Python爬虫实战,requests模块,Python实现猫眼电影《龙牌之谜》用户评论数据可视化
前言
利用Python爬取猫眼电影《龙牌之谜》用户评论。废话不多说。
让我们愉快地开始吧~
开发工具
Python版本: 3.6.4
相关模块:
requests模块;
pyecharts模块
pandas模块;
numpy模块;
PIL模块;
jieba模块;
以及一些Python自带的模块。
环境搭建
安装Python并添加到环境变量,pip安装需要的相关模块即可。
豆瓣数据获取
爬取的过程还是蛮简单的,直接给出代码
1 def get_data():
2
3 data = []
4
5 for i in range(0, 150, 25):
6
7 url = 'https://movie.douban.com/celebrity/1054531/movies?start=%s&format=text&sortby=time&role=A1' % i
8
9 res = requests.get(url).text
10
11 content = BeautifulSoup(res, "html.parser")
12
13 tbody_tag = content.find_all('tbody')
14
15 tr_tag = tbody_tag[1].find_all('tr')
16
17 for tr in tr_tag:
18
19 tmp = []
20
21 name = tr.find('a').text
22
23 year = tr.find('td', attrs={
'headers': 'mc_date'}).text
24
25 rate = tr.find('td', attrs={
'headers': 'mc_rating'}).text
26
27 tmp.append(name)
28
29 tmp.append(year)
30
31 tmp.append(rate.replace('\n', '').strip().replace('-', ''))
32
33 data.append(tmp)
34
35 return data
36
37
38
39if __name__ == '__main__':
40
41 data = get_data()
42
43 print(data)
44
45 with open('jack_data.csv', 'w', encoding='utf-8') as f:
46
47 f.write('name,year,rate\n')
48
49 for d in data:
50
51 try:
52
53 rowcsv = '{},{},{}'.format(d[0], d[1], d[2])
54
55 f.write(rowcsv)
56
57 f.write('\n')
58
59 except:
60
61 continue
数据拿到之后,我们再做些简单的数据处理,去除掉 rate 为空的数据,和一些异常数据
1 df = pd.read_csv('jack_data.csv')
2
3 df.isnull().sum() # 查看缺失值情况
4
5
6
7 df_copy = df.copy()
8
9 df_copy.dropna(how='any', inplace=True) # 去掉缺失值
10
11
12
13 # 去掉异常值
14
15 except_data = df_copy[df_copy['name'].apply(lambda x: x == '喜剧之王')].index
16
17 df_copy.drop(except_data, inplace=True).
一、成龙电影总体得分分布
成龙大哥的高分电影,多集中在早年。大多数电影的评分,都几种在6-7分上下浮动。而近些年的几部电影,口碑都不是很好,有持续下滑的趋势。
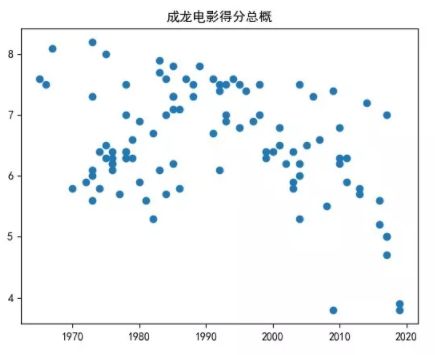
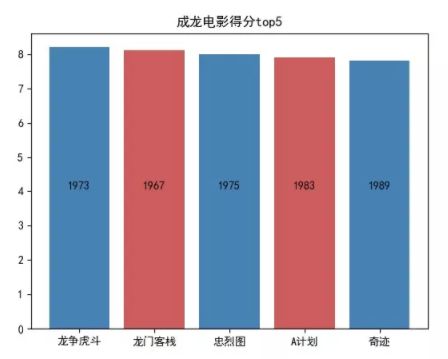
二、评分最高与最低影片
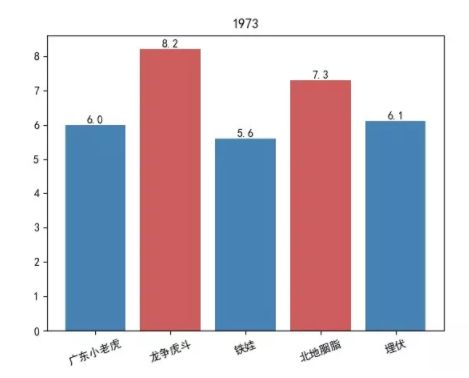
成龙大哥的电影,最高得分为《龙争虎斗》,8.2 分
评分最低的是《神探蒲松龄》,只有 3.8 分。
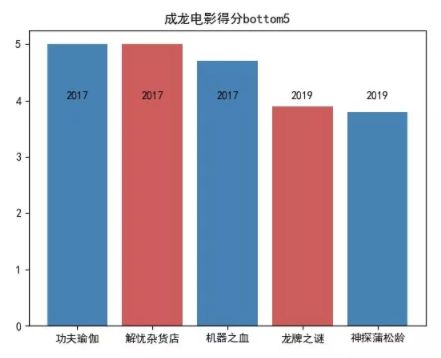
而《龙争虎斗》是 1973 年上映的,《神探蒲松龄》 则是 2019 年上映的,也从侧面反映出近些年龙大哥在电影市场的不给力情况。
其实龙大哥早些年的《A 计划》,《警察故事》等都是我蛮喜欢的电影。
三、出产电影年份
我们再来看看哪些年份,成龙大哥出产的电影比较多呢
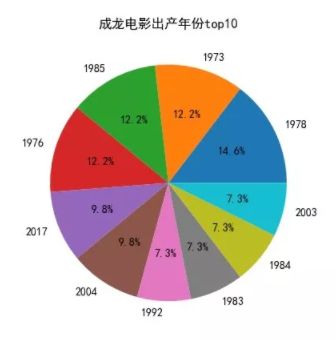
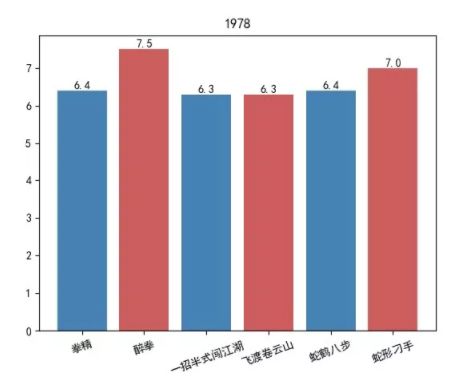
1978 年,成龙出产的电影占比是最多的,总共是 6 部,接下来就是 1973、1985 和 1976 年,都是 5部电影。
我们来看下这几年电影的评分情况
1978 年
1973 年
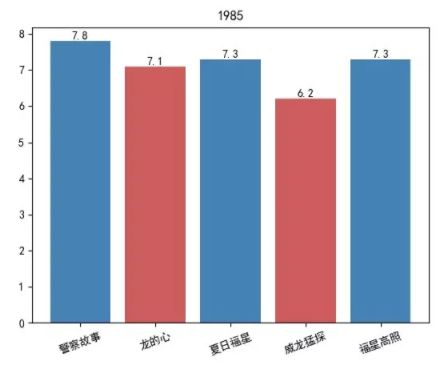
1985 年
1976 年
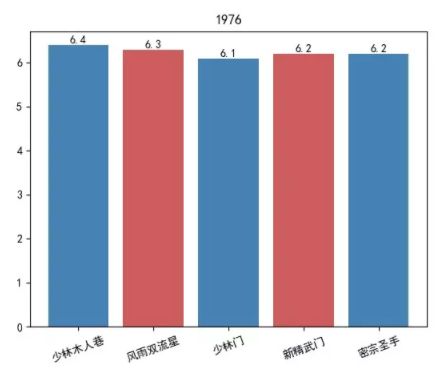
综上所述可以看出来,早些年,大哥年轻的时候,无论是数量还是质量,都是比较有保证的。
猫眼数据分析
爬一爬猫眼上《龙牌之谜》的用户评论,看看这个口碑不佳的作品,用户的想法是怎么样的
分析猫眼网站
我们首先进入到猫眼,找到对应的电影,目标地址为:https://maoyan.com/films/343473
页面拖到最下面,发现只有10条最热门的评论,其他评论哪去了?
浏览器手机模式
这里可以使用浏览器手机模式,在 Chrome 浏览器下,按 F12 打开开发者工具,再点击下图中的按钮,即可进入到手机模式
此时再重新刷新网页,发现我们已经神奇的进入到了猫眼的M站了
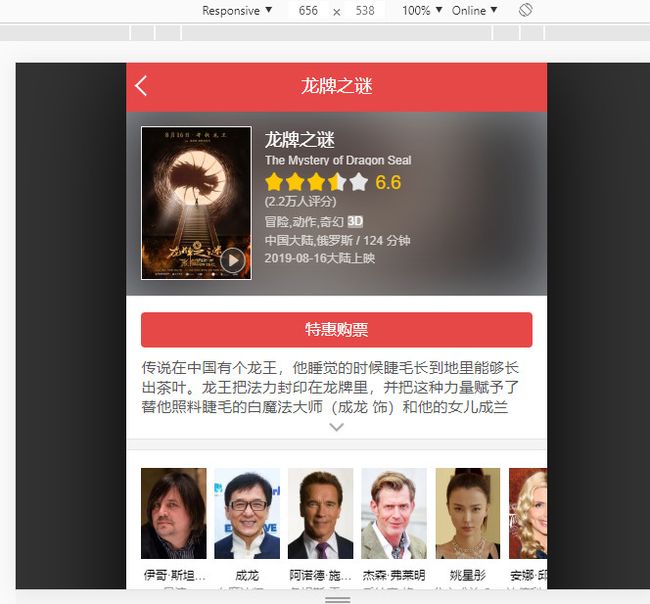
现在再拖动网页到最下部,点击查看全部评论,就可以进入到评论页面,查看全部的评论了。

寻找加载评论的接口
接下来我们继续下拉页面,发现评论是动态加载的。此时经验就非常重要了,我们让页面多加载加载评论几次,就能够发现一个“可疑”的请求,如下
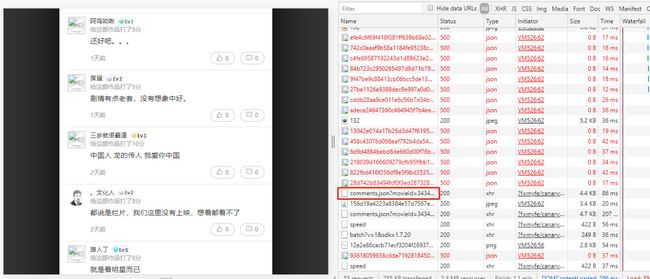
接下来再查看其 response,确实就是评论内容,而且是清爽的 json 数据,心情是如此的美丽。
分析接口参数
我们先来观察下这个接口
http://m.maoyan.com/review/v2/comments.json?movieId=343473&userId=-1&offset=30&limit=15&ts=1567064825883&type=3
movieid 很显然就是电影的 id,不动
userid 的值为 -1,应该是我们没有登陆的原因
offset 经过尝试,相当于是 page 的作用,且每次的步长为 15
limit 应该是每次返回数据的数量
其他的参数暂时不明
我们把该接口信息放到 postman 中,尝试着调用下
我去掉了 movieid 以外的所有参数,发现是可以调用成功的
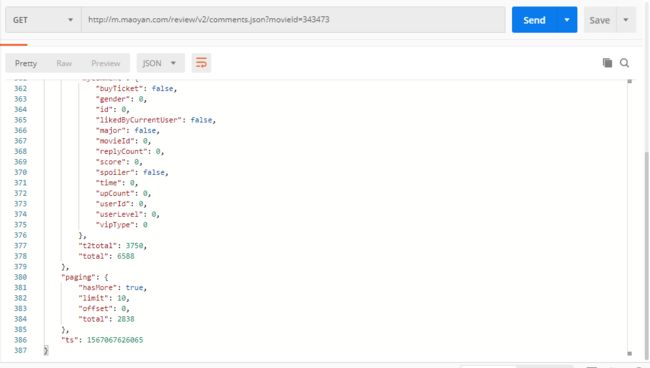
查看接口返回数据的最后面,发现一个 paging 字段
1 "paging": {
\
2 "hasMore": true,\
3 "limit": 10,\
4 "offset": 0,\
5 "total": 2838\
6 }
已经清楚的告诉了我们,还有更多数据(“hasMore”: true),每页限制为10(“limit”: 10),当前是第0页(“offset”: 0),总共的数据为2838条(“total”: 2838)。
最后经过测试,type = 3 会每次都会返回 hotComments 这个字段,而当 type = 2 时,则不会返回该字段,于是我选择使用 type 为2来发送请求,那么最终我决定使用的请求 url 就是如下:
http://m.maoyan.com/review/v2/comments.json?movieId=343473&offset=60&limit=15&type=2
offset 作为变量,循环替换即可。
编写爬虫代码
提取 json 数据
1 def get_json(res):
2 data_list = []
3 res_json = json.loads(res)
4 data = res_json['data']['comments']
5 for d in data:
6 content = d['content']
7 gender = d['gender']
8 userLevel = d['userLevel']
9 score = d['score']
10 try:
11 if len(d['tagList']) == 0:
12 ticket = 0
13 elif len(d['tagList']) == 1:
14 if d['tagList'][0]['id'] == 4:
15 ticket = 1
16 else:
17 ticket = 0
18 elif len(d['tagList']) == 2:
19 ticket == 1
20 except:
21 ticket = 0
22 tmp = [content, gender, userLevel, score, ticket]
23 data_list.append(tmp)
24 return data_list
解析 json 就比较简单了,只要做好异常处理即可。
因为评论中有很多 emoji 表情,可以使用正则过滤掉
1 emoji_pattern = re.compile("["
2 u"\U0001F600-\U0001F64F" # emoticons
3 u"\U0001F300-\U0001F5FF" # symbols & pictographs
4 u"\U0001F680-\U0001F6FF" # transport & map symbols
5 u"\U0001F1E0-\U0001F1FF" # flags (iOS)
6 "]+", flags=re.UNICODE)
7 emoji_pattern1.sub(r'', str1)
最后保存数据到 csv 文件
1 def save_to_csv(data):\
2 with open('maoyan_data.csv', 'w', encoding='utf-8') as f:\
3 f.write('content,gender,userlevel,score,ticket\n')\
4 for d in data:\
5 try:\
6 row = '{},{},{},{},{}'.format(d[0], d[1], d[2], d[3], d[4])\
7 f.write(row)\
8 f.write('\n')\
9 except:\
10 continue
展示得到的数据如下:
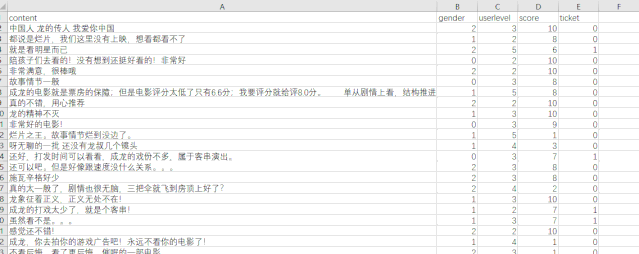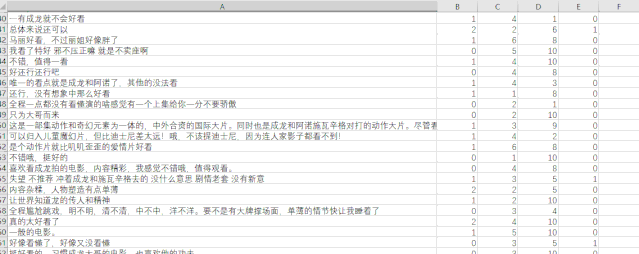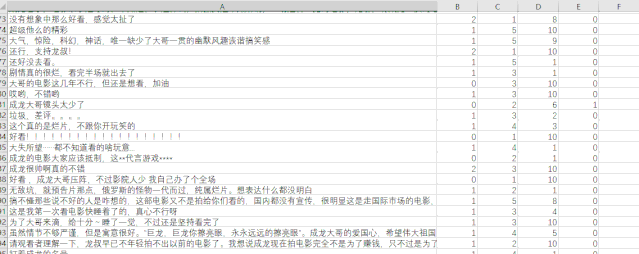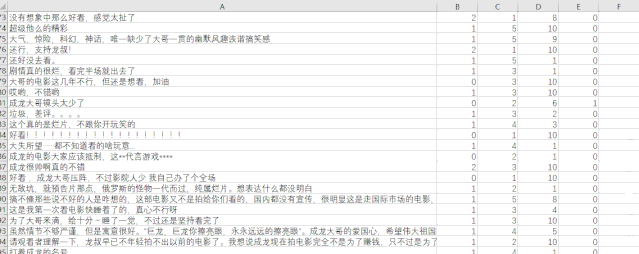
数据可视化分析
性别分布
我们先来看下评论者的性别分布是怎样的
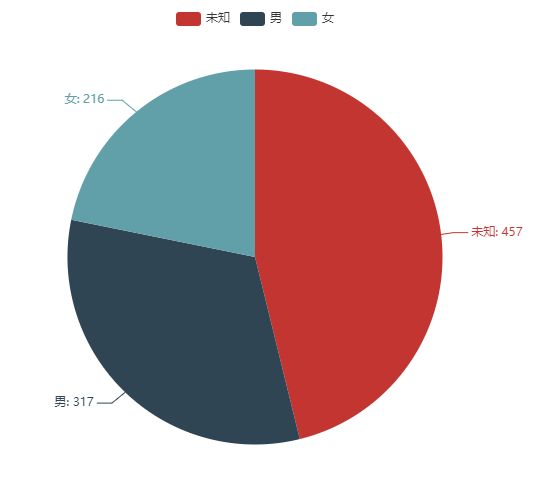
可以看出,男性观众的比例还是多一些,不过大多数人都没有设置性别,隐私工作做得很不多哦
用户等级
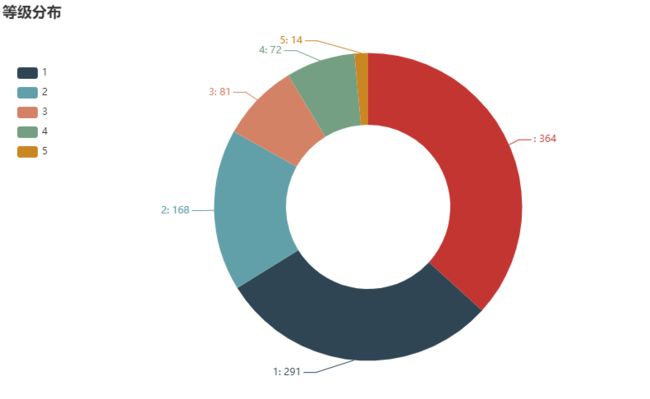
不出所料,大部分都是 level-0的用户,普通大众最普通,天下何止千千万。
评分分布
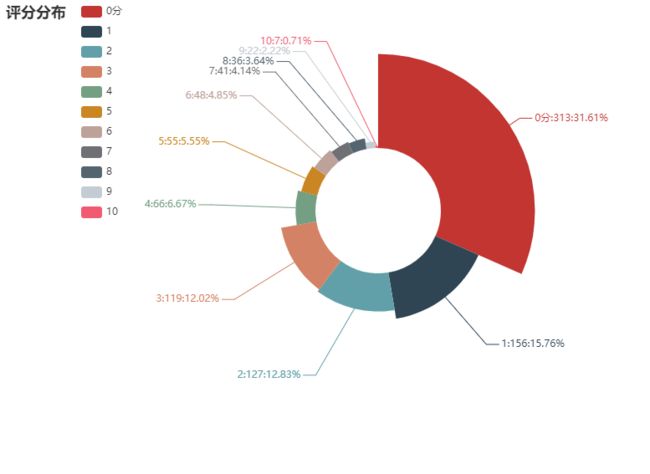
看到结果之后扎心不,打分数量最多的是0分,不知道如果可以打负分,那么情况会是怎么样
生成评论词云
最后,我们再来做一个词云,看看评论中的高频词汇都有哪些
