CDNow网站的用户购买明细分析
CDNow网站的用户购买明细分析
数据集来源于CDnow网站的用户购买行为,数据集一共包含四个字段:user_id,购买日期,购买数量和购买金额。属于非常典型的消费行为数据集。
数据集下载链接:
链接:https://pan.baidu.com/s/1l6Mu4TUpcGTaJMuxiuftQw
提取码:838h
1.数据加载与描述性统计
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime
%matplotlib inline
plt.style.use('ggplot')
columns=['user_id','order_dt','order_products','order_amount']#生成列名
df=pd.read_csv('CDNOW_master.txt',names=columns,sep='\s+')#载入数据
加载包和数据,文件是txt,用read_csv方法打开,因为原始数据不包含表头,所以需要赋予。字符串是空格分割,用\s+表示匹配任意空白符。
df.head()
| user_id | order_dt | order_products | order_amount | |
|---|---|---|---|---|
| 0 | 1 | 19970101 | 1 | 11.77 |
| 1 | 2 | 19970112 | 1 | 12.00 |
| 2 | 2 | 19970112 | 5 | 77.00 |
| 3 | 3 | 19970102 | 2 | 20.76 |
| 4 | 3 | 19970330 | 2 | 20.76 |
观察数据,order_dt表示时间,但现在它只是年月日组合的一串数字,没有时间含义。购买金额是小数。值得注意的是,一个用户在一天内可能购买多次,用户ID为2的用户就在1月12日买了两次。
df.describe()
| user_id | order_dt | order_products | order_amount | |
|---|---|---|---|---|
| count | 69659.000000 | 6.965900e+04 | 69659.000000 | 69659.000000 |
| mean | 11470.854592 | 1.997228e+07 | 2.410040 | 35.893648 |
| std | 6819.904848 | 3.837735e+03 | 2.333924 | 36.281942 |
| min | 1.000000 | 1.997010e+07 | 1.000000 | 0.000000 |
| 25% | 5506.000000 | 1.997022e+07 | 1.000000 | 14.490000 |
| 50% | 11410.000000 | 1.997042e+07 | 2.000000 | 25.980000 |
| 75% | 17273.000000 | 1.997111e+07 | 3.000000 | 43.700000 |
| max | 23570.000000 | 1.998063e+07 | 99.000000 | 1286.010000 |
用户平均每笔订单购买2.4个商品,标准差在2.3,稍稍具有波动性。中位数在2个商品,75分位数在3个商品,说明绝大部分订单的购买量都不多。最大值在99个,数字比较高。购买金额的情况差不多,大部分订单都集中在小额。
df.info()
RangeIndex: 69659 entries, 0 to 69658
Data columns (total 4 columns):
user_id 69659 non-null int64
order_dt 69659 non-null int64
order_products 69659 non-null int64
order_amount 69659 non-null float64
dtypes: float64(1), int64(3)
memory usage: 2.1 MB
没有空值,很干净的数据。
2.初步分析
2.1.时间的数据类型转换
df['order_date']=pd.to_datetime(df['order_dt'],format='%Y%m%d')#转换格式
df['month']=df['order_date'].values.astype('datetime64[M]')#以月作为消费频率
df.head()
| user_id | order_dt | order_products | order_amount | order_date | month | |
|---|---|---|---|---|---|---|
| 0 | 1 | 19970101 | 1 | 11.77 | 1997-01-01 | 1997-01-01 |
| 1 | 2 | 19970112 | 1 | 12.00 | 1997-01-12 | 1997-01-01 |
| 2 | 2 | 19970112 | 5 | 77.00 | 1997-01-12 | 1997-01-01 |
| 3 | 3 | 19970102 | 2 | 20.76 | 1997-01-02 | 1997-01-01 |
| 4 | 3 | 19970330 | 2 | 20.76 | 1997-03-30 | 1997-03-01 |
将order_dt列数据转变为标准日期格式,形成order_data列,month列为每份订单的订单日期所处的月份,为后面分析做准备。
2.2.从用户角度分析消费情况
user_consume=df.groupby('user_id').sum()[['order_products','order_amount']]#单个用户的消费情况
user_consume.head()
| order_products | order_amount | |
|---|---|---|
| user_id | ||
| 1 | 1 | 11.77 |
| 2 | 6 | 89.00 |
| 3 | 16 | 156.46 |
| 4 | 7 | 100.50 |
| 5 | 29 | 385.61 |
user_consume.describe()
| order_products | order_amount | |
|---|---|---|
| count | 23570.000000 | 23570.000000 |
| mean | 7.122656 | 106.080426 |
| std | 16.983531 | 240.925195 |
| min | 1.000000 | 0.000000 |
| 25% | 1.000000 | 19.970000 |
| 50% | 3.000000 | 43.395000 |
| 75% | 7.000000 | 106.475000 |
| max | 1033.000000 | 13990.930000 |
从用户角度看,每位用户平均购买7张CD,最多的用户购买了1033张,属于狂热用户了。用户的平均消费金额(客单价)100元,标准差是240,结合分位数和最大值看,平均值才和75分位接近,肯定存在小部分的高额消费用户。
2.3.月消费情况
month_consume=df.groupby('month').sum()[['order_products','order_amount']]#每月的消费情况
month_consume.head()
| order_products | order_amount | |
|---|---|---|
| month | ||
| 1997-01-01 | 19416 | 299060.17 |
| 1997-02-01 | 24921 | 379590.03 |
| 1997-03-01 | 26159 | 393155.27 |
| 1997-04-01 | 9729 | 142824.49 |
| 1997-05-01 | 7275 | 107933.30 |
month_consume.describe()
| order_products | order_amount | |
|---|---|---|
| count | 18.000000 | 18.000000 |
| mean | 9326.722222 | 138906.423889 |
| std | 6760.373744 | 103884.935965 |
| min | 4697.000000 | 66231.520000 |
| 25% | 5437.250000 | 78309.920000 |
| 50% | 6846.500000 | 101755.325000 |
| 75% | 8051.250000 | 120421.320000 |
| max | 26159.000000 | 393155.270000 |
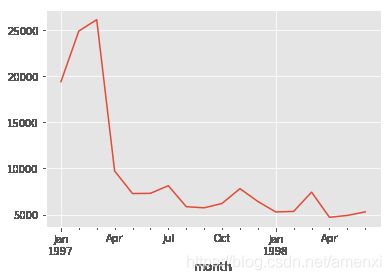
month_consume.order_products.plot()#月度订单折线图
month_consume.order_amount.plot()#月度销售额折线图
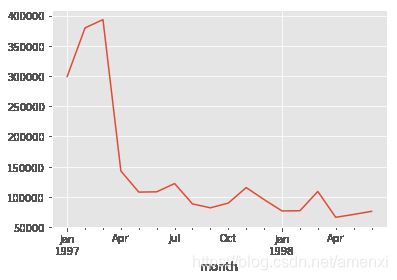
按月统计每个月的CD销量。从图中可以看到,前几个月的销量非常高涨。数据比较异常。而后期的销量则很平稳。金额一样呈现早期销售额多,后期平稳下降的趋势。为什么会呈现这个原因呢?我们假设是用户身上出了问题,早期时间段的用户中有异常值,第二假设是各类促销营销,但这里只有消费数据,所以无法判断。
2.4.订单和销售额情况
df.plot.scatter(x='order_products',y='order_amount')#每单‘销售额和订单数点图’

绘制每笔订单的散点图。从图中观察,订单消费金额和订单商品量呈规律性,每个商品十元左右。订单的极值较少,超出1000的就几个。显然不是异常波动的罪魁祸首。
user_consume.plot.scatter(x='order_products',y='order_amount')#每人‘销售额和订单数点图’

绘制用户的散点图,用户也比较健康,而且规律性比订单更强。因为这是CD网站的销售数据,商品比较单一,金额和商品量的关系也因此呈线性,没几个离群点。消费能力特别强的用户有,但是数量不多。为了更好的观察,用直方图。
fig=plt.figure(figsize=(12,4))
fig.add_subplot(1,2,1)
df.order_amount.hist(bins=30)
fig.add_subplot(1,2,2)
user_consume.order_products.hist(bins=30)

从直方图看,大部分用户的消费能力确实不高,高消费用户在图上几乎看不到。这也确实符合消费行为的行业规律。
观察完用户消费的金额和购买量,接下来看消费的时间节点。
2.5.消费的时间节点
df.groupby('user_id').month.min().value_counts()
1997-02-01 8476
1997-01-01 7846
1997-03-01 7248
Name: month, dtype: int64
用groupby函数将用户分组,并且求月份的最小值,最小值即用户消费行为中的第一次消费时间。结果出来了,所有用户的第一次消费都集中在前三个月。我们可以这样认为,该订单数据只是选择了某个时间段消费的用户在18个月内的消费行为。
df.groupby('user_id').month.max().value_counts()
1997-02-01 4912
1997-03-01 4478
1997-01-01 4192
1998-06-01 1506
1998-05-01 1042
1998-03-01 993
1998-04-01 769
1997-04-01 677
1997-12-01 620
1997-11-01 609
1998-02-01 550
1998-01-01 514
1997-06-01 499
1997-07-01 493
1997-05-01 480
1997-10-01 455
1997-09-01 397
1997-08-01 384
Name: month, dtype: int64
观察用户的最后一次消费时间。绝大部分数据依然集中在前三个月。后续的时间段内,依然有用户在消费,但是缓慢减少。
异常趋势的原因获得了解释,现在针对消费数据进一步细分。我们要明确,这只是部分用户的订单数据,所以有一定局限性。在这里,我们统一将数据上消费的用户定义为新客。
3.复购率和回购率分析
3.1.数据透视
#统计消费用户消费次数
pivoted_counts=df.pivot_table(index='user_id',columns='month',values='order_dt',aggfunc='count').fillna(0)
columns_month=df.month.sort_values().astype('str').unique()
pivoted_counts.columns=columns_month
pivoted_counts.head()
| 1997-01-01 | 1997-02-01 | 1997-03-01 | 1997-04-01 | 1997-05-01 | 1997-06-01 | 1997-07-01 | 1997-08-01 | 1997-09-01 | 1997-10-01 | 1997-11-01 | 1997-12-01 | 1998-01-01 | 1998-02-01 | 1998-03-01 | 1998-04-01 | 1998-05-01 | 1998-06-01 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||
| 1 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 1.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 4 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 5 | 2.0 | 1.0 | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 2.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
3.2.复购率分析
pivoted_counts_reorder=pivoted_counts.applymap(lambda x:1 if x>1 else np.NaN if x==0 else 0)#统计消费用户是否复购
pivoted_counts_reorder.head()
| 1997-01-01 | 1997-02-01 | 1997-03-01 | 1997-04-01 | 1997-05-01 | 1997-06-01 | 1997-07-01 | 1997-08-01 | 1997-09-01 | 1997-10-01 | 1997-11-01 | 1997-12-01 | 1998-01-01 | 1998-02-01 | 1998-03-01 | 1998-04-01 | 1998-05-01 | 1998-06-01 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||
| 1 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 0.0 | NaN | 0.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | 1.0 | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN |
| 4 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 5 | 1.0 | 0.0 | NaN | 0.0 | 0.0 | 0.0 | 0.0 | NaN | 0.0 | NaN | NaN | 1.0 | 0.0 | NaN | NaN | NaN | NaN | NaN |
这里的时间窗口是月,如果一个用户在同一天下了两笔订单,这里也将他算作复购用户。将数据转换一下,消费两次及以上记为1,消费一次记为0,没有消费记为NaN。
month_counts_reorder_rate=pd.DataFrame(pivoted_counts_reorder.sum()/pivoted_counts_reorder.count())#计算复购率
plt.figure(figsize=(10,4))
plt.plot(month_counts_reorder_rate)
plt.xticks(rotation=90)
([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17],
)

图上可以看出复购率在早期,因为大量新用户加入的关系,新客的复购率并不高,譬如1月新客们的复购率只有6%左右。而在后期,这时的用户都是大浪淘沙剩下的老客,复购率比较稳定,在20%左右。单看新客和老客,复购率有三倍左右的差距。
3.3.回购率分析
#统计用户是否回购
def func_repurchase(data):
status=[]
for i in range(data.count()-1):
if data[i]>0:
if data[i+1]>0:
status.append(1)
else:
status.append(0)
else:
status.append(np.NaN)
status.append(np.NaN)
return pd.Series(status,index=data.index)
repurchase=pivoted_counts.apply(func_repurchase,axis=1)
repurchase.head(5)
| 1997-01-01 | 1997-02-01 | 1997-03-01 | 1997-04-01 | 1997-05-01 | 1997-06-01 | 1997-07-01 | 1997-08-01 | 1997-09-01 | 1997-10-01 | 1997-11-01 | 1997-12-01 | 1998-01-01 | 1998-02-01 | 1998-03-01 | 1998-04-01 | 1998-05-01 | 1998-06-01 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||
| 1 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 0.0 | NaN | 1.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN |
| 4 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 5 | 1.0 | 0.0 | NaN | 1.0 | 1.0 | 1.0 | 0.0 | NaN | 0.0 | NaN | NaN | 1.0 | 0.0 | NaN | NaN | NaN | NaN | NaN |
if的主要逻辑是,如果用户本月进行过消费,且下月消费过,记为1,没有消费过是0。本月若没有进行过消费,为NaN,后续的统计中进行排除。
repurchase_rate=pd.DataFrame(repurchase.sum()/repurchase.count())#计算复购率
plt.figure(figsize=(10,4))
plt.plot(repurchase_rate)
plt.xticks(rotation=90)
([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17],
)

从图中可以看出,用户的回购率高于复购,约在30%左右,波动性也较强。新用户的回购率在15%左右,和老客差异不大。
将回购率和复购率综合分析,可以得出,新客的整体质量低于老客,老客的忠诚度(回购率)表现较好,消费频次稍次,这是CDNow网站的用户消费特征。
4.用户分层分析
#用户分层
def active_status(data):
status=[]
if data[0]==0:
status.append('unreg')
else:
status.append('new')
for i in range(data.count()-1):
if data[i+1]==0:
if status[i]=='unreg':
status.append('unreg')
else:
status.append('unactive')
else:
if status[i]=='unreg':
status.append('new')
elif data[i]>0:
status.append('active')
else:
status.append('return')
return pd.Series(status,index=data.index)
pivoted_purchase_status=pivoted_counts.apply(active_status,axis=1)
pivoted_purchase_status.head()
| 1997-01-01 | 1997-02-01 | 1997-03-01 | 1997-04-01 | 1997-05-01 | 1997-06-01 | 1997-07-01 | 1997-08-01 | 1997-09-01 | 1997-10-01 | 1997-11-01 | 1997-12-01 | 1998-01-01 | 1998-02-01 | 1998-03-01 | 1998-04-01 | 1998-05-01 | 1998-06-01 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||
| 1 | new | unactive | unactive | unactive | unactive | unactive | unactive | unactive | unactive | unactive | unactive | unactive | unactive | unactive | unactive | unactive | unactive | unactive |
| 2 | new | unactive | unactive | unactive | unactive | unactive | unactive | unactive | unactive | unactive | unactive | unactive | unactive | unactive | unactive | unactive | unactive | unactive |
| 3 | new | unactive | return | active | unactive | unactive | unactive | unactive | unactive | unactive | return | unactive | unactive | unactive | unactive | unactive | return | unactive |
| 4 | new | unactive | unactive | unactive | unactive | unactive | unactive | return | unactive | unactive | unactive | return | unactive | unactive | unactive | unactive | unactive | unactive |
| 5 | new | active | unactive | return | active | active | active | unactive | return | unactive | unactive | return | active | unactive | unactive | unactive | unactive | unactive |
我们按照用户的消费行为,简单划分成几个维度:新用户、活跃用户、不活跃用户、回流用户。
新用户的定义是第一次消费。活跃用户,在某一个时间窗口和前一个消费窗口都有过消费。用户有过一次以上的消费就可叫做老客,不活跃用户则是时间窗口内没有消费过的老客。回流用户是在上一个窗口中没有消费,而在当前时间窗口内有过消费。以上的时间窗口都是按月统计。
purchase_status_counts=pivoted_purchase_status.replace('unreg',np.NaN).apply(lambda x:pd.value_counts(x))#统计不同分层用户个数
purchase_status_counts
| 1997-01-01 | 1997-02-01 | 1997-03-01 | 1997-04-01 | 1997-05-01 | 1997-06-01 | 1997-07-01 | 1997-08-01 | 1997-09-01 | 1997-10-01 | 1997-11-01 | 1997-12-01 | 1998-01-01 | 1998-02-01 | 1998-03-01 | 1998-04-01 | 1998-05-01 | 1998-06-01 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| active | NaN | 1157.0 | 1681 | 1773.0 | 852.0 | 747.0 | 746.0 | 604.0 | 528.0 | 532.0 | 624.0 | 632.0 | 512.0 | 472.0 | 571.0 | 518.0 | 459.0 | 446.0 |
| new | 7846.0 | 8476.0 | 7248 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| return | NaN | NaN | 595 | 1049.0 | 1362.0 | 1592.0 | 1434.0 | 1168.0 | 1211.0 | 1307.0 | 1404.0 | 1232.0 | 1025.0 | 1079.0 | 1489.0 | 919.0 | 1029.0 | 1060.0 |
| unactive | NaN | 6689.0 | 14046 | 20748.0 | 21356.0 | 21231.0 | 21390.0 | 21798.0 | 21831.0 | 21731.0 | 21542.0 | 21706.0 | 22033.0 | 22019.0 | 21510.0 | 22133.0 | 22082.0 | 22064.0 |
plt.figure(figsize=(10,4))
plt.plot(purchase_status_counts.T)
plt.xticks(rotation=90)
plt.legend(purchase_status_counts.index)
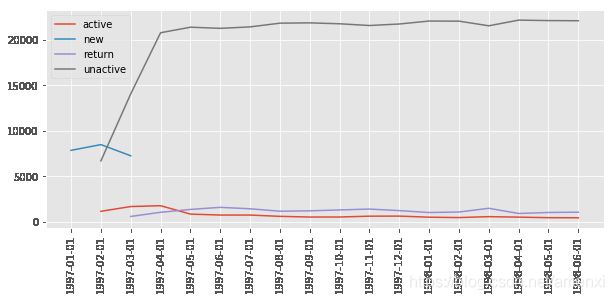
由上图可知回流用户和活跃用户数后期比较稳定。
return_rata=purchase_status_counts.apply(lambda x:x/x.sum(),axis=1)#统计不同分层用户各月份比率
return_rata.head()
| 1997-01-01 | 1997-02-01 | 1997-03-01 | 1997-04-01 | 1997-05-01 | 1997-06-01 | 1997-07-01 | 1997-08-01 | 1997-09-01 | 1997-10-01 | 1997-11-01 | 1997-12-01 | 1998-01-01 | 1998-02-01 | 1998-03-01 | 1998-04-01 | 1998-05-01 | 1998-06-01 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| active | NaN | 0.090011 | 0.130776 | 0.137934 | 0.066283 | 0.058114 | 0.058036 | 0.046989 | 0.041077 | 0.041388 | 0.048545 | 0.049168 | 0.039832 | 0.036720 | 0.044422 | 0.040299 | 0.035709 | 0.034697 |
| new | 0.332881 | 0.359610 | 0.307510 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| return | NaN | NaN | 0.031390 | 0.055342 | 0.071854 | 0.083988 | 0.075653 | 0.061620 | 0.063888 | 0.068953 | 0.074070 | 0.064996 | 0.054075 | 0.056924 | 0.078554 | 0.048483 | 0.054286 | 0.055922 |
| unactive | NaN | 0.019337 | 0.040606 | 0.059981 | 0.061739 | 0.061377 | 0.061837 | 0.063017 | 0.063112 | 0.062823 | 0.062276 | 0.062751 | 0.063696 | 0.063655 | 0.062184 | 0.063985 | 0.063838 | 0.063786 |
4.1.回流用户和活跃用户分析
plt.figure(figsize=(10,6))
plt.plot(return_rata.loc[['active','return'],].T)
plt.legend(['active','return'])
plt.xticks(rotation=90)
([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17],
)
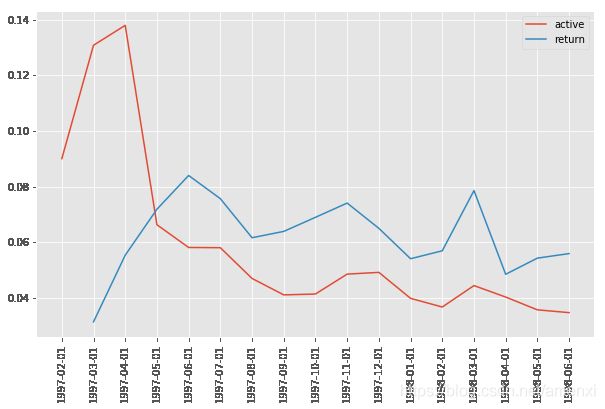
用户回流占比在5%~8%,有下降趋势。所谓回流占比,就是回流用户在总用户中的占比。另外一种指标叫回流率,指上个月多少不活跃/消费用户在本月活跃/消费。因为不活跃的用户总量近似不变,所以这里的回流率也近似回流占比。活跃用户的下降趋势更明显,占比在3%~5%间。这里用户活跃可以看作连续消费用户,质量在一定程度上高于回流用户。
结合回流用户和活跃用户看,在后期的消费用户中,60%是回流用户,40%是活跃用户/连续消费用户,整体质量还好,但是针对这两个分层依旧有改进的空间,可以继续细化数据。
4.2.用户质量分析
user_amount=df.groupby('user_id').order_amount.sum().sort_values().reset_index()
user_amount_sum=user_amount['order_amount'].sum()
user_amount['amount_cumsum'],user_amount['prop']=user_amount.order_amount.cumsum(),(user_amount.order_amount/user_amount_sum).cumsum()
user_amount.tail()
| user_id | order_amount | amount_cumsum | prop | |
|---|---|---|---|---|
| 23565 | 7931 | 6497.18 | 2463822.60 | 0.985405 |
| 23566 | 19339 | 6552.70 | 2470375.30 | 0.988025 |
| 23567 | 7983 | 6973.07 | 2477348.37 | 0.990814 |
| 23568 | 14048 | 8976.33 | 2486324.70 | 0.994404 |
| 23569 | 7592 | 13990.93 | 2500315.63 | 1.000000 |
新建一个对象,按用户的消费金额生序。使用cumsum,它是累加函数。逐行计算累计的金额,最后的2500315便是总消费额。
user_amount.prop.plot()

绘制趋势图,横坐标是按贡献金额大小排序而成,纵坐标则是用户累计贡献。可以很清楚的看到,前20000个用户贡献了40%的消费。后面4000位用户贡献了60%,确实呈现28倾向。
user_products=df.groupby('user_id').order_products.sum().sort_values().reset_index()
user_products_sum=user_products['order_products'].sum()
user_products['products_cumsum'],user_products['prop']=user_products.order_products.cumsum(),(user_products.order_products/user_products_sum).cumsum()
user_products.tail()
| user_id | order_products | products_cumsum | prop | |
|---|---|---|---|---|
| 23565 | 19339 | 378 | 164881 | 0.982130 |
| 23566 | 7931 | 514 | 165395 | 0.985192 |
| 23567 | 7983 | 536 | 165931 | 0.988385 |
| 23568 | 7592 | 917 | 166848 | 0.993847 |
| 23569 | 14048 | 1033 | 167881 | 1.000000 |
user_products.prop.plot()
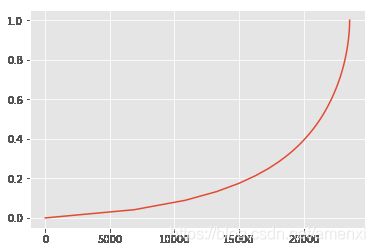
统计一下销量,前两万个用户贡献了40%的销量,高消费用户贡献了60%的销量。
在消费领域中,狠抓高质量用户是万古不变的道理。
4.3.用户生命周期分析
order_date_min,order_date_max=df.groupby('user_id').order_date.min(),df.groupby('user_id').order_date.max()
(order_date_max-order_date_min).head(10)#确定每位顾客的生命周期
user_id
1 0 days
2 0 days
3 511 days
4 345 days
5 367 days
6 0 days
7 445 days
8 452 days
9 523 days
10 0 days
Name: order_date, dtype: timedelta64[ns]
(order_date_max-order_date_min).describe()
count 23570
mean 134 days 20:55:36.987696
std 180 days 13:46:43.039788
min 0 days 00:00:00
25% 0 days 00:00:00
50% 0 days 00:00:00
75% 294 days 00:00:00
max 544 days 00:00:00
Name: order_date, dtype: object
用户生命周期,即第一次消费至最后一次消费的时间差。
因为数据中的用户都是前三个月第一次消费,所以这里的生命周期代表的是1月~3月用户的生命周期。因为用户会持续消费,所以理论上,随着后续的消费,用户的平均生命周期会增长。
所有用户的平均生命周期是134天,算比较高的了。
((order_date_max-order_date_min)/np.timedelta64(1,'D')).hist(bins=15)
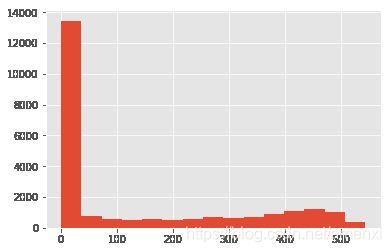
大部分用户只消费了一次,所有生命周期的大头都集中在了0天。但这不是我们想要的答案,不妨将只消费了一次的新客排除,来计算所有消费过两次以上的老客的生命周期。
life_time=(order_date_max-order_date_min).reset_index()
life_time.head()
| user_id | order_date | |
|---|---|---|
| 0 | 1 | 0 days |
| 1 | 2 | 0 days |
| 2 | 3 | 511 days |
| 3 | 4 | 345 days |
| 4 | 5 | 367 days |
life_time['life_time']=life_time.order_date/np.timedelta64(1,'D')
life_time[life_time.life_time>0].life_time.hist(bins=100,figsize=(10,5))#排除仅消费一次的用户
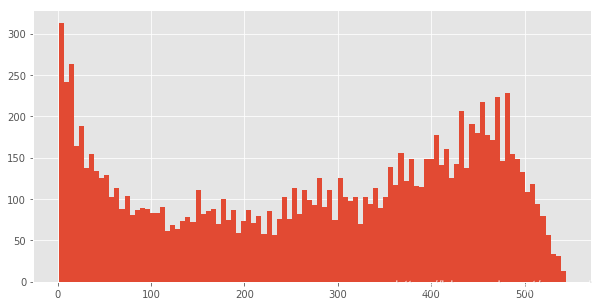
筛选出lifetime>0,即排除了仅消费了一次的那些人。做直方图。
这个图比上面的靠谱多了,虽然仍旧有不少用户生命周期靠拢在0天。这是双峰趋势图。部分质量差的用户,虽然消费了两次,但是仍旧无法持续,在用户首次消费30天内应该尽量引导。少部分用户集中在50天~300天,属于普通型的生命周期,高质量用户的生命周期,集中在400天以后,这已经属于忠诚用户了。
life_time[life_time.life_time>0].life_time.describe()
count 11516.000000
mean 276.044807
std 166.633990
min 1.000000
25% 117.000000
50% 302.000000
75% 429.000000
max 544.000000
Name: life_time, dtype: float64
消费两次以上的用户生命周期是276天,远高于总体。从策略看,用户首次消费后应该花费更多的引导其进行多次消费,提供生命周期,这会带来2.5倍的增量。
4.4.留存率分析
user_purchase_retention=pd.merge(left=df,right=order_date_min.reset_index(),on='user_id',suffixes=('','_min'))
user_purchase_retention['order_date_diff']=user_purchase_retention.order_date-user_purchase_retention.order_date_min
user_purchase_retention['date_diff']=user_purchase_retention['order_date_diff']/np.timedelta64(1,'D')
bin=[0,3,7,15,30,60,90,180,365]
user_purchase_retention['date_diff_bin']=pd.cut(user_purchase_retention.date_diff,bins=bin)
user_purchase_retention.head(10)
| user_id | order_dt | order_products | order_amount | order_date | month | order_date_min | order_date_diff | date_diff | date_diff_bin | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 19970101 | 1 | 11.77 | 1997-01-01 | 1997-01-01 | 1997-01-01 | 0 days | 0.0 | NaN |
| 1 | 2 | 19970112 | 1 | 12.00 | 1997-01-12 | 1997-01-01 | 1997-01-12 | 0 days | 0.0 | NaN |
| 2 | 2 | 19970112 | 5 | 77.00 | 1997-01-12 | 1997-01-01 | 1997-01-12 | 0 days | 0.0 | NaN |
| 3 | 3 | 19970102 | 2 | 20.76 | 1997-01-02 | 1997-01-01 | 1997-01-02 | 0 days | 0.0 | NaN |
| 4 | 3 | 19970330 | 2 | 20.76 | 1997-03-30 | 1997-03-01 | 1997-01-02 | 87 days | 87.0 | (60, 90] |
| 5 | 3 | 19970402 | 2 | 19.54 | 1997-04-02 | 1997-04-01 | 1997-01-02 | 90 days | 90.0 | (60, 90] |
| 6 | 3 | 19971115 | 5 | 57.45 | 1997-11-15 | 1997-11-01 | 1997-01-02 | 317 days | 317.0 | (180, 365] |
| 7 | 3 | 19971125 | 4 | 20.96 | 1997-11-25 | 1997-11-01 | 1997-01-02 | 327 days | 327.0 | (180, 365] |
| 8 | 3 | 19980528 | 1 | 16.99 | 1998-05-28 | 1998-05-01 | 1997-01-02 | 511 days | 511.0 | NaN |
| 9 | 4 | 19970101 | 2 | 29.33 | 1997-01-01 | 1997-01-01 | 1997-01-01 | 0 days | 0.0 | NaN |
如果用户仅消费了一次,留存率应该是0。另外一方面,如果用户第一天内消费了多次,但是往后没有消费,也算作留存率0。
pivoted_retention=user_purchase_retention.pivot_table(index='user_id',columns='date_diff_bin',values='order_amount',aggfunc=sum,dropna=False)
pivoted_retention.head(10)
| date_diff_bin | (0, 3] | (3, 7] | (7, 15] | (15, 30] | (30, 60] | (60, 90] | (90, 180] | (180, 365] |
|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||
| 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | NaN | NaN | NaN | NaN | NaN | 40.3 | NaN | 78.41 |
| 4 | NaN | NaN | NaN | 29.73 | NaN | NaN | NaN | 41.44 |
| 5 | NaN | NaN | 13.97 | NaN | 38.90 | NaN | 110.40 | 155.54 |
| 6 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 7 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 97.43 |
| 8 | NaN | NaN | NaN | NaN | 13.97 | NaN | 45.29 | 104.17 |
| 9 | NaN | NaN | NaN | NaN | NaN | NaN | 30.33 | NaN |
| 10 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
pivot_table数据透视,获得的结果是用户在第一次消费之后,在后续各时间段内的消费总额。
pivoted_retention.mean()
date_diff_bin
(0, 3] 35.905798
(3, 7] 36.385121
(7, 15] 42.669895
(15, 30] 45.964649
(30, 60] 50.215070
(60, 90] 48.975277
(90, 180] 67.223297
(180, 365] 91.960059
dtype: float64
计算一下用户在后续各时间段的平均消费额,这里只统计有消费的平均值。虽然后面时间段的金额高,但是它的时间范围也宽广。从平均效果看,用户第一次消费后的0~3天内,更可能消费更多。
pivoted_retention_trans=pivoted_retention.fillna(0).applymap(lambda x:1 if x>0 else 0)
pivoted_retention_trans.head()
| date_diff_bin | (0, 3] | (3, 7] | (7, 15] | (15, 30] | (30, 60] | (60, 90] | (90, 180] | (180, 365] |
|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| 4 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 5 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 |
(pivoted_retention_trans.sum()/pivoted_retention_trans.count()).plot.bar()

只有2.5%的用户在第一次消费的次日至3天内有过消费,3%的用户在3~7天内有过消费。数字并不好看,CD购买确实不是高频消费行为。时间范围放宽后数字好看了不少,有20%的用户在第一次消费后的三个月到半年之间有过购买,27%的用户在半年后至1年内有过购买。从运营角度看,CD机营销在教育新用户的同时,应该注重用户忠诚度的培养,放长线掉大鱼,在一定时间内召回用户购买。
5.运营策略
def diff(group):
d=group.date_diff.shift(-1)-group.date_diff
return d
last_diff=user_purchase_retention.groupby('user_id').apply(diff)
last_diff.head(10)
user_id
1 0 NaN
2 1 0.0
2 NaN
3 3 87.0
4 3.0
5 227.0
6 10.0
7 184.0
8 NaN
4 9 17.0
Name: date_diff, dtype: float64
last_diff.describe()
count 46089.000000
mean 68.973768
std 91.033032
min 0.000000
25% 10.000000
50% 31.000000
75% 89.000000
max 533.000000
Name: date_diff, dtype: float64
计算一个用户的消费时间和上一次消费时间差,可知,平均消费间隔为69天,因此,想要召回用户,在60天左右的消费间隔是比较好的。
last_diff.hist(bins=20)
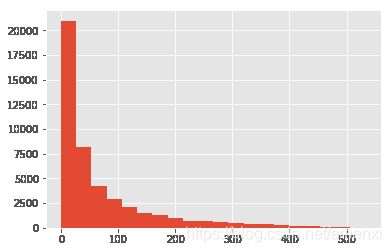
上图为典型的长尾分布,大部分用户的消费间隔确实比较短。不妨将时间召回点设为消费后立即赠送优惠券,消费后10天询问用户CD怎么样,消费后30天提醒优惠券到期,消费后60天短信推送。