Flink——Flink状态与容错恢复
文章目录
- Flink State概念
-
- 1. 有状态操作应用场景
- 2. 状态的作用
- Flink State类型及使用
-
- 1. Flink State类型概述
- 2. Keyed State
-
- 1. Keyed State概述
- 2. Keyed State使用
- 3. Operator State
-
- 1. Operator State概述
- 2. BroadcastState
- 3. Operator State使用
- Flink容错及State持久化
- Flink State Backends
-
- 1. MemoryStateBackend
-
- 1. 状态存储
- 2. 容量限制
- 3. 适用场景
- 4. 配置方式
- 2. FsStateBackend
-
- 1. 状态存储
- 2. 容量限制
- 3. 适用场景
- 4. 配置方式
- 3. RocksDBStateBackend
-
- 1. 状态存储
- 2. 容量限制
- 3. 适用场景
- 4. 配置方式
- 4. 总结
- 参考
Flink State概念
我们先来看下Flink官网对“有状态的(stateful)”的定义:
While many operations in a dataflow simply look at one individual event at a time (for example an event parser), some operations remember information across multiple events (for example window operators). These operations are called stateful.
翻译过来就是:虽然数据流(dataflow)中的许多操作只处理单条事件(例如事件解析器),但是有些操作要记录多条事件的信息进行处理(比如窗口操作),那么这些操作就是有状态的。
个人认为官网上的解释还是有些抽象,看了之后还是没说清什么是状态。我个人对Flink中状态的理解就是:数据流中过去某段时间的事件记录,或者过去的N条事件记录,或过去符合指定匹配规则的事件记录,等等。
1. 有状态操作应用场景
有状态操作应用举例:
- 当应用程序搜索特定的事件模式时,状态存储的是到目前为止出现的事件
- 当按分钟/小时/天对事件进行聚合时,状态存储的是待聚合的操作
- 当在数据流上训练一个机器学习模型时,状态存储的是模型当前版本的参数
- 当需要管理历史数据时,状态允许访问过去发生的事件。
2. 状态的作用
Flink使用checkpoint/savepoint来保存状态进而实现容错。
Flink State类型及使用
1. Flink State类型概述
Flink State分为:Raw State和Managed State。Raw State是一种内部状态,其数据结构对Flink是不可见的,而Managed State是由Flink自动管理的状态。
Raw State和Managed State的区别:
- State管理:Raw State是由用户来管理的,只有用户自己知道Raw State中的数据结构,另外,需要用户自己将Raw State序列化为所要存储的数据结构;而Managed State是由Flink Runtime来管理的,Flink Runtime会自动存储、恢复并优化状态的存储。
- State数据类型:Raw State仅仅只支持字节数组,它要求所有的状态都要转成二进制的字节数组;而Managed State支持常用的数据结构,比如Value、List、Map等。
- 应用场景:Managed State适用于大多数情况;而Raw State仅仅在Managed State不能满足特定需求的情况下才被推荐使用,比如自定义的operator。
而Managed State又分为:Operator State和Keyed State。
2. Keyed State
1. Keyed State概述
Keyed State只能用于KeyedStream上,例如keyBy()操作会返回一个KeyedStream:
DataStreamSource<String> text = env.socketTextStream("hostname", 9000, "\n");
KeyedStream keyedStream = text.keyBy(value -> value.split(", ")[0]);
Keyed State中的状态是跟key绑定的,KeyedStream 上的每个key都对应一个State,而且每个key只能访问和更新自己对应的状态数据。

2. Keyed State使用
Keyed State接口提供了对不同类型状态的访问。针对Keyed State, Flink提供了下面几种可用的状态:
- ValueState: 这种状态保存了一个可用被更新和检索的值
- ListState: 保存了一个元素列表
- ReducingState: 保存了一个单独的值,这个值表示添加到此状态的所有值的聚合值。
- AggregatingState
- MapState
上面这些状态接口在Flink框架中的UML图:

另外,我们要记住的两点:
- 上面哪些状态对象仅仅是操作状态的一个接口,而真正状态中的数据并不一定存储在内存中,也可能存储在磁盘或其它地方
- 从状态中获得的值取决于输入元素的key,如果key不同,那获取的值也可能不同。
要获取一个状态的句柄,我们必须先创建一个StateDescriptor,上面提到的5种操作状态的接口都有对应的StateDescriptor类。StateDescriptor持有状态的以下信息:
- 状态的名称,以便后续通过这个名称来访问对应状态的内容
- 状态中值的数据类型
- 一个用户自定义函数,比如一个ReduceFunction
状态的访问必须要用 RuntimeContext,而 RuntimeContext 的获取必须要使用 RichFunction 接口。RuntimeContext 中获取状态的方法:
- ValueState getState(ValueStateDescriptor stateProperties)
- ListState getListState(ListStateDescriptor stateProperties)
- ReducingState getReducingState(ReducingStateDescriptor stateProperties)
- AggregatingState
- MapState
下面是一个状态使用的代码示例:
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class CountWindowAverage extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> {
//Tuple2中第一个是count,第二个是sum
private transient ValueState<Tuple2<Long, Long>> sum;
@Override
public void flatMap(Tuple2<Long, Long> input, Collector<Tuple2<Long, Long>> out) throws Exception {
//访问状态中的值
Tuple2<Long, Long> currentSum = sum.value();
//手动判断状态内容是否为null,为null时设置默认值
if (currentSum == null) {
currentSum = Tuple2.of(0L, 0L);
}
//更新count
currentSum.f0 += 1;
//更新sum
currentSum.f1 += input.f1;
//更新状态
sum.update(currentSum);
//如果count大于等于2,计算平均值并清除状态
if (currentSum.f0 >= 2) {
out.collect(new Tuple2<>(input.f0, currentSum.f1 / currentSum.f0));
sum.clear();
}
}
@Override
public void open(Configuration config) {
ValueStateDescriptor<Tuple2<Long, Long>> descriptor =
new ValueStateDescriptor<>(
"average", //状态名
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {
}) //类型
);
//获取状态句柄
sum = getRuntimeContext().getState(descriptor);
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L), Tuple2.of(1L, 4L), Tuple2.of(1L, 2L))
.keyBy(value -> value.f0)
.flatMap(new CountWindowAverage())
.print(); // the printed output will be (1,4) and (1,5)
env.execute("State Demo");
}
}
3. Operator State
1. Operator State概述
与Keyed State不同的是,Operator State可被用于所有的operator上,它与key是没有任何关系的。
在典型的有状态的Flink应用程序中,一般是不需要operator state的,operator state通常被用于Source/Sink端,例如FlinkKafkaConsumer,Kafka消费者的每个并行实例会维护一个主题分区和偏移量的映射关系作为它的operator state。每个operator实例都会对应一个State,每个operator中的子任务共享一个State。
当operator实例的并行度发生变化时,operator state接口支持多种策略进行重新分发State。Flink内建的两种状态重分配策略:1. 将State均匀分配给每个operator实例。2. 将所有状态合并,再分发给每个operator实例。
Operator State的3中状态类型:
- BroadcastState:所有task中的状态都是相同。
- ListState:状态中的所有元素被均匀地分发给子task。ListState既可以是一个keyed list state,也可以是一个operator list state。
- UnionListState;状态中的所有元素被分发给子task
2. BroadcastState
Broadcast State其实是一种特殊类型的Operator State,引入它是为了支持需要将流记录广播到所有下游task的场景,这种情况下,所有的下游task会持有相同的state。Broadcast State被广播到某个Operator的所有并发实例中,然后与另一条流连接进行计算等操作。
Broadcast State与其他Operator State的不同之处:
- Broadcast State有一个Map格式
- Broadcast State只对具有广播流和非广播流的Operator才可用
- 一个Operator可以用多个不同名称的Broadcast State
使用BroadcastState时的注意事项:
- 目前只支持保存的内存中
- 每个task都会对各自的BroadcastState做快照,以防止热点问题
- 广播流元素到达operator的各个子task的顺序可能是不相同的
- 要确保operator子task对BroadcastState的修改逻辑是一致的
3. Operator State使用
要使用Operator State,有状态的transformation函数要实现CheckpointedFunction接口,并实现它的两个方法:
//每次触发CheckPoint进行状态保存的时候,都会调用此方法
void snapshotState(FunctionSnapshotContext context) throws Exception;
//每当用户定义的函数初始化时(无论是函数首次初始化,还是函数从之前的CheckPoint恢复时),都会调用此方法。
//initializeState()不仅是初始化不同类型状态的地方,而且还包括状态的恢复逻辑。
void initializeState(FunctionInitializationContext context) throws Exception;
目前支持List格式的operator state,状态应该是一个可序列化对象的List,对象之间相互独立,因此可以在调整并行度之后重新分配,并定义有以下两种重新分配策略:
- Even-split redistribution:均匀地重分配。每个operator返回一个状态元素List,整个状态逻辑上是所有List的和。在恢复或重分配状态的时候,整个状态List会被平均地划分为与并行operators一样多的子List,每个oper都会获得一个子List,子List可以为空,也可以包含一个或多个元素。例如,并行度为1时,operator的checkpoint state包含元素e1和e2,当将并行度增加到2时,e1可能会进入operator实例1,e2将进入operator实例2。
- Union redistribution:合并重分配。每个operator返回一个状态元素List,整个状态在逻辑上是所有List的和。在恢复或重分配状态的时候,每个operator都将获得状态元素的完整List。如果状态List中的元素很多,建议不要使用此功能,因为CheckPoint metadata会存储每个List的偏移,这可能会导致OOM。
下面是一个有状态的SinkFunction的实例,它在将元素发送给外部存储之前使用CheckPointedFunction来缓存元素。下面代码展示了基本的均匀分配的List State(Even-split redistribution):
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import java.util.ArrayList;
import java.util.List;
public class BufferingSink implements SinkFunction<Tuple2<String, Integer>>, CheckpointedFunction {
private final int threshold;
private transient ListState<Tuple2<String, Integer>> checkpointedState;
private List<Tuple2<String, Integer>> bufferedElements;
public BufferingSink(int threshold) {
this.threshold = threshold;
this.bufferedElements = new ArrayList<>();
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
//清空状态中的值
checkpointedState.clear();
for (Tuple2<String, Integer> e : bufferedElements) {
//向状态中添加缓存元素
checkpointedState.add(e);
}
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
//operator state的初始化和keyed state是很相似的。同样是通过初始化一个StateDescriptor实例。
ListStateDescriptor<Tuple2<String, Integer>> desc = new ListStateDescriptor<Tuple2<String, Integer>>(
"buffered-elements", //状态名称
TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {
})); //状态所存储值的类型
//创建一个list state
checkpointedState = context.getOperatorStateStore().getListState(desc);
//创建一个union list state
//checkpointedState = context.getOperatorStateStore().getUnionListState(desc);
if (context.isRestored()) {
//状态是否是从之前的快照进行恢复的(比如应用程序崩溃失败之后)
for (Tuple2<String, Integer> e : checkpointedState.get()) {
bufferedElements.add(e);
}
}
}
@Override
public void invoke(Tuple2<String, Integer> value, Context context) throws Exception {
bufferedElements.add(value);
if (bufferedElements.size() == threshold) {
for (Tuple2<String, Integer> e : bufferedElements) {
//写到sink
}
bufferedElements.clear();
}
}
}
上面的代码示例中,在状态初始化期间,恢复的ListState会保存在一个类变量中,以便之后再snapshotState()中使用。snapshotState()会先清除前一个CheckPoint包含的所有对象,然后向checkpointedState中添加新一次CheckPoint要保存的对象。
Flink容错及State持久化
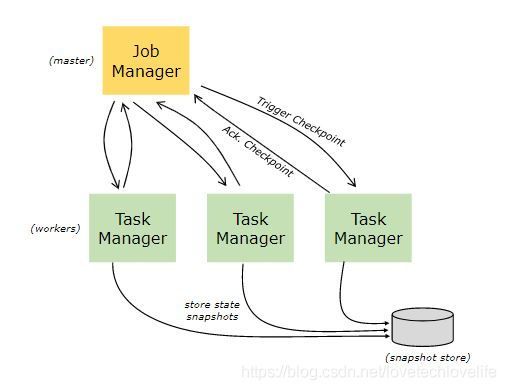
Flink使用流数据的回放和Checkpoint实现了容错。Checkpoint标记了每个输入流中特定的一个点以及每个operator对应的state。我们的Flink实时流应用程序可以从CheckPoint进行恢复,同时通过恢复operator的state并从CheckPoint重放记录来保持数据处理的一致性(Exactly-once,也即是仅且一次的处理语义)。
触发CheckPoint的间隔直接影响着容错开销和数据重放(间隔越长,失败恢复需要重放的记录就越多)的时间。
Flink的这种容错机制会对分布式数据流进行连续的快照存储。对于状态较小的流式应用程序,这些快照是非常轻量级的,可以频繁地进行快照的存储,而不会对性能造成太大的影响。
在Flink流式应用程序失败(由于机器、网络或软件故障等原因)要进行恢复的时候,系统会将operator重新启动,并将它们重置到最近成功的Checkpoint处进行重新消费,这期间不会丢失数据,也不会重复消费数据。
注意:1. 默认情况下,checkpoint是未开启的。 2. 为了实现容错机制,数据源要支持数据重放的功能,比如Kafka。
CheckPoint是Flink Runtime自动管理和触发的,主要在应用程序或task发生异常进行恢复的场景,比较轻量级,旧的CheckPoint会在新的Checkpoint完成时自动删除。
此外,Flink还提供了一种类似Checkpoint的,但是需要用户手动触发的快照存储方式,就是Savepoint,它主要是用在应用程序更新、Flink集群更新等场景,它并不会在新的CheckPoint完成时自动删除。
Flink State Backends
我们在上面多次提到了状态/快照的存储,这状态/快照就是保存到状态后端(State Backends)中的。
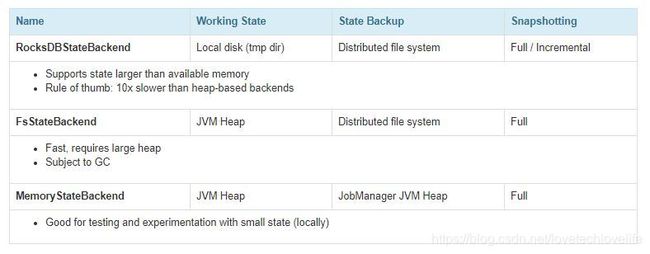
Flink目前提供了3种可用的状态后端:
- MemoryStateBackend
- FsStateBackend
- RocksDBStateBackend

1. MemoryStateBackend
1. 状态存储
MemoryStateBackend将状态数据存储在TaskManager的内存中,将每次触发Checkpoint时聚合的状态存储在JobManager的内存中。
2. 容量限制
- 默认情况下,每个状态被序列化后最大不能超过5M(DEFAULT_MAX_STATE_SIZE = 5 * 1024 * 1024),可以通过变量进行指定,但是也不能超过akka的framesize大小(默认为10M)
- 每次Checkpoint时,所有state大小总和不能超过JobManager的内存大小。
3. 适用场景
由于MemoryStateBackend将状态数据保存在内存中,所以一般建议在本地测试或状态比较小的场景中使用。
4. 配置方式
env.setStateBackend(new MemoryStateBackend(5, false));
2. FsStateBackend
1. 状态存储
- FsStateBackend将状态数据存储在TaskManager的内存中
- 将每次触发Checkpoint时聚合的状态存储在外部的文件系统中(比如HDFS、S3等)。
2. 容量限制
- 每个state不能超过TaskManager的内存大小
- 每次Checkpoint时,所有state大小总和不能超过文件系统的容量。
3. 适用场景
- 大状态,长窗口
- 大key-value状态
- 状态要求高可用
4. 配置方式
env.setStateBackend(new FsStateBackend("hdfs://namenode:40010/flink/checkpoints", false));
3. RocksDBStateBackend
1. 状态存储
- RocksDBStateBackend将state数据保存RocksDB数据库(K-V数据,先写内存,达到一定的阈值后刷到磁盘,与HBase非常类似)中
- 每次触发Checkpoint时,也是像FsStateBackend那样,将聚合的状态存储在外部的文件系统中(比如HDFS、S3等)。
RocksDBStateBackend是目前唯一提供增量CheckPoint的状态后端。
2. 容量限制
FsStateBackend中每个状态的存储主要受限于TaskManager的内存大小。而RocksDBStateBackend是将state数据保存到数据库中,只受限于磁盘容量大小,因此它可以保存非常大的状态,这也意味着更低的吞吐量。但是也会因为数据在状态后端与对象之间的序列化和反序列化,导致性能要比FsStateBackend差一些。
- 每个state不能超过TaskManager内存与磁盘容量的和,
- 单key最大不能超过2G。
3. 适用场景
- 超大状态作业
- 需要状态高可用的作业
- 对读写性能要求不高的作业
4. 配置方式
env.setStateBackend(new RocksDBStateBackend("file://...", false));
4. 总结
上面3中状态后端不仅可以在代码中配置,也可以在flink-conf.yaml文件中配置,不过配置文件会对全局的任务生效。
目前。Flink Savepoint的二进制格式是绑定与特定状态后端,使用一种状态后端获取的Savepoint不能用另一种状态后端来恢复,所以我们在生成环境中,要仔细考虑要使用哪种状态后端。
通常情况下,我们建议在生成环境中避免使用MemoryStateBackend,因为它将快照存储在JobManager中,可能会导致OOM。然后就变成了如何在FsStateBackend和RocksDB之间选择的问题了,要选哪种主要是在性能和伸缩性之间做出妥协。FsStateBackend高性能非常快,因为每个state的访问和更新是操作Java堆上的对象,但是state状态大小受限于集群可用内存容量;而RocksDBStateBackend将状态保存在RocksDB数据库中,不会受内存的限制,并且支持增量快照,但是每个state的访问和更新都要进行序列化/反序列化,并可能会从磁盘读取,这就会导致性能较差。所以,最终的选择我们还是要结合具体的业务场景。
参考
- https://ci.apache.org/projects/flink/flink-docs-release-1.12/concepts/stateful-stream-processing.html
- https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/stream/state/state.html
- https://ci.apache.org/projects/flink/flink-docs-release-1.12/ops/state/state_backends.html#the-memorystatebackend
- https://ci.apache.org/projects/flink/flink-docs-release-1.12/learn-flink/fault_tolerance.html
- https://www.alibabacloud.com/blog/apache-flink-fundamentals-state-management-and-fault-tolerance_595730