Nvidia Jetson XAvier NX开发套件从装机到pytorch环境搭建YoloV5+DeepSort+TensorRT
目录
- 1. 刷机与装机
-
- 1.1 准备VMware工作站和linux的unbuntu16.04虚拟机:
- 1.2 将SD上的系统移动至SSD
- 1.3 SSH配置
- 1.4 查看Jetpack版本
- 1.5 启动风扇
- 2. 深度学习环境配置
-
- 2.1 python环境配置
-
- 2.1.1 安装Miniforge(Conda的Arm代替版)
- 2.2 配置Miniforge——伪conda环境
- 2.3 pytorch环境配置
-
- 2.3.1 查看cuda版本
- 2.2 pytorch虚拟环境创建
- 2.2 安装pytorch(默认就是GPU版)
- 2.2.1 正常安装
-
- 2.2.2 缺少'.so'报错
- 2.2.3 Illegal instruction (core dumped)`报错
- 2.3 安装torchvision
- 3. 神经网络前向推理
-
- 3.1 根据训练的参数文件生成推理权重文件
- 3.2 编译并生成TensorRT格式的engine文件
1. 刷机与装机
1.1 准备VMware工作站和linux的unbuntu16.04虚拟机:
窗口太小:
设置里进display调一下分辨率:

把sdmanager的deb包放到Downloads目录下:
打开终端,输入:
sudo apt-get install ./XXXXXXXXXXXXX.deb
安装sdkmanager完毕后输入以下命令启动:
sdkmanager
这里我挂了梯子,所以进Nvidia官网快一点,下载也会相应快一点:
先给jetson NX 通电,连接micoUSB——USB线从Jetson到电脑上,选择虚拟机作为连接主体:
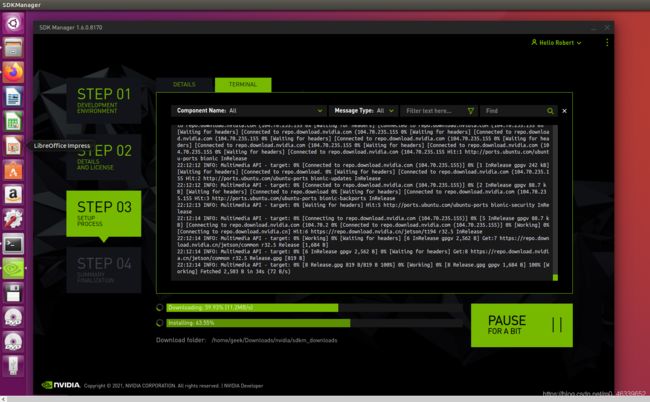
装你需要的系统(unbuntu)和包(cuda、cudnn、deepstream等):

装好的文件和包可以在相应目录下看到,我这里选取我需要的cudnn和cuda包,用U盘拷走,放Jetson系统里面

然后会发现总是有一些包安装得不尽人意,没事,大不了跳过就行了:

这里直接finish并exit
1.2 将SD上的系统移动至SSD
如果你的Jetson Xavier NX套件是默认tf卡启动的那种的话,你不仅可以使用SDKmananger 装机,你还可以使用SD卡镜像装机; 如果你和我一样是使用emmc 启动方式的话,你需要摆脱16G内嵌小SD卡的束缚,即将装好的系统移入到128G的固态中。
1.3 SSH配置
直接用Filezalla传文件会连接不上,默认FTP服务是开启的,所以出现下面这种情况是你密码输错了,或者输一下端口号:22 再登陆就可以了:

重新填写密码并输入端口号22 后:
1.4 查看Jetpack版本
cat /etc/nv_tegra_release
发现是4.5.1版本,其实你在用sdkmanager装机的时候就可以选择,此处只是再次确认一下:

1.5 启动风扇
以255的风速运行风扇一段时间:
1. sudo sh -c 'echo 255 > /sys/devices/pwm-fan/target_pwm'
设置开机风扇以255风速自启动需要编辑一下配置文件:
1. sudo vim /etc/rc.local
在打开的文件中加入这几行:
1. #!/bin/bash
2. sleep 10
3. sudo /usr/bin/jetson_clocks
4. sudo sh -c 'echo 255 > /sys/devices/pwm-fan/target_pwm'
保存并退出后,移交给该文档自启动权限:
1. sudo chmod u+x /etc/rc.local
重启看一下风扇,发现自己转起来了!!
2. 深度学习环境配置
2.1 python环境配置
首先要明确两点:
一. 虚拟环境下的Python和深度学习框架包括cuda和cudnn、tensorrt包和本地root的不在同一个目录下,所以你sudo apt-get安装的,在pytorch虚拟环境下直接是用不了的;
二. jetson的虚拟环境里面, python 和python3等价, pip 和pip3等价, 这点和树莓派明显区别(当然树莓派也使用不了虚拟环境),和正常的linux / windows很像;
三. 在jetson的root环境中,python默认还是进入Python2.7了,只有输入Python3才能进入Python3.6.13环境。
2.1.1 安装Miniforge(Conda的Arm代替版)
Miniforge下载地址
直接复制自己下载的版本,不要粘贴我的代码再改,那样会报错…虽然我也不知道为啥:

示例:
sh Miniforge-pypy3-4.10.3-5-Linux-aarch64.sh
成功:

2.2 配置Miniforge——伪conda环境
在刚刚弹出的>>>环境里面,输入以下命令,配置国科大conda环境:
# 这里使用国科大镜像源
conda config --prepend channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
conda config --prepend channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes
装完之后重启一个终端,可以看到直接进入到base环境,conda配置成功了!!

2.3 pytorch环境配置
2.3.1 查看cuda版本
无论是base环境还是pytorch虚拟环境下,平白无故直接输入nvcc -V, 都会吃一行报错:
bash: nvcc: 未找到命令
解决办法:
添加相关环境变量:
vim ~/.bashrc
在文件最下方加入:
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
export CUDA_ROOT=/usr/local/cuda
保存并退出后,
执行:
source .bashrc
以上完成后,重启终端如果还不行的话,重启jetson再输入
nvcc -V
就能看到自己的cuda release是10.2版本了!!
2.2 pytorch虚拟环境创建
在base环境下直接运行以下命令创建pytroch虚拟环境:
conda create -n pytorch python=3.6

执行以下命令进入conda环境(和Anaconda命令完全一样):
conda activate pytorch
可以看到进入了虚拟环境:

2.2 安装pytorch(默认就是GPU版)
2.2.1 正常安装
pytorch选择1.7版本的:
sudo apt-get install python3-pip libopenblas-base libopenmpi-dev
pip3 install Cython
pip3 install numpy
pip3 install torch-1.7.0-cp36-cp36m-linux_aarch64.whl
测试是否安装成功:
import torch
print(torch.__version__)
print('CUDA available: ' + str(torch.cuda.is_available()))
a = torch.cuda.FloatTensor(2).zero_()
print('Tensor a = ' + str(a))
b = torch.randn(2).cuda()
print('Tensor b = ' + str(b))
c = a + b
print('Tensor c = ' + str(c))
2.2.2 缺少’.so’报错
我在验证torch的时候报错了,这比较奇怪,因为我在jetson nano上运行上述命令就可以,但这次运行后报错:
OSError: libcurand.so.10: cannot open shared object file: No such file or director

发现是因为链接到对应的库,简单找了一下,发现没有,就sudo apt-get upgrade了一下, 然后安装cuda-Toolkit==10.2 ,然后进去 /usr/local/ 一看,发现多了一个cuda-10.2的文件夹,然而里面本来就有cuda,所以这个cuda-10.2应该和cuda是一样的,想想都不可能成功。
果不其然,这时候import torch 发现改成报 can’t find 'libcudnn.8.so’这样的错了,于是乎我全局模糊搜索了一下相关信息:
sudo find . -name '*libcudnn'
发现没有搜到任何东西,我意识到出了大问题:一定有相关的没装好,于是根据libcudnn赶紧到 /usr/local/ 下面看有没有cudnn,结果发现:没有!
于是怀疑因缺少cudnn的工具包导致的import 错误,于是这才重新使用SDKmanager下载了相关的包,覆盖了一下jetson上除系统和原有文件之外的官方工具包,然后重新试了一下:
这次结果是好的,import torch不再报错
为了印证确实是缺少cudnn相关包,我再次输入
sudo find . -name 'cudnn'
模糊搜索,却发现新的cudnn并没有找到,但这次却import 成功了,不得不说这种’.so的报错’是一个带点误导性的报错,根本的解决方案就是重装一下工具包,根据1.1部分的内容有针对性地用sdkmanager重装几个相关的加速工具包就好了。```
2.2.3 Illegal instruction (core dumped)`报错
import torch 这时候等待很长时间后会报错:
Illegal instruction (core dumped)
查阅资料发现若安装的是numpy 1.19.5则会出现以上错误,而安装pytorch时自动安装的numpy即1.19.5。
Github上讨论给出了一些不同解决方法,我选择了比较简单的一种:卸载numpy 1.19.5,重新安装numpy1.19.4即可解决:
pip3 install numpy==1.19.4
2.3 安装torchvision
因为我安装的是1.7.0的pytorch,对应 torchvision 版本是0.8.1,所以安装如下:
解压后,进入文件夹, 执行:
export BUILD_VERSION=0.8.1
sudo python3 setup.py install
要是给你报以下的错误,你就把sudo去掉再试试:
python No module named 'setuptools'
编译的时候发现报错:
fatal error: libavcodec/avcodec.h: No such file or directory
进入setup.py, 输入:
/ffmpeg
定位到该行,修改:
if has ffmpeg 改为if False即可
修改完后,再次输入python setup.py install,发现这次很快就编译成功了。
3. 神经网络前向推理
使用YoloV5+DeepSort+TensorRT 目标检测、跟踪项目进行测试:
3.1 根据训练的参数文件生成推理权重文件
将Python文件先拷到yolov5文件夹下:
cp {
tensorrtx}/yolov5/gen_wts.py {
ultralytics}/yolov5
进入yolov5文件夹,运行Python代码以载入训练好的yolov5s.pt 参数文件生成对应权重文件:
cd {
ultralytics}/yolov5 python gen_wts.py yolov5s.pt
如果报错说没有yaml模块的话,输入:
pip install pyyaml
运行成功后可以看到生成了一个wts类型的权重文件。
3.2 编译并生成TensorRT格式的engine文件
进入yolov5目录:
cd {
tensorrtx}/yolov5/
创建并进入build文件夹:
mkdir build
cd build
将权重文件复制到tensorrtx文件夹下:
cp {
ultralytics}/yolov5/best.wts {
tensorrtx}/yolov5/build
开始cmake编译:
cmake ..
make
生成engine文件
sudo ./yolov5 -s best.wts best.engine s
sudo ./yolov5 -d best.engine ../samples
然后你可能会遇到如下报错:
jetson no module named 'tensorrt'
先查看一下tensorrt版本:
dpkg -l | grep TensorRT
这时候你会发现报错说啥也没有找到。
在虚拟环境下进入Python,试一下:
import tensorrt
很可能仍然报错说没有模块。
这是因为tensorrt这个包你无论是通过sdkmanager装的还是本地sudo apt-get装的,最后都是装在了 /var/apt 目录下,你在 ‘Miniforge/env/pytorch/python3.6/ ’ 这个虚拟环境里根本链接不到tensorrt的包,因此考虑说咱们单纯跑pytorch代码的话在虚拟环境中调试,等需要实际部署了再放root环境下跑就OK。
这么处理也许有些不太优雅,但目前我能想到的就是这么做,如果有大佬知道怎么链接本地的tensorrt包,请在评论区留言,谢谢!