输入的json字符串无效,则返回NULL。
参数二中的值用 $ 开头.后面通过 .key 获取值。如果通过 .key 获取的值有多个结果,则返回数组类型的结果。
示例:
select get_json_object('{
"store": "fruit":\[{"weight":8,"type":"apple"},{"weight":9,"type":"pear"}],},
"email":"amy@only_for_json_udf_test.net",
"owner":"amy"
}’, ‘$.owner’);结果: amy
可通过 ‘$.store.fruit获取 [{"weight":8,"type":"apple"},{"weight":9,"type":"pear"}]
可通过 ‘$.store.fruit.type’ 获取 [“apple”,”pear”]
编码解析:decode(binary bin, string charset)
作用:解决默认转码没有GBK中文字符集的问题
使用提供的字符集(' US-ASCII '、' ISO-8859-1 '、' UTF-8 '、' UTF-16BE '、' UTF-16LE '、' UTF-16 ')将第一个参数解码为字符串。如果任一参数为空,结果也为空。(从Hive0.12.0开始)
万能映射:reflect(class_name,method_name,column1,column2)
Reflect (Generic) UDF:必须是静态方法
SELECT reflect("java.lang.String", "valueOf", 1),
reflect("java.util.UUID", "randomUUID"),
reflect("java.lang.String", "isEmpty"),
reflect("java.lang.Math", "max", 2, 3),
reflect("java.lang.Math", "min", 2, 3),
reflect("java.lang.Math", "round", 2.5),
reflect("java.lang.Math", "exp", 1.0),
reflect("java.net.URLDecoder", "decode", "%cb%d1%b9%b7","GBK")
FROM src LIMIT 1;结果: 1 true 3 2 3 2.7182818284590455 搜狗
4.聚合函数:
1)求总行数(count)
select count(1) from score;
count(*) 所有值不全为NULL时,加1操作
count(1) 不管有没有值,只要有这条记录,值就加1
count(col) 只对col列中不为null的值进行计数,值为NULL时过滤该行.
2)求分数的最大值(max)
select max(s_score) from score;
3)求分数的最小值(min)
select min(s_score) from score;
4)求分数的总和(sum)
select sum(s_score) from score;
5)求分数的平均值(avg)
select avg(s_score) from score;
5.日期函数
Hive解析的日期格式默认以 - 分隔。
获取年、月、日、小时、分钟、秒、当年第几周
select
year('2018-02-27 10:00:00') as year,
month('2018-02-27 10:00:00') as month,
day('2018-02-27 10:00:00') as day,
hour('2018-02-27 10:00:00') as hour,
minute('2018-02-27 10:00:00') as minute,
second('2018-02-27 10:00:00') as second,
weekofyear('2018-02-27 10:00:00') as weekofyear;返回结果:

获取当前时间:
select
current_timestamp() current_timestamp0,
unix_timestamp() unix_timestamp0,
from_unixtime(unix_timestamp()) from_unixtime0,
current_date() current_date0;返回结果:

from_unixtime:转化unix时间戳到当前时区的时间格式
select from_unixtime(1323308943,'yyyyMMdd'); -- 1323308943转成20111208
select from_unixtime(unix_timestamp('20171205','yyyyMMdd'),'yyyy-MM-dd') --20171205转成2017-12-05
unix_timestamp:获取当前unix时间戳
select unix_timestamp(); -- 输出:1430816254
select unix_timestamp('2015-04-30 13:51:20'); -- 输出:1430373080
next_day(date, week)
计算给出日期date之后的下一个星期week的日期。
参数二(week)可选值为: ‘Mo’、’Tu’、’We’、’Th’、’Fr’、’Sa’、’Su’、或前面星期几的全拼:
Monday, Tuesday, Wednesday , Thursday, Friday, Saturday, Sunday。
返回日期的格式为"YYYY-MM-DD"
last_day(date)
返回从提供的日期值参数中提取的当月最后一天。
date格式为"yyyy-MM-dd"的字符串(开头为该形式即可)
返回的值是1到31之间的值
如果输入不正确则返回NULL。yyyy-MM-dd 是事先约定的输入格式
add_months( date, n )
返回从提供的日期值参数中提取的当月最后一天。返回日期加上n个月。
日期是开始日期(在添加n个月之前)。n是到目前为止需要增加的月数。
注:目前输入的date格式为"yyyy-MM-dd"或者"yyyyMMdd"(以这个格式开头的都可以接受,否则返回null,下面同上),返回字符串也是这个格式
datediff(string enddate, string startdate)
返回开始日期减去结束日期的天数
select datediff('2015-04-09','2015-04-01');
输出:8
to_char(date,format)
将日期date转化为一个字符串;date 的格式固定为yyyy-mm-dd hh24:mi:ss:ff3,输出的格式由format 指定。format 当前支持的格式如下(不区分大小写):
yyyymmdd: 年月日;
yyyymm: 年月;
mm: 月
dd: 日
yyyy-mm-dd: 年-月-日;
yyyy-mm: 年-月;
yyyymmddhh24miss: 年月日时分秒(24小时制)
yyyy-mm-dd hh24:mi:ss: 年-月-日 时:分:秒
hh24miss: 时分秒
yyyymmddhh24missff3: 年月日时分秒毫秒(24小时制)date_add(string startdate, int days)
在startdate中增加days天数(往后推),返回 yyyy-mm-dd 格式的新日期:
select date_add('2008-12-31', 1) ;
输出:2009-01-01
select date_add('2015-04-09',4);
输出:2015-04-13
date_sub(string startdate, int days)
在startdate中减去days天数(往前推),返回 yyyy-mm-dd 格式的新日期:
select date_sub('2015-04-09',4);
输出:2015-04-05
to_date:日期时间转日期
将带有时分秒额外时间信息的日期类型转换为只包含年月日类型的日期:
select to_date('2015-04-02 13:34:12');
输出:2015-04-02
6.开窗函数--窗口函数与分析函数
开窗函数就是定义一个行为列,简单讲,就是在你查询的结果上直接多出一列值(可以是聚合值或是排序号),特征就是带有over()。
使用场景:开窗函数适用于在每一行的最后一列添加聚合函数的结果。
(1)用于分区排序;(2)动态分组;(3)Top N;(4)累加计算;(5)层次查询
注意:开窗函数只能出现在 SELECT 或 ORDER BY 子句中.
OVER从句
1.使用标准的聚合函数COUNT、SUM、MIN、MAX、AVG
2.使用PARTITION BY语句,使用一个或者多个原始数据类型的列
3.使用PARTITION BY与ORDER BY语句,使用一个或多个数据类型的分区或者排序列
4.使用窗口规范,窗口规范支持以下格式:
(rows | range) between (unbounded | [num]) preceding and ( [num] preceding | current row | (unbounded | [num]) following)
(rows | range) between current row and (current row | (unbounded | [num]) following)
(ROWS | RANGE) BETWEEN [num] FOLLOWING AND (UNBOUNDED | [num]) FOLLOWINGorder by子句可以对结果集按照指定的排序规则进行排序,并且在一个指定的范围内进行聚合运算。
order by子句(也叫做WINDOW子句)的语法为:
order by 字段名 range|rows between 边界规则1 and 边界规则2。
range|rows between 边界规则1 and 边界规则2,这个子句又被称为定位框架。
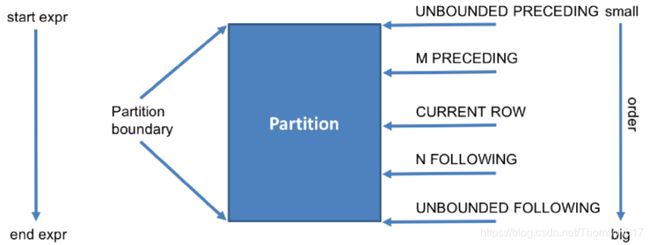
range是按照值的范围进行范围的定义,rows是按照行的范围进行范围的定义,边界范围可取值:
PRECEDING:往前(n preceding:前N行,比如 2 preceding)
FOLLOWING:往后(n following:后N行)
CURRENT ROW:当前行
UNBOUNDED:无界限(起点或终点)
UNBOUNDED PRECEDING:一直到第一条记录
UNBOUNDED FOLLOWING:一直到最后一条记录当ORDER BY后面缺少窗口子句条件,窗口规范默认是: range between unbounded preceding and current row.
当ORDER BY和窗口子句都缺失, 窗口规范默认是: rows between unbounded preceding and unbounded following.
注意:结果和ORDER BY相关,默认为升序
如果不指定ROWS BETWEEN,默认为从起点到当前行;
如果不指定ORDER BY,则将分组内所有值累加;
OVER从句支持以下函数,但是并不支持和窗口一起使用它们:
Ranking函数: NTile、Rank、Dense_Rank、Row_Number、Cume_Dist、Percent_Rank.
Lead和Lag函数.
聚合函数(sum、count、max、min、avg...)
--例如:
sum(sales)over(partition by user_type order by sales asc rows between unbounded preceding and current row) as sales_2;
over语句还可以独立出来,用window重写,但需要注意的是,如果sort by使用了多个字段,如果用range指定窗口的话会出错,需要用rows来指定窗口,因为range是对列的比较,不支持多列比较。
--例如
select
shop_id,
stat_date,
ordamt,
sum(ordamt) over win as t
from rt_data
where dt = '2015-01-11' and shop_id = 10026
window win as (distribute by shop_id sort by shop_id, ordamt desc rows between unbounded preceding and current row);over(partition by ......)与group by 区别:
group by可以实现同样的分组聚合功能,但sql语句不能写与分组聚合无关的字段,否则会报错,即group by与over(partition by ......)主要区别为:
带上group by的hive sql语句只能显示与分组聚合相关的字段;
而带上over(partition by ......)的hql语句能显示所有字段.
窗口聚合函数
可以计算一定范围内、一定值域内或者一段时间内的累积和以及移动平均值等。
可以结合聚集函数SUM() 、AVG() 等使用。
SQL标准允许将所有聚合函数用做开窗函数,只需要在聚合函数后加over()即可。
count() over(partition by ... order by ...) : 行数统计
max() over(partition by ... order by ...) : 计算最大值
min() over(partition by ... order by ...) : 计算最小值
sum() over(partition by ... order by ...) : 求和
avg() over(partition by ... order by ...) : 求平均数
stddev_samp()over() : 计算样本标准差,只有一行数据时返回null
stddev_pop()over() : 计算总体标准差
variance()over() : 计算样本方差,只有一行数据时返回0
var_samp()over() : 计算样本方差,只有一行数据时返回null
var_pop()over() : 计算总体方差
covar_samp()over() : 计算样本协方差
covar_pop()over() : 计算总体协方差
在Hive 2.1.0及以后版本中(参见Hive -9534)提供了对Distinct的支持。
Distinct支持聚合函数,包括SUM、COUNT和AVG,这些函数通过每个分区内的不同值进行聚合。当前实现的限制是,出于性能考虑,分区子句中不支持ORDER BY或window规范。
示例:
本例的数据源: select * from wx_tmp1;
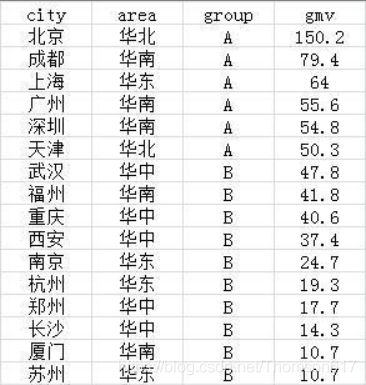
需求1:要在源表中,增加两列,全国总的gmv和各城市的gmv占比。
select *,
sum(gmv) over() as all_gmv,
gmv/sum(gmv) over() as gmv_pro
from wx_tmp1;
需求2:要在源表中,增加两列,各区域的gmv及各分组的gmv。
select *,
sum(gmv) over(partition by area) as area_gmv,
sum(gmv) over(partition by group) as group_gmv
from wx_tmp1;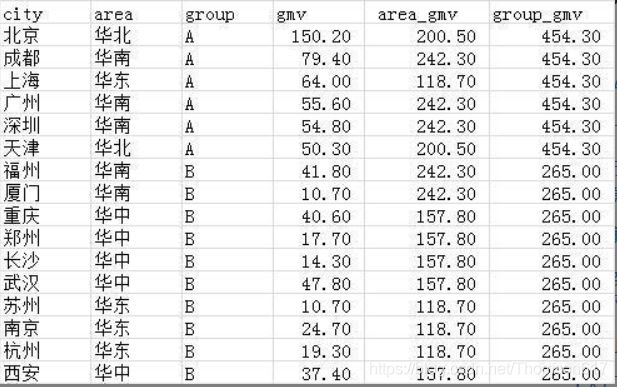
窗口分析函数
FIRST_VALUE、LAST_VALUE
-- FIRST_VALUE() 获得组内当前行往前的首个值
-- LAST_VALUE() 获得组内当前行往前的最后一个值
-- FIRST_VALUE(DESC) 获得组内全局的最后一个值
最多接受两个参数。第一个参数是您想要第一个值的列,第二个(可选)参数必须是一个布尔值,默认情况下为false。如果设置为true,它跳过空值。
select dp_id, mt, payment,
FIRST_VALUE(payment)over(partition by dp_id order by mt) payment_g_first,
LAST_VALUE(payment) over(partition by dp_id order by mt) payment_g_last,
FIRST_VALUE(payment)over(partition by dp_id order by mt desc) payment_g_last_global
from test2 ORDER BY dp_id,mt;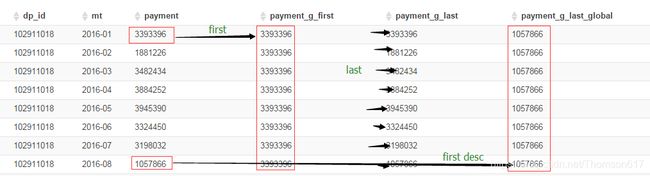
注意:如果不指定ORDER BY,则默认按照记录在文件中的偏移量进行排序,会出现错误的结果。
last_value默认的窗口是RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,表示当前行永远是最后一个值,需改成RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING。
Lag、Lead
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值.(复制目标列, 并后移n行)
第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为匹配空行对应的指定默认值(当往上第n行为NULL时取默认值,如不指定则为NULL)。
LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值, 与LAG相反。
lag 和lead 可以获取结果集中按一定排序所排列的当前行的上下相邻若干offset 的某个行的某个列(不用结果集的自关联).
select dp_id, mt, payment, LAG(mt,2) over(partition by dp_id order by mt) mt_new from test2;
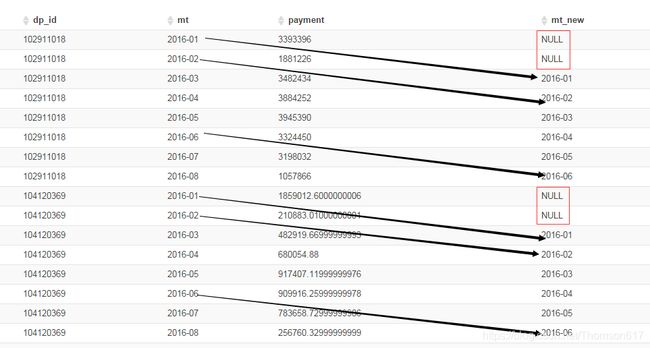
-- 组内排序后,向后或向前偏移
-- 如果省略掉第三个参数,默认为NULL,否则补上。
select dp_id, mt, payment, LEAD(mt,2,'1111-11') over(partition by dp_id order by mt) mt_new from test2;
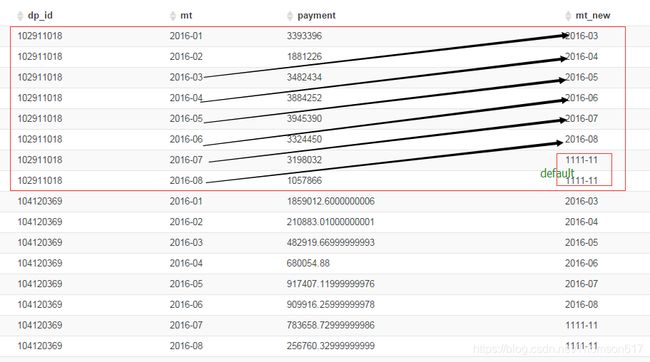
cume_dist
计算某个窗口或分区中某个值的累积分布(小于等于当前值的行数/分组内总行数)。
假定升序排序,则使用以下公式确定累积分布:小于等于当前值x的行数 / 窗口或partition分区内的总行数。其中x 等于 order by 子句中指定的列的当前行中的值。如果存在并列情况,则需加上并列的个数-1。
比如统计小于等于当前薪水的人数所占总人数的比例:
SELECT dept, userid, sal,
CUME_DIST() OVER(ORDER BY sal) AS rn1,
CUME_DIST() OVER(PARTITION BY dept ORDER BY sal) AS rn2
FROM tb;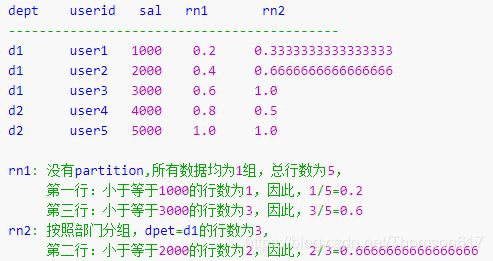
窗口排序函数
用于等级、百分点、n分片等。
Ntile
NTILE 分析函数将分区中已排序的行划分为大小尽可能相等的指定数量的已排名组,并返回给定行所在的组。可以看成是:它把有序的数据集合 平均分配 到 指定的数量(num)个桶中, 将桶号分配给每一行。如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1。如果切片不均匀,默认增加第一个切片的分布。NTILE不支持ROWS BETWEEN。语法是:
ntile (num) over ([partition_clause] order_by_clause) as your_bucket_num
然后可以根据桶号,选取前或后 n分之几的数据。
例子:给了用户和每个用户对应的消费信息表, 计算花费前50%的用户的平均消费
-- 把用户和消费表,按消费下降顺序平均分成2份
drop table if exists test_by_payment_ntile;
create table test_by_payment_ntile as
select
nick,
payment,
NTILE(2) OVER(ORDER BY payment desc) as rn
from test_nick_payment;-- 例2
select name, orderdate, cost,
ntile(3) over() as sample1 , --全局数据切片
ntile(3) over(partition by name), -- 按照name进行分组,在分组内将数据切成3份
ntile(3) over(order by cost), -- 按照cost全局升序排列,数据切成3份
ntile(3) over(partition by name order by cost ) -- 按照name分组,在分组内按照cost升序排列,数据切成3份
from t_windowRank,Dense_Rank, Row_Number
(hive0.11.0版本开始加入)3个组内排序函数,也叫做排序开窗函数。语法为:
R()over (partion by col1... order by col2... desc/asc)
rank 会对相同数值输出相同的序号,但是下一个序号会间断;
dense_rank 会对相同数值输出相同的序号,而且下一个序号不间断;
row_number 会对所有数值输出不同的序号,序号唯一连续。
示例:
select class1,score,
rank() over(partition by class1 order by score desc) rk1,
dense_rank() over(partition by class1 order by score desc) rk2,
row_number() over(partition by class1 order by score desc) rk3
from zyy_test1;如下图所示:
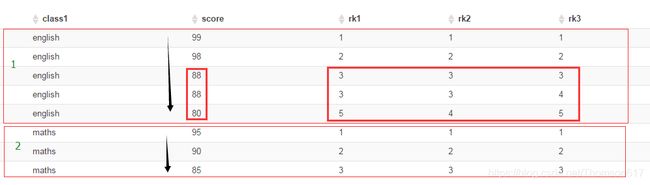
注意:当使用order by 排序,desc时NULL值排在首位,ASC时NULL值排在末尾.
可以通过NULLS LAST、NULLS FIRST 控制:
RANK() OVER (ORDER BY column_name DESC NULLS LAST)
PARTITION BY 分组排列顺序:
RANK() OVER(PARTITION BY month ORDER BY column_name DESC)
这样,就会按照month 来分,即所需要排列的信息先以month 的值来分组,在分组中排序,各个分组间不干涉。
percent_rank
计算给定行的百分比排名。排名计算公式为:(current rank - 1)/(total number of rows - 1)。
返回值范围介于 0 和 1(含 1)之间。任何集合中的第一行的 PERCENT_RANK 均为 0。
例如360小助手开机速度超过了百分之多少的人:
select
studentid, departmentid, classid, math,
row_number() over(partition by departmentid,classid order by math) as row_number,
percent_rank() over(partition by departmentid,classid order by math) as percent_rank
from student_scores;结果:
studentid departmentid classid math row_number percent_rank
115 department1 class1 93 4 0.75
114 department1 class1 94 5 1.0
124 department1 class2 70 1 0.0
121 department1 class2 74 2 0.3333333333333333
123 department1 class2 78 3 0.6666666666666666
122 department1 class2 86 4 1.0结果解释:
studentid=115,percent_rank=(4-1)/(5-1)=0.75
studentid=123,percent_rank=(3-1)/(4-1)=0.6666666666666666
7.Hive行列转换函数
行转列(一对多)
使用函数:lateral view explode(split(column, ',')) num as 别名
explode接受array或map作为输入,并将array或map的元素作为单独的行输出。UDTFs可以在select表达式列表中使用,并作为LATERAL VIEW的一部分。
作为在SELECT表达式列表中使用explode()的一个例子,考虑一个名为myTable的表,它只有一列(myCol)和两行:
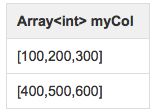
然后执行如下查询:
SELECT explode(myCol) AS myNewCol FROM myTable;
输出如下:

map的用法类似:
SELECT explode(myMap) AS (myMapKey, myMapValue) FROM myMapTable;
总结起来一句话:explode就是将hive一行中复杂的array或者map结构拆分成多行。
LATERAL VIEW(横向视图)语法为:
lateralView: LATERAL VIEW udtf(expression) tableAlias AS columnAlias (’,’ columnAlias)*
fromClause: FROM baseTable (lateralView)*
LATERAL VIEW的作用是配合explode(或者其他的UDTF)将单行数据拆解成多行后的数据结果集。在此基础上可以对拆分后的数据进行聚合。LATERAL VIEW与用户定义的表生成函数(如explode())一起使用。正如内置表生成函数中提到的,UDTF为每个输入行生成0或更多输出行。
lateral view首先为原始表的每行调用UDTF,UDTF会把一行拆分成一或者多行,lateral view再将结果组合(将结果输出行连接到输入行),产生一个支持别名表的虚拟表。
注意:LATERAL VIEW是用来生成用户自定义表以展开的形式显示map或array的值,如同explode(),但它会忽略值为NULL的列,如果要显示这些列,可以使用LATERAL VIEW OUTER explode(field)(Hive0.12.0之后版本)。Outer关键字可以把不输出的UDTF的空结果,输出成NULL,防止丢失数据。
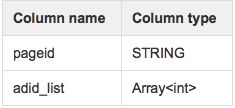
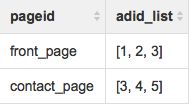
示例:考虑下面一个名为pageAds的基表。它有两列:pageid和adid_list
它有两行数据:
用户想要计算一个广告在所有页面中出现的总次数。
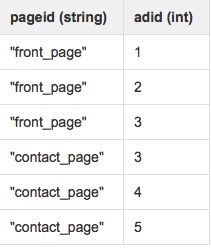
使用一个带有explode()的横向视图,可以使用查询将adid_list转换为单独的行:
SELECT pageid, adid
FROM pageAds
LATERAL VIEW explode(adid_list) adTable AS adid;结果如下:
然后,为了计算一个特定广告出现的次数,可以使用count/group by:
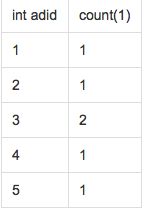
SELECT adid, count(1)
FROM pageAds
LATERAL VIEW explode(adid_list) adTable AS adid
GROUP BY adid;结果为:
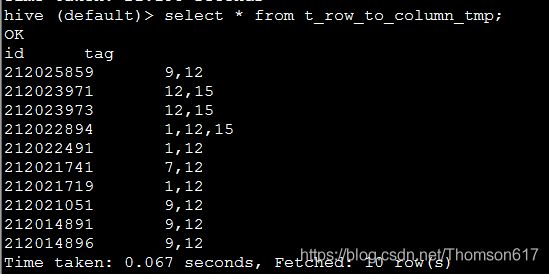
示例2: 表t_row_to_column_tmp的数据如下
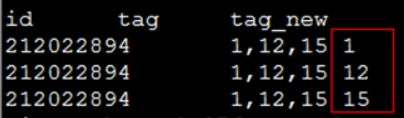
对tag列进行拆分:
select id,tag,tag_new
from t_row_to_column_tmp
lateral view explode(split(tag, ',')) num as tag_new
where id=212022894;结果为:
列转行(多对一)
使用函数:concat_ws(',',collect_set(column))
说明:collect_list不去重,collect_set去重。column的数据类型要求是string.
一般和case when一起使用.
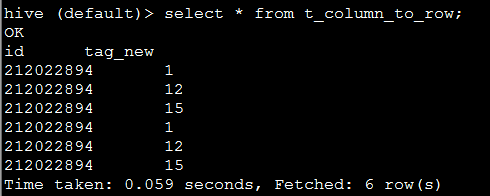
例一:如表t_column_to_row ,根据id对tag_new 进行合并
SQL代码:
select id, concat_ws(',',collect_set(tag_new)) as tag_col from t_column_to_row group by id;
执行结果:
![]()
例二: 原始数据格式:

现在的目标是转为一行,即:
productid 服务 位置 设施
344920 ** ** ** 现在想到的方式case when 结合concat_ws与collect_set实现,代码如下:
select productid,
concat_ws('',collect_set(fuwu)) as `服务`,
concat_ws('',collect_set(weizhi)) as `位置`,
concat_ws('',collect_set(sheshi)) as `设施`
from
( select productid,
case when tagtype='位置' then highlight else '' end as weizhi,
case when tagtype='服务' then highlight else '' end as fuwu,
case when tagtype='设施' then highlight else '' end as sheshi
from dw_htl.tmp_dianpingt
) a
group by productid;效果如下:

例三: 使用case ... when...
id 分类 明细
1 a a1
2 a a2
1 b b1
2 b b2
1 c c1
2 c c2
select id,
(case `分类` when 'a' then `明细` else 0 end) a,
(case `分类` when 'b' then `明细` else 0 end) b,
(case `分类` when 'c' then `明细` else 0 end) c
from tableName
group by id;想查询得到下面的显示:
id a b c
1 a1 b1 c1
2 a2 b2 c28.高级聚合
GROUPING SETS,Grouping_ID,CUBE,ROLLUP这几个分析函数通常用于OLAP中,不能累加,而且需要根据不同维度上钻和下钻的指标统计,比按小时、天、月统计UV数。
(1).GROUPING SETS
该关键字可以实现对同一个数据集的多重GROUP BY操作。事实上GROUPING SETS是多个GROUP BY进行UNION ALL操作的简单表达,它仅使用一个stage完成这些操作。GROUPING SETS的子句中如果包换()数据集,则表示整体聚合。
grouping sets为自定义维度,根据需要分组即可。例:
SELECT
name,
work_place AS main_place,
count(employee_id) AS emp_id_cnt
FROM employee_id
GROUP BY name, work_place
GROUPING SETS((name, work_place), name, work_place, ());等价于
SELECT name, work_place AS main_place, count(employee_id) AS emp_id_cnt
FROM employee_id
GROUP BY name, work_place
UNION ALL
SELECT name, NULL AS main_place, count(employee_id) AS emp_id_cnt
FROM employee_id
GROUP BY name
UNION ALL
SELECT NULL AS name, work_place AS main_place, count(employee_id) AS emp_id_cnt
FROM employee_id
GROUP BY work_place
UNION ALL
SELECT NULL AS name, NULL AS main_place, count(employee_id) AS emp_id_cnt
FROM employee_id;然而GROUPING SETS目前还有未解决的问题,参考HIVE-6950
在我们使用grouping sets时,会产生null值,这个时候就会与数据记录中本身的null值混在一起而无法区分,Hive提供了一种标记的方法,可以用来识别这种情况。
(2).Grouping_ID函数
此函数返回与每列是否存在相对应的位向量。grouping__id的生成机制是group by 后面内容的二进制对应的十进制值。
Grouping__ID函数在Hive 2.3.0中得到修复,因此该版本之前的行为是不同的(这是预期的)。对于每列,如果该列已在该行中聚合,则为结果集中的行生成值"1",否则该值为"0"。这可用于区分数据中是否存在空值。当我们没有统计某一列时,它的值显示为null,这可能与列本身就有null值冲突,这就需要一种方法区分是没有统计还是值本来就是null。(grouping_id其实就是统计各列二进制和).例如:
SELECT key, value, GROUPING__ID, count(*) as c1 FROM T1 GROUP BY key, value WITH ROLLUP;
将得到以下结果:
| key |
value |
GROUPING__ID |
c1 |
| NULL |
NULL |
3 |
6 |
| 1 |
NULL |
0 |
2 |
| 1 |
NULL |
1 |
1 |
| 1 |
1 |
0 |
1 |
| 2 |
NULL |
1 |
1 |
| 2 |
2 |
0 |
1 |
| 3 |
NULL |
0 |
2 |
| 3 |
NULL |
1 |
1 |
| 3 |
3 |
0 |
1 |
| 4 |
NULL |
1 |
1 |
| 4 |
5 |
0 |
1 |
注意:第三列是选定列的位向量。对于第一行,没有选择任何列。对于第二行,两个列都被选中(第二列恰好为空),这解释了值0。对于第三行,只选择了第一列,这解释了值1。
(3).ROLLUP和CUBE
这两个关键字都是GROUP BY的高级实现。grouping sets实现了指定组合的多维分析,Cube则可以穷举全部可能,Rollup则是一种降维分析。cube的分组组合最全,是各个维度值的笛卡尔(包含null)组合,rollup的各维度组合应满足前一维度为null后一位维度必须为null,前一维度取非null时下一维度随意。对比于规定了n层聚合的GROUPING SETS,ROLLUP会创建n+1层聚合,在此n表示分组列的个数。
GROUP BY a, b, c WITH ROLLUP
等价于 GROUP BY a,b,c GROUPING SETS ((a,b,c),(a,b),(a),())
CUBE将会对分组列进行所有可能的组合聚合。如果为CUBE指定了n列,则将返回2^n个聚合组合。
GROUP BY a, b, c WITH CUBE
等价于 GROUP BY a,b,c GROUPING SETS ((a,b,c),(a,b),(b,c),(a,c),(a),(b),(c),())
hive.new.job.grouping.set.cardinality
此参数决定hive是否应添加新的map-reduce作业以对集合/汇总/多维数据集进行分组。如果分组设置基数超过此值,则在假设原始分组将减小数据大小的情况下添加新的MR作业。
当维度过高,且统计语句中使用了 count distinct语句,就有可能出现如下报错:

此时可以通过以下语句突破这个限制: set hive.new.job.grouping.set.cardinality = 256;
其中256 为可以调节的数字,一般这个数字要大于你的维度的最高值,但是切记要慎用,一般维度最好不要超过7维,否则对集群压力会比较大。
一般生产环境多维统计时,最好先对维度列进行一次null填充,统计完后,再进行一次null填充,一般第一次使用-99999,第二次使用-100000,这样就可以方便的区分出null值了。
(4).GROUPING
GROUPING指示对于给定行是否聚合GROUP BY子句中的表达式。值0表示作为分组集的一部分的列,而值1表示不属于分组集的列。 例如:
SELECT key, value, GROUPING__ID,
grouping(key, value) as c1,
grouping(value, key) as c2,
grouping(key) as c3,
grouping(value) as c4,
count(*) as c5
FROM T1
GROUP BY key, value WITH ROLLUP;此查询将产生以下结果:
| key |
value |
GROUPING__ID |
c1 |
c2 |
c3 |
c4 |
c5 |
| NULL |
NULL |
3 |
3 |
3 |
1 |
1 |
6 |
| 1 |
NULL |
0 |
0 |
0 |
0 |
0 |
2 |
| 1 |
NULL |
1 |
1 |
2 |
0 |
1 |
1 |
| 1 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
| 2 |
NULL |
1 |
1 |
2 |
0 |
1 |
1 |
| 2 |
2 |
0 |
0 |
0 |
0 |
0 |
1 |
| 3 |
NULL |
0 |
0 |
0 |
0 |
0 |
2 |
| 3 |
NULL |
1 |
1 |
2 |
0 |
1 |
1 |
| 3 |
3 |
0 |
0 |
0 |
0 |
0 |
1 |
| 4 |
NULL |
1 |
1 |
2 |
0 |
1 |
1 |
| 4 |
5 |
0 |
0 |
0 |
0 |
0 |
1 |
9.其他函数
空值转换函数: nvl(x,y)
如果x为null就返回y,不为null就返回自身x
首字符ascii函数: ascii(string str)
作用:返回字符串str第一个字符的ascii码,返回值为int类型。
举例:hive> select ascii('abcde') ;
97
集合查找函数: find_in_set(string str, string strList)
说明: 返回str在strlist第一次出现的位置,strlist是用逗号分割的字符串。如果没有找该str字符,则返回0
举例:hive> select find_in_set('ab','ef,ab,de'), find_in_set('at','ef,ab,de') ;
2 0
位置查找函数: instr((string,str[,start][,appear])
返回string 中str 出现的位置.
start 代表开始搜索的位置,可选参数,默认为1(1表示第一个字符位置);
appear 指示搜索第几次出现的,可选参数,默认为1;若没有匹配到,返回0。
mod(n1,n2)
返回一个n1 除以n2 的余数。支持的类型有Byte、Short、Integer、Long、Float、Double。返回值的正负和n1 相关。使用此函数需要注意的2 个问题:
·对小数执行mod 计算可能会产生精度丢失.
如:mod(3.1415926535897384626,3.1415926535897384627,返回结果为0.0)
·传入比MAX_LONG还大的整数作为参数,则参数会被自动升级成Double 类型,函数也可以正常计算结果,但返回的结果是小数类型。