kudu on impala 基本用法。
好久没用kudu了 突然别的项目组开始用kudu,问各种问题,实在招架不住。。。。
于是自我学习一波。
https://impala.apache.org/docs/build/impala-2.12.pdf
1.尽量考虑用kudu自己的api来增删改查,而不是通过impala的jdbc接口去做些事。

这个就是说我们可以直接通过kudumaster的地址获取kudusession来dml操作
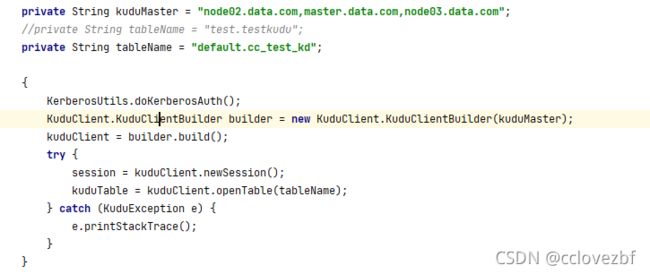
还可以通过impala jdbc的方式连接后直接crud。
官网推荐kudu方式。
2.dml
-- Single partition. Only for Impala 2.10 and higher. -
--仅供impala2.10及以上版本参考。
- Only suitable for small lookup tables. 这种只适合小表,不分区。
CREATE TABLE kudu_no_partition_by_clause ( id bigint PRIMARY KEY, s STRING, b BOOLEAN ) STORED AS KUDU;
-- Single-column primary key. 一列分区。
CREATE TABLE kudu_t1 (id BIGINT PRIMARY key, s STRING, b BOOLEAN) PARTITION BY HASH (id) PARTITIONS 20 STORED AS KUDU;
备注 像这种主键唯一,hash分区一般就会选择主键,因为主键已经满足了hash(主键)尽可能分散的这个要求
-- Multi-column primary key. 多列分区
CREATE TABLE kudu_t2 (id BIGINT, s STRING, b BOOLEAN, PRIMARY KEY (id,s)) PARTITION BY HASH (s) PARTITIONS 30 STORED AS KUDU;
备注,你看这里 主键是id和s 联合起来的。但是hash分区只是根据s。
那么根据hash(s)分区的目的是啥呢?为啥不直接hash(id,s)。
因为s肯定是有重复的数据的,其实可以这么理解。该表为一个顾客每天登陆总数表。顾客id+每天s登陆次数唯一。但是顾客每天都会登录。 这个时候我们hash(s)=每一天的数据,那么我门查询每天的数据时,所查找的tablet server 就是在一起。 同理 如果我们采用hash(id),那么我们在查询单个顾客每天的登录次数的时候,速度就会比 hash(s)和hash(id,s)快。
所以这里 hash()分区的值是很重要的,直接影响你以后的查询效果,个人认为 hash(id,name.socre)这种多字段分区是不可取的。
-- Meaningful primary key column is good for range partitioning
--选好主键很关键!!!
CREATE TABLE kudu_t3 (
id BIGINT,
year INT,
s STRING,
b BOOLEAN,
PRIMARY KEY (id,year)
)
PARTITION BY HASH (id) PARTITIONS 20,
RANGE (year) (
PARTITION 1980 <=VALUES < 1990,
PARTITION 1990 <=VALUES < 2000,
PARTITION VALUE = 2001,
PARTITION 2001
) STORED AS KUDU;
注意。这里分区细节。
1.这里是联合分区 即hash和range
2.这里range里有范围和固定值,其中范围用values 固定值用value
3.这里说下 这种联合分区的好处, 既保证了插入效率 又保证了读取速度,比较中庸
建外部表 本质就是表数据在kudu里 但是显示在impala
Here is an example of creating an external Kudu table:
-- Inherits column definitions from original table. -- For tables created through Impala, the kudu.table_name property -- comes from DESCRIBE FORMATTED output from the original table.
CREATE EXTERNAL TABLE external_t1 STORED AS KUDU TBLPROPERTIES ('kudu.table_name'='kudu_tbl_created_via_api');
具体操作
1.kudu api建了个default.cc_test_kd_2表,然后通过insert api插入数据 ,此时在impala上是查不到该表的,该表都查不到,数据更不用说了。但是kudu api还是可以查到
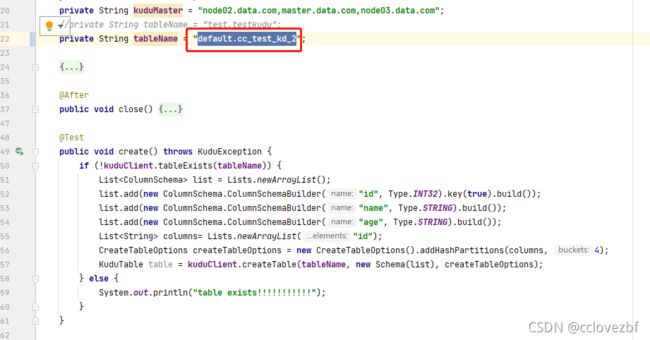
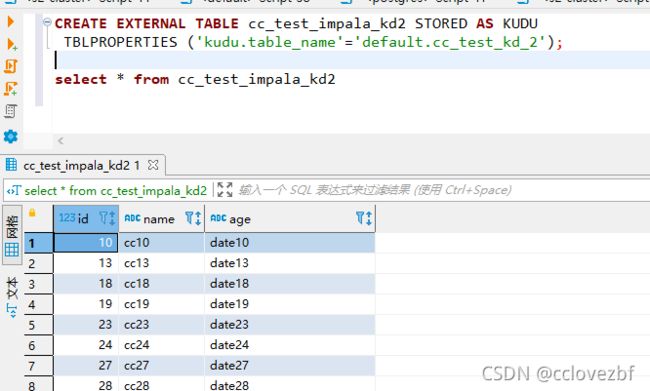
2.在impala上操作 CREATE EXTERNAL TABLE cc_test_impala_kd2 STORED AS KUDU
TBLPROPERTIES ('kudu.table_name'='default.cc_test_kd_2');
3.此时我们可以在impala上查到该数据
4. 同样 我们在impala删除该表 数据还是会保留在kudu里
CTAS建表语法
-- The CTAS statement defines the primary key and partitioning scheme. -- The rest of the column definitions are derived from the select list.
CREATE TABLE ctas_t1 PRIMARY KEY (id) PARTITION BY HASH (id) PARTITIONS 10 STORED AS KUDU AS SELECT id, s FROM kudu_t1
The following CREATE TABLE clauses are not supported for Kudu tables:
• PARTITIONED BY (Kudu tables use the clause PARTITION BY instead)
• LOCATION
• ROWFORMAT
• CACHED IN | UNCACHED
• WITH SERDEPROPERTIES
这种建表 就是说我们指定了 主键 分区 其余的键不需要我们指定,默认会继承
create table ctas_impala_kd primary key(name )
partition by hash(name ) partitions 4
stored as kudu
as select name ,id ,age from cc_test_impala_kd2
--注意 name放最前,你要创建的主键字段放最前面

其中 其余的属性 例如压缩 编码 默认值基本都不用。。。后面学到了再说。
关于kudu的分区知道多少呢?hash range ?这只是最基本的,实际上我觉得很多要学的。
PARTITION BY HASH
-- Apply hash function to 1 primary key column.
create table hash_t1 (x bigint, y bigint, s string, primary key (x,y))
partition by hash (x) partitions 10
stored as kudu;
-- Apply hash function to a different primary key column.
create table hash_t2 (x bigint, y bigint, s string, primary key (x,y))
partition by hash (y) partitions 10
stored as kudu;
-- Apply hash function to both primary key columns.
-- In this case, the total number of partitions is 10.
create table hash_t3 (x bigint, y bigint, s string, primary key (x,y))
partition by hash (x,y) partitions 10
stored as kudu;
-- When the column list is omitted, apply hash function to all primary key
columns.
create table hash_t4 (x bigint, y bigint, s string, primary key (x,y))
partition by hash partitions 10
stored as kudu;
备注-如果不指定hash(xxx,yyy)默认就是按照主键,如上就是hash(x,y)
-- Hash the X values independently from the Y values.
-- In this case, the total number of partitions is 10 x 20.
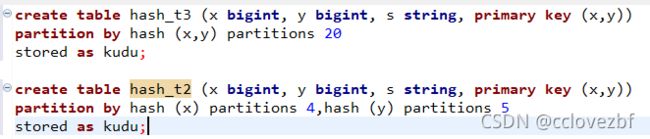
create table hash_t5 (x bigint, y bigint, s string, primary key (x,y))
partition by hash (x) partitions 10, hash (y) partitions 20
stored as kudu;
--思考下 这种做的目的是啥。。。。
hash (x) partitions 10, hash (y) partitions 20 对比 hash(x,y)parittions 200
比如我经常要通过x,y去查询字段,那么选择哪一种呢?
如果是随机系列的比如 202021 cclovezbf 淘宝购买了哪些东西
如果是前者 要经过两次hash运算找到tablet 的具体数据快,而后者只需要一次hash运算找到该tablet,然后再确定具体数据块,个人感觉是差不多的或者前者优于后者。
但是如果我这种时候有需要查询cclovezbf总共买了多少商品呢?此时前者通过计算得到了10个tablet,在10个tablet去查找数据,而后者还是需要在200个tablet去查找。。。明显前者优于后者。
如果我选择插入呢?比如我插入202001的数据,谁的性能更好呢? 前者直接插入到10个tablet,后者插入到200个tablet。实话说我觉的前者差于后者。,但是。。感觉10个tablet并发插入也不算很差了。
总的来说感觉前者的写法更好,那有没有什么坏处呢?。。暂时没想到以后来填坑。。!!!
PARTITION BY RANGE
-- Create partitions that cover every possible value of X.
-- Ranges that span multiple values use the keyword VALUES between
-- a pair of < and <= comparisons.
create table range_t1 (x bigint, s string, s2 string, primary key (x, s))
partition by range (x)
(
partition 0 <= values <= 49, partition 50 <= values <= 100,
partition values < 0, partition 100 < values
)
stored as kudu;
-- Create partitions that cover some possible values of X.
-- Values outside the covered range(s) are rejected. 不在range范围内的插入无效。不会报错
-- New range partitions can be added through ALTER TABLE.
增加分区
ALTER TABLE sales_by_year ADD RANGE PARTITION VALUE = 2017;
删除分区
ALTER TABLE sales_by_year DROP RANGE PARTITION VALUE = 2012;create table range_t2 (x bigint, s string, s2 string, primary key (x, s))
partition by range (x)
(
partition 0 <= values <= 49, partition 50 <= values <= 100
)
stored as kudu;
-- A range can also specify a single specific value, using the keyword VALUE
-- with an = comparison.
create table range_t3 (x bigint, s string, s2 string, primary key (x, s))
partition by range (s)
(
partition value = 'Yes', partition value = 'No', partition value =
'Maybe'
)
stored as kudu;
-- Using multiple columns in the RANGE clause and tuples inside the
partition spec
-- only works for partitions specified with the VALUE= syntax.
create table range_t4 (x bigint, s string, s2 string, primary key (x, s))
partition by range (x,s)
(
partition value = (0,'zero'), partition value = (1,'one'), partition
value = (2,'two')
)
stored as kudu;combining both HASH and RANGE syntax for the PARTITION BY
-- Values from each range partition are hashed into 10 associated buckets.
-- Total number of partitions in this case is 10 x 2.
create table combined_t1 (x bigint, s string, s2 string, primary key (x, s))
partition by hash (x) partitions 10, range (x)
(
partition 0 <= values <= 49, partition 50 <= values <= 100
)
stored as kudu;
-- The hash partitioning and range partitioning can apply to different
columns.
-- But all the columns used in either partitioning scheme must be from the
primary key.
create table combined_t2 (x bigint, s string, s2 string, primary key (x, s))
partition by hash (s) partitions 10, range (x)
(
partition 0 <= values <= 49, partition 50 <= values <= 100
)
stored as kudu;
这里又有问题了如果一个顾客购买商品表。字段如下 日期date 顾客 cid 商品pid ....
毫无疑问这个数据是很大的,那么我如何分区呢?
1.hash(date) 20
2.hash(cid) 20
3.hash(cid,date) partitions 20
4.hash(cid) partitions 4 hash(date)partitions 5
5.hash(cid) partitions4, range(date) partition value=20200101,partition value==20200102
6.range(date) partition value=20200101,partition value==20200102
先说
1.日期的hash值,这样能够把相同日期的数据放到一个tabletserver里,但是。。初期天数比较少的时候,
每天的数据hash值都一样,还是会插入到一个tablet server上,压力大
前期 20210101 和20200102的hash值最后都分配到同一个数据里,会导致分配不均,部分机器压力过大。
但是 查询条件是 where date=xxx 速度还行。。
强烈不推荐。。
2.根据cid分组,因为cid很多 hash值会尽量平均 数据分布均匀,每台机器负载平均, 大批量数据插入的 机器压力小,插入速度块。
查询 where cid=cc 的时候 速度还行
查询 where date=202111效果差
3.根据hash(cid,date)分区,数据均匀分布,插入性能好
联合查询 where date=202110 and cid=cclovezbf 速度快。
where date=202110效果差。 where cid=cclovezbf 速度慢
4.也是均匀分区,即使插入同一天的数据,但是因为cid hash不同,还是会分布到不同tablet server上,所以插入速度块
查询 where cid=cc 或者where date= 202111 速度中
查询where cid=cc and date =202111 速度快 与3一样
借用kudu官网的话。

5.与4相比差别在于 hash(date) 还是range(date)
区别在哪?
1.如果date的天数较少 有一定的分布不归 但是由于都cid hash了,所以数据不均的影响较小,但是此时hash date 差于 range date
如果date 天数较多,hash均匀,但是 rang如何分区?我hash可以直接parittions 20
按天分区 每天alter table add range partition 比较麻烦。range需要手动维护,
查询的话不用 where date =20210101 range 优于 hash,但是维护稍微麻烦点。(可以使用脚本建)
如果按月分区 查询 where date=202101 效率差不多把。一个是从20个parititions去找 一个是从多少个range去找,一般差不了多少。
6.适用于经常对date进行查询的表,比如要算 每天销售额 每天顾客数量。
其实综合来说 还是5>4>6>123 但是你有一些特殊需求,可以自己分区。。。
以上都是个人认识 未经过认证。。勿喷。

就是说kudu可以增删改查,和基于hdfs的hive相比功能强大还能实时读取
但是不支持load data,truncate table ,insert overwrite。
 kudu和impala的结合非常适合于那些对查询比较重要的。如果数据是持续不断的 每一小批,或者那种部分更新的,就不是特别适合。随着数据的到达,基于hdfs的表需要大量的资源去替换和查找原始数据文件。
kudu和impala的结合非常适合于那些对查询比较重要的。如果数据是持续不断的 每一小批,或者那种部分更新的,就不是特别适合。随着数据的到达,基于hdfs的表需要大量的资源去替换和查找原始数据文件。
impala对于查看kudu表也很好,修改和删除也不错, java api也可以搞这些事。。
这种感觉没啥营养 不想翻译了。

对于基于hdfs的表来说,我们一般要考虑集群有多少个dn,在集群中查询的适合 hdfs数据文件有多大,有多少被读到,同时每个dn的工作效率和网络交互 最终组成了查询结果
对于kudu表来说有点不一样
1.存储模式不一样 hbase hive都是存在hdfs上的 但是 kudu就是存在服务器上
2.kudu 必须分区,对于分区数据 每个分区的数据是单独的
3.尽量将dn和tablet server放在同一机器上 不必须。
4.kudu表的副本数为奇数。
Impala DDL Enhancements for Kudu Tables

1.kudu表首次向impala引入了主键的概念,主键一般由1-n列构成,在查询的时候会被用到多列构建的主键,这个值必须唯一,并且不能有null,并且联合主键不能被更新比如 我date=202101 id=cclovezbf 你就不能把我id改为zbflovecc 。同时分区列必须来源于主键
主键有物理和逻辑考虑
1.物理:因为主键唯一,通常将主键的值映射到特定的tablet, 怎么理解这句话?
因为分区列来源于主键,知道了主键 其实也就知道了分区。
2.逻辑:因为主键唯一约束存在,所以insert失败了,我还可以继续insert直至成功,对我没有影响,即使我insert了100次才成功(insert重复主键,不报错),对于要更新的数据,通过upsert也可以一直更新,同时还不用创建新的副本
Kudu-Specific Column Attributes for CREATE TABLE
PRIMARY KEY
| [NOT] NULL
| ENCODING codec
| COMPRESSION algorithm
| DEFAULT constant_expression
| BLOCK_SIZE number
PRIMARY KEY Attribute对于列来说可以加如下属性。
可以一列或者多列组成
主键默认用于自然排序
每行的主键唯一
主键不能为空,所以主键列默认not null
主键必须写在最前面 就是create table (column1 column2 c3 c4 ) 你可以 PRIMARY KEY(c1),或PRIMARY KEY(c1,c2)但是不要 PRIMARY KEY(c2)
两种写法primarykey 都有点类似mysql主键
CREATE TABLE pk_inline
(
col1 BIGINT PRIMARY KEY,
col2 STRING,
col3 BOOLEAN
) PARTITION BY HASH(col1) PARTITIONS 2 STORED AS KUDU;
CREATE TABLE pk_at_end
(
col1 BIGINT,
col2 STRING,
col3 BOOLEAN,
PRIMARY KEY (col1)
) PARTITION BY HASH(col1) PARTITIONS 2 STORED AS KUDU;
--两列作为联合主键
CREATE TABLE pk_multiple_columns
(
col1 BIGINT,
col2 STRING,
col3 BOOLEAN,
PRIMARY KEY (col1, col2)
) PARTITION BY HASH(col2) PARTITIONS 2 STORED AS KUDU;查看建表语句
SHOW CREATE TABLE inline_pk_rewritten;主键不能改!
主键不能改!
主键不能改!

如果联合主键太多,有56个了 会降低写入性能。
因此 主键的选择:经常被使用的,最具有代表性的,非空列。 例如身份证 手机号码 qq号。。。
如果一个列的值经常被改变那么就不要做逐渐,用个 not null 就好了。
如果有一列的值不正确或者过期了(说的应该是主键不对)。删除这列,并且插入一列正确的列(有个正确的主键)
NULL | NOT NULL Attribute
CREATE TABLE required_columns
(
id BIGINT PRIMARY KEY,
latitude DOUBLE NOT NULL,
longitude DOUBLE NOT NULL,
place_name STRING,
altitude DOUBLE,
population BIGINT
) PARTITION BY HASH(id) PARTITIONS 2 STORED AS KUDU;
在性能优化过程中,Kudu可以利用不允许空值跳过某些检查每个输入行,加快查询和联接操作。因此,在适当时指定NOTNULL约束。
除了主键 其余列都是默认null即默认可以为空,因为默认的 所以可以忽略
由于主键列不能包含任何NULL值,因此主键不需要NOTNULL子句,也可以加 没卵用
DEFAULT Attribute
CREATE TABLE default_vals
(
id BIGINT PRIMARY KEY,
name STRING NOT NULL DEFAULT 'unknown',
address STRING DEFAULT upper('no fixed address'),
age INT DEFAULT -1,
earthling BOOLEAN DEFAULT TRUE,
planet_of_origin STRING DEFAULT 'Earth',
optional_col STRING DEFAULT NULL
) PARTITION BY HASH(id) PARTITIONS 2 STORED AS KUDU;
default 默认值必须是常量constant expression 例如 文字值、算术和字符串操作的组合。它不能包含对列或列的引用,非确定性函数调用。这里说的有点笼统,其实就是不能有sysdate。。。

当设计一个全新的schema的时候,推荐使用default null作为占位符(默认的),因为你不知道接下来的数据是什么样的,因为null能被存储的非常有效,并且在查询is null 和is not null的时候是非常快的。
ENCODING Attribute
CREATE TABLE various_encodings
(
id BIGINT PRIMARY KEY,
c1 BIGINT ENCODING PLAIN_ENCODING,
c2 BIGINT ENCODING AUTO_ENCODING,
| Using Impala to Query Kudu Tables | 736
c3 TINYINT ENCODING BIT_SHUFFLE,
c4 DOUBLE ENCODING BIT_SHUFFLE,
c5 BOOLEAN ENCODING RLE,
c6 STRING ENCODING DICT_ENCODING,
c7 STRING ENCODING PREFIX_ENCODING
) PARTITION BY HASH(id) PARTITIONS 2 STORED AS KUDU;
-- Some columns are omitted from the output for readability.
describe various_encodings;
+------+---------+-------------+----------+-----------------+
| name | type | primary_key | nullable | encoding |
+------+---------+-------------+----------+-----------------+
| id | bigint | true | false | AUTO_ENCODING |
| c1 | bigint | false | true | PLAIN_ENCODING |
| c2 | bigint | false | true | AUTO_ENCODING |
| c3 | tinyint | false | true | BIT_SHUFFLE |
| c4 | double | false | true | BIT_SHUFFLE |
| c5 | boolean | false | true | RLE |
| c6 | string | false | true | DICT_ENCODING |
| c7 | string | false | true | PREFIX_ENCODING |
+------+---------+-------------+----------+-----------------+
每一列都可以自由编码。
• AUTO_ENCODING: use the default encoding based on the column type, which are bitshuffle for the numeric type columns and dictionary for the string type columns.
• PLAIN_ENCODING: leave the value in its original binary format.
• RLE: compress repeated values (when sorted in primary key order) by including a count.
• DICT_ENCODING: when the number of different string values is low, replace the original string with a numeric ID.
• BIT_SHUFFLE: rearrange the bits of the values to efficiently compress sequences of values that are identical or vary only slightly based on primary key order. The resulting encoded data is also compressed with LZ4.
• PREFIX_ENCODING: compress common prefixes in string values; mainly for use internally within Kudu.
总结下 默认都是AUTO_ENCODING 其中数字类型的默认BIT_SHUFFLE,string类型的DICT_ENCODING
那么这几种的编码各有什么用呢?优势和劣势?
AUTO_ENCODING 省心省力
PLAIN_ENCODING 保持数据原本的二进制格式
RLE 好像是通过xx来压缩重复的值,当通过主键排序的时候。。不太理解,感觉好像是有些数据有很多重复的时候使用这个好点,比如人员信息表, 身高一栏?
DICT_ENCODING 当字符串数值重复的较少的时候,用数字id替换? 例如,身份证号码?基本不一样,或者账号id 物流id?
BIT_SHUFFLE 根据主键顺序重新排列值的位,以有效压缩相同或略有不同的值序列。得到的编码数据也用LZ4压缩
PREFIX_ENCODING 压缩字符串值中的常用前缀;主要用于Kudu内部。 比如 有的前缀是地名hb_cc gd_cc hn_cc?
仅供学习,吹牛比用的。平常用个auto 就够了。
BLOCK_SIZE Attribute
要看kudu官网等会
Apache Kudu - Introducing Apache Kudu https://kudu.apache.org/docs/index.htmlPartitioning for Kudu Tables
https://kudu.apache.org/docs/index.htmlPartitioning for Kudu Tables
Kudu tables use special mechanisms to distribute data among the underlying tablet servers. Although we refer to such
tables as partitioned tables, they are distinguished from traditional Impala partitioned tables by use of different clauses
on the CREATE TABLE statement. Kudu tables use PARTITION BY, HASH, RANGE, and range specification
clauses rather than the PARTITIONED BY clause for HDFS-backed tables, which specifies only a column name and
creates a new partition for each different value.就是说kudu和hdfs数据不一样,本质是服务器之间的数据分发。
Hash Partitioning
Hash partitioning is the simplest type of partitioning for Kudu tables. For hash-partitioned Kudu tables, inserted
rows are divided up between a fixed number of “buckets” by applying a hash function to the values of the columns
specified in the HASH clause. Hashing ensures that rows with similar values are evenly distributed, instead of
clumping together all in the same bucket. Spreading new rows across the buckets this way lets insertion operations
work in parallel across multiple tablet servers. Separating the hashed values can impose additional overhead on
queries, where queries with range-based predicates might have to read multiple tablets to retrieve all the relevant
values.hash分区是最简单的分区。还是之前的话,hash尽可能分散,比如cclovezbf 和cclovezbf1两个值很接近但是hash后的值完全不一样。分布到各个tablet server区间,
插入快,但是如果是范围查询(like < >)的话就需要跨多个tablet server了
-- 1M rows with 50 hash partitions = approximately 20,000 rows per partition.
100w/50= 2w一分区,如果1000w呢? 那就要500个分区
-- The values in each partition are not sequential, but rather based on a hash function.
-- Rows 1, 99999, and 123456 might be in the same partition.
分区内的数据不是连续!是基于hash的
例如 分区column列的1 99999 123456可能是在同一个分区
CREATE TABLE million_rows (id string primary key, s string)
PARTITION BY HASH(id) PARTITIONS 50
STORED AS KUDU;
-- Because the ID values are unique, we expect the rows to be roughly
-- evenly distributed between the buckets in the destination table.
INSERT INTO million_rows SELECT * FROM billion_rows ORDER BY id LIMIT 1e6;
Note: The largest number of buckets that you can create with a PARTITIONS clause varies depending on the number of tablet servers in the cluster, while the smallest is 2. For simplicity, some of the simple CREATE TABLE statements throughout this section use PARTITIONS 2 to illustrate the minimum requirements for a Kudu table. For large tables, prefer to use roughly 10 partitions per server in the cluster.
最小是2 大点的表建议每个server 10个起步,我们集群差不多7-8个server 按照之前说的就是70个partition也就是140w数据。差不多了
Range Partitioning
Range partitioning lets you specify partitioning precisely, based on single values or ranges of values within one or more columns. You add one or more RANGE clauses to the CREATE TABLE statement, following the PARTITION BY clause. Range-partitioned Kudu tables use one or more range clauses, which include a combination of constant expressions, VALUE or VALUES keywords, and comparison operators. (This syntax replaces the SPLIT ROWS clause used with early Kudu versions.)
通过value 和values 来进行partition by range(column)( partition value=xxx)分区
-- 50 buckets, all for IDs beginning with a lowercase letter.
-- Having only a single range enforces the allowed range of value
-- but does not add any extra parallelism.
create table million_rows_one_range (id string primary key, s string)
partition by hash(id) partitions 50,
range (partition 'a' <= values < '{')
stored as kudu;
上面的例子说range就分了一个区和sb一样不要这样干
-- 50 buckets for IDs beginning with a lowercase letter
-- plus 50 buckets for IDs beginning with an uppercase letter.
-- Total number of buckets = number in the PARTITIONS clause x number of
ranges.
-- We are still enforcing constraints on the primary key values
-- allowed in the table, and the 2 ranges provide better parallelism
-- as rows are inserted or the table is scanned.
create table million_rows_two_ranges (id string primary key, s string)
partition by hash(id) partitions 50,
range (partition 'a' <= values < '{', partition 'A' <= values < '[')
stored as kudu;
range两个分区 有较好的并行度
-- Same as previous table, with an extra range covering the single key value
'00000'.
create table million_rows_three_ranges (id string primary key, s string)
partition by hash(id) partitions 50,
range (partition 'a' <= values < '{', partition 'A' <= values < '[',
partition value = '00000')
stored as kudu;
-- The range partitioning can be displayed with a SHOW command in impalashell.
show range partitions million_rows_three_ranges;
+---------------------+
| RANGE (id) |
+---------------------+
| VALUE = "00000" |
| "A" <= VALUES < "[" |
| "a" <= VALUES < "{" |
+---------------------+
Note:
When defining ranges, be careful to avoid “fencepost errors” where values at the extreme ends might be included or omitted by accident. For example, in the tables defined in the preceding code listings, the range "a" <= VALUES< "{" ensures that any values starting with z, such as za or zzz or zzz-ZZZ, are all included, by using a less-than operator for the smallest value after all the values starting with z.
For range-partitioned Kudu tables, an appropriate range must exist before a data value can be created in the table.
Any INSERT, UPDATE, or UPSERT statements fail if they try to create column values that fall outside the specified ranges. The error checking for ranges is performed on the Kudu side; Impala passes the specified range information to Kudu, and passes back any error or warning if the ranges are not valid. (A nonsensical range specification causes an error for a DDL statement, but only a warning for a DML statement.)
fencepost errors 翻译篱笆桩错误是啥呢?思考了下 就是范围分区貌似不能动态分区,比如我要按天数分区,天数一直增长 我不可能一直无限制增长到2099-12-31.结果发现理解错了。。
意思是就是范围分区 特别是 <>这种 "a" <= VALUES< "{ “这种分区才是正确的,如果是"a" <= VALUES<= "z" 那么zzz zzz-ZZ可能就被排除了