翻译Deep Learning and the Game of Go(10)第七章:从数据中学习:一个深度学习AI
本章包括
- 下载和处理实际的围棋游戏记录
- 了解存储围棋游戏的标准格式
- 训练一个使用这样的数据进行落子预测的深度学习模型
- 运行自己的实验并评估它们
在前一章中,您看到了构建深度学习应用程序的许多基本要素,并构建了一些神经网络来测试您所学到的工具。而关键的是你仍然缺少好的数据来学习。一个监督式的深度神经网络需要你提高好的数据——但目前为止,你只拥有自己生成的数据。
在这一章中,您将了解围棋数据最常见的数据格式-----SGF。您可以从几乎每个流行的围棋服务器中获得SGF游戏记录。为了加强深度神经网络的落子预测能力,在本章中,您将从围棋服务器中下载许多SGF文件,用智能的方式对它们进行编码,并使用这些数据训练神经网络。由此产生的经过训练的神经网络,将比以前的任何模型都要强得多。
图7.1说明了到本章结尾时可以构建的内容。
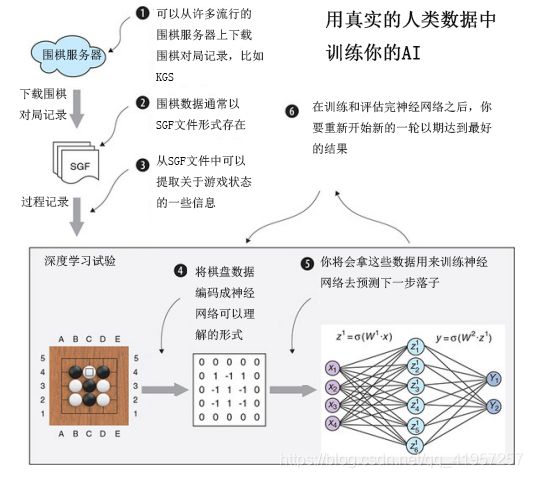
在本章的末尾,您可以使用复杂的神经网络运行自己的试验,完全独立地构建一个强大的AI。要开始,您需要访问真实的围棋数据。
7.1. 引入围棋数据
到目前为止,您使用的所有围棋数据都是由你自己生成的。在上一章中,你训练了一个深度神经网络来预测生成的数据的落子。你所希望实你的网络可以完美地预测这些落子,在这种情况下,网络将像生成数据的树搜索算法一样发挥作用。在某种程度上,你输入的数据奥克提供了一个深度学习机器人训练的上限。机器人不能超过产生的数据。如果利用强大的人类棋手游戏记录作为深层神经网络的输入,就可以大大提高您的机器人的水平。现在您将使用KGS围棋服务器(以前称为Kiseido GoServer)的游戏数据,这是世界上最流行的围棋游戏平台。在介绍如何从KGS下载和处理数据之前,我们将首先向你介绍围棋数据的数据格式。
7.1.1 SGF文件格式
SGF,80年代后期就开始开发。它目前的第四个主要版本(表示FF[4])是在90年代后期发布的。SGF是基于文本的一种格式,可以用来表达围棋游戏及围棋游戏的变体(例如,围棋高手的游戏评论)以及其他棋盘游戏。章节的剩下部分,你将假设你正在处理的SGF文件是由围棋游戏组成,没有其他任何别的东西。在本节中,我们会教你一些关于这个丰富游戏格式的基本知识,但如果你想学习更多关于它的知识的话,请去https://senseis.xmp.net/?SmartGameFormat。
SGF主要包括游戏情况和落子数据,是通过两个指定的大写字母包在两个大括号里面。例如,在SGF中,一个大小为9×9的围棋盘将被编码为SZ[9]。围棋落子将会如下编码,在第三行和第三列上的一个交叉点上落白棋将是W[cc],而在第七行和第三列上的一个交叉点上落黑棋将被表示成B[gc];字母B和W代表棋子的颜色,行和列的坐标按字母顺序索引。若要表示pass,请使用空步骤B[]和W[]。
下面的SGF文件示例取自第二章9*9棋盘上的完整对局。它显示了一个围棋游戏(GM[1]代表是围棋),HA[0]表示让子数为0,KM[6.5]表示贴目6.5,R U[Japanese]表示规则是日本规则,RE[W9.5]表示白赢了6.5目

一个SGF文件被组织成一个节点列表,节点由分号分隔。第一个节点包含有关游戏的信息:棋盘大小、使用的规则、游戏结果和其他背景信息。后面的每个节点表示游戏中的一个落子。最后,你也可以看到属于白棋地盘的点,列在TW之下,以及属于黑棋地盘的点,列在TB之下。
7.1.2.从KGS下载和回放Go游戏记录
如果你进入到https://ugo.net/gamerecords/,你会看到一张表格,上面有可供下载的各种格式游戏记录。这个游戏数据是从KGS 围棋服务器收集的,所有这些游戏都是在19×19的棋盘上进行的,而在第六章中,我们为了减少计算而只使用了个9×9的棋盘。
这是一个令人难以置信的强大数据集,可以用于围棋落子预测,您将在本章中使用该数据集来为强大的深度学习机器人提供动力。您需要可以自动通过获取单个文件的链接下载,然后解压文件,最后处理其中包含的SGF游戏记录。
作为使用这个数据作为深度学习模型的输入第一步,你可以在主dlgo模块中创建一个名为data的新子模块,并像往常一样提供一个空的_init_.py。这个子模块将包含所有这本书所需的数据处理。
接下来,要下载游戏数据,您可以在数据子模块中添加新文件index_processor.py中,并创建一个名为KGSIndex的类,然后实现其中的download_files方法
7.2 为深度学习准备数据
在第6章中,您看到了一个简单的围棋数据编码器,该编码器已经表示了在第3章中介绍的Board和GameState类。当使用SGF文件时,您首先需要对内容进行回放,产生对应的一个对局,得到必要的游戏信息。
7.2.1.根据SGF记录重放围棋对局
读取SGF文件的游戏信息意味着要理解和实现格式规范。虽然这并不是特别难做到(只是强加一个规则在一串文本上),这也不是构建围棋AI最令人兴奋的方面,需要大量的努力和时间才能做到完美无缺。出于这些原因,我们将引入另一个子模块gosgf到dlgo中,它负责处理SGF文件所需的所有逻辑。gosgf模块是从Gomill Python库改编而来的,地址是https://mjw.woodcraft.me.uk/gomill/
您将需要一个来自gosgf的实体,它足以处理您需要的所有内容:sgf_game。让我们看看如何使用SGF_Game加载一个SGF游戏,逐步读出游戏信息,并将落子应用于Game State对象。图7.2显示了围棋游戏的开始,用SGF命令表示。

从SGF文件中重放游戏记录。原来的SGF文件编码游戏移动与字符串,如B[ee]。Sgf_game类解码这些字符串并将它们作为Python元组返回。你就可以将这些落子应用到GameState对象以重建游戏
# 先从新的gosgf模块导入Sgf_game类
from dlgo.gosgf import Sgf_game
from dlgo.goboard_fast import GameState, Move
from dlgo.gotypes import Point
from dlgo.utils import print_board
# 定义示例SGF字符串,此内容稍后会来自下载的数据
sgf_content = "(;GM[1]FF[4]SZ[9];B[ee];W[ef];B[ff]" + ";W[df];B[fe];W[fc];B[ec];W[gd];B[fb])"
# 使用from_string方法,您可以创建一个SGF_game
sgf_game = Sgf_game.from_string(sgf_content)
game_state = GameState.new_game(19)
# 重复游戏的主要顺序,你忽略了棋局变化和评论
for item in sgf_game.main_sequence_iter():
# 这个主序列中的项是(颜色,落子)对,其中"落子"是一对坐标。
color, move_tuple = item.get_move()
if color is not None and move_tuple is not None:
row, col = move_tuple
point = Point(row + 1, col + 1)
move = Move.play(point)
# 将读出的落子应用到棋盘上
game_state = game_state.apply_move(move)
print_board(game_state.board)从本质上讲,在您有了一个有效的SGF字符串之后,您就可以根据它得到主要序列,而这些序列你可以通过迭代得到。上面代码是本章的核心,它给出了一个粗略的大纲,告诉你将如何继续处理深度学习所需的数据:
- 下载并解压缩围棋游戏文件。
- 遍历这些文件中包含的每个SGF文件,读取文件中的内容变成字符串,然后从这些字符串中创建一个Sgf_game。
- 读出每个SGF字符串的围棋游戏的主要顺序,确保处理重要的细节,如放置棋子,并将产生的落子数据输入到GameState对象中。
- 对于每一个落子,棋盘局面采用编码器进行编码成特征,并将落子本身存储为标签,然后将其放置在棋盘上。这样,您将创建落子预测数据,以便在后面训练中进行深入学习。
- 5.将生成的特征和标签以合适的格式存储起来,这样您就可以稍后将其添加到神经网络中。
在接下来的几节中,您将非常详细地处理这五个任务。处理完这些数据后,您可以回到您的落子预测应用程序,看看如何让数据影响落子预测精度。
7.2.2.构建围棋数据处理器
在本节中,您将构建一个围棋数据处理器,该处理器可以将原始SGF数据转换为机器学习算法的特征和标签。这将是一个相对较长的实现,因此我把它分成几个部分。当你完成的时候,你就可以准备好在真实数据上运行一个深度学习模型。
要开始,先在data模块下新建一个名为processor.py的新文件,让我们导入几个核心Python库,除了用于数据出来的NumPy之外,您还需要相当多的包来处理文件。
import os.path
import tarfile
import gzip
import glob
import shutil
import numpy as np
from keras.utils import to_categorical至于dlgo本身所需要的功能,您需要导入到目前为止构建的许多核心类。
from dlgo.gosgf.sgf import Sgf_game
from dlgo.agent.FastRandomAgent.goboard_fast import Board, GameState, Move
from dlgo.gotypes import Player, Point
from dlgo.Encoder.Base import get_encoder_by_name
from dlgo.data.index_processor import KGSIndex
from dlgo.data.sampling import Sampler # 从文件中采样训练和测试数据我们还没有后面两个引入,但我们将在构建围棋数据处理器中引入它们。现在继续使用processor.py,GoDataProcessor初始化是通过提供一个Encoder作为字符串和一个存储围棋书记路径的data_directory
class GoDataProcessor:
def __init__(self,encoder="OnePlaneEncoder",data_directory="data"):
self.encoder = get_encoder_by_name(encoder,19)
self.data_directory = data_directory接下来,您将实现主要的数据处理方法,称为load_go_data。在此方法中,您可以指定要处理的游戏数量以及要加载的数据类型,即训练或测试数据。load_go_data将从KGS中下载在线游戏记录,对指定数量的游戏进行采样,通过创建功能和标签进行处理,然后将结果持久化到本地作为NumPy数组。
并行处理parallel.py
"""
将sgf文件转成可被机器学习使用的格式
"""
# 文件相关类 begin
import os.path
import tarfile
import gzip
import glob
import shutil
# 文件相关类 end
import os
from os import sys
import multiprocessing
import numpy as np
from keras.utils import to_categorical
from dlgo.gosgf.sgf import Sgf_game
from dlgo.agent.FastRandomAgent.goboard_fast import Board, GameState, Move
from dlgo.gotypes import Player, Point
from dlgo.Encoder.Base import get_encoder_by_name
from dlgo.data.index_processor import KGSIndex
from dlgo.data.Sample import Sampler
from dlgo.data.generator import DataGenerator
def worker(jobinfo):
try:
clazz, encoder, zip_file, data_file_name, game_list = jobinfo
clazz(encoder=encoder).process_zip(zip_file, data_file_name, game_list)
except (KeyboardInterrupt, SystemExit):
raise Exception('>>> Exiting child process.')
class GoDataProcessor:
def __init__(self,encoder="OnePlaneEncoder",data_directory="data"):
self.encoder = get_encoder_by_name(encoder,19)
self.data_directory = data_directory
self.encoder_string = encoder
# 加载游戏训练数据
# data_type,您可以选择train或test,num_samples是指从数据中加载的数目
def load_go_data(self,data_type='train',num_samples=1000,use_generator=False):
"""index = KGSIndex(data_directory=self.data_directory)
index.download_files()"""
sampler = Sampler(data_dir=self.data_directory)
# 采样指定数据类型和指定数量的对局记录。
data = sampler.draw_data(data_type,num_samples)
# 将加载工作送到CPU
self.map_to_workers(data_type, data)
# 根据选择返回生成器和数据集
if use_generator:
generator = DataGenerator(self.data_directory, data)
return generator
else:
features_and_labels = self.consolidate_games(data_type, data)
return features_and_labels
# 解压数据
def unzip_data(self, zip_file_name):
this_gz = gzip.open(self.data_directory + '/' + zip_file_name)
# 去掉后缀gz
tar_file = zip_file_name[0:-3]
this_tar = open(self.data_directory + '/' + tar_file, 'wb')
# 将解压文件的内容复制到"tar"文件中
shutil.copyfileobj(this_gz, this_tar)
this_tar.close()
return tar_file
# 将压缩文件进行处理,得到特征和标签,game_list里存该zip文件夹下所有sgf文件下标
def process_zip(self,zip_file_name,data_file_name,game_index_list):
tar_file = self.unzip_data(zip_file_name)
zip_file = tarfile.open(self.data_directory+"/"+tar_file)
# 获得该zip下的所有文件名
name_list = zip_file.getnames()
# 确定此压缩文件中落子总数,也就对应数据总数
total_examples = self.num_total_examples(zip_file, game_index_list, name_list)
# 从您使用的编码器中推断特征和标签的形状,即(1,19,19)
shape = self.encoder.shape()
# 把数据总数插入到shape数组的第一个,这样的思维数组有几个三维数组,即代表有几局盘面,而每个三维数组都是经过编码后的单平面形状
feature_shape = np.insert(shape, 0, np.asarray([total_examples]))
features = np.zeros(feature_shape)
# 一个局面对应一个标签,所以有几局就有几个标签
labels = np.zeros((total_examples,))
# 用于特征和标签的下标
counter = 0
# 遍历每个文件
for index in game_index_list:
name = name_list[index+1]
# 读取该文件内容
sgf_content = zip_file.extractfile(name).read()
# 使用from_string方法,根据文件内容创建一个Sgf_game
sgf = Sgf_game.from_string(sgf_content)
# 得到初始游戏状态
game_state,first_move_done = self.get_handicap(sgf)
# 遍历文件中的主要落子序列
for item in sgf.main_sequence_iter():
color,move_tuple = item.get_move()
point = None
if color is not None:
# 有落子
if move_tuple is not None:
row,col =move_tuple
point = Point(row+1,col+1)
move = Move.play(point)
# 玩家pass了
else:
move = Move.pass_turn()
#如果第一步下了的话,就把之前的局面和下的一步编码后加入到特征和标签数组里
if first_move_done and point is not None:
features[counter] = self.encoder.encode(game_state)
labels[counter] = self.encoder.encode_point(point)
counter+=1
game_state = game_state.apply_move(move)
first_move_done = True;
# 将特征矩阵和标签矩阵存入到文件中
feature_file_base = self.data_directory + '/' + data_file_name + '_features_%d'
label_file_base = self.data_directory + '/' + data_file_name + '_labels_%d'
chunk = 0 # 由于文件包含大量内容,因此在chunksize之后拆分
chunksize = 1024
# 将数据总数按1024进行分割,每个分块都存到单独地的文件中
while features.shape[0] >= chunksize:
feature_file = feature_file_base % chunk
label_file = label_file_base % chunk
chunk += 1
# 当前的块与功能和标签被切断...
current_features, features = features[:chunksize], features[chunksize:]
current_labels, labels = labels[:chunksize], labels[chunksize:]
# 然后存储在一个单独的文件中,每个文件中存储1024个的数据
np.save(feature_file, current_features)
np.save(label_file, current_labels)
# 合并所有数组成一个
def consolidate_games(self, data_type, samples):
files_needed = set(file_name for file_name, index in samples)
file_names = []
for zip_file_name in files_needed:
file_name = zip_file_name.replace('.tar.gz', '') + data_type
file_names.append(file_name)
feature_list = []
label_list = []
for file_name in file_names:
file_prefix = file_name.replace('.tar.gz', '')
base = self.data_directory + '/' + file_prefix + '_features_*.npy'
for feature_file in glob.glob(base):
label_file = feature_file.replace('features', 'labels')
x = np.load(feature_file)
y = np.load(label_file)
x = x.astype('float32')
y = to_categorical(y.astype(int), 19 * 19)
feature_list.append(x)
label_list.append(y)
features = np.concatenate(feature_list, axis=0)
labels = np.concatenate(label_list, axis=0)
np.save('{}/features_{}.npy'.format(self.data_directory, data_type), features)
np.save('{}/labels_{}.npy'.format(self.data_directory, data_type), labels)
def map_to_workers(self, data_type, samples):
zip_names = set()
indices_by_zip_name = {}
for filename, index in samples:
zip_names.add(filename)
if filename not in indices_by_zip_name:
indices_by_zip_name[filename] = []
indices_by_zip_name[filename].append(index)
zips_to_process = []
for zip_name in zip_names:
base_name = zip_name.replace('.tar.gz', '')
data_file_name = base_name + data_type
if not os.path.isfile(self.data_directory + '/' + data_file_name):
zips_to_process.append((self.__class__, self.encoder_string, zip_name,
data_file_name, indices_by_zip_name[zip_name]))
cores = multiprocessing.cpu_count() # Determine number of CPU cores and split work load among them
pool = multiprocessing.Pool(processes=cores)
p = pool.map_async(worker, zips_to_process)
try:
_ = p.get()
except KeyboardInterrupt: # Caught keyboard interrupt, terminating workers
pool.terminate()
pool.join()
sys.exit(-1)
# 获取让子(可能没让子)的初始棋盘状态,让子后表示黑棋已经让出先行权,因此first_move_done为true
@staticmethod
def get_handicap(sgf):
go_board = Board(19, 19)
first_move_done = False
move = None
game_state = GameState.new_game(19)
# 有让子就加上让的棋子
if sgf.get_handicap() is not None and sgf.get_handicap() != 0:
for setup in sgf.get_root().get_setup_stones():
for move in setup:
row, col = move
go_board.place_stone(Player.black, Point(row + 1, col + 1))
first_move_done = True
game_state = GameState(go_board, Player.white, None, move)
return game_state, first_move_done
def num_total_examples(self, zip_file, game_index_list, name_list):
total_examples = 0
for index in game_index_list:
name = name_list[index + 1]
# 后缀名是.sgf
if name.endswith('.sgf'):
# 读取sgf文件里的内容
sgf_content = zip_file.extractfile(name).read()
# 根据内容创建Sgf_game
sgf = Sgf_game.from_string(sgf_content)
game_state, first_move_done = self.get_handicap(sgf)
# 只计算真正落子的数目
num_moves = 0
for item in sgf.main_sequence_iter():
color, move = item.get_move()
if color is not None:
if first_move_done:
num_moves += 1
first_move_done = True
total_examples = total_examples + num_moves
else:
raise ValueError(name + ' is not a valid sgf')
return total_examples
if __name__ == "__main__":
process = GoDataProcessor()
generator = process.load_go_data('train', 100, use_generator=True)
print(generator.get_num_samples())
generator = generator.generate(batch_size=10, num_classes=361)
x, y = next(generator)
print(x)
print("-------------------")
print(y)
生成器generator.py
import numpy as np
import glob
from keras.utils import to_categorical
# 处理数据样本,保证训练需要一批数据时,为其提供数据
class DataGenerator:
def __init__(self,data_directory,samples):
self.data_directory = data_directory
self.samples = samples
self.files = set(file_name for file_name,index in samples)
self.num_samples = None
# 获得样本的数目
def get_num_samples(self,batch_size=128,num_classes=361):
if self.num_samples is not None:
return self.num_samples
else:
self.num_samples = 0
for x, y in self._generate(batch_size=batch_size, num_classes=num_classes):
self.num_samples += x.shape[0]
return self.num_samples
def _generate(self, batch_size, num_classes):
for zip_file_name in self.files:
file_name = zip_file_name.replace('.tar.gz', '') + 'train'
base = self.data_directory + '/' + file_name + '_features_*.npy'
for feature_file in glob.glob(base):
label_file = feature_file.replace('features', 'labels')
x = np.load(feature_file)
y = np.load(label_file)
x = x.astype('float32')
y = to_categorical(y.astype(int), num_classes)
while x.shape[0] >= batch_size:
x_batch, x = x[:batch_size], x[batch_size:]
y_batch, y = y[:batch_size], y[batch_size:]
yield x_batch, y_batch # 返回一小批
def generate(self, batch_size=128, num_classes=19 * 19):
while True:
for item in self._generate(batch_size, num_classes):
yield item7.3.用人类数据进行深度学习训练
现在您可以访问HighDan Go数据并对其进行处理以适应移动预测模型,让我们连接这些点并为这些数据构建一个深度神经网络。在我们的GitHub存储库中,在我们的DLGO包中有一个名为网络的模块,您将使用它来提供神经网络的示例体系结构,您可以使用它作为基线来构建强移动预测模型。因斯坦在网络模块中,您会发现三个不同复杂度的卷积神经网络,分别称为small.py、media.py和size.py。每个文件都包含一个返回的层函数可以添加到顺序Keras模型中的层的列表。您将构建一个由四个卷积层组成的卷积神经网络,然后是最后一个密集层,所有这些都是ReLUactiv。iations.除此之外,您将在每个卷积层之前使用一个新的实用程序层-Zero Patding2D层。零填充是一种操作,其中输入特性被填充为0。让我们一起是的,你使用你的一个平面编码器从第6章编码板作为一个19×19矩阵。如果您指定了2的填充,这意味着您添加了左右两列0,以及两行从0到该矩阵的顶部和底部,导致一个扩大的23×23矩阵。在这种情况下,使用零填充来人为地增加卷积层的输入,从而使co卷积操作不会使图像缩小太多。在我们给你看代码之前,我们必须讨论一个小的技术问题。回想一下,卷积层的输入和输出都是四个子国际:我们提供了一个小批量的过滤器,每个都是二维的(即它们有宽度和高度)。这四个维度的顺序(小批量大小,过滤器的数量,宽度和高度)是一个惯例问题,你在实践中主要发现两个这样的顺序。请注意,过滤器通常也被称为通道(C)和小批量大小也称为例子的数目(N)。此外,您可以使用速记宽度(W)和高度(H)。有了这个符号,两个主要的顺序是NWHC和NCWH。在凯拉斯,这个命令就是由于一些明显的原因,LLED数据_Format和NWHC被称为通道_last和NCWH通道_first。现在,你建造第一个Go板编码器的方式,一个平面编码器,是在通道冷杉圣约定(编码板具有形状1,19,19,这意味着单个编码的平面是第一位的)。这意味着您必须首先提供data_format=Channels_first作为所有卷积层的参数。让我们看看这个模型是什么样子的。
from keras.layers.core import Dense, Activation, Flatten
from keras.layers.convolutional import Conv2D, ZeroPadding2D
# 应对9*9棋盘所需的层
def layers(input_type):
return [
# 使用ZeroPadding2D层放大层,避免卷积过后矩阵太小
ZeroPadding2D(padding=3, input_shape=input_type, data_format='channels_first'),
Conv2D(48, (7, 7), data_format='channels_first'),
Activation('relu'),
# 通过使用channels_first,您可以指定您的特征输入在平面维度优先。
ZeroPadding2D(padding=2, data_format='channels_first'),
Conv2D(32, (5, 5), data_format='channels_first'),
Activation('relu'),
ZeroPadding2D(padding=2, data_format='channels_first'),
Conv2D(32, (5, 5), data_format='channels_first'),
Activation('relu'),
ZeroPadding2D(padding=2, data_format='channels_first'),
Conv2D(32, (5, 5), data_format='channels_first'),
Activation('relu'),
Flatten(),
Dense(512),
Activation('relu'),
]该层函数返回一个Keras层列表,您可以将其逐个添加到顺序模型中。使用这些层,您现在可以构建一个应用程序,从t开始执行前五个步骤他在图7.1中概述了一个应用程序,它下载、提取和编码Go数据,并使用它来训练神经网络。对于训练部分,您将使用您构建的数据生成器。但首先,让我们导入您正在成长的Go机器学习库的一些基本组件。您需要Go数据处理器、编码器和神经网络体系结构来构建此应用程序。
from dlgo.data.parallel_processor import GoDataProcessor
from dlgo.Encoder.OnePlaneEncoder import OnePlaneEncoder
from dlgo.network import SmallLayer as small
from keras.models import Sequential
from keras.layers.core import Dense
from keras.callbacks import ModelCheckpoint # 存储进度。最后导入了名为ModelCheckpoint的Keras工具。因为你访问大量的数据进行训练去建立一个模型可能需要几个小时甚至几天。如果这样的实验因为某种原因而失败,你最好有一个备份。而这正是ModelChecpoint对你的作用:它们每轮训练完后都会保存一个模型。即使有些事情失败了,你也可以从最后一个检查点恢复训练。
接下来,让我们定义训练和测试数据。为此,首先初始化OnePlaneEncoder用来创建GoDataProcessor。使用此处理器,您可以实例化一个训练和一个测试数据生成器,该生成器将与Keras模型一起使用。
if __name__ == '__main__':
go_board_rows, go_board_cols = 19, 19
num_classes = go_board_rows * go_board_cols
num_games = 100
# 创建OnePlane编码器
encoder = OnePlaneEncoder((go_board_rows, go_board_cols))
# 初始化围棋数据进程
processor = GoDataProcessor(encoder=encoder.name())
# 创建训练数据生成器
generator = processor.load_go_data('train', num_games, use_generator=True)
# 创建测试数据生成器
test_generator = processor.load_go_data('test', num_games, use_generator=True)下一步,您可以使用dlgo.networks.small.py中的Layers函数来定义带有Keras的神经网络。你把这个小网络的层逐一添加到一个新的顺序网络中,然后最后添加一个最终的Dense层与Softmax激活。然后用分类交叉熵损失编译这个模型,并用SGD进行训练。
input_shape = (encoder.num_planes, go_board_rows, go_board_cols)
network_layers = small.layers(input_shape)
model = Sequential()
for layer in network_layers:
model.add(layer)
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])使用生成器训练Keras模型的工作方式与使用数据集的训练方式稍有不同。您现在需要调用fit_generator,而不是在模型上调用fit,还需要替换evaluate为evaluate_generator。此外,这些方法的特征与你之前看到的略有不同。使用fit_generator通过指定一个generator,指定训练轮数,以及您提供的step_per_epoch。这三个参数提供了训练模型的最小值。您还希望用测试数据验证培训过程。为此,您可以使用测试数据生成器提供validation_data,并将每轮的验证步骤数指定为validation_steps。最后,在模型中添加一个回调,以便在每轮之后存储Keras模型。作为示例,你训练一个五轮模型,每批大小为128
input_shape = (encoder.num_planes, go_board_rows, go_board_cols)
network_layers = small.layers(input_shape)
model = Sequential()
for layer in network_layers:
model.add(layer)
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
# end::train_generator_model[]
# tag::train_generator_fit[]
epochs = 5
batch_size = 128
model.fit_generator(generator=generator.generate(batch_size, num_classes), # <1>
epochs=epochs,
steps_per_epoch=generator.get_num_samples() / batch_size, # <2>
validation_data=test_generator.generate(batch_size, num_classes), # <3>
validation_steps=test_generator.get_num_samples() / batch_size, # <4>
callbacks=[ModelCheckpoint('../checkpoints/small_model_epoch_{epoch}.h5')]) # <5>
model.evaluate_generator(generator=test_generator.generate(batch_size, num_classes),
steps=test_generator.get_num_samples() / batch_size) # <6>请注意,如果您自己运行此代码,您应该知道完成此实验所需的时间。如果你在CPU上运行这个,训练一轮可能需要几个小时。恰好,机器学习中使用的数学与计算机图形学中使用的数学有很多共同之处。因此,在某些情况下,您可以将您的神经网络计算移动到您的GPU上,这样你可以获得一个大的加速。
如果你想使用GPU进行机器学习,那么带有Windows或Linux操作系统的NVIDIA芯片是最好的支持组合。
如果你不想自己尝试这个,或者只是现在不想这样做,我们已经为你预先计算了这个模型。看看我们的GitHub存储库,以下是训练运行的输出(计算在笔记本电脑上的旧CPU上,以鼓励您立即获得快速GPU)

正如你所看到的,经过三轮,就已经达到了98%的训练准确率和84%的测试数据。这是一个巨大的进步,为了建立一个真正强大的对手,您需要下一步使用更好的围棋数据编码器。在第7.4节中,您将了解两个更复杂的编码器,这将提高您的培训性能。
7.4.建造更好的围棋数据编码
第2章和第3章涵盖了围棋中的打劫规则。回想一下,这个规则的存在是为了防止游戏无限循环。如果我们给你一个随机的棋盘局面,你必须要判断是否有有一个劫。如果没有看到导致这个局面的序列,就没有办法知道。特别是,你使用一个平面编码器,它将黑色的棋子编码为1,白色的棋子编码为-1,空的位置编码为0,这样根本不可能了解任何关于劫的信息。你在第6章中构建的OnePlaneEncoder是有点过于简单,无法捕捉到构建强大围棋AI所需的所有内容。
在本节中,我们将为您提供两个更精细的编码,可以导致相对较强的落子预测性能。第一个我们称为SevenPlaneEncoder,它由七个特征平面组成。每架平面都是19×19矩阵,描述了一组不同的特征:
- 第一个平面用1表示只有1口气的白棋,否则都是0。
- 第二和第三特征平面用1分别表示有两口或至少三口气的白棋。
- 第四到第六个平面对于黑石头也是如此;它们编码1,2或至少3口气的黑棋。
- 最后一个平面再标记不能落的点,因为劫被标上了1。
除了显式编码ko的概念外,使用这组功能,您还可以模拟气,并区分黑棋和白棋。只有一口气的棋子有额外的意义,因为它们有可能在下一个回合被吃掉。因为该模型可以直接“看到”这个属性,所以它更容易了解这是如何影响游戏的。通过为诸如劫和气等概念创建平面,你可以给出对模型的暗示,这些概念是重要的,而不必解释它们是如何或为什么重要的。
让我们看看如何通过从编码器扩展来实现这一点。将下面的代码保存在sevenplane.py中。
import numpy as np
from dlgo.Encoder.Base import Encoder
from dlgo.gotypes import Point
from dlgo.agent.FastRandomAgent.goboard_fast import Move
class SevenPlaneEncoder(Encoder):
def __init__(self,board_width,board_height):
self.board_width = board_width
self.board_height = board_height
self.num_planes = 7
def name(self):
return "SevenPlanEncoder"下面实现编码:
def encode(self, game_state):
board_matrix = np.zeros(self.shape())
# 白棋从0下标平面开始,黑棋从3下标平面开始
base_plane = {
game_state.current_player: 0,
game_state.current_player.other: 3
}
for row in self.board_width:
for col in self.board_height:
point = Point(row+1, col+1)
point_string = game_state.board.get_go_string(point)
if point_string is None:
# 最后一层设置劫:把不能提回的劫设为1
if game_state.does_move_violate_ko(game_state.current_player, Move.play(point)):
board_matrix[6][row][col] = 1
else:
# 第1-3层留给白棋,分别存1,2,至少是3口气的白棋
# 第4-6层留给黑棋,分别存1,2,只杀3口气的白棋
liberty_plane = min(3, point_string.num_liberties)-1
liberty_plane += base_plane[point_string.color]
board_matrix[liberty_plane][row][col] = 1
def encode_point(self, point):
return self.board_width*(point.row-1)+(point.col-1)
def decode_point_index(self, index):
row = index // self.board_width + 1
col = index % self.board_width + 1
return Point(row, col)
def num_points(self):
return self.board_height*self.board_width
def shape(self):
return self.num_planes, self.board_width, self.board_height
def create(board_width, board_height):
return SevenPlaneEncoder(board_width, board_height)还有一种编码器,表现11个特征平面,类似于SevenPlaneEncoder,它叫SimpleEncoder,特征平面如下:
- 前四个特征平面分别描述具有1、2、3、4口气的黑棋。
- 后四个特征平面分别描述具有1、2、3、4口气的白棋。
- 如果轮到黑棋下,第九个特征平面设为1,如果轮到白下,就把第十个特征平面设为1。
- 最后一个特征平面同样表示劫。
import numpy as np
from dlgo.Encoder.Base import Encoder
from dlgo.gotypes import Point,Player
from dlgo.agent.FastRandomAgent.goboard_fast import Move
class ElevenPlaneEncoder(Encoder):
def __init__(self, board_width, board_height):
self.board_width = board_width
self.board_height = board_height
self.num_planes = 11
def name(self):
return "ElevenPlanEncoder"
def encode(self, game_state):
board_matrix = np.zeros(self.shape())
# 白棋从0下标平面开始,黑棋从3下标平面开始
base_plane = {
game_state.current_player: 0,
game_state.current_player.other: 4
}
# 轮到黑下
if game_state.current_player == Player.black:
board_matrix[8] = 1
# 轮到白下
else:
board_matrix[9] = 1
for row in self.board_width:
for col in self.board_height:
point = Point(row+1, col+1)
point_string = game_state.board.get_go_string(point)
if point_string is None:
# 最后一层设置劫:把不能提回的劫设为1
if game_state.does_move_violate_ko(game_state.current_player, Move.play(point)):
board_matrix[10][row][col] = 1
else:
# 第1-4层留给白棋,分别存1,2,3,4口气的白棋
# 第5-8层留给黑棋,分别存1,2,3,4口气的白棋
liberty_plane = min(4, point_string.num_liberties)-1
liberty_plane += base_plane[point_string.color]
board_matrix[liberty_plane][row][col] = 1
def encode_point(self, point):
return self.board_width*(point.row-1)+(point.col-1)
def decode_point_index(self, index):
row = index // self.board_width + 1
col = index % self.board_width + 1
return Point(row, col)
def num_points(self):
return self.board_height*self.board_width
def shape(self):
return self.num_planes, self.board_width, self.board_height
def create(board_width, board_height):
return ElevenPlaneEncoder(board_width, board_height)这个有11个平面的编码器更加具体地说明了一串棋子的气。两个都是很好的编码器,将会导致模型性能的显著改进。
在整个第5章和第6章中,你了解到了许多深度学习的技术,但其中一个重要的实验要素:您使用随机梯度下降(SGD)作为优化器。虽然SGD提供了一个很好的基线,但在下一节中,我们将教您Adagrad和Adadelta这两个优化器,使你的训练过程将大大受益。
7.5.具有适应性的培训
为了进一步提高围棋落子预测模型的性能,我们将在本章中介绍最后一组工具-随机梯度下降(SGD)以外的优化器。回顾第5章,SGD有一个相当简单的更新规则。如果对于参数W,您接收到ΔW的反向传播误差,还有特定的α学习速率,则用SGD更新此参数仅仅是计算![]() 。在许多情况下,这种更新规则可以导致良好的结果,但也存在一些缺点。为了解决这些问题,您可以使用其他许多优秀的优化器
。在许多情况下,这种更新规则可以导致良好的结果,但也存在一些缺点。为了解决这些问题,您可以使用其他许多优秀的优化器
7.5.1.SGD的衰退和动量
例如,一个广泛使用的想法是让学习率随着时间的推移而衰减;随着您采取的每一个更新步骤,学习率就会变小。这种技术通常很有效,因为在开始阶段,你的网络还没有学到任何东西,因此大的更新步骤可能会导致最小的损失,但当训练过程达到一定程度后,你应该使您的更新变小,并且只对不破坏进度的学习过程进行适当的改进。通常,你指定了一个衰减率来表示学习率衰减,这个百分比下降使得你会减少下一步的。
另一种流行的技术是动量技术,其中最后一个更新步骤的一小部分被添加到当前的更新步骤中。例如,如果W是你想要更新的参数向量,而]W是W的当前梯度,如果您使用的最后一次更新是U,那么下一个更新步骤将如下:
![]()
从上次更新中保留的这个分数g称为动量项。如果两个梯度项指向大致相同的方向,则下一个更新步骤将得到加强(接收动量)。如果梯度指向相反的方向,它们相互抵消,梯度受到抑制。这种技术被称为动量,因为物理概念同名相似,你可以将你的损失函数看成表面,而里面的参数则像一个滚下表面的球,而参数的更新就好像球在移动。如果你正在做梯度下降,你就可以想象成球在一个接一个地往下滚。如果最后几步(梯度)都指向同一个方向,球就会加快速度到达它的目的地。动量技术就利用了这种类比。
如果您想在SGD中使用衰变、动量或两者兼而有之,那就提供各自的比率。假如SGD的学习率为0.1,衰减率为1%,动量为90%,你会做以下工作
from keras.optimizers import SGD
sgd = SGD(lr=0.1, momentum=0.9, decay=0.01)7.5.2.利用Adagrad优化神经网络
学习率衰减和动量都在改进普通SGD方面做得很好,但仍然存在一些弱点。例如,如果你想到围棋棋盘,专业棋手几乎前几步只会下在棋盘的第三到五行,从来不会下在第一或第二行,但在对局结束时,形势有些逆转,因为最后的许多棋子会落在棋盘的边界。在你迄今为止使用的所有深度学习模型中,最后一层是Dense层(这里是19×19)。这一层的每个神经元对应一个棋盘上的落子点。如果你使用SGD,无论是否有动量或衰减,这些神经元的学习速率是相同的,这样就可能出现问题。也许你在训练中的糟糕数据,而且其学习率已经下降了很多,以至于在第一行和第二行上的落子不再得到任何重要的更新,这样这意味着没有学习。一般来说,你想确保很少观察到的模式仍然得到足够大的更新,而频繁使用的模式收到越来越小的更新。
要解决设置由全局学习率引起的问题,您可以使用自适应梯度的技术。我们将向你们展示两种方法:Adagrad 和Adadelta
在Adagrad中,没有全局学习率,您可以调整每个参数的学习率。当你有很多数据时,Adagrad可以工作得很好,而且数据中的模式很少能找到。这些标准都非常适用于我们的情况:你虽然有很多数据,但专业的围棋对局是非常复杂,以至于某些落子组合很少出现在你的数据集中。
假设你有一个长度为l的权重向量W(在这里更容易想到向量,但这种技术也更普遍地适用于张量),其中单独的分量设为![]() 。对于这些参数给定梯度]W,在学习速率为a的普通SGD中,每个Wi的更新规则如下:
。对于这些参数给定梯度]W,在学习速率为a的普通SGD中,每个Wi的更新规则如下:
![]()
在Adagrad中,您用一个东西替换α,它可以通过查看你过去更新了多少Wi来动态适应每个索引i。事实上,在Adagrad中,个人的学习率是与先前的更新成正比的。更准确地说,在Adagrad,您更新参数如下:
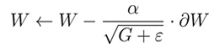
在这个式子中,ε是一个很小的正值,以确保分母不为0,而GI是到这一点平方梯度Wi的总和。我们把这个写成Gi,是因为你可以看到它作为长度为l的平方矩阵G的一部分,其中所有对角线项Gj都有我们刚才描述的形式,所有非对角线项都是0,因此这种形式的矩阵叫做对角矩阵。每次参数更新后,通过向对角线上元素添加最新的梯度来更新G矩阵,但如果您想将此更新规则写成简洁的形式使其独立于索引i,式子如下
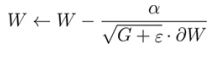
请注意,由于G是一个矩阵,您需要在每个分量Gi中添加ε,并将α除以每个分量。此外,用G.]W表示G与W的矩阵乘法。使用此优化器创建模型的工作如下。
from keras.optimizers import Adagrad
adagrad = Adagrad()与其他SGD技术相比,Adagrad的一个关键好处是你不必手动设置学习速率。事实上,您可以通过使用Adagrad(lr=0.02)来改变Keras的初始学习率,但不建议这样做
7.5.3.利用Adadelta精炼自适应梯度
一个类似于Adagrad的优化器是Adadelta。在这个优化器中,G矩阵中不是累积所有过去的(平方)梯度,而是使用我们的动量技术,只保留上次更新的一小部分,并将当前梯度添加到它上面:
![]()
虽然这个想法大致是在Adadelta发生的事情,但使这个优化器工作的细节在这里讲有点太复杂了。我们建议你查看原始文件以了解更多细节(https://arxiv.org/abs/1212.5701)
在keras中,你要这样使用Adadelta优化器:
from keras.optimizers import Adadelta
adadelta = Adadelta()与随机梯度下降(SGD)相比,Adagrad和Adadelta都对围棋数据上的深层神经网络训练非常有益。在后面的章节中,您将经常使用其中一个作为模型的优化器。
7.6运行你自己的示例并评估表现
在第5章、第6章和这一章中,我们向您展示了许多深度学习技术。我们给了你一些作为基线的提示和示例架构,但是现在是时候训练你的自己的模型了。在机器学习实验中,至关重要的是尝试各种超参数组合,如层数、选择哪一层、训练的轮数等等。特别是,有了深度神经网络,你面临的选择数量可能是很大的,并不总是那么清楚如何调整一个特定的参数去影响模型的性能。深度学习研究员可以依靠几十年实验结果和进一步的理论论点拥有一些直觉,但我们不能给你提供这么深层次的知识,不过我们可以帮助你开始建立自己的直觉。
像我们这样的实验装置要取得很好的结果的一个关键因素是尽可能快速地训练一个神经网络去预测围棋的落子。建立模型架构、开始模型训练、观察和评估性能指标所需的时间,然后回去调整模型和重新开始的过程时间必须都要短。当你看到数据科学的挑战,比如kaggle.com上的那些挑战时,往往是那些尝试最多的团队赢得了胜利。你真幸运,keras可以快速建立示例那样。这也是我们选择它作为本书的深度学习框架的主要原因之一。
7.6.1.测试体系结构和超参数的指南
让我们看看构建落子预测网络时的一些实际考虑:
- 卷积神经网络是围棋落子预测网络的一个很好的选择。如果只使用Dense层将导致较低的预测质量。建立一个由几个卷积层和一个或两个Dense层组成的网络通常是必须的。在后面的章节中,您将看到更复杂的体系结构,但是目前,就使用卷积网络。
- 在你的卷积层中,改变卷积核大小,看看这种变化是如何影响的模型性能。一般来说,2到7之间的卷积核大小是合适的,你不应该比这个大得多。
- 如果您使用池化层,请确保同时使用max和average池,但更重要的是,不要选择太大的池尺寸。在你的情况下,一个实际的上限可能是(3,3)。您可能还想尝试在没有池化层的情况下构建网络,其计算很耗时间,但可以达到很好的效果。
- 使用DRopout层进行正则化。在第六章中,您看到了如何使用Dropout来防止模型过度拟合。如果你不使用太多的Drought层,也不把Dropout rate设置得太高,那么你的网络通常会从中受益。
- 在最后一层使用softmax激活产生概率分布是有好处的,如果再将其与分类交叉熵损失相结合使用,这将非常适合您的用例。
- 用不同的激活函数进行实验。我们已经给你介绍了ReLU,这应该作为您现在的默认选择,还有Sigmoid激活。您可以在Keras中使用大量其他激活函数,如elu、selu、PReLU和Leaky ReLU。我们可以这里不讨论这些relu变体,但它们的用法在https://keras.io/activations/中找到很好的描述
- 变化的小训练集大小会对模型性能有影响。预测问题,如第五章的预测MNIST手写数字,通常建议选择与类数相同数量级的小训练集大小。对于MNIST,您经常会看到从10到50的训练集大小。如果数据是完全随机的,那么每个梯度都会从各个类接收信息,这使得SGD通常表现得更好。在我们的用例中,一些围棋落子比其他落子更频繁。例如,围棋的四个尖角很少会去下,特别是与星位相比。我们称之为数据中的类不平衡。在这种情况下,你不能指望一个小训练集,所有的类,应该使用从16到256不等的训练集。优化器的选择也会对你的网络有很大的影响,比如有或没有学习率衰减的SGD,以及Adagrad和Adadelta。在hhttps://keras.io/optimizers/下你会发现其他的优化器。
- 用来训练模型的轮数必须适当地选择。如果您使用模型检查点并跟踪每轮的各种性能指标,这样当训练停止时,你可以有效地测量。在本章的下一节也是最后一节中,我们将简要讨论如何评估性能指标。一般来说,拥有足够的计算能力,设置轮数太高而不是太低。如果模型训练停止改进,甚至会出现过度拟合而变得更糟
权重初始化
调整深层神经网络的另一个关键方面是如何在训练开始前初始化权值。因为优化网络意味着在损失表面找到最小损失值所需的权重,因此你开始的权重是很重要的。在第5章的网络实现中,我们随机分配初始权重,这通常是个不好的做法。
权重初始化是一个有趣的研究课题,值得书写一章。keras有很多权重初始化方案,每个有权重的层都可以进行相应的初始化,不过Keras默认选择通常是非常好的,因此不值得费心更改它们。
7.6.2.评估训练和测试数据的性能指标
在7.3节中,我们向您展示了在一个小数据集上执行训练运行的结果。我们使用的网络是一个相对较小的卷积网络,然后我们对这个网络进行了五轮的训练,接着我们跟踪训练数据的损失和准确性,并使用测试数据进行验证。最后,我们计算了测试数据的准确性。这就是你应该遵循的一般工作流程,但是你能判断什么时候应该停止训练或检测什么时候就应该关闭训练?以下是一些指导方针:
- 你的训练准确性和损失通常每过一轮都会提高。后面阶段,这些指标会逐渐减少,有时会有一些波动。如果你好几轮都看不到改善,你可能想停下来。
- 同时,您应该看看您的测试损失和准确性是什么样子的。在早期,验证损失会持续下降,但后来,经常会开始增加,这样就表示模型已经对训练数据过拟合了。
- 如果使用模型检查点,请选择高精度低损失的模型。
- 如果训练和测试损失都很高,请尝试选择更深层次的网络架构或其他超参数。
- 当你的模型训练误差较低,但验证误差较高,那说明已经出现了过拟合。当您有一个真正大的训练数据集时,通常不会发生此场景。去学习拥有17万围棋对局和数百万个落子的话,问题不是很大。
- 要选择一个符合硬件要求的训练数据大小。如果一轮的训练需要超过几个小时,那就不是很有趣了。相反,试着在许多中等规模的数据集上找到一个表现良好的模型,然后在尽可能大的数据集上再次训练这个模型。
- 如果你没有一个好的GPU,你可能想选择在云中训练你的模型。在附录D中,我们将向您展示如何使用AmazonWeb服务(AWS)用GPU训练模型。
- 当运行比较时,不要停止看起来初始阶段学习比较差的模型,因为有些模型适应的比较慢,后面可能会慢慢赶上,甚至超越。
您可能会问自己,您可以使用本章中介绍的方法构建多强的AI。理论上的上限是这样的:网络永远不会比你提供的数据要强。特别是,使用监督式学习之后,AI不会超过人类。在实践中,如果有足够的计算能力和时间,绝对有可能达到大约2段水平。
为了达到超越人类的游戏表现,你需要使用强化学习技术,在第9章中介绍了这一技术。然后,您可以结合第四章的树搜索、强化学习和监督深度学习,在第13章和第14章中构建更强的机器人。在下一章中,我们将向您展示如何部署一个机器人,并让它通过与人类对手或其他机器人打交道来与其环境进行交互。
7.7.总结
- 无处不在的智能游戏格式(SGF)可用于围棋和其他游戏记录。
- 可以并行处理围棋数据以获得更快速度和更有效的生成器。
- 有了强大的接近职业的游戏记录,你就可以建立起预测围棋落子的深度学习模型。
- 如果你知道你的训练数据的重要属性,你可以显式地将它们编码在特征平面上。然后,模型可以快速学习特征平面与你预测的结果之间的联系。对于围棋机器人,您可以添加一串棋子气的特征平面。
- 通过使用自适应梯度技术,你可以更有效地进行训练,如Adagrad或Adadelta。随着训练的进展,这些算法对学习速率进行了动态调整。
- 最终的模型训练可以在一个相对较小的脚本中实现,您可以使用它作为模板来训练你自己的AI。