Hadoop生产调优手册
HDFS
—核心参数
1.1 NameNode
内存生产配置
1
)
NameNode
内存计算
每个文件块大概占用
150byte
,一台服务器
128G
内存为例,能存储多少文件块呢?
128 * 1024 * 1024 * 1024 / 150Byte
≈
9.1
亿
G MB
KB Byte
2
)
Hadoop2.x
系列,配置
NameNode
内存
NameNode
内存默认
2000m
,如果服务器内存
4G
,
NameNode
内存可以配置
3g
。在
hadoop-env.sh
文件中配置如下。
HADOOP_NAMENODE_OPTS=-Xmx3072m
3
)
Hadoop3.x
系列,配置
NameNode
内存
(
1
)
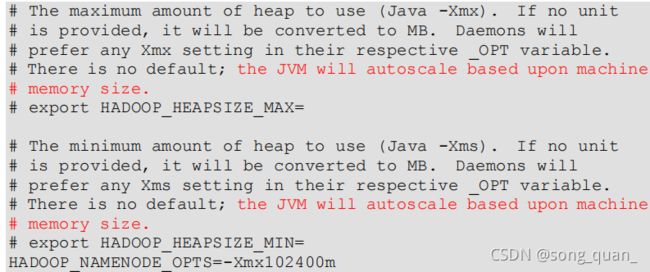
hadoop-env.sh
中描述
Hadoop
的内存是动态分配的
(2)查看
NameNode
占用内存


(3)查看
DataNode
占用内存

查看发现
hadoop102
上的
NameNode
和
DataNode
占用内存都是自动分配的,且相等。
不是很合理。
经验参考:

具体修改:
hadoop-env.sh
export HDFS_NAMENODE_OPTS="-Dhadoop.security.logger=INFO,RFAS
-
Xmx1024m"
export HDFS_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS
-Xmx1024m"
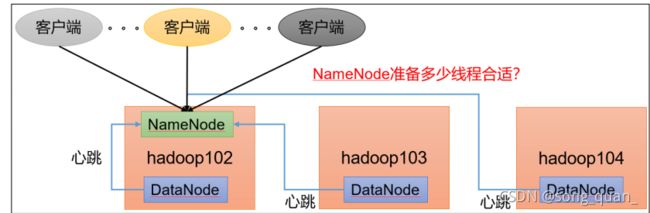
1.2 NameNode
心跳并发配置
1
)
hdfs-site.xml

数)为
3
台时,此参数设置为
21
。
计算并发连接数
开启回收站配置
开启回收站功能,可以将删除的文件在不超时的情况下,恢复原数据,起到防止误删除、
备份等作用。
1
)回收站工作机制

2)开启回收站功能参数说明
(
1
)默认值
fs.trash.interval = 0
,
0
表示禁用回收站;其他值表示设置文件的存活时间。
(2)默认值
fs.trash.checkpoint.interval = 0
,检查回收站的间隔时间。如果该值为
0
,则该
值设置和
fs.trash.interval
的参数值相等。(有时间差,检查的时间文件还存在)
(3)要求
fs.trash.checkpoint.interval <= fs.trash.interval
。
3
)启用回收站
修改
core-site.xml
,配置垃圾回收时间为
1
分钟。
4
)查看回收站
回收站目录在
HDFS
集群中的路径:
/user/atguigu/.Trash/….
5
)注意:通过网页上直接删除的文件也不会走回收站。
6
)通过程序删除的文件不会经过回收站,需要调用
moveToTrash()
才进入回收站
Trash trash = New Trash(conf);
trash.moveToTrash(path);
7
)只有在命令行利用
hadoop fs -rm
命令删除的文件才会走回收站。
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs
-rm
-r
/user/atguigu/input
2021-07-14 16:13:42,643 INFO fs.TrashPolicyDefault: Moved:
'hdfs://hadoop102:9820/user/atguigu/input' to trash at:
hdfs://hadoop102:9820/user/atguigu/.Trash/Current/user/atguigu
/input
8
)恢复回收站数据
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv
/user/atguigu/.Trash/Current/user/atguigu/input
/user/atguigu/input
HDFS
—集群压测
在企业中非常关心每天从
Java
后台拉取过来的数据,需要多久能上传到集群?消费者
关心多久能从
HDFS
上拉取需要的数据?
为了搞清楚
HDFS
的读写性能,生产环境上非常需要对集群进行压测。

HDFS
的读写性能主要受
网络和磁盘
影响比较大。为了方便测试,将
hadoop102
、
hadoop103
、
hadoop104
虚拟机网络都设置为
100mbps
。
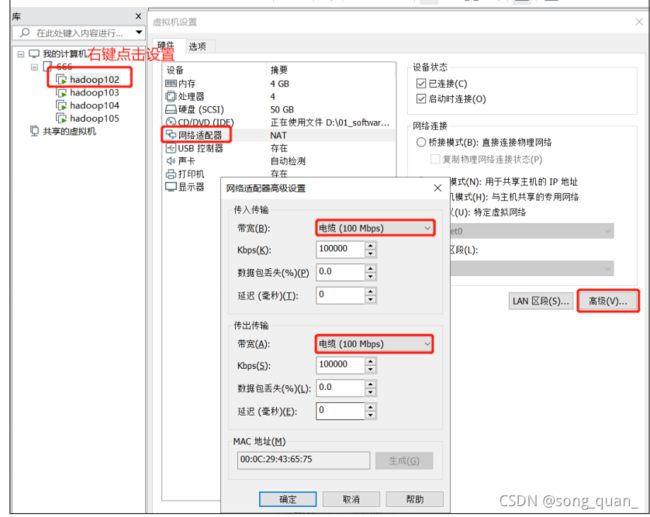
100Mbps 单位是 bit;10M/s 单位是 byte ; 1byte=8bit,100Mbps/8=12.5M/s。
测试网速:来到
hadoop102
的
/opt/module
目录,创建一个
[atguigu@hadoop102 software]$ python -m SimpleHTTPServer
测试
HDFS
写性能
0)写测试底层原理

两个汇总方式,一个是每个节点写速度相加(分量/分时间),另外一种(总量/总时间)
1)测试内容:向 HDFS 集群写 10 个 128M 的文件

注意:
nrFiles n
为生成
mapTask
的数量,生产环境一般可通过
hadoop103:8088
查看
CPU
核数,设置为(
CPU
核数
- 1
)
参数解释
➢
Number of files
:生成
mapTask
数量,一般是集群中(
CPU
核数
-1
),我们测试虚
拟机就按照实际的物理内存
-1
分配即可
➢
Total MBytes processed
:单个
map
处理的文件大小
➢
Throughput mb/sec:
单个
mapTak
的吞吐量
计算方式:处理的总文件大小
/
每一个
mapTask
写数据的时间累加
集群整体吞吐量:生成
mapTask
数量
*
单个
mapTak
的吞吐量
➢
Average IO rate mb/sec::
平均
mapTak
的吞吐量
计算方式:每个
mapTask
处理文件大小
/
每一个
mapTask
写数据的时间
全部相加除以
task
数量
➢
IO rate std deviation:
方差、反映各个
mapTask
处理的差值,越小越均衡
(上图测试写结果为1.6mb/s单个maptask)
(
1
)可以在
yarn-site.xml
中设置虚拟内存检测为
false
(
2
)分发配置并重启
Yarn
集群
(yarn的资源检测中会计算虚拟内存,实际的使用,会超过所分配的资源,被yarn停掉)
3
)测试结果分析
(
1
)由于副本
1
就在本地,所以该副本不参与测试

一共参与测试的文件:
10
个文件
* 2
个副本
= 20
个()
压测后的速度:
1.61
实测速度:
1.61M/s * 20
个文件
≈ 32M/s
三台服务器的带宽:
12.5 + 12.5 + 12.5 ≈ 30m/s(100mb带宽/8bety=12.5mb/b,一台机器的上传速度)
所有网络资源都已经用满。
如果实测速度远远小于网络,并且实测速度不能满足工作需求,可以考虑采用固态硬盘
或者增加磁盘个数。
(2)如果客户端不在集群节点,那就三个副本都参与计算
测试
HDFS
读性能
1
)测试内容:读取
HDFS
集群
10
个
128M
的文件
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-
3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client
jobclient-3.1.3-tests.jar TestDFSIO
-read -nrFiles 10 -fileSize
128MB
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: ----- TestDFSIO ----- : read
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: Date & time: Tue Feb
09 11:34:15 CST 2021
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: Number of files: 10
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: Total MBytes processed: 1280
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: Throughput mb/sec:
200.28
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: Average IO rate mb/sec:
266.74
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: IO rate std deviation: 143.12
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: Test exec time sec: 20.83
2
)删除测试生成数据
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-
3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client
jobclient-3.1.3-tests.jar TestDFSIO -clean
3
)测试结果分析:为什么读取文件速度大于网络带宽?由于目前只有三台服务器,且有三
个副本,数据读取就近原则,相当于都是读取的本地磁盘数据,没有走网络。
HDFS
—多目录(企业使用方案为HA,联邦)
NameNode
多目录配置
1
)
NameNode
的本地目录可以配置成多个,
且每个目录存放内容相同
,增加了可靠性

2
)具体配置如下
(
1
)在
hdfs-site.xml
文件中添加如下内容

注意:因为每台服务器节点的磁盘情况不同,所以这个配置配完之后,可以选择不分发
(2)停止集群,删除三台节点的
data
和
logs
中所有数据。

(3)格式化集群并启动。
3)查看结果

检查 name1 和 name2 里面的内容,发现一模一样。
DataNode
多目录配置
1
)
DataNode
可以配置成多个目录,
每个目录存储的数据不一样
(数据不是副本)

2
)具体配置如下
在
hdfs-site.xml
文件中添加如下内容

3)查看结果

4)向集群上传一个文件,再次观察两个文件夹里面的内容发现不一致(一个有数一个没有)

集群数据均衡之磁盘间数据均衡
生产环境,由于硬盘空间不足,往往需要增加一块硬盘。刚加载的硬盘没有数据时,可
以执行磁盘数据均衡命令。(
Hadoop3.x
新特性)

(
1
)生成均衡计划
(
我们只有一块磁盘,不会生成计划
)
hdfs diskbalancer -plan hadoop103
(2)执行均衡计划
hdfs diskbalancer -execute hadoop103.plan.json
(3)查看当前均衡任务的执行情况
hdfs diskbalancer -query hadoop103
(4)取消均衡任务
hdfs diskbalancer -cancel hadoop103.plan.json
HDFS
—集群扩容及缩容
添加白名单
白名单:表示在白名单的主机
IP
地址可以,用来存储数据。
企业中:配置白名单,可以尽量防止黑客恶意访问攻击。

配置白名单步骤如下:
1
)在
NameNode
节点的
/opt/module/hadoop-3.1.3/etc/hadoop
目录下分别创建
whitelist
和
blacklist
文件
(
1
)创建白名单
[atguigu@hadoop102 hadoop]$ vim whitelist
在
whitelist
中添加如下主机名称,假如集群正常工作的节点为
102 103
hadoop102
hadoop103
(2)创建黑名单
[atguigu@hadoop102 hadoop]$ touch blacklist
保持空的就可以
2
)在
hdfs-site.xml
配置文件中增加
dfs.hosts
配置参数

3
)分发配置文件
whitelist
,
hdfs-site.xml
[atguigu@hadoop104 hadoop]$ xsync hdfs-site.xml whitelist
4
)第一次添加白名单必须重启集群,不是第一次,只需要刷新
NameNode
节点即可
[atguigu@hadoop102 hadoop-3.1.3]$
myhadoop.sh stop
[atguigu@hadoop102 hadoop-3.1.3]$
myhadoop.sh start
5
)在
web
浏览器上查看
DN
,
http://hadoop102:9870/dfshealth.html#tab-datanode

6)在 hadoop104 上执行上传数据数据失败
[atguigu@hadoop104 hadoop-3.1.3]$ hadoop fs -put NOTICE.txt /
7
)二次修改白名单,增加
hadoop104
[atguigu@hadoop102 hadoop]$ vim whitelist
修改为如下内容
hadoop102
hadoop103
hadoop104
8
)刷新
NameNode
[atguigu@hadoop102 hadoop-3.1.3]$
hdfs dfsadmin -refreshNodes
Refresh nodes successful
9
)在
web
浏览器上查看
DN
,
http://hadoop102:9870/dfshealth.html#tab-datanode

服役新服务器
1
)需求
随着公司业务的增长,数据量越来越大,原有的数据节点的容量已经不能满足存储数据
的需求,需要在原有集群基础上动态添加新的数据节点。
2
)环境准备
(
1
)在
hadoop100
主机上再克隆一台
hadoop105
主机
(2)修改
IP
地址和主机名称

(3)
拷贝
hadoop102
的
/opt/module
目录和
/etc/profile.d/my_env.sh
到
hadoop105
(4)删除 hadoop105 上 Hadoop 的历史数据,data 和 log 数据
[atguigu@hadoop105 hadoop-3.1.3]$ rm -rf data/ logs/
(5)配置
hadoop102
和
hadoop103
到
hadoop105
的
ssh
无密登录
[atguigu@
hadoop102
.ssh]$ ssh-copy-id hadoop105
[atguigu@
hadoop103
.ssh]$ ssh-copy-id hadoop105
3
)服役新节点具体步骤
(
1
)直接启动
DataNode
,即可关联到集群


4)在白名单中增加新服役的服务器
(
1
)在白名单
whitelist
中增加
hadoop104
、
hadoop105
,并重启集群
[atguigu@hadoop102 hadoop]$ vim whitelist
修改为如下内容
hadoop102
hadoop103
hadoop104
hadoop105
(2)分发
[atguigu@hadoop102 hadoop]$ xsync whitelist
(3)刷新
NameNode
[atguigu@hadoop102 hadoop-3.1.3]$
hdfs dfsadmin -refreshNodes
Refresh nodes successful
5
)在
hadoop105
上上传文件
[atguigu@hadoop105 hadoop-3.1.3]$ hadoop
fs
-put
/opt/module/hadoop-3.1.3/LICENSE.txt /

服务器间数据均衡
1
)企业经验:
在企业开发中,如果经常在
hadoop102
和
hadoop104
上提交任务,且副本数为
2
,由于
数据本地性原则,就会导致
hadoop102
和
hadoop104
数据过多,
hadoop103
存储的数据量小。
另一种情况,就是新服役的服务器数据量比较少,需要执行集群均衡命令

2)开启数据均衡命令:
[atguigu@hadoop105 hadoop-3.1.3]$ sbin/start-balancer.sh -
threshold 10
对于参数
10
,代表的是集群中各个节点的磁盘空间利用率相差不超过
10%
,可根据实
际情况进行调整。
3
)停止数据均衡命令:
[atguigu@hadoop105 hadoop-3.1.3]$ sbin/stop-balancer.sh
注意:由于
HDFS
需要启动单独的
Rebalance Server
来执行
Rebalance
操作,所以尽量
不要在
NameNode
上执行
start-balancer.sh
,而是找一台比较空闲的机器。
4.4
黑名单退役服务器
黑名单:表示在黑名单的主机
IP
地址不可以,用来存储数据。
企业中:配置黑名单,用来退役服务器。

黑名单配置步骤如下:
1
)编辑
/opt/module/hadoop-3.1.3/etc/hadoop
目录下的
blacklist
文件
[atguigu@hadoop102 hadoop] vim blacklist
添加如下主机名称(要退役的节点)
hadoop105
注意:如果白名单中没有配置,需要在
hdfs-site.xml
配置文件中增加
dfs.hosts
配置参数

2
)分发配置文件
blacklist
,
hdfs-site.xml
[atguigu@hadoop104 hadoop]$ xsync hdfs-site.xml blacklist
3
)第一次添加黑名单必须重启集群,不是第一次,只需要刷新
NameNode
节点即可
[atguigu@hadoop102 hadoop-3.1.3]$
hdfs dfsadmin -refreshNodes
Refresh nodes successful
4
)检查
Web
浏览器,退役节点的状态为
decommission in progress
(退役中),说明数据
节点正在复制块到其他节点

5
)等待退役节点状态为
decommissioned
(所有块已经复制完成),停止该节点及节点资源
管理器。注意:如果副本数是
3
,服役的节点小于等于
3
,是不能退役成功的,需要修改
副本数后才能退役

6)如果数据不均衡,可以用命令实现集群的再平衡
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-balancer.sh -
threshold 10