Python爬虫:简单的图片验证码识别
前言
目前,许多网站采取各种各样的措施来反爬虫,其中一个措施便是使用验证码。随着技术的发展,验证码的花样越来越多。验证码由最初的几个数字组合的简单的图形验证码,后来加入了英文字母和混淆曲线。有的网站还可以看到中文字符的验证码,这使得识别愈发困难。
现在交互式验证码越来越多,如滑动验证码,需要滑动拼合滑块才可以完成验证,点触验证码需要完全点击正确的结果才可以完成验证,另外还有滑动宫格验证码、计算题验证码等等。
验证码变得越来越复杂,爬虫的工作也变得愈发困难。有时候我们必须通过验证码的验证才能访问页面。
本次分享的知识就是教会大家验证码的识别做讲解。
图片验证码的识别
我们首先做最简单的一种验证码,即图形验证码。这种验证码出现的最早,现在也很常见,一般由4位字母或数字组成。
举个简单的例子,中国知网的注册页面就有类似的验证码。网页链接如下:
https://my.cnki.net/Register/CommonRegister.aspx

表单的最后一项就是图形验证码,我们必须完全正确的输入图中的字符才可以完成注册。
准备工作
识别图形需要用到库:tesserocr。
在爬虫过程中,难免会遇到各种各样的验证码,有些验证码就是图形验证码,这个时候我们可以直接使用OCR来识别。
1、OCR
0CR,即Opticla Character Recognition,光学字符识别,是指通过扫描字符,然后通过其形状将其翻译成电子文本的过程。对于图片验证码来说,它们都是一些不规则的字符,这些字符确实是由字符稍加扭曲变换得到的内容。
tesserocr是Python一个OCR识别库,但其实对于一个tesseract做的一层Python API封装,所以它的核心是tesseract。因此,在安装tesserocr之前,我们需要先安装tesseract。
下载链接如下:
https://digi.bib.uni-mannheim.de/tesseract/
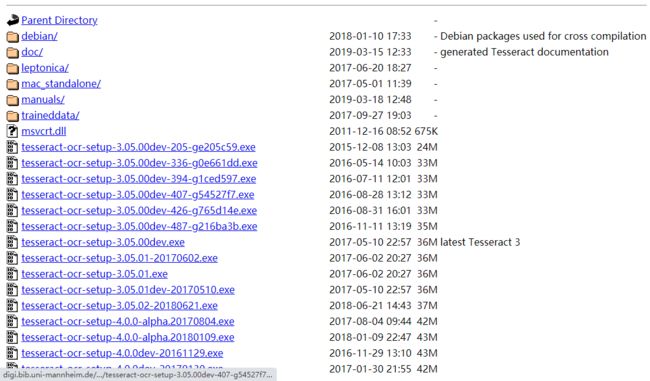
这里可以选择下载5.0的版本,下载之后安装方式还是比较简单的,直接下一步即可。
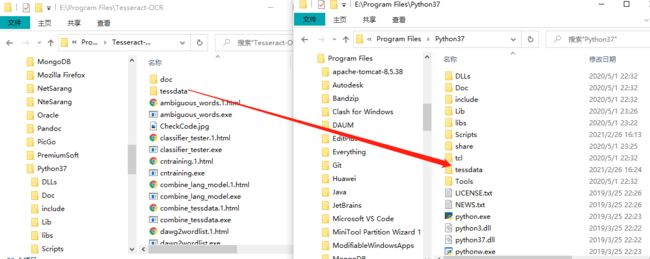
安装完毕之后将安装目录下的testdata文件复制到Python安装目录下,具体如下图所示:
接下来,再安装tessercor即可,此时可以使用pip进行安装:
pip install tesserocr pillow
为了防止安装错误,可以直接安装whl文件,安装这个库对版本要求比较高。下载链接如下:
https://github.com/simonflueckiger/tesserocr-windows_build/releases

这里我选择下载2.4.0版本,注意一定要使用Python3.7版本,否则会不兼容。
获取验证码
为了便于实验,我们先将验证码的图片保存下来。
打开开发者工具,找到验证码元素。验证码元素是一张图片,这张图片的链接是:
https://my.cnki.net/Register/CheckCode.aspx
打开链接就可以看到一张,图片,那个就是图片验证码,如下图所示:

识别测试
将验证码图片放在项目的根目录下,用tesserocr库识别该验证码,代码如下所示:
import tesserocr
from PIL import Image
image = Image.open('test3.jpg')
result = tesserocr.image_to_text(image)
print(result)
首先创建了一个image对象,然后调用了tesserocr下的image_to_text()方法。传入该image对象即可完成识别。
然而,有些时候也难免会识别错误。因此,我们需要对图片再做处理,如转灰度、二值化操作。
我们可以利用Image对象的convert()方法传入参数L,即可将图片转化为灰度图像。
具体代码,如下所示:
from PIL import Image
image = Image.open('test3.jpg')
image = image.convert('L')
image.show()
传入1即可将图片进行二值化处理,如下所示:
import tesserocr
from PIL import Image
image = Image.open('test3.jpg')
image = image.convert('1')
image.show()
我们还可以指定二值化的阀值。上面的方法采用的是默认阀值127.不过,我们不能直接转化为原图,首先要将原图先转为灰度图像,然后再制定阀值,当我们把验证码中的线条都去掉之后再重新来识别图片,会更加准确。
具体代码,如下所示:
import tesserocr
from PIL import Image
image = Image.open('test3.jpg')
image = image.convert('L')
threshold = 123 # 指定阀值
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
image = image.point(table, '1')
image.show()
result = tesserocr.image_to_text(image)
print(result)

本次分享的内容让大家了解到了如何使用tesserocr以及它的安装过程,如果大家在安装过程中出现了什么问题也可以和我联系。
资源获取
本次文章中所涉及到的文件几个,如下图所示:

毕竟上面的两个文件,我们都要通过访问国外的网站才能获取到,因此这里我给你们打包好了。
公众号回复【图片验证码】即可获取。
最后
没有什么事情是可以一蹴而就的,生活如此,学习亦是如此!
因此,哪里会有什么三天速成,七天速成的说法呢?
唯有坚持,方能成功!
啃书君说:
文章的每一个字都是我用心敲出来的,只希望对得起每一位关注我的人。在文章末尾点【赞】,让我知道,你们也在为自己的学习拼搏和努力。
路漫漫其修远兮,吾将上下而求索。
我是啃书君,一个专注于学习的人,你懂的越多,你不懂的越多。更多精彩内容,我们下期再见!