大数据开发基础入门与项目实战(三)Hadoop核心及生态圈技术栈之3.数据仓库工具Hive基础
文章目录
- 1.Hive概述
-
- (1)数仓工具Hive的产生背景
- (2)数仓工具Hive与RDBMS对比
- (3)数仓工具Hive的优缺点
- (4)数仓工具Hive的架构原理
- 2.Hive安装与配置
-
- (1)安装准备
- (2)安装MySQL元数据库
- (3)Hive的安装与配置
- (4)Hive安装的注意事项
- (5)参数配置
- 3.数据类型与文件格式
-
- (1)基本数据类型及转换
- (2)集合数据类型
- (3)Hive文本文件数据编码及读时模式
1.Hive概述
(1)数仓工具Hive的产生背景
前面已经详细讲解了Hadoop框架的三大核心:
-
HDFS => 海量数据的存储
-
MapReduce => 海量数据的分析和处理
-
Yarn => 集群资源的管理和作业调度
可以说,在面对海量数据时,已经有了一个相对完整的解决方案。
但是直接使用MapReduce处理大数据,存在以下问题:
-
MapReduce开发难度大,学习成本高
-
HDFS文件没有字段名、没有数据类型,不方便对数据进行有效的管理
-
使用MapReduce框架开发,项目周期长、成本高
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件 映射为一张表(类似于RDBMS中的表),并提供类SQL查询功能;Hive是由Facebook开源,用于解决海量结构化日志的数据统计。
Hive本质是将SQL转换为MapReduce的任务进行运算;
底层仍由HDFS来提供数据存储;
可以将Hive理解为一个将SQL转换为MapReduce任务的工具。
数据仓库(Data Warehouse)由数据仓库之父比尔·恩门于1991年提出,是一个面向主题的、集成的、相对稳定的、反映历史变化的 数据集合。
数据仓库的目的:
构建面向分析的、集成的数据集合;
为企业提供决策支持。
数据仓库本身不产生数据,数据来源于外部;
数仓存储了大量数据,对这些数据的分析和处理不可避免地用到Hive。
(2)数仓工具Hive与RDBMS对比
由于Hive采用了类似SQL的查询语言HQL(Hive Query Language),因此很容易将Hive理解为数据库。其实从结构上来看,Hive和传统的关系数据库除了拥有类似的查询语言,再无类似之处。
两者的对比如下:
- 查询语言相似(同)
HQL与SQL高度相似。
由于SQL被广泛的应用在数据仓库中,因此,专门针对Hive的特性设计了类SQL的查询语言HQL。熟悉SQL开发的开发者可以很方便的使用Hive进行开发。
- 数据规模(异)
Hive存储海量数据;RDBMS只能处理有限的数据集。
由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据。
而RDBMS可以支持的数据规模较小。
- 执行引擎(异)
Hive的引擎是MR/Tez/Spark/Flink;RDBMS使用自己的执行引擎。
Hive中大多数查询的执行是通过Hadoop提供的MapReduce来实现的。
而RDBMS通常有自己的执行引擎。
- 数据存储(异)
Hive保存在HDFS上;RDBMS保存在本地文件系统或裸设备。
Hive的数据都是存储在HDFS中的。
而RDBMS是将数据保存在本地文件系统或裸设备中。
- 执行速度(异)
Hive相对慢(MR/数据量);RDBMS相对快。
Hive存储的数据量大,在查询数据的时候,通常没有索引,需要扫描整个表;加之Hive使用MapReduce作为执行引擎,这些因素都会导致较高的延迟。
而RDBMS对数据的访问通常是基于索引的,执行延迟较低。当然这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出并行的优势。
- 可扩展性(异)
Hive支持水平扩展;通常RDBMS支持垂直扩展,对水平扩展不友好。
Hive建立在Hadoop之上,其可扩展性与Hadoop的可扩展性是一致的(Hadoop集群规模可以轻松超过1000个节点)。
而RDBMS由于ACID语义的严格限制,扩展行非常有限。目前最先进的并行数据库Oracle在理论上的扩展能力也只有100台左右。
- 数据更新(异)
Hive对数据更新不友好;RDBMS支持频繁、快速数据更新。
Hive是针对数据仓库应用设计的,数据仓库的内容是读多写少的。因此,Hive中不建议对数据的改写,所有的数据都是在加载的时候确定好的。
而RDBMS中的数据需要频繁、快速地进行更新。
(3)数仓工具Hive的优缺点
Hive的优点如下:
- 学习成本低
Hive提供了类似SQL的查询语言,开发人员能快速上手。
- 处理海量数据
底层执行的是MapReduce任务。
- 系统可以水平扩展
底层基于Hadoop。
- 功能可以扩展
Hive允许用户自定义函数。
- 良好的容错性
某个节点发生故障,HQL仍然可以正常完成。
- 统一的元数据管理
元数据包括有哪些表、表有什么字段、字段是什么类型等内容。
Hive的缺点如下:
-
HQL表达能力有限
-
迭代计算无法表达
-
Hive的执行效率不高(基于MR的执行引擎)
-
Hive自动生成的MapReduce作业,某些情况下不够智能
-
Hive的调优困难
(4)数仓工具Hive的架构原理
Hive的架构图如下:
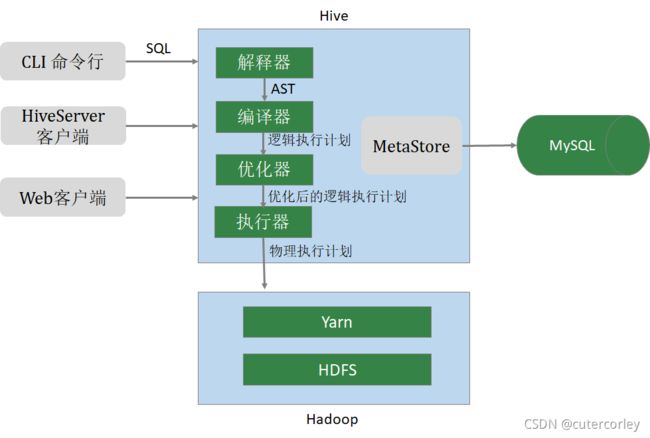
其中:
- 用户接口有3种:
- CLI(Common Line Interface):Hive的命令行,用于接收HQL,并返回结果;
- JDBC/ODBC:是指Hive的java实现,与传统数据库JDBC类似;
- WebUI:是指可通过浏览器访问Hive。
- Thrift Server
Hive可选组件,是一个软件框架服务,允许客户端使用包括Java、C++、Ruby和其他很多种语言,通过编程的方式远程访问Hive。
- 元数据管理(MetaStore)
Hive将元数据存储在关系数据库中(如MySQL、derby);
Hive的元数据包括:数据库名、表名及类型、字段名称及数据类型、数据所在位置等。
- 驱动程序(Driver)
- 解析器(SQLParser)
使用第三方工具(antlr)将HQL字符串转换成抽象语法树(AST);对AST进行语法分析,比如字段是否存在、SQL语义是否有误、表是否存在。
- 编译器(Compiler)
将抽象语法树编译生成逻辑执行计划。
- 优化器(Optimizer)
对逻辑执行计划进行优化,减少不必要的列、使用分区等。
- 执行器(Executor)
把逻辑执行计划转换成可以运行的物理计划。
2.Hive安装与配置
(1)安装准备
与Hive相关的3个网站如下:
Hive官网:http://hive.apache.org;
下载网址:http://archive.apache.org/dist/hive/;
文档网址:https://cwiki.apache.org/confluence/display/Hive/LanguageManual。
安装Hive的前提:
准备好3台虚拟机,同时安装Hadoop,前面的阶段已经完成该工作。
需要安装的软件包括Hive 2.3.7 和MySQL 5.7 (可以选择5.7.26或5.7.35)。
这里之所以需要安装MySQL,是因为:
Hive的元数据默认存储在自带的 derby 数据库中;
derby是Java语言开发的占用资源少,但是只支持单进程、单用户,仅仅适用于个人的测试;
生产中多采用MySQL。
各个节点安装软件的分布如下:
| 软件 | node01 | node02 | node03 |
|---|---|---|---|
| Hadoop | √ | √ | √ |
| MySQL | √ | ||
| Hive | √ |
需要准备的安装包包括:
- Hive安装包
可点击http://archive.apache.org/dist/hive/hive-2.3.7/apache-hive-2.3.7-bin.tar.gz下载。
- MySQL安装包
可点击https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.26-1.el7.x86_64.rpm-bundle.tar下载。
- MySQL的JDBC驱动程序
可点击https://cdn.mysql.com/archives/mysql-connector-java-5.1/mysql-connector-java-5.1.46.tar.gz下载。
这些安装包可以在本地下载再通过工具上传到虚拟机中,也可以在虚拟机上通过wget命令进行下载。
(2)安装MySQL元数据库
MySQL的安装步骤一般如下:
- 环境准备
1. 删除有冲突的依赖包
2. 安装必须的依赖包
-
安装MySQL
-
在数据库中创建hive用户
因为前2步已经在2.6 Linux服务器中执行过,因此可以省略,直接创建hive用户。
为了在开发阶段密码便于记忆和使用,在创建用户时可以设置较简单的密码,此时就需要在创建用户前修改密码验证策略和长度,如下:
mysql> set global validate_password_policy=0;
Query OK, 0 rows affected (0.00 sec)
mysql> set global validate_password_length=4;
Query OK, 0 rows affected (0.00 sec)
其中,validate_password_policy 表示密码密码策略,可配置的值如下:
- 0 or LOW
仅需需符合密码长度,由参数validate_password_length指定,默认为8。
- 1 or MEDIUM
满足LOW策略,同时还需满足至少有1个数字、小写字母、大写字母和特殊字符。
- 2 or STRONG
满足MEDIUM策略,同时密码不能存在字典文件(dictionary file)中。
说明:
个人开发环境,出于方便的目的可以设置比较简单的密码;生产环境一定要设置复杂密码 。
再创建hive用户,如下:
-- 创建用户设置密码
mysql> create user 'hive'@'%' identified by 'hive';
Query OK, 0 rows affected (0.02 sec)
-- 授权
mysql> grant all on *.* to 'hive'@'%';
Query OK, 0 rows affected (0.00 sec)
-- 刷新
mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)
再退出MySQL使用hive用户登录验证,如下:
[root@node03 ~]$ mysql -u hive -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 9
Server version: 5.7.35 MySQL Community Server (GPL)
Copyright (c) 2000, 2021, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| java_demo |
| mysql |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.00 sec)
mysql>
可以看到,成功登录并进行了查看。
(3)Hive的安装与配置
安装和配置Hive的步骤如下:
(1)下载Hive软件,并解压缩
[root@node03 ~]$ cd /opt/packages/
[root@node03 packages]$ tar -xzvf apache-hive-2.3.7-bin.tar.gz -C ../software/
apache-hive-2.3.7-bin/LICENSE
apache-hive-2.3.7-bin/RELEASE_NOTES.txt
apache-hive-2.3.7-bin/NOTICE
apache-hive-2.3.7-bin/binary-package-licenses/com.thoughtworks.paranamer-LICENSE
apache-hive-2.3.7-bin/binary-package-licenses/org.codehaus.janino-LICENSE
...
apache-hive-2.3.7-bin/hcatalog/share/webhcat/svr/lib/wadl-resourcedoc-doclet-1.4.jar
apache-hive-2.3.7-bin/hcatalog/share/webhcat/svr/lib/commons-exec-1.1.jar
apache-hive-2.3.7-bin/hcatalog/share/webhcat/svr/lib/jetty-all-server-7.6.0.v20120127.jar
apache-hive-2.3.7-bin/hcatalog/share/webhcat/svr/lib/jul-to-slf4j-1.7.10.jar
apache-hive-2.3.7-bin/hcatalog/share/webhcat/java-client/hive-webhcat-java-client-2.3.7.jar
[root@node03 packages]$ cd ../software/
[root@node03 software]$ mv apache-hive-2.3.7-bin/ hive-2.3.7/
[root@node03 software]$ ls
hadoop-2.9.2 hive-2.3.7 java tomcat
[root@node03 software]$ cd hive-2.3.7/
[root@node03 hive-2.3.7]$ pwd
/opt/software/hive-2.3.7
可以看到,最后得到了Hive的安装路径。
(2)修改环境变量
编辑/etc/profile文件vim /etc/profile,添加如下内容:
# HIVE_HOME
export HIVE_HOME=/opt/software/hive-2.3.7
export PATH=$PATH:$HIVE_HOME/bin
保存退出后,执行source /etc/profile使环境变量生效,如下:
[root@node03 hive-2.3.7]$ source /etc/profile
[root@node03 hive-2.3.7]$ hive --version
Hive 2.3.7
Git git://Alans-MacBook-Air.local/Users/gates/git/hive -r xxxxxd88304034393d68cc31a95be24f5aaxxxxx
Compiled by gates on Tue Apr 7 12:42:45 PDT 2020
From source with checksum xxxxxe8ac4737126b00a1a47f66xxxxx
可以看到,环境变量配置生效,获取到了Hive的版本信息。
(3)修改 Hive 配置
进入Hive安装目录下的conf目录:
[root@node03 hive-2.3.7]$ cd conf/
[root@node03 conf]$ ls
beeline-log4j2.properties.template ivysettings.xml
hive-default.xml.template llap-cli-log4j2.properties.template
hive-env.sh.template llap-daemon-log4j2.properties.template
hive-exec-log4j2.properties.template parquet-logging.properties
hive-log4j2.properties.template
并创建文件hive-site.xml,添加内容如下:
javax.jdo.option.ConnectionURL
jdbc:mysql://node03:3306/hivemetadata?createDatabaseIfNotExist=true&useSSL=false
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
hive
username to use against metastore database
javax.jdo.option.ConnectionPassword
hive
password to use against metastore database
退出并保存;
先通过javax.jdo.option.ConnectionURL参数指定了Hive元数据保存的数据库的位置和数据库,如果不存在则创建,同时指定连接时不加密,如果没有useSSL=false会有大量警告, &表示连接符&;
再通过javax.jdo.option.ConnectionDriverName参数指定驱动程序;
同时指定登录到MySQL的用户名和密码。
(4)准备MySQL的JDBC驱动程序
将MySQL的驱动程序移动到Hvie安装目录下的lib目录下,如下:
[root@node03 conf]$ cd ..
[root@node03 hive-2.3.7]$ pwd
/opt/software/hive-2.3.7
[root@node03 hive-2.3.7]$ mv ../../packages/mysql-connector-java-5.1.46.jar lib/
[root@node03 hive-2.3.7]$ ls lib/ | grep mysql
mysql-connector-java-5.1.46.jar
mysql-metadata-storage-0.9.2.jar
(5)初始化元数据库
执行schematool -dbType mysql -initSchema命令初始化源数据库,其中-dbType选项用于指定数据库,这里即MySQL,-initSchema用于指定执行的操作为初始化Schema。
如下:
[root@node03 hive-2.3.7]$ cd bin/
[root@node03 bin]$ ls
beeline ext hive hive-config.sh hiveserver2 hplsql metatool schematool
[root@node03 bin]$ schematool -dbType mysql -initSchema
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/software/hive-2.3.7/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/software/hadoop-2.9.2/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://node03:3306/hivemetadata?createDatabaseIfNotExist=true&useSSL=false
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: hive
Starting metastore schema initialization to 2.3.0
Initialization script hive-schema-2.3.0.mysql.sql
Initialization script completed
schemaTool completed
修改完成后,查看数据库:
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| hivemetadata |
| java_demo |
| mysql |
| performance_schema |
| sys |
+--------------------+
6 rows in set (0.01 sec)
mysql> use hivemetadata;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+---------------------------+
| Tables_in_hivemetadata |
+---------------------------+
| AUX_TABLE |
| BUCKETING_COLS |
| CDS |
| COLUMNS_V2 |
| COMPACTION_QUEUE |
| COMPLETED_COMPACTIONS |
| COMPLETED_TXN_COMPONENTS |
| DATABASE_PARAMS |
| DBS |
| DB_PRIVS |
| DELEGATION_TOKENS |
| FUNCS |
| FUNC_RU |
| GLOBAL_PRIVS |
| HIVE_LOCKS |
| IDXS |
| INDEX_PARAMS |
| KEY_CONSTRAINTS |
| MASTER_KEYS |
| NEXT_COMPACTION_QUEUE_ID |
| NEXT_LOCK_ID |
| NEXT_TXN_ID |
| NOTIFICATION_LOG |
| NOTIFICATION_SEQUENCE |
| NUCLEUS_TABLES |
| PARTITIONS |
| PARTITION_EVENTS |
| PARTITION_KEYS |
| PARTITION_KEY_VALS |
| PARTITION_PARAMS |
| PART_COL_PRIVS |
| PART_COL_STATS |
| PART_PRIVS |
| ROLES |
| ROLE_MAP |
| SDS |
| SD_PARAMS |
| SEQUENCE_TABLE |
| SERDES |
| SERDE_PARAMS |
| SKEWED_COL_NAMES |
| SKEWED_COL_VALUE_LOC_MAP |
| SKEWED_STRING_LIST |
| SKEWED_STRING_LIST_VALUES |
| SKEWED_VALUES |
| SORT_COLS |
| TABLE_PARAMS |
| TAB_COL_STATS |
| TBLS |
| TBL_COL_PRIVS |
| TBL_PRIVS |
| TXNS |
| TXN_COMPONENTS |
| TYPES |
| TYPE_FIELDS |
| VERSION |
| WRITE_SET |
+---------------------------+
57 rows in set (0.00 sec)
mysql>
可以看到,在执行初始化元数据库的命令后,创建了hivemetadata数据库,并在数据库中创建了保存元数据所需要的表。
(6)执行命令启动Hive
启动Hive服务之前,请先启动HDFS、Yarn的服务 。
如果没有启动HDFS,则需要在node01节点执行start-dfs.sh启动HDFS;
如果没有启动Yarn,则需要在node03节点执行start-yarn.sh启动Yarn。
然后等待一段时间,等待HDFS集群度过安全模式的时间(默认为30秒,不能进行操作),再启动Hive。
启动Hive直接使用命令hive即可,如下:
[root@node03 ~]$ hive
which: no hbase in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/opt/software/java/jdk1.8.0_231/bin:/opt/software/hadoop-2.9.2/bin:/opt/software/hadoop-2.9.2/sbin:/opt/software/hive-2.3.7/bin:/root/bin)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/software/hive-2.3.7/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/software/hadoop-2.9.2/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/opt/software/hive-2.3.7/lib/hive-common-2.3.7.jar!/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive> show databases;
OK
default
Time taken: 6.42 seconds, Fetched: 1 row(s)
hive> create database test1;
OK
Time taken: 0.315 seconds
hive> show databases;
OK
default
test1
Time taken: 0.039 seconds, Fetched: 2 row(s)
hive> use test1;
OK
Time taken: 0.262 seconds
hive>
可以看到,启动Hive成功,与MySQL命令行类似,同时自带默认数据库default。
(4)Hive安装的注意事项
可在 hive-site.xml 中增加一些常用配置,方便使用,例如设置数据在HDFS中的存储位置、Hive命令行中显示当前库、显示表头信息和本地模式等,在/opt/software/hive-2.3.7/conf目录下编辑hive-site.xml,如下:
hive.metastore.warehouse.dir
/user/hive/warehouse
location of default database for the warehouse
hive.cli.print.current.db
true
Whether to include the current database in the Hive prompt.
hive.cli.print.header
true
hive.exec.mode.local.auto
true
Let Hive determine whether to run in local mode automatically
其中,本地模式的含义是:当 Hive 的输入数据量非常小时,Hive通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间会明显被缩短。
当一个job满足如下条件才能真正使用本地模式:
-
job的输入数据量必须小于参数
hive.exec.mode.local.auto.inputbytes.max的值(默认是128MB) -
job的map数必须小于参数
hive.exec.mode.local.auto.tasks.max的值(默认是4) -
job的reduce数必须为0或者1
此时再重新启动Hive,如下:
hive (default)> show databases;
OK
database_name
default
test1
Time taken: 8.184 seconds, Fetched: 2 row(s)
hive (default)> use test1;
OK
Time taken: 0.094 seconds
hive (test1)>
可以看到,此时显示了正在使用的数据库。
同时从前面可以看到,在启动Hive的时候,会提示Hive和Hadoop中SLF4J(一个日志标准)的版本冲突的问题,此时可以删除Hive中的SLF4J、而保留Hadoop中的版本,此时Hive在启动时就会自动使用Hadoop中的版本,根据提示信息中的路径来删除即可,例如rm -f /opt/software/hive-2.3.7/lib/log4j-slf4j-impl-2.6.2.jar,删除后再重新执行就不会有SLF4J冲突的提示了。
Hive的日志默认存放在/tmp/root目录下(root表示当前用户名),可以查看如下:
[root@node03 ~]$ ll -ht /tmp/root/
总用量 20K
-rw-r--r-- 1 root root 4.8K 9月 21 09:13 hive.log
-rw-r--r-- 1 root root 2.9K 9月 21 09:12 hive.log.2021-09-20
-rw-r--r-- 1 root root 6.3K 9月 20 22:06 stderr
在遇到错误、需要排查时就可以查看这个路径下的hive.log文件。
这个位置是在Hive安装路径下的conf目录下的hive-log4j2.properties.template文件定义的,也可以修改,hive-log4j2.properties.template是一个模板文件,可以cp hive-log4j2.properties.template hive-log4j2.properties新建一个文件,并在hive-log4j2.properties中修改,其中property.hive.log.dir = {sys:java.io.tmpdir}/{sys:user.name},可以根据自己的需要进行修改。
在实际的开发和使用过程中,要对端口号敏感,例如前面启动Hive使如果报错和9000端口相关,说明可能是HDFS未启动或者有异常,因为之前在配置HDFS时,core-site.xml文件中设置的fs.defaultFS值就是hdfs://node01:9000(端口指定9000),如果这里不指定9000,就会使用默认的端口,Hadoop 2.x 中 NameNode RPC缺省的端口号是8020。
在实际的生产过程中,可能需要使用第三方账号,用于保证安全性,因此需要添加第三方用户。
如下:
# 添加组
[root@node03 ~]$ groupdel hadoop
# 添加用户
[root@node03 ~]$ useradd -m hadoop -g hadoop -s /bin/bash
# 设置用户密码
[root@node03 ~]$ passwd hadoop
更改用户 hadoop 的密码 。
新的 密码:
无效的密码: 密码少于 8 个字符
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新。
# 切换用户
[root@node03 ~]$ su hadoop
# 启动Hive
[hadoop@node03 root]$ hive
which: no hbase in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/opt/software/java/jdk1.8.0_231/bin:/opt/software/hadoop-2.9.2/bin:/opt/software/hadoop-2.9.2/sbin:/opt/software/hive-2.3.7/bin:/root/bin)
Logging initialized using configuration in file:/opt/software/hive-2.3.7/conf/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive (default)> show databases;
OK
database_name
default
test1
Time taken: 7.132 seconds, Fetched: 2 row(s)
hive (default)> exit;
其中,useradd命令的常用选项如下:
| 选项 | 含义 |
|---|---|
| -m | 自动建立用户的登入目录 |
| -g | 指定用户所属的起始群组 |
| -G<群组> | 指定用户所属的附加群组 |
| -s | 指定用户登入后所使用的Shell |
建议现阶段还是使用root用户即可。
(5)参数配置
Hive中查看参数配置信息的方式如下:
-- 查看全部参数
hive (default)> set;
_hive.hdfs.session.path=/tmp/hive/root/97a4196d-bd8d-4c40-b736-de3061563bf7
_hive.local.session.path=/tmp/root/97a4196d-bd8d-4c40-b736-de3061563bf7
_hive.tmp_table_space=/tmp/hive/root/97a4196d-bd8d-4c40-b736-de3061563bf7/_tmp_space.db
datanode.https.port=50475
datanucleus.cache.level2=false
...
system:user.dir=/root
system:user.home=/root
system:user.language=zh
system:user.name=root
system:user.timezone=Asia/Shanghai
-- 查看某个参数
hive (default)> set hive.exec.mode.local.auto;
hive.exec.mode.local.auto=true
hive (default)>
参数配置有3种方式,如下:
-
用户自定义配置文件(hive-site.xml)
-
启动Hive时指定参数(-hiveconf)
-
Hive命令行指定参数(set)
其中默认配置文件是hive-default.xml,用户自定义配置文件是hive-site.xml,后者优先级大于前者;
配置文件中的设置对本机启动的所有Hive进程有效;
也可以启动Hive时,在命令行添加-hiveconf param=value来设定参数,这些设定仅对本次启动有效;
还可以在 Hive 命令行中使用SET关键字设定参数,同样仅对本次启动有效。
现在使用如下:
[root@node03 ~]$ hive
which: no hbase in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/opt/software/java/jdk1.8.0_231/bin:/opt/software/hadoop-2.9.2/bin:/opt/software/hadoop-2.9.2/sbin:/opt/software/hive-2.3.7/bin:/root/bin)
Logging initialized using configuration in file:/opt/software/hive-2.3.7/conf/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive (default)> set hive.exec.mode.local.auto;
hive.exec.mode.local.auto=true
hive (default)> exit;
[root@node03 ~]$ hive -hiveconf hive.exec.mode.local.auto=false
which: no hbase in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/opt/software/java/jdk1.8.0_231/bin:/opt/software/hadoop-2.9.2/bin:/opt/software/hadoop-2.9.2/sbin:/opt/software/hive-2.3.7/bin:/root/bin)
Logging initialized using configuration in file:/opt/software/hive-2.3.7/conf/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive (default)> set hive.exec.mode.local.auto;
hive.exec.mode.local.auto=false
hive (default)> set hive.exec.mode.local.auto=true;
hive (default)> set hive.exec.mode.local.auto;
hive.exec.mode.local.auto=true
hive (default)>
可以总结,各个配置方式的优先级如下:
set > -hiveconf > hive-site.xml > hive-default.xml
可以查看Hive命令的帮助文档,如下:
[root@node03 ~]$ hive -help
which: no hbase in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/opt/software/java/jdk1.8.0_231/bin:/opt/software/hadoop-2.9.2/bin:/opt/software/hadoop-2.9.2/sbin:/opt/software/hive-2.3.7/bin:/root/bin)
usage: hive
-d,--define <key=value> Variable substitution to apply to Hive
commands. e.g. -d A=B or --define A=B
--database <databasename> Specify the database to use
-e <quoted-query-string> SQL from command line
-f <filename> SQL from files
-H,--help Print help information
--hiveconf <property=value> Use value for given property
--hivevar <key=value> Variable substitution to apply to Hive
commands. e.g. --hivevar A=B
-i <filename> Initialization SQL file
-S,--silent Silent mode in interactive shell
-v,--verbose Verbose mode (echo executed SQL to the
console)
其中,-e选项用于不进入Hive交互窗口、直接执行SQL语句,如下:
[root@node03 ~]$ hive -e "show databases;"
which: no hbase in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/opt/software/java/jdk1.8.0_231/bin:/opt/software/hadoop-2.9.2/bin:/opt/software/hadoop-2.9.2/sbin:/opt/software/hive-2.3.7/bin:/root/bin)
Logging initialized using configuration in file:/opt/software/hive-2.3.7/conf/hive-log4j2.properties Async: true
OK
database_name
default
test1
Time taken: 6.09 seconds, Fetched: 2 row(s)
-f参数用于执行脚本中SQL语句。
先创建文件vim hdfsfile1.sql,内容如下:
show databases;
执行如下:
# 执行文件中的SQL语句
[root@node03 ~]$ hive -f hdfsfile1.sql
which: no hbase in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/opt/software/java/jdk1.8.0_231/bin:/opt/software/hadoop-2.9.2/bin:/opt/software/hadoop-2.9.2/sbin:/opt/software/hive-2.3.7/bin:/root/bin)
Logging initialized using configuration in file:/opt/software/hive-2.3.7/conf/hive-log4j2.properties Async: true
OK
database_name
default
test1
Time taken: 5.97 seconds, Fetched: 2 row(s)
# 执行文件中的SQL语句,并将结果写入文件
[root@node03 ~]$ hive -f hdfsfile1.sql >> result.log
which: no hbase in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/opt/software/java/jdk1.8.0_231/bin:/opt/software/hadoop-2.9.2/bin:/opt/software/hadoop-2.9.2/sbin:/opt/software/hive-2.3.7/bin:/root/bin)
Logging initialized using configuration in file:/opt/software/hive-2.3.7/conf/hive-log4j2.properties Async: true
OK
Time taken: 7.183 seconds, Fetched: 2 row(s)
[root@node03 ~]$ cat result.log
database_name
default
test1
和MySQL类似,退出Hive命令行可以使用exit;或者quit;命令。
还可以在命令行执行Shell命令和HDFS命令如下:
# 操作节点本地
hive (default)> ! ls;
111
123abc
aaa
abc.txt
anaconda-ks.cfg
bbb
cba.txt
hdfsfile1.sql
lxDemo
result.log
# 操作HDFS
hive (default)> dfs -ls /;
Found 13 items
drwxrwxrwx - root supergroup 0 2021-09-01 17:59 /api_test
drwxrwxrwx - root supergroup 0 2021-08-26 19:22 /cl
drwxr-xr-x - root supergroup 0 2021-09-06 10:14 /collect_log
drwxr-xr-x - root supergroup 0 2021-09-02 18:37 /demo
drwxr-xr-x - root supergroup 0 2021-09-02 18:29 /output
-rw-r--r-- 1 root supergroup 281214 2021-09-02 12:43 /packet.txt
drwxr-xr-x - root supergroup 0 2021-09-02 18:14 /test
drwxrwxrwx - root supergroup 0 2021-09-20 15:33 /tmp
-rw-r--r-- 1 root supergroup 18 2021-09-02 11:12 /tmp.txt
drwxrwxrwx - root supergroup 0 2021-09-21 11:08 /user
drwxr-xr-x - root supergroup 0 2021-09-04 11:00 /wc_output
drwxrwxrwx - root supergroup 0 2021-08-25 22:33 /wcinput
drwxrwxrwx - root supergroup 0 2021-09-07 18:52 /wcoutput
hive (default)> dfs -ls /user;
Found 2 items
drwxrwxrwx - root supergroup 0 2021-09-20 18:52 /user/hive
drwxrwxrwx - root supergroup 0 2021-09-02 22:01 /user/root
hive (default)>
3.数据类型与文件格式
Hive支持关系型数据库的绝大多数基本数据类型,同时也支持4种集合数据类型。
(1)基本数据类型及转换
Hive类似和Java语言中一样,会支持多种不同长度的整型和浮点类型数据,同时也支持布尔类型、字符串类型,时间戳数据类型以及二进制数组数据类型等。具体如下:
- Integers(整型)
- TINYINT—1字节的有符号整数
- SMALLINT—2字节的有符号整数
- INT—4字节的有符号整数
- BIGINT—8字节的有符号整数
- Floating point numbers(浮点数)
- FLOAT—单精度浮点数
- DOUBLE—双精度浮点数
- Fixed point numbers(定点数)
- DECIMAL—17字节,任意精度数字。通常用户自定
义decimal(12, 6)
- String(字符串)
- STRING—可指定字符集的不定长字符串
- VARCHAR—1-65535长度的不定长字符串
- CHAR—1-255定长字符串
- Datetime(时间日期类型)
- TIMESTAMP—时间戳(纳秒精度)
- DATE—时间日期类型
- Boolean(布尔类型)
- BOOLEAN—TRUE / FALSE
- Binary types(二进制类型)
- BINARY—字节序列
这些类型名称都是 Hive 中保留字。
这些基本的数据类型都是 Java 中的接口进行实现的,因此与 java 中数据类型是基本一致的,具体如下:
| Hive数据类型 | Java数据类型 | 长度 | 样例 |
|---|---|---|---|
| TINYINT | byte | 1字节有符号整数 | 20 |
| SMALLINT | short | 2字节有符号整数 | 30 |
| INT | int | 4字节有符号整数 | 40 |
| BIGINT | long | 8字节有符号整数 | 50 |
| BOOLEAN | boolean | 布尔类型 | true、false |
| FLOAT | float | 单精度浮点数 | 3.14159 |
| DOUBLE | double | 双精度浮点型 | 2.71828 |
| STRING | String | 字符序列,可指定字符集;可以使用单引号或双引号 | ‘The Apache Hive data warehouse software facilitates’ |
| TIMESTAMP | 时间类型 | ||
| BINARY | 字符数组 |
Hive的数据类型是可以进行隐式转换 的,类似于Java的类型转换。如用户在查询中将一种浮点类型和另一种浮点类型的值做对比,Hive会将类型转换成两个浮点类型中值较大的那个类型,即:将FLOAT类型转换成DOUBLE类型;当然如果需要的话,任意整型会转化成DOUBLE类型。 Hive 中基本数据类型遵循以下层次结构:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IpLZRV5C-1636255026508)(image/image_1.png)]
按照这个层次结构,子类型到祖先类型允许隐式转换。
总的来说数据转换遵循以下规律:
任何整数类型都可以隐式转换为一个范围更广的类型,例如tinyInt => Int、int => bigint;
所有整数类型、float、string(都是数字)都可以隐式转换为Double;
tinyint、 smallint、int => float;
boolean不能转换。
使用如下:
hive (default)> select "1.0" + 2;
OK
_c0
3.0
Time taken: 1.69 seconds, Fetched: 1 row(s)
hive (default)> select "111" > 112;
OK
_c0
false
Time taken: 0.199 seconds, Fetched: 1 row(s)
hive (default)> select "111" > 110;
OK
_c0
true
Time taken: 0.089 seconds, Fetched: 1 row(s)
hive (default)> select "1" > true;
OK
_c0
false
Time taken: 0.142 seconds, Fetched: 1 row(s)
hive (default)> select "1" + true;
FAILED: SemanticException [Error 10014]: Line 1:7 Wrong arguments 'true': No matching method for class org.apache.hadoop.hive.ql.udf.generic.GenericUDFOPNumericPlus with (string, boolean)
使用cast函数进行强制类型转换 ;如果强制类型转换失败,返回NULL。
使用如下:
hive (default)> select cast('111a' as int);
OK
_c0
NULL
Time taken: 0.119 seconds, Fetched: 1 row(s)
hive (default)> select cast('111' as int);
OK
_c0
111
Time taken: 0.177 seconds, Fetched: 1 row(s)
hive (default)>
(2)集合数据类型
Hive支持集合数据类型,包括array、map、struct、union等类型,分别如下:
| 类型 | 含义 | 字面量示意 |
|---|---|---|
| ARRAY | 有序的相同数据类型的集合 | array(1,2) |
| MAP | key-value对,其中key必须是基本数据类型、value不限 | map(‘a’, 1, ‘b’,2) |
| STRUCT | 不同类型字段的集合,类似于C语言的结构体 | struct(‘1’,1,1.0); named_struct(‘col1’, ‘1’, ‘col2’, 1, ‘clo3’, 1.0) |
| UNION | 不同类型的元素存储在同一字段的不同行中 | create_union(1, ‘a’, 63) |
和基本数据类型一样,这些类型的名称同样是保留字;
ARRAY 和 MAP 与 Java 中的 Array 和 Map 类似;
STRUCT 与 C 语言中的 Struct 类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套。
使用如下:
-- array
hive (default)> select array(1, 2, 3, 4, 5) as myarr;
OK
myarr
[1,2,3,4,5]
Time taken: 6.692 seconds, Fetched: 1 row(s)
hive (default)> select myarr from (select array(1, 2, 3, 4, 5) as myarr) tmp;
OK
myarr
[1,2,3,4,5]
Time taken: 0.128 seconds, Fetched: 1 row(s)
hive (default)> select myarr[0] from (select array(1, 2, 3, 4, 5) as myarr) tmp;
OK
_c0
1
Time taken: 0.112 seconds, Fetched: 1 row(s)
hive (default)> select myarr[4] from (select array(1, 2, 3, 4, 5) as myarr) tmp;
OK
_c0
5
Time taken: 0.137 seconds, Fetched: 1 row(s)
hive (default)> select myarr[5] from (select array(1, 2, 3, 4, 5) as myarr) tmp;
OK
_c0
NULL
Time taken: 0.113 seconds, Fetched: 1 row(s)
-- map
hive (default)> select map("a", 10, "b", 20, "c", 30, "d", 40, "e", 50) mymap;
OK
mymap
{
"a":10,"b":20,"c":30,"d":40,"e":50}
Time taken: 0.12 seconds, Fetched: 1 row(s)
hive (default)> select mymap["a"] from (select map("a", 10, "b", 20, "c", 30, "d", 40, "e", 50) mymap) tmp;
OK
_c0
10
Time taken: 0.126 seconds, Fetched: 1 row(s)
hive (default)> select mymap["e"] from (select map("a", 10, "b", 20, "c", 30, "d", 40, "e", 50) mymap) tmp;
OK
_c0
50
Time taken: 0.116 seconds, Fetched: 1 row(s)
hive (default)> select mymap["f"] from (select map("a", 10, "b", 20, "c", 30, "d", 40, "e", 50) mymap) tmp;
OK
_c0
NULL
Time taken: 0.1 seconds, Fetched: 1 row(s)
-- struct
hive (default)> select struct("Corley", 18, 190) as userinfo;
OK
userinfo
{
"col1":"Corley","col2":18,"col3":190}
Time taken: 0.082 seconds, Fetched: 1 row(s)
hive (default)> select named_struct("name", "Jack", "age", 30, "height", 170) as userinfo2;
OK
userinfo2
{
"name":"Jack","age":30,"height":170}
Time taken: 0.125 seconds, Fetched: 1 row(s)
hive (default)> select userinfo2.name, userinfo2.age, userinfo2.height from (select named_struct("name", "Jack", "age", 30, "height", 170) as userinfo2) t1;
OK
name age height
Jack 30 170
Time taken: 0.111 seconds, Fetched: 1 row(s)
-- union
hive (default)> select create_union(0, "Corley", 18, 20900) as myunion;
OK
myunion
{
0:"Corley"}
Time taken: 0.509 seconds, Fetched: 1 row(s)
hive (default)> select myunion from (select create_union(0, "Corley", 18, 20900) as myunion) tmp;
OK
myunion
{
0:"Corley"}
Time taken: 0.095 seconds, Fetched: 1 row(s)
hive (default)>
其中,array和map通过中括号[]访问元素,struct通过列名.字段名访问具体信息;
如果要访问的元素不存在时,返回NULL,而不会报错。
(3)Hive文本文件数据编码及读时模式
Hive表中的数据在存储在文件系统上,Hive定义了默认的存储格式,也支持用户自定义文件存储格式。
Hive默认使用几个很少出现在字段值中的控制字符,来表示替换默认分隔符的字符。Hive默认分隔符及其含义如下:
| 分隔符 | 名称 | 含义 |
|---|---|---|
| \n | 换行符 | 用于分隔行:每一行是一条记录,使用换行符分割数据 |
| ^A | +A | 用于分隔字段:在CREATE TABLE语句中使用八进制编码\001表示 |
| ^B | +B | 用于分隔 ARRAY、MAP、STRUCT 中的元素:在CREATE TABLE语句中使用八进制编码\002表示 |
| ^C | +C | Map中 key、value之间的分隔符:在CREATE TABLE语句中使用八进制编码\003表示 |
先举例如下:
有一个表的字段如下:
id name age hobby(array) score(map)
先创建表:
create table s1(
id int,
name string,
age int,
hobby array<string>,
score map<string, int>
);
再在本地的/home/hadoop/data目录(不存在则先创建)下创建数据文件vi s1.dat,输入s1表的数据,内容如下:
666^ACorley^A18^Aread^Bmusic^Ajava^C97^Bhadoop^C87
777^AJack^A30^Aread^Bgame^Amath^C73^^Bpython^C67
在 vi 中输入特殊字符即分隔符时,不能直接输入^,而是需要使用快捷键,3个分隔符的快捷键如下:
(Ctrl + v) + (Ctrl + a) => ^A
(Ctrl + v) + (Ctrl + b) => ^B
(Ctrl + v) + (Ctrl + c) => ^C
需要注意,在输入分隔符的时候需要确保快捷键Ctrl+v没有被占用。
同时,^A、^B和^C 都是特殊的控制字符,直接使用more、cat命令是看不见的,可以使用cat -A s1.dat进行查看,如下:
[root@node03 data]$ cat -A s1.dat
666^ACorley^A18^Aread^Bmusic^Ajava^C97^Bhadoop^C87$
777^AJack^A30^Aread^Bgame^Amath^C73^^Bpython^C67$
再加载本地数据和查询,如下所示:
hive (default)> load data local inpath '/home/hadoop/data/s1.dat' into table s1;
Loading data to table default.s1
OK
Time taken: 0.681 seconds
hive (default)> select * from s1;
OK
s1.id s1.name s1.age s1.hobby s1.score
666 Corley 18 ["read","music"] {
"java":97,"hadoop":87}
777 Jack 30 ["read","game"] {
"math":null,"python":67}
Time taken: 1.924 seconds, Fetched: 2 row(s)
hive (default)>
可以看到,导入和查询出了数据。
默认的分隔符因为使用极少,在数据中一般不会出现,所以不会干扰数据的分割;
当然,一般情况下不会采用默认的分隔符,因为可读性太差,同时输入也比较麻烦;
Hive 中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三个属性,即列分隔符(通常为空格、"\t"、"\x001")、行分隔符("\n")以及读取文件数据的方法;
在加载数据的过程中,Hive 不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的 HDFS 目录中;
将 Hive 数据导出到本地时,系统默认的分隔符是A、B、^C这些特殊字符,使用cat或者vim是看不到的。
写时模式:
在传统数据库(RDBMS)中,在加载时发现数据不符合表的定义,则拒绝加载数据。数据在写入数据库 时对照表模式进行检查,这种模式称为写时模式 (schema on write)。
读时模式:
Hive 中数据加载过程采用读时模式 (schema on read),加载数据时不进行数据格式的校验,读取数据 时如果不合法则显示NULL;
这种模式的优点是加载数据迅速,问题是格式不一致时很多数据都读为NULL。