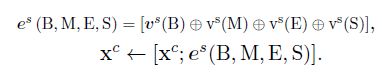NER中的词汇增强方法(LatticeLSTM、CGN、FLAT、Simple-Lexicon)
文章目录
-
- NER中的词汇增强方法
- Dynamic Architecture
-
- LatticeLSTM
- MGLatticeLSTM
- LR-CNN
- CGN
- FLAT
- Adaptive Embedding
-
- Simple-Lexicon
NER中的词汇增强方法
虽然基于字符的NER系统通常好于基于词汇(经过分词)的方法,但基于字符的NER没有利用词汇信息,而词汇边界对于实体边界通常起着至关重要的作用。
如何在基于字符的NER系统中引入词汇信息,是近年来NER的一个研究重点。这种在NER任务中引入词汇的方法又被称为词汇增强。从另一个角度看,由于NER标注数据资源的稀缺,BERT等预训练语言模型在一些NER任务上表现不佳。特别是在一些中文NER任务上,词汇增强的方法会好于或逼近BERT的性能。因此,词汇增强方法在中文NER任务很有必要。
词汇增强也可以看做是一种融入外部知识库的方法,传统的NER方法都是在挖掘输入文本中特征,比如词性、上下位字符、依存关系等等,而词汇增强则通过外部的词典,加入了不能从文本中直接挖掘出来的信息。在可预见的未来,信息抽取等多个NLP领域,融入外部知识库都会是一个重点的研究方向。
词汇增强方法根据融合词汇信息的方式不同又可以分为动态框架和自适应编码两种主要方式:
- Dynamic Architecture:设计一个动态框架,能够兼容词汇输入。例如Lattice LSTM,通过更改LSTM的结构动态的融入词汇信息
- Adaptive Embedding :基于词汇信息,构建自适应Embedding,在编码的过程中,融入词汇信息
Dynamic Architecture
LatticeLSTM
论文:Chinese NER Using Lattice LSTM(ACL18)
在bert出现之前的中文NER任务中,以字符还是以词汇作为输入单元是一个很难选择的问题。如果以词作为输入单元,一旦出现分词错误,就会直接影响实体边界的预测,导致识别错误,这在开放领域是很严重的问题。以字符作为输入单元的方法优于基于词的方法,但是由于没有进行分词,基于字符的方法无法利用句子中的单词信息,这也会使得识别效果有瑕疵。举个例子,比如一句话“南京市长江大桥”,如果没有单词信息,识别结果很可能为:“南京“、”市长”、“江大桥”,而正确的结果应该是“南京市“、“长江大桥”。
为了解决上述问题,论文提出了LatticeLSTM模型,该模型的核心思想是:通过 Lattice LSTM 将潜在的词汇信息融合到基于字符的 LSTM结构中。如下图所示,LatticeLSTM更改了LSTM的结构,在编码字符“市”的时候,加入了词汇“南京市”的信息,这样在进行实体识别的时候,模型就不会倾向于把“南京市”三个字分开。
LatticeLSTM通过更改LSTM的结构实现词汇信息的融入,这是一种非常典型的动态结构方法。在训练之前,需要做一个预处理过程,将输入文本和外部词表进行匹配,识别输入文本中的所有词汇,然后在训练过程中,LatticeLSTM会根据词汇的跨度信息,动态的改变LSTM结构将词汇信息融入该词汇的最后一个字符中。
LatticeLSTM的缺点:
- 计算性能低下,不能batch并行化。究其原因主要是每个字符之间增加的 word cell(看作节点)数目不一致,有的字符可能会融入多个词汇的信息,而有的词汇则不会融入词汇信息。
- 信息损失:对于一个词,只有词的末尾的那个字符会融入词汇的信息,如上图中,只有字符“市”在编码的过程中会融入“南京市”的词汇信息,其他字符“南”、“京”没有融入词汇信息。
- 可迁移性差:只适用于LSTM,不具备向其他神经网络如CNN等迁移的能力。
MGLatticeLSTM
论文:Chinese Relation Extraction with Multi-Grained Information and External Linguistic Knowledge(ACL19)
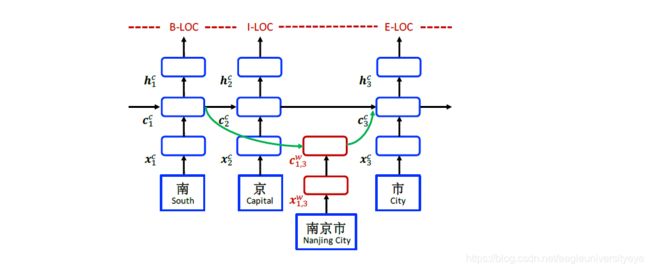
这篇论文和LatticeLSTM的结构差不多,对LSTM结构的改进方式是一样的,所以和LatticeLSTM有一样的缺点。MGLatticeLSTM的主要创新点在于引入了多义词。LatticeLSTM只能融入词汇的一种表示,但是中文词汇是存在多义词的,相同的词汇可能有不同的含义,如果在引入词汇的过程中引入了不正确的词义信息,那么可能会导致原本只使用字符作为输入就能正确分词的句子,在引入错误词义后导致分词出现错误。
MGLatticeLSTM为了解决这个问题,在融入词汇信息的过程中使用注意力机制将词汇所有的词义信息通过注意力进行整合,然后在加入进字符编码中。MGLatticeLSTM可以算作是对LatticeLSTM的补充。
LR-CNN
论文:CNN-Based Chinese NER with Lexicon Rethinking(IJCAI-19)
LR-CNN论文中首先提出了LatticeLSTM的不足
- 效率限制: 基于RNN的模型由于循环结构的限制无法进行并行训练
- 词汇冲突问题: 当句子中的某个字符同时出现在多个词汇中时,基于RNN的模型难以对此做出判断。例如,下图中的"长"即属于"市长"一词,也属于"长隆"一词,那么如何给字符“长”分配标签就成了问题,到底是应该按“市长”来分词,还是应该按“长隆”来分词。
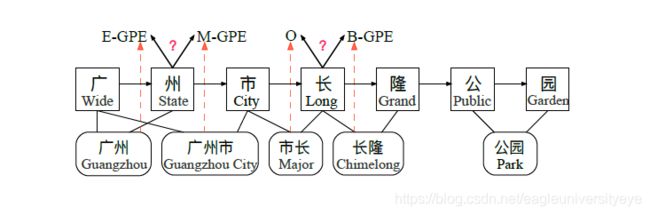
针对RNN不能并行化训练的问题,LR-CNN改用CNN来作为编码层。针对词汇冲突问题,LR-CNN提出了一种Rethinking机制。LR-CNN的模型结构如下图所示:
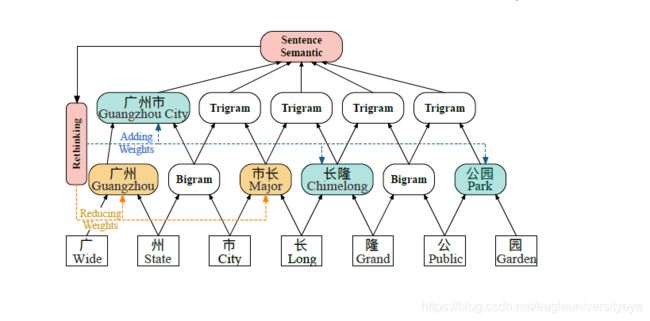
LR-CNN采取CNN对字符特征进行编码,采用不同的感受野提取特征。将获得的multi-gram信息堆叠多层,采取注意力机制进行融合;对于词汇信息冲突问题,LR-CNN增加了一个feedback layer来调整词汇信息的权重,具体地,将高层特征作为输入通过注意力模块调节下层词汇特征分布。如上图,高层特征得到的 “广州市 “和 “长隆 “会降低 “市长 “ 在输出特征中的权重,通过注意力的方式进行调节,解决词汇信息冲突问题。
CGN
论文:Leverage Lexical Knowledge for Chinese Named Entity Recognition via Collaborative Graph Network(EMNLP19)
CGN论文提出外部词汇实际包含了两种重要信息: 一是词语的边界信息, 二是词语的语义信息。在LatticeLSTM中,词汇信息只融入词汇的最后一个字符中,句子中其他字符没有融合词汇的信息,这样的结果是对词汇信息的利用效率低下。词汇中的字符不能利用词汇的边界信息,上下文字符不能利用词汇的语义信息。
CGN相对于之前的词汇增强方法,主要有两点改进:
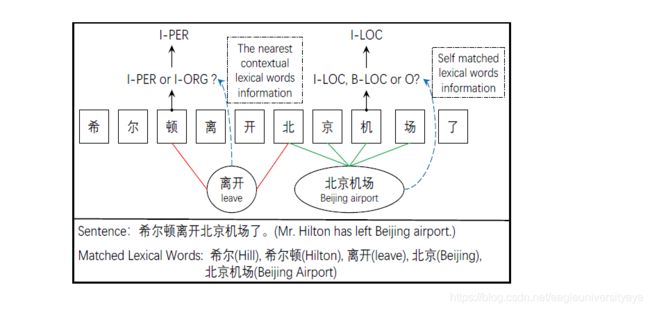
- 将词汇信息融合进词汇的每一个字符中,以利用好词汇的边界信息。如下图中“北京机场”的例子,如果字符“机”能够获取到“北京机场”这个词汇的边界信息,那么在进行标签分类时字符“机”就不会被错误标注为标签”B-LOC“或者标签“O”
- 通过GAN图注意力网络将词汇信息融合进上下文的字符中。如下图“离开”的例子,如果将词汇“离开”的语义信息融合进上下文字符“顿”和”北“中,那么在对字符“顿”进行标签分类时,模型可以识别出希尔顿是一个PER,那么自然地,顿的标签就是I-PER而不是I-ORG或者其他。
CGN是一种基于字符的协作图网络,该网络包含编码层、图网络层、融合层、解码层。图网络层包含C-graph、T-graph和L-graph三个不同结构的图,图网络层的结果由三种图经过图注意力网络计算后的结果拼接而成。整体结构及C-graph、T-graph和L-graph三种图的构建方式如下图所示:
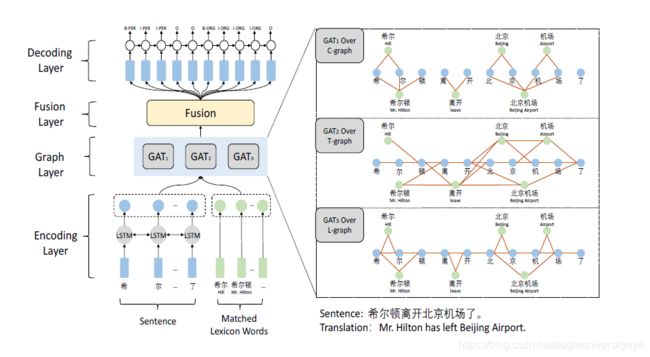
图网络层三种不同结构的图的构建方式:
- C-graph:字符与字符之间无连接,词汇与词汇中的的字符之间有连接,这个图的目的是为了将词汇的边界信息和词义信息融合进字符(词汇内部)中。
- T-graph:相邻字符相连接,词与其前后字符连接,将距离字符最近的上下文匹配词的词义信息融合进字符中。
- L-graph:相邻字符相连接,词与其开始结束字符相连。将LatticeLSTM结构转变为了图结构。
图构建完成后,使用图注意力网络GAN进行计算,每个GAN的输入是节点特征表示 N o d e = f 1 , f 2 , . . . , f n Node=f_1,f_2,...,f_n Node=f1,f2,...,fn及对应的邻接矩阵, 输出是节点表示的更新
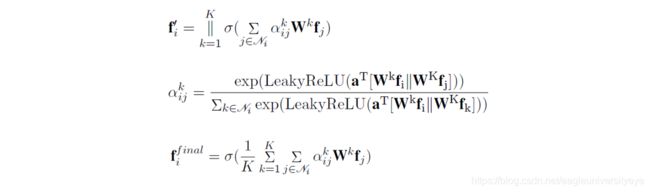
融合层将图网络层的三个图所得的字符节点的表示进行融合。融合层的输入是编码层通过BiLSTM编码得到的字符表示 H H H和三个GAT图得到的字符表示 Q 1 , Q 2 , Q 3 Q_1,Q_2,Q_3 Q1,Q2,Q3, 通过如下方法进行融合:
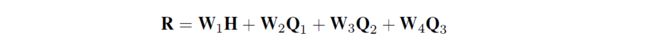
FLAT
论文:FLAT: Chinese NER Using Flat-Lattice Transformer(ACL20)
FLAT使用Transformer代替LSTM,设计position encoding来融合词汇信息.
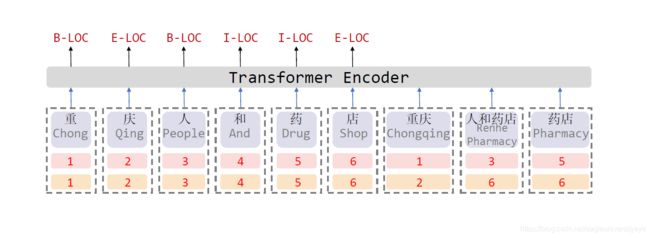
如上图所示,对于每一个字符和词汇都构建一个head position encoding 和 tail position encoding,分别表示词或者字的开始及结束位置。Transformer在更新每个token的表示时会使用上下文所有token的表示,通过自注意力机制决定对每个token的关注程度的大小。因此,FLAT可以直接建模字符与所有匹配的词汇信息间的交互,例如,字符“药”可以匹配词汇“人和药店”和“药店”,因为字符“药”的开始和结束位置都是5,而“人和药店”和“药店”的跨度都包含了位置5,在Transformer编码的过程中,字符“药”会分配更多的注意力在词汇“人和药店”和“药店”上。
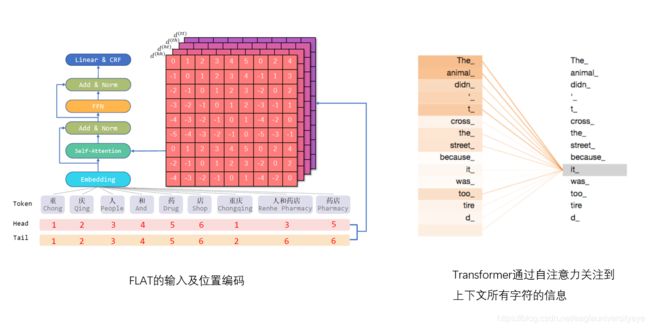
FLAT这篇论文提出了相对位置编码,使用稠密向量来表达 x i x_i xi和 x j x_j xj之间的相对位置关系:
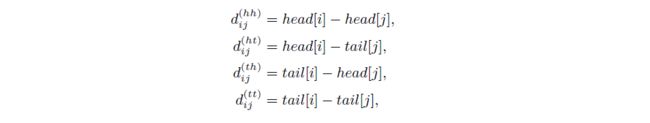
x i x_i xi和 x j x_j xj之间的相对位置向量的最终表达形式是上述4种距离表达的线性变换:
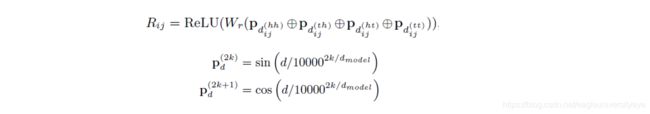
最后,FLAT通过一种自注意力的变体来利用相对跨度位置编码:

Adaptive Embedding
Simple-Lexicon
论文:Simplify the Usage of Lexicon in Chinese NER(ACL20)
论文一开始还是先讲了LatticeLSTM的很多不足,如效率低,信息损失,只能用在LSTM中等问题。然后论文提出了一种Simple-Lexicon方法,这种方法可以用在不同的特征提取器中,能够避免信息损失,而且可以并行化,效率还很高。
Simple-Lexicon的核心思想是,通过BMES标签来融合词汇信息。对于每一个输入字符,使用字典匹配该字符作为B开始、M中间、E结束、S单个四种位置类型对应的词。例如下图中的字符“语”,以“语”开头的词汇有“语言”、“语言学”,以“语”结束的词汇有“国语”,“中国语”。
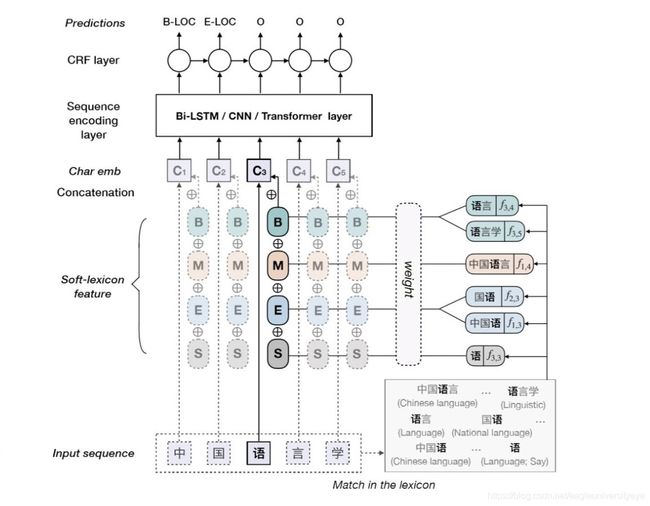
在词典匹配完成后,将词汇编码 V s V^s Vs以拼接的方式融合进字符编码中 X c X^c Xc中: