Hadoop+Spark + Hive高可用集群部署
Hadoop+Spark+Hive高可用分布式集群安装
集群规划
| 节点IP | 节点别名 | zookeeper节点 | JournalNode节点 | NodeManager节点 | DataNode节点 | zkfc节点 | NameNode节点 | ResourceManager节点 |
|---|---|---|---|---|---|---|---|---|
| 192.168.99.61 | spark01 | zookeeper | JournalNode | NodeManager | DataNode | DFSZKFailoverController | NameNode | |
| 192.168.88.221 | spark02 | zookeeper | JournalNode | NodeManager | DataNode | DFSZKFailoverController | NameNode | ResourceManager |
| 192.168.99.98 | spark03 | zookeeper | JournalNode | NodeManager | DataNode | ResourceManager |
一 Hadoop的完全分布式集群安装
1、环境准备
(1)服务器三台
192.168.99.61,192.168.88.221,192.168.88.221
(2)域名解析及免密
配置hosts文件域名解析及各节点互相免密
192.168.99.61 hadoop01 spark01 zookeeper01 hive01
192.168.88.221 hadoop02 spark02 zookeeper02 metastore01
192.168.99.98 hadoop03 spark03 zookeeper03 mysql01
(3)路径
安装路径:/usr/local/spark
java-home:/usr/java/jdk1.8.0_162(rpm包安装默认路径)
(4)软件版本
zookeeper:zookeeper-3.4.14.tar.gz
hadoop:hadoop-2.7.0.tar.gz
jdk:jdk-8u162-linux-x64.rpm
scala:scala-2.11.8.zip
spark:spark-2.2.0-bin-hadoop2.7.tgz
Hive:apache-hive-2.1.1-bin.tar.gz
mysql:
2、管理节点zookeeper的安装
三个几点都安装zookeeper,leader自动选举
安装目录:/usr/local/spark/zookeeper-3.4.14
安装过程:
(1)解压进目录
tar –xf zookeeper-3.4.14.tar.gz –C zookeeper-3.4.14.tar.gz
cd /usr/local/spark/zookeeper-3.4.14/conf/
cp zoo_sample.cfg zoo.cfg
(2)修改配置文件
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/spark/zookeeper-3.4.14/data/
dataLogDir=/usr/local/spark/zookeeper-3.4.14/logs/
clientPort=2181
server.1=zookeeper01:2888:3888
server.2=zookeeper02:2888:3888
server.3=zookeeper03:2888:3888
(3)创建数据存储目录及myid
mkdir –p /usr/local/spark/zookeeper-3.4.14/{data,logs}
在不同的节点输入不同的值给myid
[root@spark01 hadoop]# echo 1 > /usr/local/spark/zookeeper-3.4.14/data/myid
[root@spark02 hadoop]# echo 2 > /usr/local/spark/zookeeper-3.4.14/data/myid
[root@spark03 hadoop]# echo 3 > /usr/local/spark/zookeeper-3.4.14/data/myid
(4)其他节点的安装
安装过程步骤一致,只需要修改myid的值
(5)添加zookeeper集群启动的环境变量
在 /etc/profile
ZOOKEEPER_HOME=/usr/local/spark/zookeeper-3.4.14
PATH=PATH:ZOOKEEPER_HOME/bin
生效环境变量soruce /etc/profile
(6)zookeeper集群的启动
三个几点执行:zkServer.sh start
查看该节点zookeeper的状态:zkServer.sh status



由图可见,spark02的zookeeper是该集群的leader,其他节点为follwer,leader节点挂掉其他节点会选举一个成为下一个leader
3、hadoop集群安装
(1)解压进目录
tar –xf hadoop-2.7.0.tar.gz –C /usr/local/spark/
cd /usr/local/spark/hadoop-2.7.0/etc/hadoop
(2)修改文件hdfs、mapred、yarn的java环境变量
JAVA_HOME=/usr/java/jdk1.8.0_162
(3)修改文件core-site.xml
fs.defaultFS
hdfs://hadoop-cluster
hadoop.tmp.dir
file:/usr/local/spark/hadoop-2.7.0/data/tmp/
ha.zookeeper.quorum
zookeeper01:2181,zookeeper02:2181,zookeeper03:2181
(4)修改文件hdfs-site.xml
dfs.replication
2
dfs.nameservices
hadoop-cluster
dfs.namenode.name.dir
file:/usr/local/spark/hadoop-2.7.0/data/dfs/name
dfs.datanode.data.dir
file:/usr/local/spark/hadoop-2.7.0/data/dfs/data
dfs.ha.namenodes.hadoop-cluster
nn01,nn02
dfs.namenode.rpc-address.hadoop-cluster.nn01
hadoop01:8020
dfs.namenode.rpc-address.hadoop-cluster.nn02
hadoop02:8020
dfs.namenode.http-address.hadoop-cluster.nn01
hadoop01:50070
dfs.namenode.http-address.hadoop-cluster.nn02
hadoop02:50070
dfs.namenode.shared.edits.dir
qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/hadoop-cluster
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.journalnode.edits.dir
/usr/local/spark/hadoop-2.7.0/data/journalnode
dfs.permissions.enable
false
dfs.client.failover.proxy.provider.hadoop-cluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.automatic-failover.enabled
true
(5)修改文件mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
hadoop01:10020
mapreduce.jobhistory.webapp.address
hadoop01:19888
mapreduce.jobhistory.joblist.cache.size
20000
mapreduce.jobhistory.done-dir
$yarn.app.mapreduce.am.staging-dir/history/done
mapreduce.jobhistory.intermediate-done-dir
$yarn.app.mapreduce.am.staging-dir/history/done_intermediate
yarn.app.mapreduce.am.staging-dir
/usr/local/spark/hadoop-2.7.0/data/hadoop-yarn/staging
(6)修改文件yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
rmCluster
yarn.resourcemanager.ha.rm-ids
rm01,rm02
yarn.resourcemanager.hostname.rm01
hadoop02
yarn.resourcemanager.hostname.rm02
hadoop03
yarn.resourcemanager.zk-address
zookeeper01:2181,zookeeper02:2181,zookeeper03:2181
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
(7)修改文件slaves
[root@spark01 hadoop]# cat slaves
hadoop01
hadoop02
hadoop03
(8)其他节点部署
scp –r /usr/local/spark/hadoop-2.7.0/ spark02:/usr/local/spark/
scp –r /usr/local/spark/hadoop-2.7.0/ spark03:/usr/local/spark/
(9)各个节点hadoop的环境变量配置
HADOOP_HOME=/usr/local/spark/hadoop-2.7.0
HADOOP_CONF_DIR=$PATH:$HADOOP_HOME/etc/hadoop
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
生效环境变量soruce /etc/profile
(10)组件启动
[1] JournalNode启动
hadoop-daemon.sh start journalnode
[root@spark01 hadoop]# hadoop-daemon.sh start journalnode
[root@spark02 hadoop]# hadoop-daemon.sh start journalnode
[root@spark03 hadoop]# hadoop-daemon.sh start journalnode
[2] namenode启动
hadoop-daemon.sh start namenode
先启动spark01节点的nn01
[root@spark01 hadoop]# hadoop-daemon.sh start namenode
在spark02节点nn02上面同步spark01节点的nn01的元数据
[root@spark02 hadoop]# hdfs namenode -bootstrapStandby
启动spark02节点的nn02
[root@spark02 hadoop]# hadoop-daemon.sh start namenode
[3] datanode启动
在任意节点执行
hadoop-daemons.sh start datanode
[root@spark01 hadoop]# hadoop-daemons.sh start datanode
[4] 启动zkfc,修改NameNode状态
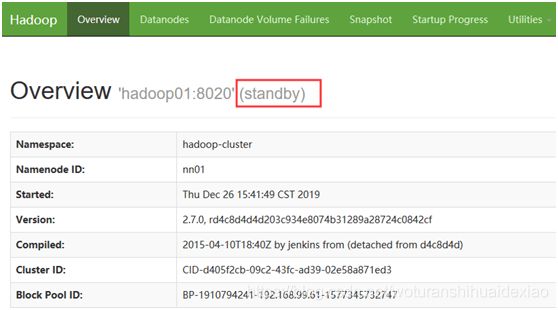
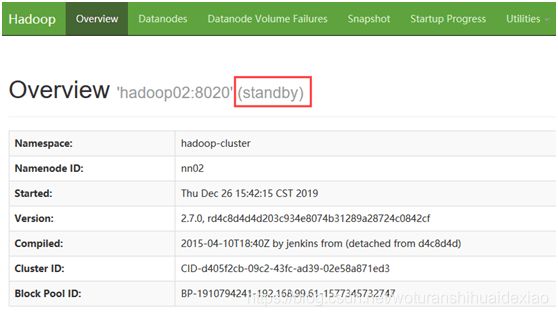
如上所示nodename状态为standby,需修改其中一个状态为Active。在spark01和 spark02节点启动组件zkfc,谁先启动谁为Active
hadoop-daemon.sh start zkfc
[root@spark01 hadoop]# hadoop-daemon.sh start zkfc
[root@spark02 hadoop]# hadoop-daemon.sh start zkfc
执行完如下图所示
![]()
![]()
强制修改节点状态
hdfs haadmin -transitionToActive nn01 --forcemanual
hdfs haadmin -transitionToStandby nn01 --forcemanual
[5] 自动切换namenode状态
需要初始化HA在Zookeeper中状态 hdfs zkfc –formatZK
[root@spark01 hadoop]# hdfs zkfc -formatZK
![]()
[6] yarn启动
在任意节点执行start-yarn.sh,生成nodemanager的jps进程
[root@spark01 ~]# start-yarn.sh
[7] resourcemanager启动
在spark02和spark03节点执行
yarn-daemon.sh start resourcemanager
[root@spark02 hadoop]# yarn-daemon.sh start resourcemanager
[root@spark02 hadoop]# yarn-daemon.sh start resourcemanager
查看状态

[8] 查看jps启动进程信息
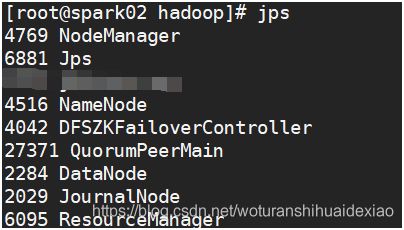
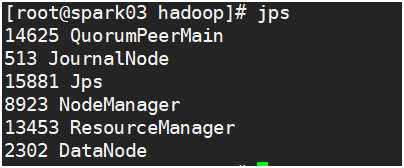
(11)namenode状态自动切换测试
现在是spark01上的namenode是avctive,kill掉改进程,看状态变换
![]()
![]()
kill掉saprk01节点的namenode
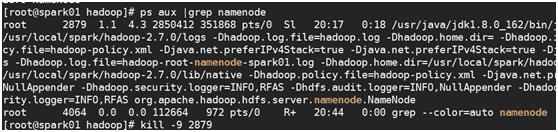
状态变化,hadoop01访问不了namenode,active切换到hadoop的namenode上面去了

二 spark高可用yarn分布式集群搭建
1、scala环境安装
(1)解压
unzip -d /usr/local/spark/ scala-2.11.8.zip
(2)配置环境变量
修改文件/etc/profile
SCALA_HOME=/usr/local/spark/scala-2.11.8
PATH=$PATH:$SCALA_HOME/bin
2、spark安装
(1)解压进目录
[root@spark01 ~]# tar -xf spark-2.2.0-bin-hadoop2.7.tgz -C /usr/local/spark/
[root@spark01 ~]# cd /usr/local/spark/spark-2.2.0-bin-hadoop2.7/conf/
(2)修改文件spark-env.sh
[root@spark01 conf]# cp spark-env.sh.template spark-env.sh
[root@spark01 conf]# vim spark-env.sh
#!/usr/bin/env bash
#指定默认master的ip或主机名
export SPARK_MASTER_HOST=spark01
#指定maaster提交任务的默认端口为7077
export SPARK_MASTER_PORT=7077
#指定masster节点的webui端口
export SPARK_MASTER_WEBUI_PORT=8080
#每个worker从节点能够支配的内存数
export SPARK_WORKER_MEMORY=1g
#允许Spark应用程序在计算机上使用的核心总数(默认值:所有可用核心)
export SPARK_WORKER_CORES=1
#每个worker从节点的实例(可选配置)
export SPARK_WORKER_INSTANCES=1
#指向包含Hadoop集群的(客户端)配置文件的目录,运行在Yarn上配置此项
export HADOOP_CONF_DIR=/usr/local/spark/hadoop-2.7.0/etc/hadoop
#指定整个集群状态是通过zookeeper来维护的,包括集群恢复
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=zookeeper01:2181,zookeeper02:2181,zookeeper03:2181
-Dspark.deploy.zookeeper.dir=/spark/data"
(3)修改slaves文件
[root@spark01 conf]# grep -Pv "^$|#" slaves
spark01
spark02
spark03
(4)其他节点部署
[root@spark01 conf]# scp spark-env.sh slaves spark02:/usr/local/spark/spark-2.2.0-bin-hadoop2.7/conf/
[root@spark01 conf]# scp spark-env.sh slaves spark03:/usr/local/spark/spark-2.2.0-bin-hadoop2.7/conf/
修改spark02的配置文件spark-env.sh,将地址改为spark02
export SPARK_MASTER_HOST=spark02
(5)配置环境变量
SPARK_HOME=/usr/local/spark/spark-2.2.0-bin-hadoop2.7
PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
[root@spark01 conf]# source /etc/profile
(6)节点启动
master节点启动
[root@spark01 spark-2.2.0-bin-hadoop2.7]# start-master.sh
[root@spark02 spark-2.2.0-bin-hadoop2.7]# start-master.sh
worker节点启动
指定节点启动woker
[root@spark01 spark-2.2.0-bin-hadoop2.7]# start-slave.sh spark://spark01:7077
[root@spark02 spark-2.2.0-bin-hadoop2.7]# start-slave.sh spark://spark01:7077
[root@spark03 spark-2.2.0-bin-hadoop2.7]# start-slave.sh spark://spark01:7077
或者启动所有的worker
[root@spark01 spark-2.2.0-bin-hadoop2.7]# start-slaves.sh
jps进程查看
[root@spark01 spark-2.2.0-bin-hadoop2.7]# jps
3445 NodeManager
3142 DFSZKFailoverController
16775 Jps
2811 JournalNode
3707 QuorumPeerMain
16495 Master
16299 Worker
16637 NameNode
3037 DataNode
[root@spark02 spark-2.2.0-bin-hadoop2.7]# jps
27556 Jps
2029 JournalNode
4769 NodeManager
4516 NameNode
2284 DataNode
4042 DFSZKFailoverController
27050 Master
27205 Worker
27371 QuorumPeerMain
6095 ResourceManager
[root@spark03 spark-2.2.0-bin-hadoop2.7]# jps
14625 QuorumPeerMain
513 JournalNode
7770 Worker
8923 NodeManager
9356 Jps
13453 ResourceManager
2302 DataNode
web页面查看状态


(7)高可用测试
kill掉spark01的master进程,worker节点注册到spark02的备master节点上
[root@spark01 spark-2.2.0-bin-hadoop2.7]# jps
3445 NodeManager
3142 DFSZKFailoverController
2811 JournalNode
3707 QuorumPeerMain
12795 Worker
13084 Jps
3037 DataNode
12687 Master
[root@spark01 spark-2.2.0-bin-hadoop2.7]# kill -9 12687

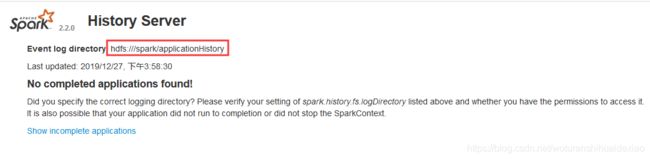
(8)配置历史服务器
修改配置文件spark-2.2.0-bin-hadoop2.7/confspark-defaults.conf
#开启记录事件日志的功能
spark.eventLog.enabled true
#日志优化选项,压缩日志
spark.eventLog.compress true
#设置事件日志存储的目录
spark.eventLog.dir hdfs://spark01:8020/spark/applicationHistory
#设置HistoryServer加载事件日志的位置
spark.history.fs.logDirectory hdfs://spark01:8020/spark/applicationHistory
创建hdfs目录
[root@spark01 conf]# hdfs dfs -mkdir -p /spark/applicationHistory
[root@spark01 conf]# hdfs dfs -ls /spark
Found 1 items
drwxr-xr-x - root supergroup 0 2019-12-27 15:13 /spark/applicationHistor
查看jps
[root@spark01 hadoop]# jps
3445 NodeManager
3142 DFSZKFailoverController
2811 JournalNode
3707 QuorumPeerMain
16299 Worker
19820 HistoryServer
20412 Jps
3037 DataNode
16637 NameNode
16495 Master
查看web界面
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lhwvey4L-1577676855798)
三 数据仓库 Hive的搭建
节点分配
192.168.99.61:hive,远程metastore服务端
192.168.88.221:客户端
192.168.99.98:mysql服务
1、mysql安装
(1)卸载mariadb下载安装包
[root@spark03 mysql]# rpm -qa |grep mariadb
[root@spark03 mysql]# yum remove -y mariadb-libs-5.5.52-1.el7.x86_64
[root@spark03 mysql]# ll
总用量 82644
-rw-r--r--. 1 root root 19730692 2月 13 2019 mysql-community-client-5.6.16-1.el7.x86_64.rpm
-rw-r--r--. 1 root root 252116 2月 13 2019 mysql-community-common-5.6.16-1.el7.x86_64.rpm
-rw-r--r--. 1 root root 3486556 2月 13 2019 mysql-community-devel-5.6.16-1.el7.x86_64.rpm
-rw-r--r--. 1 root root 2070536 2月 13 2019 mysql-community-libs-5.6.16-1.el7.x86_64.rpm
-rw-r--r--. 1 root root 59068576 2月 13 2019 mysql-community-server-5.6.16-1.el7.x86_64.rpm
(2)mysql安装
[root@spark03 mysql]# rpm -ivh mysql-community-common-5.6.16-1.el7.x86_64.rpm
[root@spark03 mysql]# rpm -ivh mysql-community-libs-5.6.16-1.el7.x86_64.rpm
[root@spark03 mysql]# rpm -ivh mysql-community-devel-5.6.16-1.el7.x86_64.rpm
[root@spark03 mysql]# rpm -ivh mysql-community-client-5.6.16-1.el7.x86_64.rpm
[root@spark03 mysql]# yum install -y mysql-community-server-5.6.16-1.el7.x86_64.rpm
[root@spark03 mysql]# systemctl start mysqld
[root@spark03 mysql]# mysqladmin -uroot password 123456
(3)授权
[root@spark03 mysql]# mysql -uroot -p123456
mysql> grant all privileges on *.* to root@'%' identified by '123456';
mysql> grant all privileges on *.* to root@'localhost' identified by '123456';
mysql> grant all privileges on *.* to root@'192.168.99.98' identified by '123456';
mysql> flush privlieges;
mysql> \q
Bye
2、Hive安装,远程Metastore服务端和客户端
(1)解压进目录
[root@spark01 ~]# tar -xf apache-hive-2.1.1-bin.tar.gz -C /usr/local/spark/
[root@spark01 ~]# cd /usr/local/spark/apache-hive-2.1.1-bin/conf
(2)配置环境变量
修改文件 /etc/profile
HIVE_HOME=/usr/local/spark/apache-hive-2.1.1-bin
PATH=$PATH:$HIVE_HOME/bin
生效环境变量
[root@spark01 ~]# source /etc/profile
(3)修改文件hive-env.sh
[root@spark01 conf]# cp hive-env.sh.template hive-env.sh
[root@spark01 conf]# vim hive-env.sh
HADOOP_HOME=/usr/local/spark/hadoop-2.7.0
HIVE_CONF_DIR=/usr/local/spark/apache-hive-2.1.1-bin/conf
(4)修改文件hive-log4j2.properties
[root@spark01 conf]# cp hive-log4j2.properties.template hive-log4j2.properties
[root@spark01 conf]# vim hive-log4j2.properties
修改下面的配置指定hive的日志路径
property.hive.log.dir = /usr/local/spark/apache-hive-2.1.1-bin/logs
创建Hive日志目录
[root@spark01 apache-hive-2.1.1-bin]# mkdir logs
(5)修改服务端配置文件
[root@spark01 conf]# cp hive-default.xml.template hive-site.xml
[root@spark01 conf]# echo > hive-site.xml
[root@spark01 conf]# vim hive-site.xml
hive.exec.scratchdir
/spark/hive/data
hive.scratch.dir.permission
733
hive.metastore.warehouse.dir
/spark/hive/warehouse
javax.jdo.option.ConnectionURL
jdbc:mysql://mysql01:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
123456
hive.cli.print.header
true
hive.cli.print.current.db
true
hive.exec.local.scratchdir
/usr/local/spark/apache-hive-2.1.1-bin/logs/HiveJobsLog
hive.downloaded.resources.dir
/usr/local/spark/apache-hive-2.1.1-bin/logs/ResourcesLog
hive.querylog.location
/usr/local/spark/apache-hive-2.1.1-bin/logs/HiveRunLog
hive.server2.logging.operation.log.location
/usr/local/spark/apache-hive-2.1.1-bin/logs/OpertitionLog
(6)修改客户端配置文件
先操作(1)-(5)然后修改hive-default.xml客户端配置配置文件
[root@spark02 conf]# cp hive-default.xml.template hive-site.xml
[root@spark02 conf]# echo > hive-site.xml
[root@spark02 conf]# vim hive-site.xml
?xml version="1.0" encoding="UTF-8" standalone="no"?>
hive.exec.scratchdir
/spark/hive/data
hive.scratch.dir.permission
733
hive.metastore.warehouse.dir
/spark/hive/warehouse
hive.metastore.uris
thrift://hive-client01:9083
hive.cli.print.header
true
hive.cli.print.current.db
true
(7)安装mysql连接插件
服务端
[root@spark01 ~]# unzip mysql-connector-java-5.1.46.zip
[root@spark01 ~]# cd mysql-connector-java-5.1.46/
[root@spark01 mysql-connector-java-5.1.46]# cp mysql-connector-java-5.1.46-bin.jar /usr/local/spark/apache-hive-2.1.1-bin/lib/
客户端
[root@spark02 mysql-connector-java-5.1.46]# scp mysql-connector-java-5.1.46-bin.jar spark02:/usr/local/spark/apache-hive-2.1.1-bin/lib/
(8)启动Hive
初始化服务端
[root@spark01 apache-hive-2.1.1-bin]# schematool -dbType mysql -initSchema
启动Hive
[root@spark01 apache-hive-2.1.1-bin]# hive --service metastore &>/usr/local/spark/apache-hive-2.1.1-bin/logs/\ /hive-start.log &
客户端连接Hive
[root@spark02 conf]# hive
四 调优
1、yarn调优
修改yarn-site.xml文件
yarn.scheduler.minimum-allocation-mb
750
yarn.scheduler.maximum-allocation-mb
4096
参考文档:
spark生态圈:https://blog.csdn.net/xiangxizhishi/article/details/77927564
hadoop、hbase、hive、spark分布式系统架构原理:https://blog.csdn.net/luanpeng825485697/article/details/80319552
Map-Reduce理解:https://blog.csdn.net/laobai1015/article/details/86590076
NN和2NN工作机制:https://www.cnblogs.com/linkworld/p/10941256.html
数据仓库的概念:https://www.cnblogs.com/frankdeng/p/9462754.html
Hive学习:https://www.cnblogs.com/frankdeng/p/9381934.html
hadoop完全集群搭建:https://www.cnblogs.com/frankdeng/p/9047698.html
spark高可用集群搭建:https://www.cnblogs.com/frankdeng/p/9294812.html