bigdata_kafka与streaming
一丶Kafka应用
鉴于kafka在实际使用时,绝大多数应用场景均为Producer和Consumer的API配合使用,故在此只介绍这两种API操作方法,其它的Connector和Streams还有admin可以视自身情况自行学习。
1.java版
-
实现步骤
-
创建maven项目(done)
-
加入kafka依赖
-
producer push message实现
-
consumer pull message实现
-
效果测试
-
-
加入依赖
org.apache.kafka
kafka-clients
2.0.0
org.slf4j
slf4j-simple
1.7.25
具体代码:
producer push message
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
importorg.apache.kafka.common.serialization.StringSerializer;
/**
* kafka测试工具类
* @author tianliang
*/
public class KafkaProducerUtil {
// 生产者抽象对象
public KafkaProducer producer;
// 传入brokerList,以hostname:port的方式,多个之间用,号隔开
public KafkaProducerUtil(String brokerList) {
Properties props = new Properties();
// 服务器ip:端口号,集群用逗号分隔
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
// key序列化指定类
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
// value序列化指定类
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
// 生产者对象
producer = new KafkaProducer(props);
}
public void close(){
this.producer.close();
}
public static void main(String[] args) {
// 初始化broker列表
String brokerList = "cluster1.hadoop:6667,cluster0.hadoop:6667";
String topic="TestKafka";
// 初始化生产者工具类
KafkaProducerUtil kafkaProducerUtil = new KafkaProducerUtil(brokerList);
// 向test_topic发送hello, kafka
kafkaProducerUtil.producer.send(new ProducerRecord(
topic, "hello,李英杰!"));
kafkaProducerUtil.close();
System.out.println("done!");
}
} comsumer push message实现
import java.util.Arrays;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
importorg.apache.kafka.common.serialization.StringDeserializer;
/**
* Kafka消费者工具类
*
* @author tianliang
*/
public class KafkaConsumerUtil {
// 消费者对象
public KafkaConsumer kafkaConsumer;
public KafkaConsumerUtil(String brokerList, String topic) {
Properties props = new Properties();
// 服务器ip:端口号,集群用逗号分隔
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
// 消费者指定组,名称可以随意,注意相同消费组中的消费者只能对同一个分区消费一次
props.put(ConsumerConfig.GROUP_ID_CONFIG, "TestTL");
// 是否启用自动提交offset,默认true
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
// 自动提交间隔时间1s
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 1000);
// key反序列化指定类
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
// value反序列化指定类,注意生产者与消费者要保持一致,否则解析出问题
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
// 消费者对象
kafkaConsumer = new KafkaConsumer<>(props);
//订阅Topic
kafkaConsumer.subscribe(Arrays.asList(topic));
}
public void close() {
kafkaConsumer.close();
}
public static void main(String[] args) {
// 初始化broker列表
String brokerList = "cluster0.hadoop:6667,cluster1.hadoop:6667";
String topic = "TestKafka";
// 初始化消费者工具类
KafkaConsumerUtil kafkaConsumerUtil = new KafkaConsumerUtil(brokerList,
topic);
boolean runnable=true;
while (runnable) {
ConsumerRecords records = kafkaConsumerUtil.kafkaConsumer
.poll(100);
for (ConsumerRecord record : records) {
System.out.printf("key = %s, offset = %d, value = %s", record.key(),record.offset(),
record.value());
System.out.println();
}
}
kafkaConsumerUtil.close();
System.out.println("done!");
}
} 2.scala版
producer push message实现
import org.apache.kafka.clients.producer.KafkaProducer
import java.util.Properties
import org.apache.kafka.clients.producer.ProducerRecord
import org.apache.kafka.clients.producer.ProducerConfig
import org.apache.kafka.common.serialization.StringSerializer
/**
* scala实现kafka producer工具类
*/
object KafkaProducerUtil {
//将生产者对象的获取封装到方法中
def getKafkaProducer(brokerList: String): KafkaProducer[String, String] = {
val properties = new Properties()
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList)
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer].getName) //key的序列化;
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer].getName) //value的序列化;
var producer4Kafka = new KafkaProducer[String, String](properties)
return producer4Kafka
}
def main(args: Array[String]): Unit = {
//定义broker list,topic
val brokersList = "sc-slave7:6667,sc-slave8:6667"
val topic:String = "TestKafka_scala"
//获取生产者对象
var producer4Kafka = KafkaProducerUtil.getKafkaProducer(brokersList)
//发送实际的message
producer4Kafka.send(new ProducerRecord(topic,"hello,李英杰!"))
//发送完成后关闭链接
producer4Kafka.close;
println("done!")
}
}consumer pull message实现
import org.apache.kafka.clients.producer.KafkaProducer
import java.util.Properties
import org.apache.kafka.clients.producer.ProducerRecord
import org.apache.kafka.clients.producer.ProducerConfig
import org.apache.kafka.common.serialization.StringSerializer
import org.apache.kafka.clients.consumer.KafkaConsumer
import java.util.Collections
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.common.serialization.StringDeserializer
/**
* scala实现kafka consumer工具类
*/
object KafkaConsumerUtil {
//将消费者对象的获取封装到方法中,注意groupid是必选项,此为与java api不相同之处
def getKafkaConsumer(brokerList: String, topic: String, consumerGroupId: String): KafkaConsumer[String, String] = {
val properties = new Properties()
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList)
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, classOf[StringDeserializer].getName) //key的序列化;
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, classOf[StringDeserializer].getName) //value的序列化;
properties.put(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId) //指定groupid
var consumer4Kafka = new KafkaConsumer[String, String](properties)
consumer4Kafka.subscribe(Collections.singletonList(topic))
return consumer4Kafka
}
def main(args: Array[String]): Unit = {
//指定broker list列表
val brokersList = "sc-slave7:6667"
//必须指定消费者组id
var consumerGroupId = "TestConsumerID"
val topic: String = "TestKafka_scala"
var consumer4Kafka = KafkaConsumerUtil.getKafkaConsumer(brokersList, topic, consumerGroupId)
//注意用标志位做循环判断
var runnable = true
while (runnable) {
//因为版本的原因,此处用iterator遍历,而不用for循环
val records = consumer4Kafka.poll(100)
var iter = records.iterator()
while (iter.hasNext()) {
val record = iter.next()
println(record.offset() + "--" + record.key() + "--" + record.value())
}
}
consumer4Kafka.close()
println("done!")
}
}二丶Kafka与Streaming
两种方法
1.基于Receiver方式
先存于内存
-
优点
-
因为使用的kafka的高层API,用户在编码时更加可以专注数据本身,不需要关心offset等附加信息,而完全由zookeeper来管理,节省了工作量,减少了代码复杂度
-
因为其简单性,当对数据处理要求不是极为严格时,一般建均建议采用这种方式。
-
-
缺点
-
如果这时候集群退出,而偏移量又没处理好的话,数据就丢掉了,存在程序失败丢失数据的可能,后在Spark 1.2时引入一个配置参数spark.streaming.receiver.writeAheadLog.enable以规避此风险,即通过先写日志的方式来解决,相当于存储了两次数据,降低了数据处理效率,同时增加了receiver负担。
-
上边所述的方式,解决了数据丢失,但增加了数据重复消费的风险,比如程序计算完成并输出,但没有更新offset的情况,则会出现重复消费。
-
recevier也是executor的一部分,会占用相当一部分资源,降低了可用于streaming计算的资源,造成资源浪费。
-
receiver增加了数据消费链路的一个executor中转环节,该环节中的executor会和计算executor相一致才能保证系统稳定,而这两个环节之间是异步的,存在如网络异常、计算压力大的情况下,中转积压和消费缓慢的情况,导致系统崩溃。
-
用的较少
2.
- 基于Direct直接读取的方式
-
流程图
-
具体流程
-
实例化KafkaCluster,根据用户配置的Kafka参数,连接到Kafka集群
-
通过Kafka API读取Topic中每个Partition最后一次读的Offset
-
接收成功的数据,直接转换成KafkaRDD,供后续计算
-
-
代码实现
-
直接通过kafka consumer直接消费数据,形成一个Kafka的partition对应一个KafkaRDD的partition。
-
-
实现逻辑
-
使用Kafka Consumer直接消费其数据,不再需要Receiver作缓存。
-
-
背景
-
Receiver方式存储数据存储浪费、效率低等问题,在Spark1.3之后推出了Direct方式。
-
-
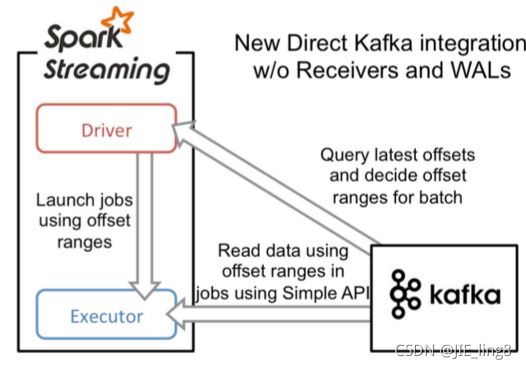
-
-
-
优点
-
存储效率更高: 不需要receiver中的防数据丢失的wal重复写一份了。
-
简化并行设计: Kafka中的Partition和Spark中的Partition一一对应,而Receiver并不对应,造成若干处理复杂,如流Join问题。
-
降低内存使用量:之前的recevier也占用了内存,必然导致总内存申请量的提高。
-
计算效率更高: 不需receiver后,降低了内存浪费,使更大比例内存用于实际的并行计算。
-
当对数据处理效率、性能要求较高时,一般建议采用这种方式。
-
-
问题点
-
offset在receiver时由zookeeper维护,而在direct时需要采用checkpoint或是第三方来存储维护,提高了用户开发成本。
-
监控可视化:offset信息由zookeeper维护时,均可通过监控zk相关信息来监控消费情况,而direct的offset是自行维护,其消费监控因此也需要自行开发才行
-
-
-
2、基于Direct方式读取kafka的代码实现
package com.tl.job015.streamingwithkafka
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.kafka010.LocationStrategies
import org.apache.spark.streaming.kafka010.ConsumerStrategies
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.Seconds
/**
* streaming集成kafka
*/
object SparkStreamingReadKafka4Direct {
def main(args: Array[String]): Unit = {
/**
* 1、构建ssc
* 2、设置checkpoint
* 3、构造direct stream对象
* 4、针对DStream的算子操作
* 5、环境变量操作
*/
// 1、构造ssc对象
val parasArray = Array[String]("cluster0.hadoop:6667", "TestKafka4Job015", "consumer_job015", "200")
val Array(brokers, topics, groupId, maxPoll) = parasArray
val sparkConf = new SparkConf().setAppName("KafkaDirect4Job011")
//可以代码设置运行模式,也可以在spark-submit当中设置
//sparkConf.setMaster(master)
val sc = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc, Seconds(5))
//2、设置offset的存储目录,此目录一般为hdfs目录
ssc.checkpoint("./kafka_direct")
//3、构造direct stream对象
val topicsSet = topics.split(",").toSet
val kafkaParams = Map(
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
ConsumerConfig.GROUP_ID_CONFIG -> groupId,
ConsumerConfig.MAX_POLL_RECORDS_CONFIG -> maxPoll.toString,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer])
val messages = KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))
//4、针对DStream的算子操作
val result: DStream[(String, Int)] = messages.map(_.value).flatMap(_.split("\\s+")).map((_, 1)).reduceByKey(_ + _)
// result.print
result.foreachRDD(x => {
x.foreachPartition(part => {
part.foreach(print)
})
})
//5、环境变量操作
ssc.start()
ssc.awaitTermination()
}
}