java redis设置过期时间_Redis基础知识总结(面试必备)

1. Redis对集群的支持情况
- redis 3.0之前版本不支持集群,若要实现集群,则需要借助中间件来实现存值和取值的对应节点。
redis3.0之后的版本(含3.0),搭建集群,集群中机器两两连接,每台机器都可以做中转,事先给每台机器分配槽点(总共16384个),对于存值和取值,根据key来映射对应槽点和机器节点,若key不属于当前节点则跳转到对应其他节点,相当于每台机器节点都是一个全局路由。
2. Redis集群投票机制
Redis集群通过Gossip通信,当某个节点发现另外一个节点失联的时候,对外广播PFail信息,当某个节点收到集群绝大多数节点都判定那个节点为PFail的时候,强制将那个节点设置为Fail、并广播出去让其他节点接受、并立即对该节点进行主从切换。cluster-node-timeout ,当某个节点持续timeout时间失联,才认为该节点故障,需要主从切换,从而避免频繁的主从切换(数据的重新复制)。
3. Redis的淘汰策略volatile_lru:从设置过期的key中,挑选最近最少使用的key。
volatile_ttl:从设置过期的key中,挑选即将过期的key。
volatile_random:从设置过期的key中,随机挑选一个key。
allkeys_lru:从数据集中,挑选最近最少使用的key。
allkeys_random:从数据集中,随机挑选一个key。
- no_enviction:禁止淘汰数据(还是会根据引用计数进行内存释放),当内存使用超过设置的阈值,若再有内存申请操作则会失败。
4. Redis解决并发问题的思路
- 采用单进程单线程模式,没有锁的概念
- 通过队列将并发访问串行化
- 通过setnx命令,若不存在则设置对应的key
多路复用,保证高并发,定时任务,小顶堆,将最近最快要执行的任务放在堆顶,距离要执行的时间为多路复用的timeout,因为redis知道这段时间是没有任务要执行的,可以安心sleep,QPS可以达到10w/s。
5. Redis内存回收
- 对于不再引用或者过期的key,采用惰性和定时任务检测的方式,用户有请求过来、同时判断此key是否过期,若过期则删除并返回空,定时任务随机选取一些key(可配置),判断是否过期,对于Redis单进程单线程的架构来说,这样可以节省CPU和内存。定时任务每个数据库随机抽检20个key,发现过期则删除,若超过检查数目的25%的key过期,则循环执行,直到不足25%或者超过执行时间。
当设置了最大使用内存后、并且内存使用已经超过设置阈值,则采用上述淘汰策略进行内存回收。
6. Redis的数据类型
- string:动态的字符串,可以修改,当字符串长度小于1MB的时候,扩充都是加倍现有空间,超过1MB的话,扩充一次最多增加1MB,最大512MB。
- list:类似于java的linklist,插入和删除很快,O(1),但是查找很慢,O(n), 当弹出list的最后一个元素后,该list自动被删除,内存被回收。ziplist和双向链表结合来实现quicklist,ziplist里面是一块连续的内存,是经过压缩的,因为对于int等基础类型,额外的两个指针太耗费空间,存储方式类似于LevelDb里面的Block,最后通过双向链表将ziplist连起来,这样既满足快速插入、删除的特性,空间浪费也不多。
- hash:相当于java的HashMap,无序字典,内部实现是用数组+链表,第一维的数组出现碰撞,则存到链表里面去。Rehash的时候,为了不阻塞服务,采用的是渐进式的Rehash,保留2个Hash,逐渐在指令执行或者定时任务中,将数据从老的Hash迁移到新的Hash。
- set:相当于java的HashSet,无序的键值对,不过其值都是NULL,键不可以重复。数据量较少且是整数的时候用有序数组,较大的时候采用散列表。
zset:最具特色的数据结构,也是面试官问的最多的知识点。通过散列表+跳表实现,一方面是一个set,保证键的唯一性,另一方面,可以给每个value赋一个score,可以根据score排序、区段查找。应用场景:value为粉丝ID,score是关注时间,可以按照关注时间顺序给出粉丝ID。value是学生ID,score是其分数,可以按照分数排序。
7. Redis的过期设置
Redis所有的数据结构都可以设置过期时间,比如hash,需要注意,只能对hash整体设置过期时间,无法对其中的单个field设置过期时间。若一个对象已经设置了过期时间,但是待会你又修改了他,那么他的过期时间就会消失,也就是需要重新设置过期时间。
8. Redis分布式锁的一些讨论
redis是单进程单线程,本身没有锁的概念,主要是应用分布在多台机器,客户端不同顺序访问引起的互斥问题,例如,A读取字段field1,然后修改设置,B也同时读取字段field1(在A修改生效前),然后也修改设置(在A修改生效后),这样B的修改就将A的修改覆盖掉了,下面是递进的几种改进思路。setnx key value; del key,若程序异常,del没有执行的话,则其他程序永远得不到锁了。
setnx key value; expire key 超时时间(单位秒);del key,加一个超时命令,似乎能解决问题,但是也存在同样的问题,即在执行expire之前程序就可能core dump了。
set key value ex 超时时间(单位秒) nx; del key,这个基本没有问题了,但是业务执行时间不能超过超时时间,否则可能也会有问题。例如,程序A获得了锁,并执行,过了设置的超时时间后,锁自动释放,程序B获得锁,这个时候程序A执行完毕,将锁删除了。这样程序C就能获得锁,B和C可能会产生冲突。
如果产生锁的时候随机生成一个数,删除的时候先check一下随机数是否相同,只有相同了才能删除锁(即是当时生产锁的责任人)。Redis本身没有这个机制(检测和删除不是原子的),不过可以通过lua脚本来实现。
- 若是Redis集群,主从切换期间,程序A先在主机申请获得了一把锁,这时候发生主从切换,从机还没有感知到那把锁(即还没有将对应key同步过来),然后程序B又在新的主机(原来的从机)申请获得了一把同样的锁,这样业务就会出现问题。出现这个情况,本质上是因为Redis集群是异步复制(先给客户端回包,再主->从replication),不像Paxos等强一致性保证。
分布式锁通常采用租约的形式,即设定的一个超时时间,避免某个获得锁的客户端挂死导致锁一直得不到释放。
租约锁通常是不安全的,例如,程序A获得锁,尝试修改某些信息,在这期间可能因为网络、java等的GC机制导致程序暂停,很可能就过了租约期了即使在前面加多次check租约是否到期的逻辑、也可能没有用。这个时候程序B获得锁,并发的修改的某些受控信息,这就会引起混乱。
给资源加上fencing token,递增的数字token,这个时候,配合的,存储服务需要check 一下token的值,只能递增的修改,不能回头,比如token 34修改过了,token 33就不能修改了。
RedLock没有提供fenciing token 机制, 随机数不能解决这个问题,单机提供一个计数器也不行,若要多机的话,需要一个consensus算法生成fencing token。
通常,分布式一致性算法,是不会去依赖时间的,性能可能很差,但是绝不会出错,比如paxos。
RedLock 做了很多时间假设,假设网络延迟等时间、程序因为GC等暂停的时间比锁的租约时间小,redis某节点拥有的key的时间也小于锁租约时间。
- 作者的一些建议:1)如果用锁是为了效率(避免做多次做很重的活),可以直接用单例redis(conditional set-if-not-exists to obtain a lock, atomic delete-if-value-matches to release a lock),不用太多担心;2)如果用锁是为了正确,请不要用RedLock, 不靠谱,应该用zk等。
9. Redis中使用lua脚本的好处及其限制
- lua脚本中的命令一起执行,是原子的,不用担心被打断,有效解决多个客户端的读+修改+回写引起的冲突问题。
- 可以定制自己的命令,并常驻内存。
- 有效降少客户单、服务器之间的交互。
- lua脚本不要执行太长时间,默认是不超过5秒。
- redis+lua适合单机,不适合集群,主要是没有实现调度,一个脚本中的所有key要在同一个槽点执行。
- 为了安全考虑,屏蔽了很多命令。
阿里云redis集群支持lua,不过对脚本做了如下限制:1)所有key应该由keys数组传递,2)所有key必须在一个slot上,3)调用必须带key。
场景举例,往集合里面添加100w条记录,计算其中不重复的数据个数,若用set去重,会占用很多空间,使用hyperloglog只用12KB,但是会损失一些精准度,误差在0.81%左右。
11. Redis中的布隆过滤组件
布隆过滤器可以作为一个插件加载到redis server: redis-server --loadmodule /path/to/redisbloom.so 一个大型的位数组和若干无偏Hash函数,多个Hash函数保证元素的hash值算的均匀一点。add操作:经过若干Hash函数,计算出若干hash值,和位数组大小取模后得到数组的索引,然后将对应位置设置为1.
- exists操作:和add一样,先经过若干Hash函数,计算出若干hash值,和位数组大小取模后得到一些数组的索引,判断这些索引对应的位置的值,只要有一个为0,则说明不存在。如果都为1的话,则说明存在。”存在“的判断可能会有误判,因为可能是其他内容设置的值,”不存在“的判断没有误判。
12. Redis限流模块
redis-cell,rust语言编写的基于令牌桶算法的限流模块,举例: cl.throttle "svr:itf" 15 30 60 1 其中, "svr:itf":限流对象 15:capacity, 桶的容量 30:操作次数 60:60s,和上面一个值表示,在60s内最多有30次操作 1:可选参数,默认值是1,代表一个操作。针对某个限流微服务接口,预先设置好访问频率,每次请求过来,执行类似的如上命令,若返回0代表可以调用,若返回1则表示不可以调用。若一段时间后,接口频率增大了,可以重新使用此命令设置一次(调整桶的容量和频次)。
13. GeoHash算法
地理位置距离排序算法GeoHash算法。 经度:(-180, 180],以本初子午线(英国格林尼治天文台)东正西负。 纬度:(-90, 90],以赤道为界,北正南负。将地球想象成一个平面,用正方形方格分隔它,最终将二维坐标映射成一个整数,整数越长,精度越精确。通过zset结构存储,value是地址,score是上面映射的52位整数,通过zset的score排序,就可以得到附近的人的坐标(整数还原成二维坐标)
添加经纬度信息:geoadd key longitude latitude member [longitude latitude member ...]
计算两者距离:geodist key member1 member2 [unit]
获取集合中元素的地理信息:geopos key member [member ...]
获取某个地点的geohash编码:geohash key member[member ...]
- 查找指定元素附近的其他元素:1)georadiusbymember key member radius m|km|ft|mi [WITHCOORD][WITHDIST][COUNT count][ASC|DESC][STORE key][STOREDIST key], 2) georadius key longitude latitude radius m|km|ft|mi [WITHCOORD][WITHDIST][COUNT count][ASC|DESC][STORE key][STOREDIST key]
geoXXX 操作的是一个zset结构,假设key为company,则可以通过del company 来删除整个集合,geo没有提供删除单个元素的接口,不过可以通过zrem key member来删除某个值。需要注意geo结构的大小(zset),若用redis集群,结果过大会给集群迁移造成停顿,可以按照国家/城市/区做划分,前面再加一个地点路由,减少key的数量。
14. Redis的scan
通过游标、分步骤执行,不阻塞线程,不影响其他指令的执行,通过limit限制每次吐出的数据,可多可少,返回结果可能是重复的,需要客户端去重,服务器不保存游标状态,唯一的游标状态是返回的游标整数,单次返回空不代表遍历结束,遍历是否结束要看返回的游标整数是否为0。在遍历过程中,修改后的值能否遍历到,这是不确定的。
scan x match y count limit , x~游标,从0开始,本次scan会返回一个游标,下次scan用那个返回的游标,直到为0才算结束,y~key的正则匹配,limit~每次返回的limit(实际是遍历的槽位数目),只是一个参考。
key的的存储结构:一维数组+二维链表,一维数组也就是槽位,limit指的是这个,之所以返回的数量有多有少,是因为并不是所有槽位上面都挂有链表。
扩容是按照一维数组来的,为了避免扩容、缩容的过程中重复遍历元素,采用高位加法(从左到右开始加并进位)。
zscan对zset扫描,hscan对hash扫描,sscan对set扫描。
15. 大key问题
大key对redis是一个挑战,包括redis集群(集群会迁移节点),内存申请、扩容、删除等场景造成卡顿。
scan->type指令得到各个数据类似->用各个数据结构的size/len计算大小,对每种类型,保留topN,通过这种方式找到大key。
官方脚本:redis-cli -h 127.0.0.1 -p 6379 -bigkeys -i 0.1 , -i 0.1 代表每执行100条指令休息0.1秒。
16. Redis通信协议
直观的文本协议,实现简单,解析性能好,单元结束后统一加上\r\n。单行字符串,以+符号开始 ,+hello world\r\n
多行字符串,以$符号开始,后跟字符串长度 $11\r\nhello world\r\n
整数值,以:符号开始,后跟整数的字符串形式 :1024\r\n
错误消息,以-符号开始, -WRONGTYPE Operation against a key holding the wrong kind of value
数组,以*开始,后跟数组的长度,*3\r\n:1\r\n:2\r\n:3\r\n
NULL用多行字符串表示,不过长度要写成-1, $-1\r\n
- 空行用多行字符串表示,长度填0,$0\r\n
快照(rdb文件),全量备份,内存数据的二进制序列化,非常紧凑,通过COW(Copy on Write)机制,fork一个子进程专门用于写磁盘,父进程继续接受请求进行处理,一开始父子进程共享数据段,当父进程有写操作的时候,会在写之前单独拷贝一份内容给子进程(以页为单位),这样虽然会导致内存增大,但是可以保证数据在某一时刻的一致性,即“快照”,通过save/bgsave 产生快照。
AOF日志,连续的增量备份,内存修改记录的指令文本,需要定期重写,只存储修改指令,指令参数校验没有问题后,写AOF日志、然后执行指令,长时间的运行会导致AOF日志过大,系统重启后的回放也很耗时。通过bgrewriteaof命令开启子进程进行日志瘦身,将可以合并的写指令进行合并。fsync,控制刷盘时间,通常1s一次,在性能和安全之间做权衡。
- 混合持久化,快照(rdb文件)和AOF同时使用,此时AOF不是增量备份文件,而是快照落盘开始到落盘结束这段时间的增量内容。
通常主节点不持久化,由从节点进行持久化,适当增加从节点的个数,保证数据安全。
18. pipeline与事务
为提高执行效率,通过pipeline一次执行多个命令,且整体当做一个事务,满足隔离性但是不满足原子性,比如3个命令,第二个失败了,第三个会继续执行。pipeline不是服务端的特性,是客户端的特性,客户端通过改变读写顺序带来了性能的巨大提升(前提是pipeline中的多条命令没有前后数据依赖,通常也不会有的)。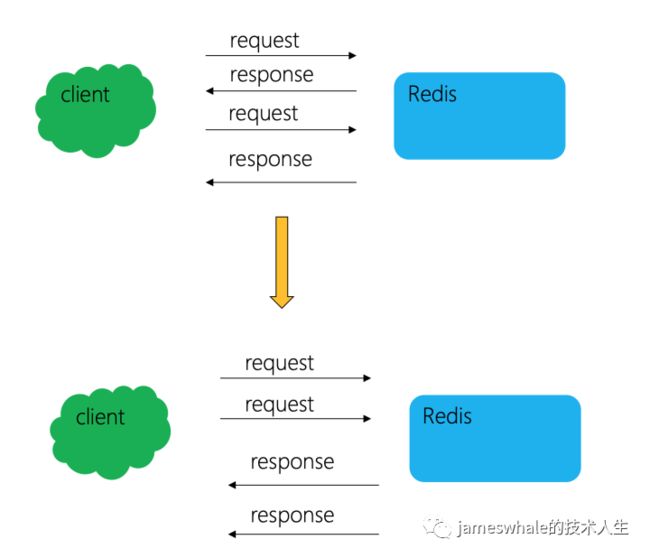
19. Redis内存占用
32bit位编译,内存上限是4GB,可以使指针等内存减少一半,可以结合多实例来突破4GB的限制。
小对象压缩存储ziplist见下图,若是hash,key和value作为两个entry相邻在一起,若是zset,value和score作为两个entry相邻在一起。
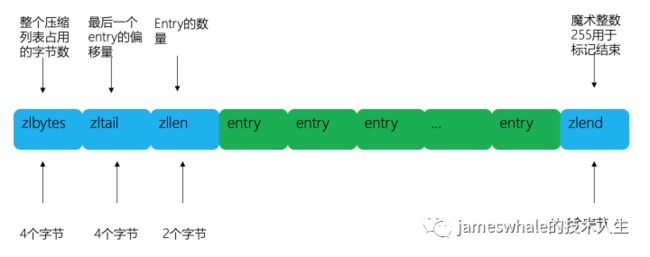
intset:紧凑型set,用于整数且数量较小的set集合,若有字符串,则立即升级为hashtable结构。不同的数据结构,当数量或者元素大小较小的时候,用紧凑型存储,当超过规定后,开始用标准存储,一般元素个数是512,元素大小是64字节。
下面是各个控制参数的意义:
hash-max-zipmap-entries 512 : hash的元素个数超过512就必须使用标准结构存储。
hash-max-zipmap-value 64:hash的任意元素的key/value的长度超过64就必须使用标准结构存储。
list-max-ziplist-entries 512 : list的元素个数超过512就必须使用标准结构存储。
list-max-ziplist-value 64:list的任意元素的长度超过64就必须使用标准结构存储。
zset-max-ziplist-entries 128 : zset的元素个数超过128就必须使用标准结构存储。
zset-max-ziplist-value 64:zset的任意元素的长度超过64就必须使用标准结构存储。
- set-max-intset-entries 512 : set的元素个数超过512就必须使用标准结构存储。
20. Redis内存分配与回收
Redis没有管内存分配,直接采用第三方内存分配算法,libc、jemalloc,tcmalloc。删除key后并不会让内存立即释放,因为操作系统回收是以页为单位的,只要这一页还有1个key在使用,就无法回收。Redis会重用已经删除的key的内存的。
21. Redis主从同步
CAP原理:C-一致性,A-可用性,P-分区容忍性, 当网络发生故障(网络分区),分布的节点无法互相访问:若保证一致性,则无法对外提供修改(若能修改,则必然不一致了)。
- 若保证可用性(可修改),则无法保证一致性。
增量同步,同步的是修改状态的指令流,指令流有一个固定的buffer,循环使用,绕一圈则覆盖,主机将指令流同步给从机,从机执行指令流,并告知主机的指令偏移。
快照同步,先在主库上面执行bgsave将当前内存的数据全部快照到磁盘,拷贝到从机,执行全量加载,加载完毕后通知主机进行增量同步,若快照过大,在快照恢复期间,主机的指令流buffer满了,从机即使加载了快照仍然无法从主机同步增量,这就需要重新弄一变快照,极端情况可能会死循环,所以要合理设置buffer大小。
- 无盘复制:主机通过套接字将快照内容发给从机,生成快照是一个遍历的过程,一边遍历,一边将内容序列化后发给从机,从机接受后先保存到本地文件,后面再一次性load。
Redis的复制默认是异步,wait指令可以将异步变成同步,确保系统强一致,不过这会一定程度上影响主机的执行效率。wait param1 param2, param1~从机的数量,param2~时间,最多等待param2毫秒,为0则表示无限等待直到N个从库同步完成。
22. Redis Sentinel 模式
类似一个zk集群,多机,专门负责Redis的主从切换,客户端先请求Sentinel,Sentinel负责分配主机地址给客户端,后续客户端直接和给定的主机地址通信。若Redis主机挂掉,Sentinel会识别出来,并从多个从机中选择一个作为主机,原先挂掉的主机恢复后成为从机,和新的主机进行同步,客户端原先的旧的链接会断掉、重新连接、或者抛出readonly异常(旧的主机恢复后变成从机,只读,不能修改)。min-slaves-to-write 1 主节点至少有一个从节点在正常同步,否则停止对外提供写操作。min-slaves-max-lag 10 如果10s内没有收到从节点的反馈,则说明从节点同步异常。
Sentinel切换主从,客户端如何感知:redis-py 建立链接的时候,会和库内主地址比较,若不一样,则会断掉所有链接、重新创建链接。
若是原先主库异常恢复后降为从机,原先链接的写操作会抛ReadOnly错误,检测到此错误后会断掉旧链接、创建新链接。
- 接续第二点,若只有读操作,链接没有切换,这样也没有危险,让他继续好了(若没有来得及同步,则可能会有一点不一致)。
23. Codis,分而治之
go语言开发,对外提供的协议和Redis一样,外界无感知,代理中间件,Codis后面挂多个Redis实例,形成一个Redis集群,可以在线扩容。
通过zk、etcd持久化槽位信息,Codis proxy 通过监听槽位变化并同步槽位信息,从而实现多个Codis proxy共享相同的槽位信息。
Codis内存维护槽位和Redis实例的关系,例如1024个槽位,根据key计算相应的槽位(crc32 hash然后取1024余数),然后根据槽位得到Redis实例。hash = crc32(command.key)
slot_index = hash % 1024
redis = slot[slot_index].redis
redis.do(command)