深度学习中的深度信念神经网络
深度信念神经网络(DBNN)是深度学习的最早应用之一。DBNN就是具有多个层的常规信念神经网络。Neil在1992年提出的信念神经网络不同于常规的FFNN。Hinton(2007)将DBNN描述为“由多层随机的潜在变量组成的概率生成式模型。”由于这个技术描述起来很复杂,因此我们要定义一些术语。
- 概率:DBNN用于分类,其输出是输入属于每个类别的概率。
- 生成式:DBNN可以为输入生成合理的、随机创建的值。一些DBNN文献将这个特征称为“做梦”(dreaming)。
- 多层:与神经网络一样,DBNN可以由多层组成。
- 随机的潜在变量:DBNN由玻尔兹曼机组成,这些机器会产生一些无法直接观察到(潜在)的随机值。
DBNN和FFNN之间的主要区别总结如下。
- DBNN的输入必须是二进制数,FFNN的输入必须是十进制数。
- DBNN的输出是输入所属的分类,FFNN的输出可以是类(分类)或数字预测(回归)。
- DBNN可以根据给定的结果生成合理的输入,FFNN不能像DBNN一样表现。
这些是DBNN和FFNN重要的差异。第一点是DBNN的最大限制因素之一。DBNN仅接收二进制输入,这一事实通常严重限制了它可以解决的问题类型。你还需要注意,DBNN只能用于分类,而不能用于回归。换言之,DBNN可以将股票分为购买、持有或出售等类别,但它无法提供有关库存的数字预测,如未来30天内可能达到的数量。如果需要这些特征中的任何一个,则应考虑使用常规的深度前馈神经网络。
与FFNN相比,DBNN最初似乎有些局限性。但是,它们确实具有根据给定输出生成合理的输入的能力。最早的DBNN实验之一是让DBNN使用手写样本将10个数字分类。这些数字来自MNIST手写数字数据集。用MNIST手写数字对DBNN进行训练,它就能产生每个数字的新表示,如图9-5所示。

图9-5 DBNN生成的数字
以上数字摘自Hinton(2006)的深度学习论文。第一行显示了DBNN从其训练数据生成的各种不同的0。
RBM是DBNN的中心。提供给DBNN的输入通过一系列堆叠的RBM传递,它们构成了神经网络的各层。创建附加的RBM层会导致DBNN更深。尽管我们没有对RBM进行监督,但是希望对最终的DBNN进行监督。为了完成监督,我们添加了一个最终的对数概率回归层,以区分类别。对于Hinton的实验(见图9-6),类别是10个数字。
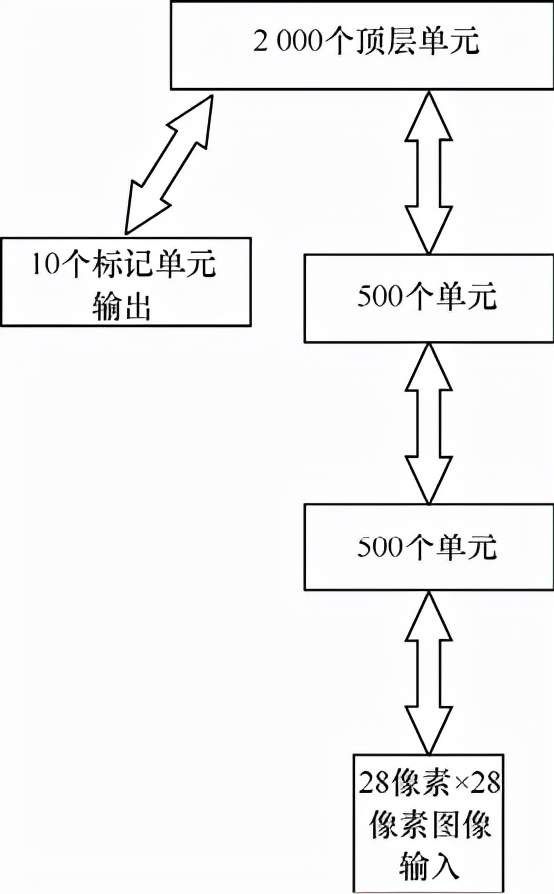
图9-6 DBNN
图9-6展示了一个DBNN,使用的超参数与Hinton的实验相同。超参数指定了神经网络的架构,如层数、隐藏的神经元计数和其他设置。呈现给DBNN的每个数字图像大小均为28×28(即784)维的向量。这些图像是单色的(即黑白的),每个像素都可以用一个比特来表示,与DBNN的所有输入均为二进制的要求兼容。上面的神经网络具有三层堆叠的RBM,分别包含500个神经元、500个神经元和2 000个神经元。
以下各小节讨论用于实现DBNN的多种算法。
9.8.1 受限玻尔兹曼机
第3章“霍普菲尔德神经网络和玻尔兹曼机”包含了对玻尔兹曼机的讨论,这里不赘述。本章介绍玻尔兹曼机的受限版本——RBM,并堆叠这些RBM以获得深度。第3章的图3-4展示了RBM。RBM与玻尔兹曼机的主要区别在于,RBM可见(输入)神经元和隐藏(输出)神经元具有仅有的连接。在堆叠RBM的情况下,隐藏神经元将成为下一层的输出。图9-7展示了如何将两台RBM堆叠在一起。
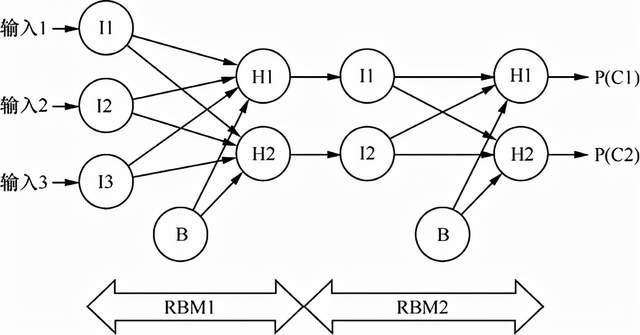
图9-7 堆叠的RBM
我们可以计算RBM的输出,可以利用第3章“霍普菲尔德神经网络和玻尔兹曼机”中的公式3-6进行计算。唯一的区别在于,现在我们有两台RBM堆叠在一起。RBM1接收传递到其可见神经元的3个输入;隐藏神经元将其输出直接传递到RBM2的两个输入(可见神经元)。请注意,两个RBM之间没有权重,RBM1中H1和H2神经元的输出直接从RBM2传递给I1和I2。
9.8.2 训练DBNN
训练DBNN的过程需要许多步骤。尽管这个过程背后的数学原理可能有些复杂,但是你无须了解训练DBNN的每个细节也可以使用它们。你只需要了解以下要点。
- DBNN接受有监督和无监督训练。
- 在无监督部分,DBNN使用训练数据而没有标记,这使DBNN可以混合使用监督数据和无监督数据。
- 在有监督部分,仅使用带有标记的训练数据。
- 在无监督部分,每个DBNN层都经过独立训练。
- 可以在无监督部分(通过线程)训练DBNN层。
- 在无监督部分完成之后,通过有监督对数概率回归来优化层的输出。
- 顶层对数概率回归层预测输入所属的分类。
有了这些知识,你就可以跳到本章9.8.8小节的深度信念应用。如果你想了解DBNN训练的具体细节,请继续阅读。
图9-8总结了DBNN训练的步骤。
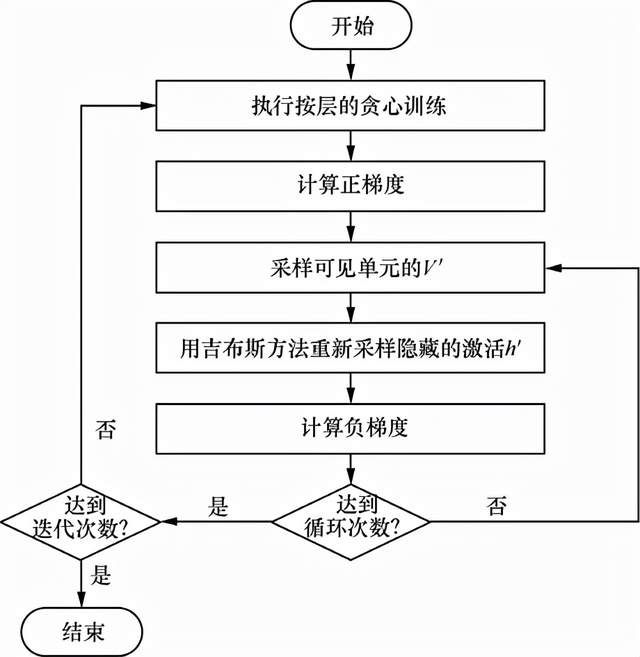
图9-8 DBNN训练
9.8.3 逐层采样
在单层上执行无监督训练时,第一步是计算直到该层的DBNN的所有值。你将针对每个训练集进行这种计算,DBNN将为你提供当前正在训练的层的采样值。采样是指神经网络根据概率随机选择一个真/假值。
你需要理解,抽样使用随机数为你提供结果。由于这种随机性,你不会总是获得相同的结果。如果DBNN确定隐藏神经元为真的概率为0.75,那么有75%的时间你将获得真值。逐层采样与第3章“霍普菲尔德神经网络和玻尔兹曼机”中用于计算玻尔兹曼机的输出的方法非常相似。我们将使用第3章中的公式3-6来计算概率。唯一的不同是,我们将使用公式3-6给出的概率来生成随机样本。
逐层采样的目的是产生一个二进制向量,提供给对比散度算法(contrastive divergence algorithm)。在训练每个RBM时,我们总是将前一个RBM的输出作为当前RBM的输入。如果我们要训练第一个RBM(最接近输入),只需将训练输入向量用于对比散度。该过程允许对每个RBM进行训练。DBNN的最终Softmax层在无监督阶段未受训练,最后的对数概率回归阶段将训练Softmax层。
9.8.4 计算正梯度
一旦逐层训练完了每个RBM层,我们就可以利用“上下算法”(up-down algorithm)或对比散度算法。完整的算法包括以下步骤,这些步骤将在后文中介绍。
- 计算正梯度;
- 吉布斯采样;
- 更新权重和偏置;
- 有监督的反向传播。
和第6章“反向传播训练”中介绍的许多基于梯度下降的算法一样,对比散度算法也基于梯度下降。它使用函数的导数来寻找让该函数产生最小输出的函数输入。在对比散度过程中估计了几个不同的梯度,我们可以使用这些估计值代替实际梯度计算,因为实际梯度太复杂而无法计算。对于机器学习,采用估计值通常就足够了。
另外,我们必须通过将可见神经元传播到隐藏神经元来计算隐藏神经元的平均概率。该计算是上下算法中的“向上”部分。公式9-1执行以下计算:
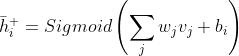
(9-1)
公式9-1计算每个隐藏神经元的平均概率(
![]()
)。
![]()
上方的短横表示它是一个平均值,正号标记表示我们正在计算算法中正向(即“向上”)部分的平均值。偏置会添加到所有可见神经元的加权和的S型激活函数值中。
接下来,必须为每个隐藏神经元采样一个值。利用刚计算出的平均概率,该值将随机分配为true(1)或false(0)。公式9-2完成了这种采样:
![]()
(9-2)
公式9-2假设
![]()
是0~1的一个均匀随机数。均匀随机数意味着该范围内的每个可能的数字都有相等的被选择概率。
9.8.5 吉布斯采样
负梯度的计算是上下算法的“向下”阶段。为了完成这种计算,该算法使用吉布斯采样来估计负梯度的平均值。Geman D.和Geman S.(1984)引入了吉布斯采样,并以物理学家Josiah Willard Gibbs命名。该技术通过循环迭代
![]()
次来完成,以提高估计的质量。每次迭代执行两个步骤:
(1)采样可见神经元提供给隐藏神经元;
(2)采样隐藏神经元提供给可见神经元。
对于吉布斯采样的第一次迭代,我们从9.8.4小节获得的正隐藏神经元样本开始。我们将从采样可见神经元的平均概率[即步骤(1)]。接下来,我们将利用这些可见的隐藏神经元,对隐藏的神经元进行采样[即步骤(2)]。这些新的隐藏概率是负梯度。对于下一次迭代,我们将使用负梯度代替正梯度。这个过程在每次迭代中重复,并产生更好的负梯度。公式9-3完成了对可见神经元的采样:
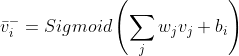
(9-3)
公式9-3实质上是公式9-1取反的结果。在这里,我们使用隐藏值确定可见平均值。然后,正如对正梯度所做的,我们使用公式9-4采样一个负概率:
![]()
(9-4)
公式9-4假设
![]()
是0~1的一个均匀随机数。
公式9-3和公式9-4只是吉布斯采样步骤的一半。这些方程式实现了步骤(1),它们在给定隐藏神经元的情况下对可见神经元进行了采样。接下来,我们必须完成步骤(2)。给定可见的神经元,我们必须对隐藏神经元进行采样。这个过程与9.8.4小节“计算正梯度”非常相似。但这一次,我们要计算负梯度。
刚刚计算出的可见神经元的样本可以获得隐藏平均值,如公式9-5所示:
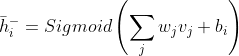
(9-5)
和以前一样,平均概率可以采样一个实际值。在这种情况下,我们使用隐藏平均值来采样一个隐藏值,如公式9-6所示:
![]()
(9-6)
吉布斯采样过程继续进行。负的隐藏样本可以在每次迭代中进行处理。一旦计算完成,你将拥有以下6个向量:
- 隐藏神经元的正平均概率;
- 隐藏神经元的正采样值;
- 可见神经元的负平均概率;
- 可见神经元的负采样值;
- 隐藏神经元的负平均概率;
- 隐藏神经元的负采样值。
这些值将更新神经网络的权重和偏置。
9.8.6 更新权重和偏置
所有神经网络训练的目的都是更新权重和偏置。这种调整使神经网络能够学习执行希望它执行的任务。这是DBNN训练过程中无监督部分的最后一步。在这个步骤中,将更新单层(玻尔兹曼机)的权重和偏置。如前所述,各个玻尔兹曼层是独立训练的。
权重和偏置会独立更新。公式9-7展示了如何更新权重:
![]()
(9-7)
学习率(ε)指定应该采用计算出的变化的比率。较高的学习率将使学习速度更快,但它们可能会跳过一组最佳权重。较低的学习率将使学习速度更慢,但结果的质量可能更高。值
![]()
代表当前训练集元素。因为
![]()
是向量(数组),所以
![]()
用“|| ||”标识其长度。公式9-7还使用了正平均隐藏概率、负平均隐藏概率和负采样值。
公式9-8以类似的方式计算偏置:
![]()
(9-8)
公式9-8使用了来自正向阶段的采样隐藏值、来自负向阶段的平均隐藏值,以及输入向量。权重和偏置更新后,训练的无监督部分就完成了。
9.8.7 DBNN反向传播
到目前为止,DBNN训练一直侧重于无监督训练。DBNN仅使用训练集输入(
![]()
值),即使数据集提供了预期的输出(
![]()
值),无监督的训练也没有使用它。现在,使用预期的输出来训练DBNN。在最后阶段,我们仅使用数据集中包含预期输出的数据项。这个步骤允许程序将DBNN与数据集一起使用,而其中每个数据项不一定具有预期的输出。我们将该数据称为部分标记的数据集。
DBNN的最后一层就是针对每个分类的神经元。这些神经元具有前一个RBM层输出的权重。这些输出神经元都使用S型激活函数和Softmax层。Softmax层确保每个类的输出总和为1。
采用常规的反向传播训练最后一层。最后一层实质上是前馈神经网络的输出层,前馈神经网络从顶层RBM接收其输入。第6章“反向传播训练”包含了对反向传播的讨论,因此不赘述。DBNN的主要思想是,层次结构允许每一层解释下一层的数据。这种层次结构使学习可以遍及各个层。较高的层学习更多的抽象概念,而较低的层由输入数据形成。在实践中,与常规的反向传播训练前馈神经网络相比,DBNN可以处理更复杂的模式。
9.8.8 深度信念应用
本小节介绍一个简单的DBNN示例。这个示例就是接受一系列输入模式及其所属的分类。输入模式如下所示:
[[1, 1, 1, 1, 0, 0, 0, 0],
[1, 1, 0, 1, 0, 0, 0, 0],
[1, 1, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 1, 1, 1, 1],
[0, 0, 0, 0, 1, 1, 0, 1],
[0, 0, 0, 0, 1, 1, 1, 0]]我们提供每个训练集元素的预期输出。这些信息指定了上述每个元素所属的分类,如下所示:
[[1, 0],
[1, 0],
[1, 0],
[0, 1],
[0, 1],
[0, 1]]本书示例中提供的程序将创建具有以下配置的DBNN。
- 输入层的大小:8。
- 隐藏的第1层:2。
- 隐藏的第2层:3。
- 输出层的大小:2。
首先,我们训练每个隐藏层。然后,我们在输出层执行对数概率回归。该程序的输出如下所示:
Training Hidden Layer #0
Training Hidden Layer #1
Iteration: 1, Supervised training: error = 0.2478464544753616
Iteration: 2, Supervised training: error = 0.23501688281192523
Iteration: 3, Supervised training: error = 0.2228704042138232
...
Iteration: 287, Supervised training: error = 0.001080510032410002
Iteration: 288, Supervised training: error = 7.821742124428358E-4
[0.0, 1.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0] -> [0.9649828726012807, 0.03501712739871941]
[1.0, 0.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0] -> [0.9649830045627616, 0.035016995437238435]
[0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0] -> [0.03413161595489315, 0.9658683840451069]
[0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 1.0] -> [0.03413137188719462, 0.9658686281128055]如你所见,该程序首先训练了隐藏层,然后进行了288次回归迭代。在迭代过程中,误差水平显著下降。最后,样本数据查询了神经网络。神经网络响应是在我们上面指定的两个类别中输入样本出现在每个类别中的概率。
如神经网络报告了以下元素:
[0.0, 1.0, 1.0, 1.0, 0.0, 0.0, 0.0, 0.0]其中,元素属于1类的概率约为96%,而属于2类的概率只有约4%。针对每个分类报告的两个概率之和必须为100%。
本文摘自《人工智能算法(卷3):深度学习和神经网络》

自早期以来,神经网络就一直是人工智能(Artificial Intelligence,AI)的支柱。现在,令人兴奋的新技术(如深度学习和卷积)正在将神经网络带入一个全新的方向。本书将演示各种现实世界任务中的神经网络,如图像识别和数据科学。我们研究了当前的神经网络技术,包括ReLU激活、随机梯度下降、交叉熵、正则化、Dropout及可视化等。
本书适合作为人工智能入门读者以及对人工智能算法感兴趣的读者阅读参考。