【pandas】 pandas基础
pandas基础
文件的读取和写入
文件读取
常用文件形式读取:
pd.read_csv(".csv")pd.read_table(".txt")⭐可以设置分隔符sep=" ",engine='python'但sep需要使用正则表达式pd.read_excel(".xlsx")
注:读取xlsx的文件需要把xlrd包降级到1.2.0版本
公共参数:
-
header=None表示第一行不作为列名 -
index_col表示把某一列或几列作为索引 -
usecols表示读取列的集合,默认读取所有的列 -
parse_dates表示需要转化为时间的列
数据写入
常用的文件形式写入:
df.to_csv(".csv", index=False)⭐index默认是True,不需要保存索引时需要手动设置为False,sep可以自定义设置df.to_csv(".txt", index=False, sep='\t')没有自定义to_table函数,可以自定义sepdf.to_excel(".xlsx", index=False)
安装tabulate包以后可以将表格转换为md和latex语言:
df.to_markdown()df.to_latex()
基本数据结构
pandas中具有两种基本的数据存储结构,存储一维values的Series和存储二维values的DataFrame,在这两种结构上定义了很多的属性和方法。值得注意的是这两种结构都不要求同列数据的type一致,与R语言的data.frame不一样。
Series(序列)
Series一般由四个部分组成,分别是序列的值data、索引index、存储类型dtype、序列的名字name。其中,索引也可以指定它的名字,默认为空。

Dataframe
构造
-
from 二维data
data = [[1, 'a', 1.2], [2, 'b', 2.2], [3, 'c', 3.2]] df = pd.DataFrame(data = data, index = ['row_%d'%i for i in range(3)], columns=['col_0', 'col_1', 'col_2']) df #col_0 col_1 col_2 #row_0 1 a 1.2 #row_1 2 b 2.2 #row_2 3 c 3.2 -
from 列索引
df = pd.DataFrame(data = { 'col_0': [1,"s",3], 'col_1':list('abc'), 'col_2': [1.2, 2.2, 3.2]}, index = ['row_%d'%i for i in range(3)]) df # 同列元素数据类型可以不一样,一般一样是为了应用函数方便? #col_0 col_1 col_2 #row_0 1 a 1.2 #row_1 s b 2.2 #row_2 3 c 3.2
取值
在DataFrame中可以用[col_name]与[col_list]来取出相应的列与由多个列组成的表,结果分别为Series和DataFrame
⭐注意多个列需要用[]框起来列名

转置
可以通过.T可以把DataFrame进行转置
常用基本函数
汇总函数
head, tail函数分别表示返回表或者序列的前n行和后n行,其中n默认为5
info, describe分别返回表的信息概况和表中数值列对应的主要统计量 (注意describe只对数值列进行统计)
特征统计函数
和numpy类似在基本数据结构上定义了许多基本的统计函数,常见的有sum, mean, median, var, std, max, min
使用方法示例:df.sum()
唯一值函数
unique
对序列Series使用unique和nunique可以分别得到其唯一值组成的列表和唯一值的个数,返回的是array!不是Series!

value_counts()
对Series使用value_counts()可以得到唯一值和其对应出现的频数,类似R语言table函数
drop_duplicates & duplicated
如果想要观察多个列组合的唯一值,可以使用drop_duplicates。其中的关键参数是keep,默认值first表示每个组合保留第一次出现的所在行,last表示保留最后一次出现的所在行,False表示把所有重复组合所在的行剔除。在Series上和Dataframe都可以使用。

替换函数
映射替换replace
-
by 字典构造 key->value
df['Gender'].replace({ 'Female':0, 'Male':1}).head() -
by 两个列表 list1->list2
df['Gender'].replace(['Female', 'Male'], [0, 1]).head()上述等价
-
特殊的方向替换,指定
method参数为ffill则为用前面一个最近的未被替换的值进行替换,bfill则使用后面最近的未被替换的值进行替换
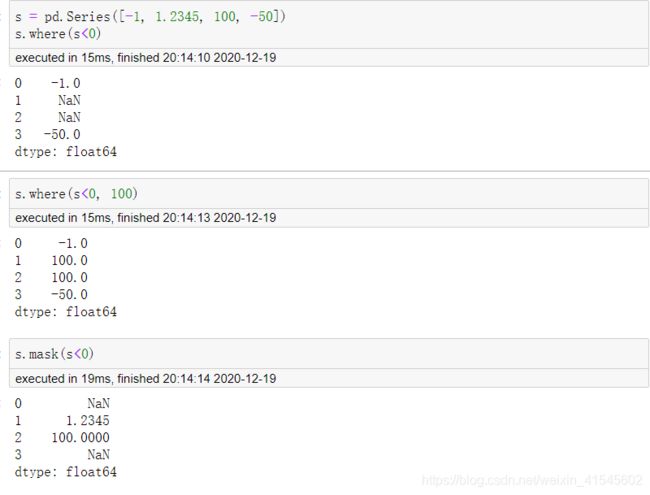
逻辑替换where,mask
where函数在传入条件为False的对应行进行替换,而mask在传入条件为True的对应行进行替换,当不指定替换值时,替换为缺失值。
数值替换round,abs,clip
round, abs, clip方法,它们分别表示取整、取绝对值和截断

排序函数
排序共有两种方式,其一为值排序,其二为索引排序,对应的函数是sort_values和sort_index,通用默认参数ascending=True为升序。
多层排序需要注意索引排序需要用level指定索引层的名字
df_demo.sort_values(['Weight','Height'],ascending=[True,False]).head()
df_demo.sort_index(level=['Grade','Name'],ascending=[True,False]).head()
apply方法
apply方法常用于DataFrame的行迭代或者列迭代,axis=1为逐行,axis=0为逐列。
⭐这里需要注意R语言的apply族函数能够很好的替代for循环,内部做了优化,能够提升运行效率,但是在pandas里由于pandas内置的很多函数本身能够设置axis,所以不必要用apply的时候不建议使用。
窗口对象
滑窗对象rolling
窗口由前面的n-1个元素加上本期元素构成
s = pd.Series([1,2,3,4,5])
roller = s.rolling(window = 3)
roller.mean()
#0 NaN
#1 NaN
#2 2.0
#3 3.0
#4 4.0
#dtype: float64
# 滑动相关系数和协方差
s2 = pd.Series([1,2,6,16,30])
roller.cov(s2)
#0 NaN
#1 NaN
#2 2.5
#3 7.0
#4 12.0
#dtype: float64
roller.corr(s2)
#0 NaN
#1 NaN
#2 0.944911
#3 0.970725
#4 0.995402
#dtype: float64
⭐rolling对象支持apply传入自定义函数
滑窗函数
shift, diff, pct_change是一组类滑窗函数,它们的公共参数为periods=n,默认为1,分别表示取向前第n个元素的值、与向前第n个元素做差(与Numpy中不同,后者表示**n阶差分**)、与向前第n个元素相比计算增长率。这里的n可以为负,表示反方向的类似操作。
常用于时间序列的处理!
扩张窗口expanding
扩张窗口又称累计窗口,可以理解为一个动态长度的窗口,其窗口的大小就是从序列开始处到具体操作的对应位置,其使用的聚合函数会作用于这些逐步扩张的窗口上。具体地说,设序列为a1, a2, a3, a4,则其每个位置对应的窗口即[a1]、[a1, a2]、[a1, a2, a3]、[a1, a2, a3, a4]。

指数加权窗口ewm
指数加权窗口最重要的参数是alpha,它决定了默认情况下的窗口权重为 w i = ( 1 − α ) i , i ∈ { 0 , 1 , . . . , t } w_i=(1−\alpha)^i,i\in\{0,1,...,t\} wi=(1−α)i,i∈{ 0,1,...,t},其中 i = t i=t i=t表示当前元素, i = 0 i=0 i=0表示序列的第一个元素。
从权重公式可以看出,离开当前值越远则权重越小,若记原序列为 x x x,更新后的当前元素为 y t y_t yt,此时通过加权公式归一化后可知:
$$
\begin{split}y_t &=\frac{\sum_{i=0}^{t} w_i x_{t-i}}{\sum_{i=0}^{t} w_i} \
&=\frac{x_t + (1 - \alpha)x_{t-1} + (1 - \alpha)^2 x_{t-2} + …
- (1 - \alpha)^{t} x_{0}}{1 + (1 - \alpha) + (1 - \alpha)^2 + …
- (1 - \alpha)^{t-1}}\\end{split}
$$
对于Series而言,可以用ewm对象如下计算指数平滑后的序列:
np.random.seed(0)
s = pd.Series(np.random.randint(-1,2,30).cumsum())
s.head()
练习:
Ex1:口袋妖怪数据集
现有一份口袋妖怪的数据集,下面进行一些背景说明:
-
#代表全国图鉴编号,不同行存在相同数字则表示为该妖怪的不同状态 -
妖怪具有单属性和双属性两种,对于单属性的妖怪,
Type 2为缺失值 -
Total, HP, Attack, Defense, Sp. Atk, Sp. Def, Speed分别代表种族值、体力、物攻、防御、特攻、特防、速度,其中种族值为后6项之和
- 对
HP, Attack, Defense, Sp. Atk, Sp. Def, Speed进行加总,验证是否为Total值。
df = pd.read_csv('../data/pokemon.csv')
df.head(3)
# 1.
df_ex1 = df[['HP','Attack','Defense','Sp. Atk','Sp. Def','Speed']]
(df_ex1.sum(1)!=df['Total']).sum()
- 对于
#重复的妖怪只保留第一条记录,解决以下问题:
- 求第一属性的种类数量和前三多数量对应的种类
- 求第一属性和第二属性的组合种类
- 求尚未出现过的属性组合
# 2.
df_ex1 = df.drop_duplicates("#", keep = 'first')
print('第一属性的种类数量:',df_ex1['Type 1'].nunique())
print('前三多数量对应的种类: ',df_ex1['Type 1'].value_counts().head(3),'\n')
print('第一属性和第二属性的组合种类')
print(df_ex1[['Type 1','Type 2']].drop_duplicates(['Type 1','Type 2']).shape)
typefull = [' '.join([i, j]) if i!=j else i for j in df_ex1['Type 1'].unique() for i in df_ex1['Type 1'].unique()]
typepart = [' '.join([i, j]) if type(j)!=float else i for i,j in zip(df_ex1['Type 1'],df_ex1['Type 2'])]
set(typefull).difference(set(typepart))
sep.join(seq)是字符串的连接函数,由于unique返回的是array所以不能在返回结果上使用drop_duplicates,连接成字符串,然后使用集合函数来去重。
- 按照下述要求,构造
Series:
- 取出物攻,超过120的替换为
high,不足50的替换为low,否则设为mid - 取出第一属性,分别用
replace和apply替换所有字母为大写 - 求每个妖怪六项能力的离差,即所有能力中偏离中位数最大的值,添加到
df并从大到小排序
df['Attack'].mask(df['Attack']>120, 'high').mask(df['Attack']<50, 'low').mask((50<=df['Attack'])&(df['Attack']<=120), 'mid').head()
df['Type 1'].replace({
i:str.upper(i) for i in df['Type 1'].unique()})
df['Type 1'].apply(lambda x:str.upper(x)).head()
df['Deviation'] = df[['HP', 'Attack', 'Defense', 'Sp. Atk', 'Sp. Def', 'Speed']].apply(lambda x:np.max((x-x.median()).abs()), 1)
df.sort_values('Deviation', ascending=False).head()
参考:DataWhale joyful-pandas