七 Flink window API
文章目录
- 1 winsow的概念
- 2 window的类型
-
- 2.1 时间窗口(Time Window)
-
- 2.1.1 **滚动时间窗口**
- 2.1.2 求最近10秒的最小温度
- 2.1.3 **滑动时间窗口**
- 2.1.4 **会话窗口**
- 2.2 计数窗口(Count Window)
- 3 窗口分配器
-
- 3.1 创建不同类型的窗口
-
- 3.1.1 滚动时间窗口(tumbling time window)
- 3..1.2 滑动时间窗口(sliding time window)
- 3..1.3 会话窗口(session window)
- 3..1.4 滚动计数窗口(tumbling count window)
- 3.1.5 滑动计数窗口(sliding count window)
- 4 window function (增量聚合和全量聚合)
-
- 4.1 增量聚合函数(incremental aggregation functions)
-
- 4.1.1 增量聚合函数计算平均温度
- 4.1.2 增量reduce求最大温度和最小温度值
- 4.2 全窗口函数(full window functions)
-
- 4.2.1 全量聚合函数计算平均温度
- 4.2.1 全量全最大温度和最小温度值
- 5 其它可选 API
-
- 5.1 函数调用表:
1 winsow的概念
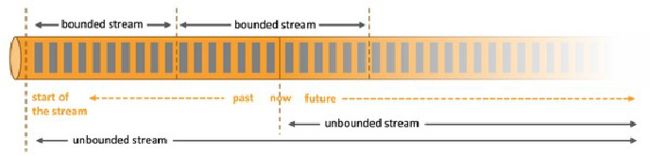
flink是流失处理框架,在真实应用中流一般是没有边界的.那要处理无界的流我们一般怎么处理呢?一般是把无界流切分成一份份有界的流,窗口就是切分无界流的一种方式.它会将流数据分发到有限大小的桶(bucket)中进行分析.
2 window的类型
2.1 时间窗口(Time Window)
2.1.1 滚动时间窗口
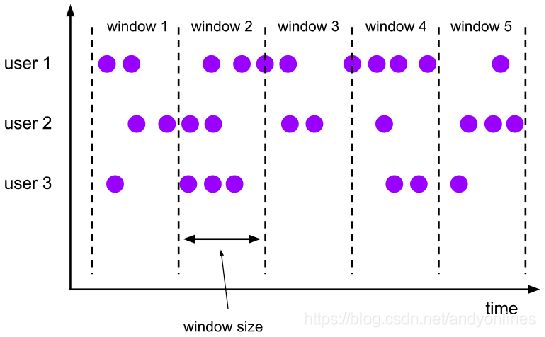
(1) 将数据依照固定的窗口大小进行切分,每个窗口首尾相连.
(2) 时间对齐,窗口长度固定,没有重叠
2.1.2 求最近10秒的最小温度
package test3
import test2.{
SensorReading, SensorSource}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object MinMaxTempPerWindow {
case class MinMaxTemp(id: String,
min: Double,
max: Double,
endTs: Long)
/**
* 求5秒钟内的最大值和最小值
* @param args
*/
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env
.addSource(new SensorSource)
stream
.keyBy(_.id)
.timeWindow(Time.seconds(5))
.process(new HighAndLowTempPerWindow)
.print()
env.execute()
}
class HighAndLowTempPerWindow extends ProcessWindowFunction[SensorReading, MinMaxTemp, String, TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[SensorReading], out: Collector[MinMaxTemp]): Unit = {
val temps = elements.map(_.temperature)
val windowEnd = context.window.getEnd
out.collect(MinMaxTemp(key, temps.min, temps.max, windowEnd))
}
}
}
2.1.3 滑动时间窗口
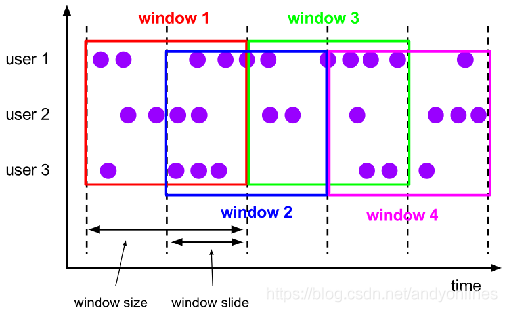
(1) 滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成
(2) 窗口长度固定,可以有重叠
package org.example.windowfunc
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.example.source.self.SensorSource
/**
* 没5秒钟求最近10秒钟的温度最小值
*/
object MinTempPerWindow {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.addSource(new SensorSource)
stream.map(r => (r.id, r.temperature))
.keyBy(_._1)
.timeWindow(Time.seconds(10), Time.seconds(5))
.reduce((r1, r2) => (r1._1, r1._2.min(r2._2)))
.print()
env.execute()
}
}
2.1.4 会话窗口
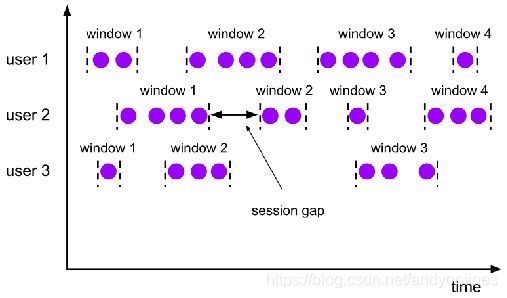
(1) 由一系列事件组合一个指定时间长度的 timeout 间隙组成,也就是一段时间没有接收到新数据就会生成新的窗口
(2) 特点:时间无对齐
package org.example.windowfunc
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.example.source.self.SensorSource
/**
*这是会话窗口的例子
* 如果20秒钟没有数据来,那么窗口关闭
*/
object SessionWindow {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.addSource(new SensorSource)
.keyBy(0)
.window(EventTimeSessionWindows.withGap(Time.seconds(20)))
.sum(2)
.print()
env.execute()
}
}
2.2 计数窗口(Count Window)
- 滚动计数窗口
和时间滚动窗口差不多,但时间滚动窗口是按照时间来设置窗口的大小和滚动步长的.计数窗口是按照数据的数量来设置窗口大小.
比如开一个50条数据的窗口,等数据来了50条之后,窗口就会关闭.
package org.example.windowfunc
import org.apache.flink.streaming.api.scala._
import org.example.source.self.SensorSource
/**
* 每10条数据计算温度和
*/
object GuanCountWindow {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.addSource(new SensorSource)
.keyBy(0)
.countWindow(10)
.sum(2)
.print()
env.execute()
}
}
- 滑动计数窗口
和时间滑动窗口差不多.
package org.example.windowfunc
import org.apache.flink.streaming.api.scala._
import org.example.source.self.SensorSource
/**
* 每10条数据计算温度和
*/
object GuanCountWindow {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.addSource(new SensorSource)
.keyBy(0)
.countWindow(10)
.sum(2)
.print()
env.execute()
}
}
3 窗口分配器
注意 window () 方法必须在 keyBy 之后才能用。
窗口分配器 —— window() 方法
我们可以用 .window() 来定义一个窗口,然后基于这个 window 去做一些聚合或者其它处理操作。注意 window () 方法必须在 keyBy 之后才能用。
Flink 提供了更加简单的 .timeWindow 和 .countWindow 方法,用于定义时间窗口和计数窗口。
window() 方法接收的输入参数是一个 WindowAssigner
WindowAssigner 负责将每条输入的数据分发到正确的 window 中
Flink 提供了通用的 WindowAssigner
- 滚动窗口(tumbling window)
- 滑动窗口(sliding window)
- 会话窗口(session window)
- 全局窗口(global window)
3.1 创建不同类型的窗口
3.1.1 滚动时间窗口(tumbling time window)
.timeWindow(Time.seconds(15)
3…1.2 滑动时间窗口(sliding time window)
.timeWindow(Time.seconds(15),Time.seconds(5))
3…1.3 会话窗口(session window)
.window(EventTimeSessionWindows.withGap(Time.seconds(20)))
3…1.4 滚动计数窗口(tumbling count window)
countWindow(5)
3.1.5 滑动计数窗口(sliding count window)
countWindow(10,2)
4 window function (增量聚合和全量聚合)
window function 定义了要对窗口中收集的数据做的计算操作
4.1 增量聚合函数(incremental aggregation functions)
每条数据到来就进行计算,保持一个简单的状态
ReduceFunction, AggregateFunction
4.1.1 增量聚合函数计算平均温度
package org.example.windowfunc
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.example.source.self.SensorSource
/**
* 增量聚合函数计算平均温度
*/
object AvgTempPerWindow {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env
.addSource(new SensorSource)
stream
.map(r => (r.id, r.temperature))
.keyBy(_._1)
.timeWindow(Time.seconds(5))
.aggregate(new AvgTempFunction)
.print()
env.execute()
}
// 平均温度值 = 总的温度值 / 温度的条数
class AvgTempFunction extends AggregateFunction[(String, Double), (String, Double, Long), (String, Double)] {
// 创建累加器
override def createAccumulator(): (String, Double, Long) = ("", 0.0, 0L)
// 每来一条数据,如何累加?
override def add(value: (String, Double), accumulator: (String, Double, Long)): (String, Double, Long) = {
(value._1, accumulator._2 + value._2, accumulator._3 + 1)
}
override def getResult(accumulator: (String, Double, Long)): (String, Double) = {
(accumulator._1, accumulator._2 / accumulator._3)
}
override def merge(a: (String, Double, Long), b: (String, Double, Long)): (String, Double, Long) = {
(a._1, a._2 + b._2, a._3 + b._3)
}
}
}
4.1.2 增量reduce求最大温度和最小温度值
package org.example.windowfunc
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
import org.example.source.self.SensorSource
object MinMaxTempByReduceAndProcess {
case class MinMaxTemp(id: String,
min: Double,
max: Double,
endTs: Long)
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.addSource(new SensorSource)
stream
.map(r => (r.id, r.temperature, r.temperature))
.keyBy(_._1)
.timeWindow(Time.seconds(5))
.reduce(
(r1: (String, Double, Double), r2: (String, Double, Double)) => {
(r1._1, r1._2.min(r2._2), r1._3.max(r2._3))
},
new WindowResult
)
.print()
env.execute()
}
class WindowResult extends ProcessWindowFunction[(String, Double, Double),
MinMaxTemp, String, TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[(String, Double, Double)], out: Collector[MinMaxTemp]): Unit = {
val temp = elements.head
out.collect(MinMaxTemp(temp._1, temp._2, temp._3, context.window.getEnd))
}
}
}
4.2 全窗口函数(full window functions)
先把窗口所有数据收集起来,等到计算的时候会遍历所有数据
ProcessWindowFunction
4.2.1 全量聚合函数计算平均温度
package org.example.windowfunc
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
import org.example.source.self.SensorSource
/**
* 全量聚合函数计算平均温度
*/
object AvgTempPerWindowByProcessWindowFunction {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env
.addSource(new SensorSource)
stream
.map(r => (r.id, r.temperature))
.keyBy(_._1)
.timeWindow(Time.seconds(5))
.process(new AvgTempFunc)
.print()
env.execute()
}
class AvgTempFunc extends ProcessWindowFunction[(String, Double), (String, Double), String, TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[(String, Double)], out: Collector[(String, Double)]): Unit = {
val size = elements.size
var sum: Double = 0.0
for (r <- elements) {
sum += r._2
}
out.collect((key, sum / size))
}
}
}
4.2.1 全量全最大温度和最小温度值
package org.example.windowfunc
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
import org.example.source.self.{
SensorReading, SensorSource}
object MinMaxTempByAggregateAndProcess {
case class MinMaxTemp(id: String,
min: Double,
max: Double,
endTs: Long)
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.addSource(new SensorSource)
stream
.keyBy(_.id)
.timeWindow(Time.seconds(5))
// 第一个参数:增量聚合,第二个参数:全窗口聚合
.aggregate(new Agg, new WindowResult)
.print()
env.execute()
}
class WindowResult extends ProcessWindowFunction[(String, Double, Double),
MinMaxTemp, String, TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[(String, Double, Double)], out: Collector[MinMaxTemp]): Unit = {
// 迭代器中只有一个值,就是增量聚合函数发送过来的聚合结果
val minMax = elements.head
out.collect(MinMaxTemp(key, minMax._2, minMax._3, context.window.getEnd))
}
}
class Agg extends AggregateFunction[SensorReading, (String, Double, Double), (String, Double, Double)] {
//累加器
override def createAccumulator(): (String, Double, Double) = {
("", Double.MaxValue, Double.MinValue)
}
//每来一条数据调用一次
override def add(value: SensorReading, accumulator: (String, Double, Double)): (String, Double, Double) = {
(value.id, value.temperature.min(accumulator._2), value.temperature.max(accumulator._3))
}
//关窗的时候返回结果
override def getResult(accumulator: (String, Double, Double)): (String, Double, Double) = accumulator
//分区间的聚合
override def merge(a: (String, Double, Double), b: (String, Double, Double)): (String, Double, Double) = {
(a._1, a._2.min(b._2), a._3.max(b._3))
}
}
}
5 其它可选 API
- .trigger() —— 触发器
定义 window 什么时候关闭,触发计算并输出结果
- .evitor() —— 移除器
定义移除某些数据的逻辑
- .allowedLateness() —— 允许处理迟到的数据
- .sideOutputLateData() —— 将迟到的数据放入侧输出流
- .getSideOutput() —— 获取侧输出流
5.1 函数调用表:
