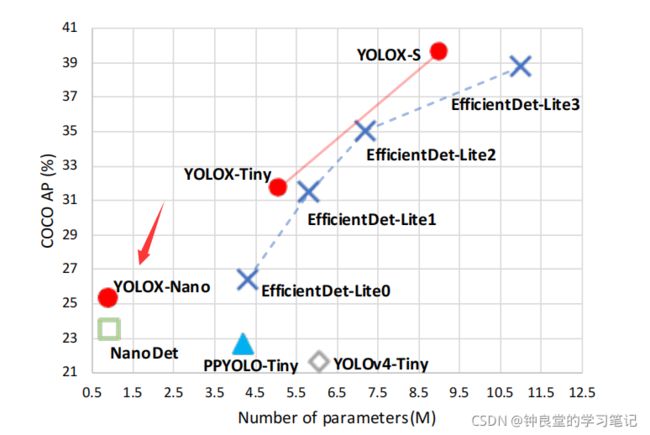
yolox_nano训练和NCNN安卓部署总结(自己的数据集)
yolox_nano模型的参数量极小,并且有着一定的准确度而被使用到手机端的yolox部署:
yolox_nano训练命令:
python tools/train.py -f exps/example/yolox_voc/yolox_voc_nano.py -d 1 -b 8 -c weights/yolox_nano.pth
yolox_nano.pth是官网下载的coco数据集的权重文件来做完这个预训练权重(我发现使用之前训练过的yolox_nano.pth其实也是可以的,这个不是主要问题,重要的是yolox_voc_nano.py这个文件需要好好改,如果改的有问题,就会之后转onnx文件的时候有错误:Missing key(s) & Unexpected key(s) in state_dict…)。
这里需要注意:
-f exps/example/yolox_voc/yolox_voc_nano.py
中的
yolox_voc_nano.py
代码如下:
(在.\exps\default\nano.py和.\exps/example/yolox_voc/yolox_voc.py基础上修改,也就是把nano.py的init函数和get_model复制粘贴到yolox_voc.py里,修改修改类别数 self.num_classes 还有image_sets,最后把名字变成yolox_voc_nano.py文件就行)
# encoding: utf-8
import os
import torch
# 需要加上这个
import torch.nn as nn
import torch.distributed as dist
from yolox.data import get_yolox_datadir
from yolox.exp import Exp as MyExp
class Exp(MyExp):
def __init__(self):
super(Exp, self).__init__()
# 修改网络深度和宽度
self.depth = 0.33
self.width = 0.25
self.input_size = (416, 416)
self.mosaic_scale = (0.5, 1.5)
self.random_size = (10, 20)
self.test_size = (416, 416)
self.exp_name = os.path.split(os.path.realpath(__file__))[1].split(".")[0]
self.enable_mixup = False
# 修改类别数
self.num_classes = 1
# 之前没有加上这个get_model函数,就训练有问题
def get_model(self, sublinear=False):
def init_yolo(M):
for m in M.modules():
if isinstance(m, nn.BatchNorm2d):
m.eps = 1e-3
m.momentum = 0.03
if "model" not in self.__dict__:
from yolox.models import YOLOX, YOLOPAFPN, YOLOXHead
in_channels = [256, 512, 1024]
# NANO model use depthwise = True, which is main difference.
backbone = YOLOPAFPN(self.depth, self.width, in_channels=in_channels, depthwise=True)
head = YOLOXHead(self.num_classes, self.width, in_channels=in_channels, depthwise=True)
self.model = YOLOX(backbone, head)
self.model.apply(init_yolo)
self.model.head.initialize_biases(1e-2)
return self.model
def get_data_loader(self, batch_size, is_distributed, no_aug=False, cache_img=False):
from yolox.data import (
VOCDetection,
TrainTransform,
YoloBatchSampler,
DataLoader,
InfiniteSampler,
MosaicDetection,
worker_init_reset_seed,
)
from yolox.utils import (
wait_for_the_master,
get_local_rank,
)
local_rank = get_local_rank()
with wait_for_the_master(local_rank):
dataset = VOCDetection(
data_dir=os.path.join(get_yolox_datadir(), "VOCdevkit"),
# image_sets=[('2007', 'trainval'), ('2012', 'trainval')],
# 训练的时候只有VOC2007的数据集,所以需要改这里
image_sets=[('2007', 'trainval')],
img_size=self.input_size,
preproc=TrainTransform(
max_labels=50,
flip_prob=self.flip_prob,
hsv_prob=self.hsv_prob),
cache=cache_img,
)
dataset = MosaicDetection(
dataset,
mosaic=not no_aug,
img_size=self.input_size,
preproc=TrainTransform(
max_labels=120,
flip_prob=self.flip_prob,
hsv_prob=self.hsv_prob),
degrees=self.degrees,
translate=self.translate,
mosaic_scale=self.mosaic_scale,
mixup_scale=self.mixup_scale,
shear=self.shear,
enable_mixup=self.enable_mixup,
mosaic_prob=self.mosaic_prob,
mixup_prob=self.mixup_prob,
)
self.dataset = dataset
if is_distributed:
batch_size = batch_size // dist.get_world_size()
sampler = InfiniteSampler(
len(self.dataset), seed=self.seed if self.seed else 0
)
batch_sampler = YoloBatchSampler(
sampler=sampler,
batch_size=batch_size,
drop_last=False,
mosaic=not no_aug,
)
dataloader_kwargs = {
"num_workers": self.data_num_workers, "pin_memory": True}
dataloader_kwargs["batch_sampler"] = batch_sampler
# Make sure each process has different random seed, especially for 'fork' method
dataloader_kwargs["worker_init_fn"] = worker_init_reset_seed
train_loader = DataLoader(self.dataset, **dataloader_kwargs)
return train_loader
def get_eval_loader(self, batch_size, is_distributed, testdev=False, legacy=False):
from yolox.data import VOCDetection, ValTransform
valdataset = VOCDetection(
data_dir=os.path.join(get_yolox_datadir(), "VOCdevkit"),
image_sets=[('2007', 'test')],
img_size=self.test_size,
preproc=ValTransform(legacy=legacy),
)
if is_distributed:
batch_size = batch_size // dist.get_world_size()
sampler = torch.utils.data.distributed.DistributedSampler(
valdataset, shuffle=False
)
else:
sampler = torch.utils.data.SequentialSampler(valdataset)
dataloader_kwargs = {
"num_workers": self.data_num_workers,
"pin_memory": True,
"sampler": sampler,
}
dataloader_kwargs["batch_size"] = batch_size
val_loader = torch.utils.data.DataLoader(valdataset, **dataloader_kwargs)
return val_loader
def get_evaluator(self, batch_size, is_distributed, testdev=False, legacy=False):
from yolox.evaluators import VOCEvaluator
val_loader = self.get_eval_loader(batch_size, is_distributed, testdev, legacy)
evaluator = VOCEvaluator(
dataloader=val_loader,
img_size=self.test_size,
confthre=self.test_conf,
nmsthre=self.nmsthre,
num_classes=self.num_classes,
)
return evaluator
修改过后,就可以开始训练yolox_nano了:
yolox_nano训练命令:
python tools/train.py -f exps/example/yolox_voc/yolox_voc_nano.py -d 1 -b 8 -c weights/yolox_nano.pth
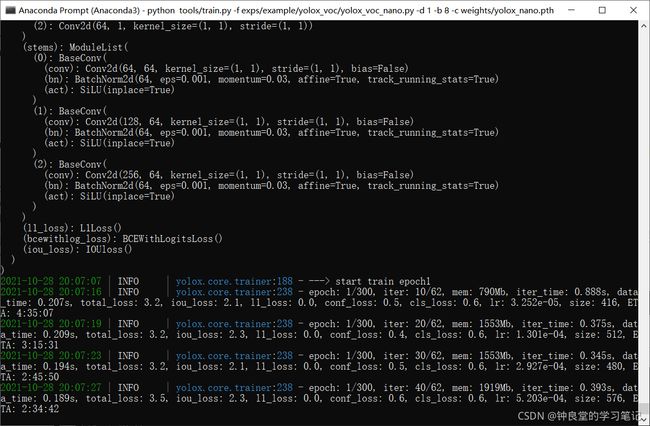
这里我没有使用混合精度训练,原因如下博客所示:
https://blog.csdn.net/ELSA001/article/details/120918082?spm=1001.2014.3001.5502
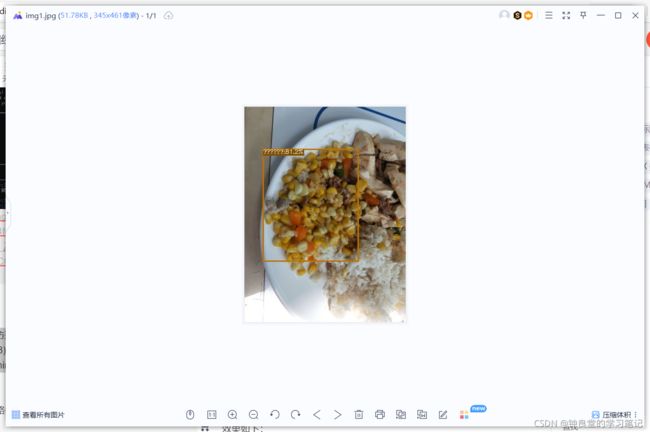
训练结束之后测试一下:
python tools/demo.py image -f exps/example/yolox_voc/yolox_voc_nano.py -c YOLOX_outputs/yolox_voc_nano/best_ckpt.pth --path testfiles/img1.jpg --conf 0.3 --nms 0.65 --tsize 640 --save_result --device cpu
效果如下:

接下来生成onnx文件(YOLOX路径下执行):
python tools/export_onnx.py -n yolox-nano -c weights/yolox_nano.pth --output-name weights/yolox_nano.onnx
yolox_nano.pth文件是训练好的best_ckpt.pth改了名字得来的
效果如下:

(torch_G) E:\YOLOX>python tools/export_onnx.py -n yolox-nano -c weights/yolox_nano.pth --output-name weights/yolox_nano.onnx
2021-10-28 21:45:50.843 | INFO | __main__:main:59 - args value: Namespace(batch_size=1, ckpt='weights/yolox_nano.pth', dynamic=False, exp_file=None, experiment_name=None, input='images', name='yolox-nano', no_onnxsim=False, opset=11, opts=[], output='output', output_name='weights/yolox_nano.onnx')
2021-10-28 21:45:51.001 | INFO | __main__:main:83 - loading checkpoint done.
2021-10-28 21:45:56.211 | INFO | __main__:main:96 - generated onnx model named weights/yolox_nano.onnx
2021-10-28 21:45:56.773 | INFO | __main__:main:112 - generated simplified onnx model named weights/yolox_nano.onnx
loading checkpoint done这个过程可能会比较久。
接下来就是导出ncnn文件:
拷贝yolox_nano.onnx文件到E:\ncnn\build-vs2019\tools\onnx文件下
同时也使用命令行到E:\ncnn\build-vs2019\tools\onnx目录下:

使用命令生成ncnn相应的param和bin文件:
onnx2ncnn.exe yolox_nano.onnx yolox_nano.param yolox_nano.bin

这里输出了很多Unsupported slice step !也没关系,后面可以改的,主要是因为ncnn不支持Focus模块,会有警告。
修改yolox_nano.param文件:
把 295修改为295 - 9 = 286 (由于我们将删除 10 层并添加 1 层,因此总层数应减去 9)。
然后从 Split 到 Concat 删除 10 行代码,但记住Concat一行最后倒数第二个数字:683。
在输入后添加 YoloV5Focus 层(使用之前的数字 683):
YoloV5Focus focus 1 1 images 683
这里需要注意,里面的空格需要一个个慢慢敲的,可以使用Netron软件来看看:
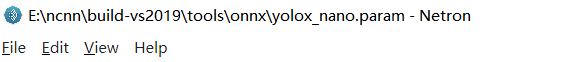
修改之后是这样的:
7767517
286 328
Input images 0 1 images
YoloV5Focus focus 1 1 images 683
Convolution Conv_41 1 1 683 1177 0=16 1=3 11=3 2=1 12=1 3=1 13=1 4=1 14=1 15=1 16=1 5=1 6=1728
....
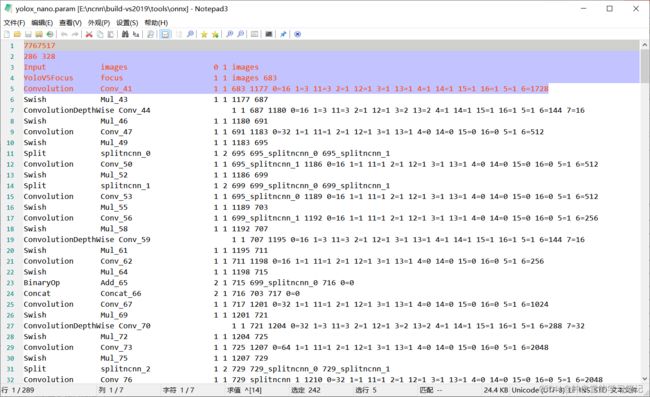
yolox_nano.param修改之后使用Netron软件来看的效果如下:

这样就算是成功修改了!
使用ncnn_optimize优化ncnn文件:
产生新的param和bin文件:
在E:\ncnn\build-vs2019\tools路径下执行(先拷贝yolox_nano.bin和yolox_nano.param文件到此路径下)
ncnnoptimize.exe yolox_nano.param yolox_nano.bin yolox_nano.param yolox_nano.bin 65536
(torch_G) E:\ncnn\build-vs2019\tools\onnx>cd ..
(torch_G) E:\ncnn\build-vs2019\tools>ncnnoptimize.exe yolox_nano.param yolox_nano.bin yolox_nano.param yolox_nano.bin 65536
create_custom_layer YoloV5Focus
fuse_convolution_activation Conv_314 Sigmoid_330
fuse_convolution_activation Conv_328 Sigmoid_329
fuse_convolution_activation Conv_347 Sigmoid_363
fuse_convolution_activation Conv_361 Sigmoid_362
fuse_convolution_activation Conv_380 Sigmoid_396
fuse_convolution_activation Conv_394 Sigmoid_395
model has custom layer, shape_inference skipped
model has custom layer, estimate_memory_footprint skipped
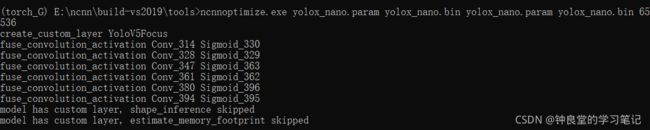
这样就算是把ncnn文件优化完成了。
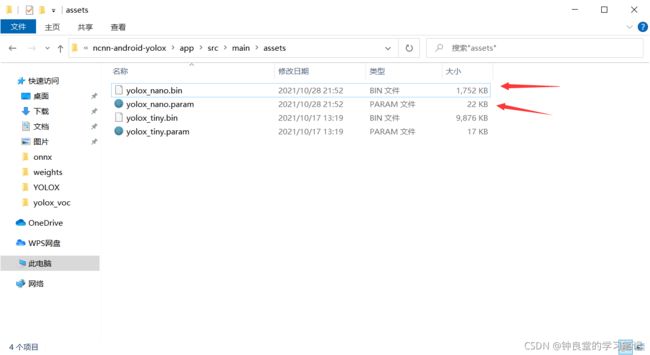
之后在Android studio上面使用build.gradle来自动编译yolox的安卓文件。
编译结束之后,把刚刚优化之后的yolox_nano.param和yolox_nano.bin放在这个assets目录下:
E:\AndroidStudioProjects\ncnn-android-yolox\app\src\main\assets
最后,我们只需要修改cpp目录下的yolox.cpp和yoloxncnn.cpp的class_names数组就行:
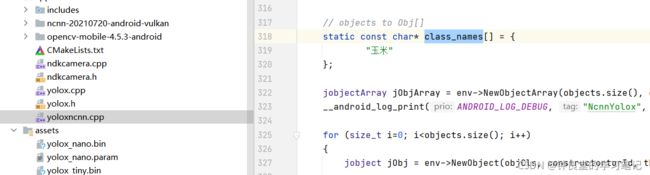
点击运行即可检测:


但是这个检测还是有问题的,就是我没办法识别高分辨率的图片和视频,只能识别我喂入神经网络来训练的图片的低分辨率的图片,不过最终还是检测出来了,还是很开心的。