人工智能期末考试复习
人工智能期末考试复习
-
-
- 选择题
-
- 1.1997年5月,闻名的“人机大战”,最终运算机以3.5比2.5的总比分将世界国际象棋棋王卡斯帕罗夫击败,这台运算机被称为( A )
- 2.下列不在人工智能系统的知识包含的4个要素中(D)
- 或图通常称为(D)
- 4. 不属于人工智能的学派是(B)
- 5.人工智能的含义最早由一位科学家于1950年提出,同时同时提出一个机器智能的测试模型,请问那个科学家是(C)
- 6.要想让机器具有智能,必须让机器具有知识。因此,在人工智能中有一个研究领域,要紧研究运算机如何自动猎取知识和技能,实现自我完善,这门研究分支学科叫( B)。
- 7.人工智能的目的是让机器能够____,以实现某些脑力劳动的机械化。
- 8. 盲人看不到一切物体,他们可以通过辨别人的声音识别人,这是智能的__B__方面。
- 9.连接主义认为人的思维基元是___B_。
- 10.第一个神经元的数学模型-MP模型是__A__年诞生的。
- 11.下列哪个不是人工智能的研究领域(D)
- 12.家用扫地机器人具有自动避障、清扫、自动充电等功能,这主要体现了信息技术中的(A)
- 填空题
- 知识点
-
- 人工智能是什么?
- AI是什么?
- 人工智能的三大学派
- 人工智能的分类
- 主要研究和应用领域有哪些?
- “图灵实验”是什么?具体解释实验过程
- 人工智能代表作品
- 人工智能与计算机的区别
- 知识表示法
- 状态空间法
- 问题归约法
- 谓词逻辑法 (Predicate Logic)
-
- 量词
- 连接词
- 示例
- 与或图表示
- 可解节点一般定义
- 不可解节点的一般定义
- 机器学习定义
- 机器学习的分类
- 机器学习的算法
- 神经网络的定义
- 神经元模型
- 神经网络的特点
- 神经网络的分类
-
- 网上说法
- ppt零散说法
- 前馈神经网络
- 反馈式神经网络
- 神经网络的构成
- 常用的激活函数
- 普遍神经网络的三层神经元分别是:
- 感知机模型概念
- BP神经网络
- 人工神经网络的基本功能
- 卷积的计算
- 代码
-
- KNN算法思想和步骤,电影分类的代码理解
- K-means的算法思想和代码解释
-
还是以ppt为主,因为这篇文章可能不全
选择题
1.1997年5月,闻名的“人机大战”,最终运算机以3.5比2.5的总比分将世界国际象棋棋王卡斯帕罗夫击败,这台运算机被称为( A )
A. 深蓝
B. IBM
C. 深思
D. 蓝天
2.下列不在人工智能系统的知识包含的4个要素中(D)
A. 事实
B. 规则
C. 操纵和元知识
D. 关系
或图通常称为(D)
A. 框架网络
B. 语义图
C. 博亦图
D. 状态图
4. 不属于人工智能的学派是(B)
A. 符号主义
B. 机会主义
C. 行为主义
D. 连接主义。
5.人工智能的含义最早由一位科学家于1950年提出,同时同时提出一个机器智能的测试模型,请问那个科学家是(C)
A. 明斯基
B. 扎德
C. 图灵
D. 冯.诺依曼
6.要想让机器具有智能,必须让机器具有知识。因此,在人工智能中有一个研究领域,要紧研究运算机如何自动猎取知识和技能,实现自我完善,这门研究分支学科叫( B)。
A. 专家系统
B. 机器学习
C. 神经网络
D. 模式识别
7.人工智能的目的是让机器能够____,以实现某些脑力劳动的机械化。
A. 具有完全的智能
B. 和人脑一样考虑问题
C. 完全代替人
D. 模拟、延伸和扩展人的智能
8. 盲人看不到一切物体,他们可以通过辨别人的声音识别人,这是智能的__B__方面。
A. 行为能力
B. 感知能力
C. 思维能力
D. 学习能力
9.连接主义认为人的思维基元是___B_。
A. 符号
B. 神经元
C. 数字
D. 图形
10.第一个神经元的数学模型-MP模型是__A__年诞生的。
A. 1943
B. 1958
C. 1982
D. 1986
11.下列哪个不是人工智能的研究领域(D)
A、机器证明
B、模式识别
C、人工生命
D、编译原理
12.家用扫地机器人具有自动避障、清扫、自动充电等功能,这主要体现了信息技术中的(A)
A、人工智能技术
B、网络技术
C、多媒体技术
D、数据管理技术
填空题
在谓词公式中,紧接于量词之后被量词作用的谓词公式称为该量词的 辖域 ,而在一个量词的辖域中与该量词的指导变元相同的变元称为 约束变元,其他变元称为 自由变元
人工神经网络属于反馈网络有 BP网络
ANN中文意义是 :人工神经网络
知识点
人工智能是什么?
一般解释:人工智能就是用 人工 的方法在机器(计算机)上实现的智能,或称机器智能
人工智能学科:从学科的角度来说,人工智能是一门研究 如何构造智能机器或智能系统,使之能模拟、延伸、扩展人类智能的学科
人工智能能力:从智能能力的角度来说,人工智能是智能机器所执行的通常与人类智能有关的智能行为,如判断、推理、证明、识别、感知、理解、通信、设计、思考、规划、学习和问题求解等思维活动
AI是什么?
AI:表示人工智能,即Artificial Intelligence,缩写为AI
人工智能是一门通过计算过程力图理解和模仿智能行为的学科
人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门技术科学
人工智能的三大学派
- 符号主义学派
- 连接主义学派
- 行为主义学派
人工智能的分类
- 领域人工智能
- 通用人工智能或跨领 域人工智能
- 混合增强人工智能
主要研究和应用领域有哪些?

“图灵实验”是什么?具体解释实验过程
1950年图灵提出了著名的“图灵测试”,一种测试机器是不是具备人类智能的方法。
测试主持人提出问题,机器和人同时回答,如果人类无法区分说明机器具有模仿人的能力,即智能。
例如这里连续问同一个问题,回答没有差异,我们会说像个机器人,不是人是机器一般,很机械,不应变
机器回答:
问:你会下国际象棋吗?
答:是的。
问:你会下国际象棋吗?
答:是的。
问:请再次回答,你会下国际象棋吗?
答:是的。
人回答:
问:你会下国际象棋吗?
答:是的。
问:你会下国际象棋吗?
答:是的,我不是已经说过了吗?
问:请再次回答,你会下国际象棋吗?
答:你烦不烦,干嘛老提同样的问题
人工智能代表作品
IBM“深蓝”
AlphaGo
人工智能与计算机的区别
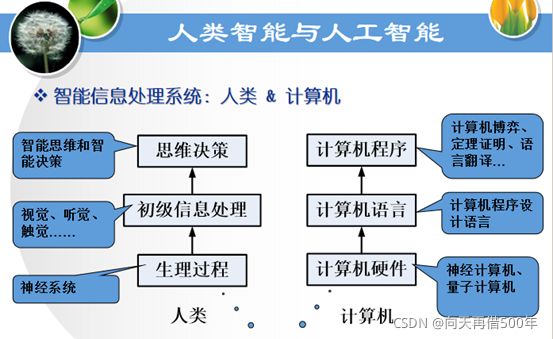
知识表示法
状态空间法,问题规约法,谓词逻辑法,语义网络法
状态空间法

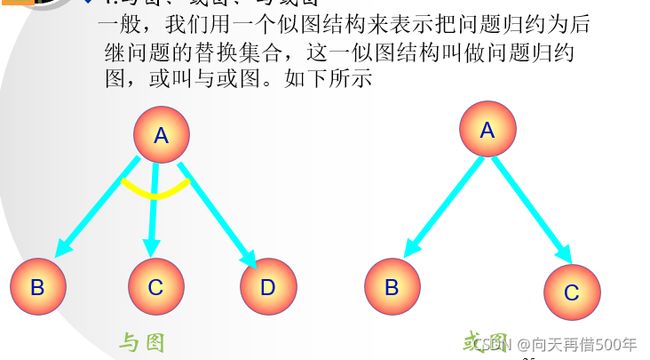
问题归约法
我的理解就是递归
先把问题分解为子问题及子-子问题,然后解决较小的问题。对该问题的某个具体子集的解答就意味着对原始问题的一个解答
谓词逻辑法 (Predicate Logic)
逻辑语句:一种形式语言,它能够把逻辑论证符号化,并用于证明定理,求解问题。
形式语言:严格地按照相关领域的特定规则,以数学符号(符号串)形式描述该领域有关客体的表达式
量词
“对全额的”、“对任意的”等词在逻辑中被称为全称量词,记作“∀”

“存在一个”、“至少一个”等词在逻辑中被称为**存在量词**,记作“∃”

连接词
与、合取(conjunction):用连词∧把几个公式连接起来而构成的公式

或、析取(disjunction):用连词∨把几个公式连接起来而构成的公式
![]()
蕴涵(Implication):“=>”表示“如果—那么”(IF—THEN)关系,其所构成的公式叫做蕴涵。
非(Not)表示否定,~、—均可表示

示例



与或图表示
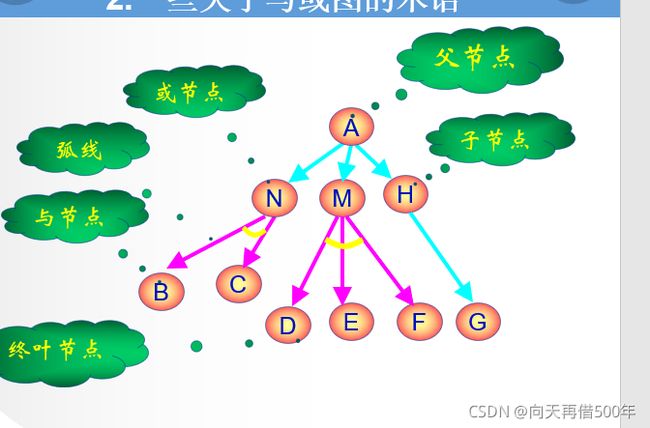

可解节点一般定义
终叶节点是可解节点(因为它们与本原问题相关连)。:
如果某个非终叶节点含有或后继节点,那么只要当其后继节点至少有一个是可解的时,此非终叶节点才是可解的。
如果某个非终叶节点含有与后继节点,那么只有当其后继节点全部为可解时,此非终叶节点才是可解的
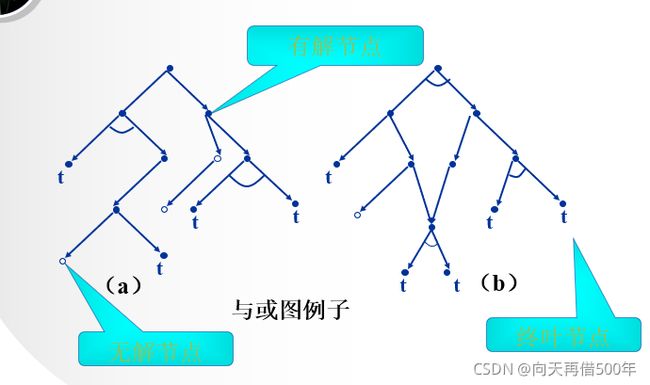
不可解节点的一般定义
没有后裔的非终叶节点为不可解节点。
全部后裔为不可解的非终叶节点且含有或后继节点,此非终叶节点才是不可解的。
后裔至少有一个为不可解的非终叶节点且含有与后继节点,此非终叶节点才是不可解的
机器学习: machine learning
机器学习定义
机器学习就是用算法解析数据,不断学习,对世界中发生的事做出判断和预测的一项技术

机器学习的分类
- 监督式学习
- 无监督式学习
- 半监督式学习
- 强化学习
监督学习,输入数据被称为训练数据,每组训练数据有一个明确的标识或结果
无监督学习,数据并不被特别标识,学习模型是为了推出数据的一些内在结构
监督学习和无监督学习的区别:训练集目标是否被标注
强化学习的本质是自动进行决策,并且可以连续决策
机器学习的算法
- KNNK近邻算法
- 决策树
- 朴素贝叶斯分类
- 逻辑回归
- 支持向量机
- KMeans
- 神经网络
神经网络的定义

神经元模型

神经网络的特点
- 类神经网络是模式识别和误差最小化的过程,在每一次经验中提取和学习信息。
- 类神经网络可以处理连续型和类别型的数据,对数据进行预测。
- 神经网络是有监督学习。
- 神经网络可以构建成非线性的模型,模型的精确度高
- 神经网络有良好的推广性,对于未知的输入亦可得到正确的输出。
- 类神经网络可以接受不同种类的变量作为输入,适应性强。
- 神经网络可应用的领域相当广泛,模型建构能力强。
- 神经网络具模糊推论能力,允许输出入变量具模糊性,归纳学习较难具备此能力
神经网络的分类
这一点ppt上没找到我网上找的
网上说法
按性能分:连续型和离散型网络,或确定型和随机型网络。
按拓扑结构分:前向网络和反馈网络。
按学习方法分:有监督的学习网络和无监督的学习网络
ppt零散说法
前馈神经网络,反馈神经网络,卷积神经网络,循环神经网络
前馈神经网络
前馈神经网络是指信息只朝一个方向流动,也就是数据在神经元之间的流动方向是单向的,没有循环。
这种网络而在分类过程中数据只能向前传送,直到到达输出层,层间没有向后的反馈信号,因此被称为前馈网络
感知机网络,卷积网络是前馈神经网络
反馈式神经网络
反馈式神经网络是指数据在神经元之间的流动方向是双向关系,神经元会输出到其他所有的神经元,也会接收其他神经元的输出成为输入
bp网络是反馈神经网络
神经网络的构成

常用的激活函数
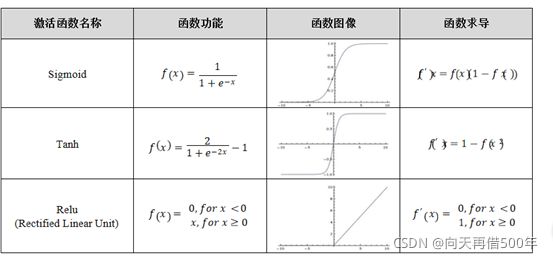


普遍神经网络的三层神经元分别是:
输入层、隐藏层、输出层,为了是模型的精度更高可以增加隐藏层的层数
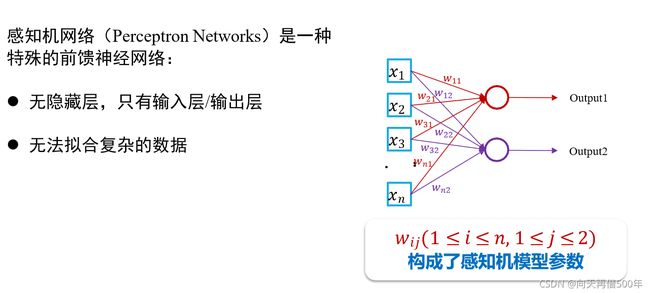
感知机模型概念
感知机网络(Perceptron Networks)是一种 特殊的前馈神经网络:无隐藏层,只有输入层和输出层无法拟合复杂结构
BP神经网络
BP算法是一种将输出层误差反向传播给隐藏层进行参数更新的方法。
将误差从后向前传递,将误差分摊给各层所有单元,从而获得各层单元所产 生的误差,进而依据这个误差来让各层单元负起各自责任、修正各单元参数

人工神经网络的基本功能
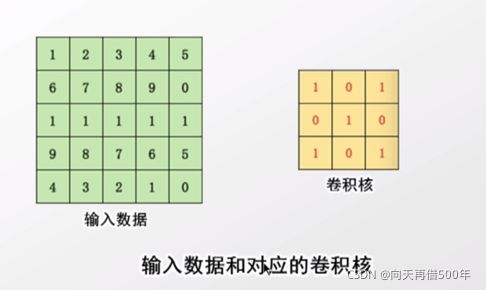
卷积的计算
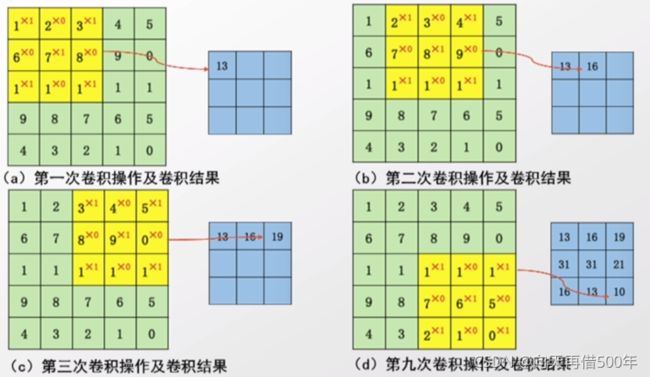
代码
KNN算法思想和步骤,电影分类的代码理解
KNN(k-NearestNeighbor)又被称为近邻算法,它的核心思想是:物以类聚,人以群分。假设一个未知样本数据x需要归类,总共有N个类别,那么离x距离最近的有k个邻居,这k个邻居里最多类别的就认为是样本X的类别,也就是说x的类别完全由邻居来推断出来。
所以我们可以总结出其算法步骤为:
1、计算测试对象到训练集中每个对象的距离
2、按照距离的远近排序
3、选取与当前测试对象最近的k的训练对象,作为该测试对象的邻居
4、统计这k个邻居的类别频率
5、k个邻居里频率最高的类别,即为测试对象的类别
我们可以简化为:找邻居 + 投票决定


K-means的算法思想和代码解释
K-Means算法的思想很简单,对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
kmeans算法流程
1)随机选取k个点作为初始质心/种子点(这k个点不一定属于数据集,k个点就代表有k类)
2)分别计算每个数据点到k个质心点的距离,离哪个质心点最近,就属于哪类
3)重新计算k个质心点的坐标(简单常用的方法是求坐标值的平均值作为新的坐标值)
4)重复2、3步,直到质心点坐标不变或者循环次数完成