【C/C++服务器开发】socket网络编程函数接口详解
文章目录
-
- 一、前言
-
- TCP 网络编程
- 结合三次握手连接的 TCP socket
- 结合四次次挥手的 TCP socket
- 二、socket常用函数和数据结构
-
- 1.socket()函数
- 2.bind() 函数
-
- sockaddr_in 结构体
- in_addr 结构体
- 为什么使用 sockaddr_in 而不使用 sockaddr
- 3.connect() 函数
- 4.listen() 函数
-
- 请求队列
- 5.accept() 函数
- 6.write()函数
- 7.read()
- 三、总结
一、前言
我一般有一个习惯,在学习一个新东西之前,会对其宏观上的位置,基础概念进行理解,这样有利于将其加入到自身的知识体系中,这样更容易建立知识之间的联系,也可以和相似的内容进行类比学习。
初学socket时,很容易产生不知道这是啥的感觉。
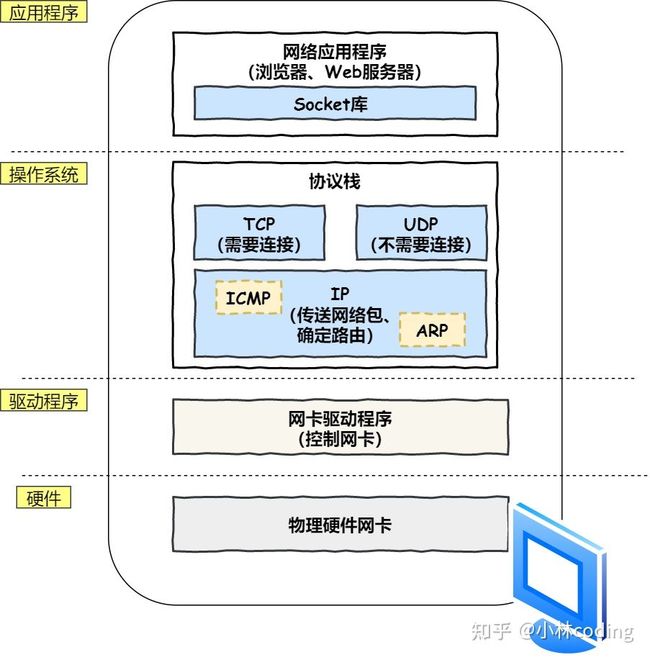
socket 其实就是操作系统提供给程序员操作「网络协议栈」的接口,说人话就是,你能通过socket 的接口,来控制协议找工作,从而实现网络通信,达到跨主机通信。
协议栈的上半部分有两块,分别是负责收发数据的 TCP 和 UDP 协议,它们两会接受应用层的委托执行收发数据的操作。
协议栈的下面一半是用 IP 协议控制网络包收发操作,在互联网上传数据时,数据会被切分成一块块的网络包,而将网络包发送给对方的操作就是由 IP 负责的。
此外 IP 中还包括 ICMP 协议和 ARP 协议。
ICMP用于告知网络包传送过程中产生的错误以及各种控制信息。ARP用于根据 IP 地址查询相应的以太网 MAC 地址。
IP 下面的网卡驱动程序负责控制网卡硬件,而最下面的网卡则负责完成实际的收发操作,也就是对网线中的信号执行发送和接收操作。
那具体 socket 有哪些接口呢?
socket 一般分为 TCP 网络编程和 UDP 网络编程。
TCP 网络编程
先来看看 TCP 网络编程,一幅图就很好理解。
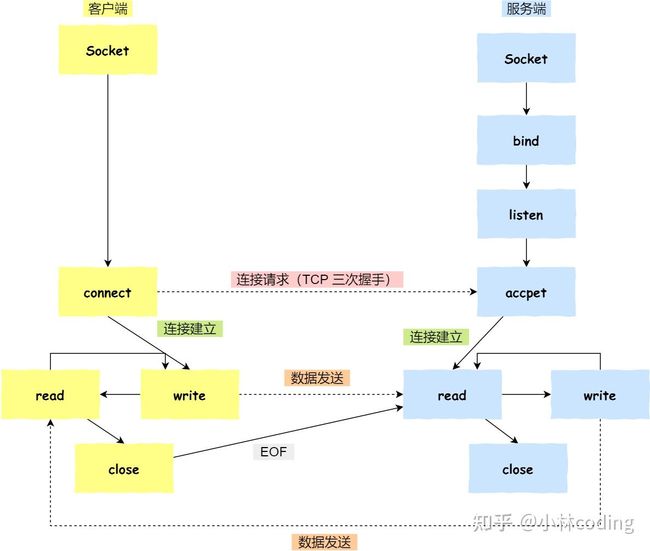
基于 TCP 协议的客户端和服务器工作
- 服务端和客户端初始化
socket,得到文件描述符; - 服务端调用
bind,将绑定在 IP 地址和端口; - 服务端调用
listen,进行监听; - 服务端调用
accept,等待客户端连接; - 客户端调用
connect,向服务器端的地址和端口发起连接请求; - 服务端
accept返回用于传输的socket的文件描述符; - 客户端调用
write写入数据;服务端调用read读取数据; - 客户端断开连接时,会调用
close,那么服务端read读取数据的时候,就会读取到了EOF,待处理完数据后,服务端调用close,表示连接关闭。
这里需要注意的是,服务端调用 accept 时,连接成功了会返回一个已完成连接的 socket,后续用来传输数据。
所以,监听的 socket 和真正用来传送数据的 socket,是「两个」 socket,一个叫作监听 socket,一个叫作已完成连接 socket。
成功连接建立之后,双方开始通过 read 和 write 函数来读写数据,就像往一个文件流里面写东西一样。
结合三次握手连接的 TCP socket
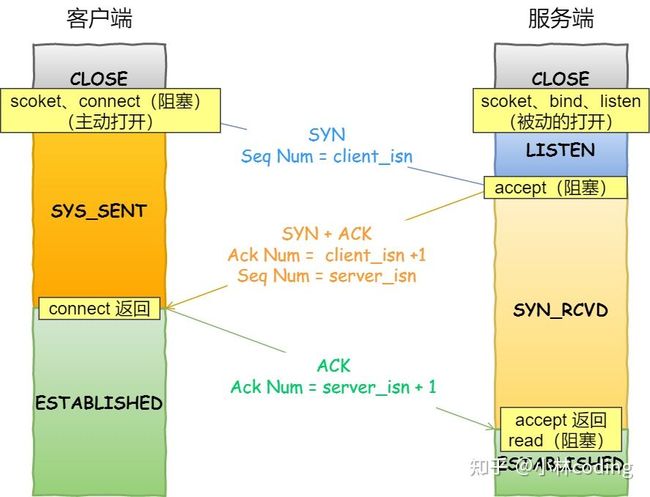
客户端连接服务端
- 客户端的协议栈向服务器端发送了 SYN 包,并告诉服务器端当前发送序列号 client_isn,客户端进入 SYN_SENT 状态;
- 服务器端的协议栈收到这个包之后,和客户端进行 ACK 应答,应答的值为 client_isn+1,表示对 SYN 包 client_isn 的确认,同时服务器也发送一个 SYN 包,告诉客户端当前我的发送序列号为 server_isn,服务器端进入 SYN_RCVD 状态;
- 客户端协议栈收到 ACK 之后,使得应用程序从
connect调用返回,表示客户端到服务器端的单向连接建立成功,客户端的状态为 ESTABLISHED,同时客户端协议栈也会对服务器端的 SYN 包进行应答,应答数据为 server_isn+1; - 应答包到达服务器端后,服务器端协议栈使得
accept阻塞调用返回,这个时候服务器端到客户端的单向连接也建立成功,服务器端也进入 ESTABLISHED 状态。
结合四次次挥手的 TCP socket
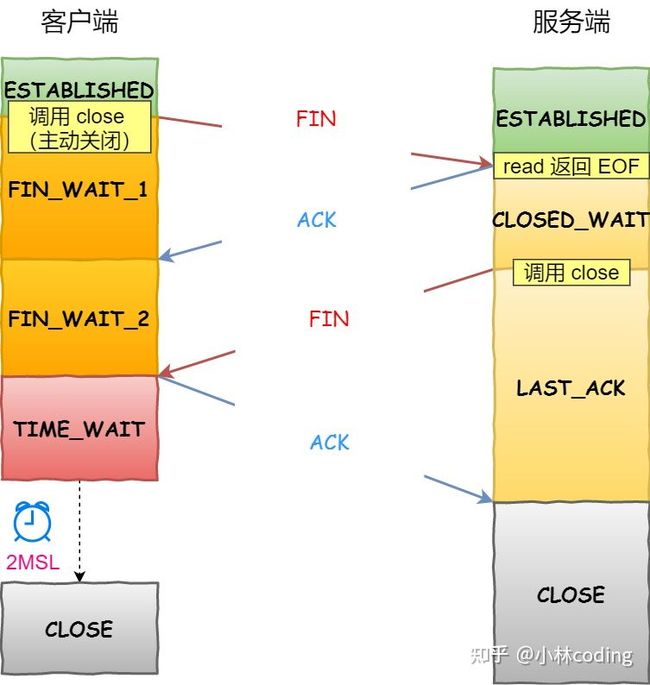
客户端调用 close 过程
- 客户端调用
close,表明客户端没有数据需要发送了,则此时会向服务端发送 FIN 报文,进入 FIN_WAIT_1 状态; - 服务端接收到了 FIN 报文,TCP 协议栈会为 FIN 包插入一个文件结束符
EOF到接收缓冲区中,应用程序可以通过read调用来感知这个 FIN 包。这个EOF会被放在已排队等候的其他已接收的数据之后,这就意味着服务端需要处理这种异常情况,因为 EOF 表示在该连接上再无额外数据到达。此时,服务端进入 CLOSE_WAIT 状态; - 接着,当处理完数据后,自然就会读到
EOF,于是也调用close关闭它的套接字,这会使得客户端会发出一个 FIN 包,之后处于 LAST_ACK 状态; - 客户端接收到服务端的 FIN 包,并发送 ACK 确认包给服务端,此时客户端将进入 TIME_WAIT 状态;
- 服务端收到 ACK 确认包后,就进入了最后的 CLOSE 状态;
- 客户端经过
2MSL时间之后,也进入 CLOSE 状态;
ref:https://www.zhihu.com/question/29637351
二、socket常用函数和数据结构
1.socket()函数
int socket(int af, int type, int protocol);
- af 为地址族(Address Family),也就是 IP 地址类型,常用的有 AF_INET 和 AF_INET6。AF 是“Address Family”的简写,INET是“Inetnet”的简写。AF_INET 表示 IPv4 地址,例如 127.0.0.1;AF_INET6 表示 IPv6 地址,例如 1030::C9B4:FF12:48AA:1A2B。
大家需要记住127.0.0.1,它是一个特殊IP地址,表示本机地址,后面的教程会经常用到。
你也可以使用 PF 前缀,PF 是“Protocol Family”的简写,它和 AF 是一样的。例如,PF_INET 等价于 AF_INET,PF_INET6 等价于 AF_INET6。
-
type 为数据传输方式/套接字类型,常用的有 SOCK_STREAM(流格式套接字/面向连接的套接字) 和 SOCK_DGRAM(数据报套接字/无连接的套接字),我们已经在《套接字有哪些类型》一节中进行了介绍。
-
protocol 表示传输协议,常用的有 IPPROTO_TCP 和 IPPTOTO_UDP,分别表示 TCP 传输协议和 UDP 传输协议。
有了地址类型和数据传输方式,还不足以决定采用哪种协议吗?为什么还需要第三个参数呢?
正如大家所想,一般情况下有了 af 和 type 两个参数就可以创建套接字了,操作系统会自动推演出协议类型,除非遇到这样的情况:有两种不同的协议支持同一种地址类型和数据传输类型。如果我们不指明使用哪种协议,操作系统是没办法自动推演的。
本教程使用 IPv4 地址,参数 af 的值为 PF_INET。如果使用 SOCK_STREAM 传输数据,那么满足这两个条件的协议只有 TCP,因此可以这样来调用 socket() 函数:
int tcp_socket = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP); //IPPROTO_TCP表示TCP协议
这种套接字称为 TCP 套接字。
如果使用 SOCK_DGRAM 传输方式,那么满足这两个条件的协议只有 UDP,因此可以这样来调用 socket() 函数:
int udp_socket = socket(AF_INET, SOCK_DGRAM, IPPROTO_UDP); //IPPROTO_UDP表示UDP协议
这种套接字称为 UDP 套接字。
上面两种情况都只有一种协议满足条件,可以将 protocol 的值设为 0,系统会自动推演出应该使用什么协议,如下所示:
int tcp_socket = socket(AF_INET, SOCK_STREAM, 0); //创建TCP套接字
int udp_socket = socket(AF_INET, SOCK_DGRAM, 0); //创建UDP套接字
后面的教程中多采用这种简化写法。
2.bind() 函数
bind() 函数的原型为:
int bind(int sock, struct sockaddr *addr, socklen_t addrlen); //Linux
sock 为 socket 文件描述符,addr 为 sockaddr 结构体变量的指针,addrlen 为 addr 变量的大小,可由 sizeof() 计算得出。
下面的代码,将创建的套接字与IP地址 127.0.0.1、端口 1234 绑定:
//创建套接字
int serv_sock = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP);
//创建sockaddr_in结构体变量
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof(serv_addr)); //每个字节都用0填充
serv_addr.sin_family = AF_INET; //使用IPv4地址
serv_addr.sin_addr.s_addr = inet_addr("127.0.0.1"); //具体的IP地址
serv_addr.sin_port = htons(1234); //端口
//将套接字和IP、端口绑定
bind(serv_sock, (struct sockaddr*)&serv_addr, sizeof(serv_addr));
这里我们使用 sockaddr_in 结构体,然后再强制转换为 sockaddr 类型,后边会讲解为什么这样做。
sockaddr_in 结构体
接下来不妨先看一下 sockaddr_in 结构体,它的成员变量如下:
struct sockaddr_in{
sa_family_t sin_family; //地址族(Address Family),也就是地址类型
uint16_t sin_port; //16位的端口号
struct in_addr sin_addr; //32位IP地址
char sin_zero[8]; //不使用,一般用0填充
};
-
sin_family 和 socket() 的第一个参数的含义相同,取值也要保持一致。
-
sin_prot 为端口号。uint16_t 的长度为两个字节,理论上端口号的取值范围为 0~65536,但 0~1023 的端口一般由系统分配给特定的服务程序,例如 Web 服务的端口号为 80,FTP 服务的端口号为 21,所以我们的程序要尽量在 1024~65536 之间分配端口号。
端口号需要用 htons() 函数转换,后面会讲解为什么。
-
sin_addr 是 struct in_addr 结构体类型的变量,下面会详细讲解。
-
sin_zero[8] 是多余的8个字节,没有用,一般使用 memset() 函数填充为 0。上面的代码中,先用 memset() 将结构体的全部字节填充为 0,再给前3个成员赋值,剩下的 sin_zero 自然就是 0 了。
in_addr 结构体
sockaddr_in 的第3个成员是 in_addr 类型的结构体,该结构体只包含一个成员,如下所示:
struct in_addr{
in_addr_t s_addr; //32位的IP地址
};
in_addr_t 在头文件
unsigned long ip = inet_addr("127.0.0.1");
printf("%ld\n", ip);
运行结果:
16777343
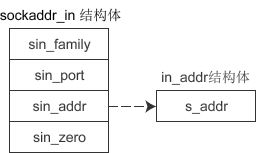
图解 sockaddr_in 结构体
为什么要搞这么复杂,结构体中嵌套结构体,而不用 sockaddr_in 的一个成员变量来指明IP地址呢?socket() 函数的第一个参数已经指明了地址类型,为什么在 sockaddr_in 结构体中还要再说明一次呢,这不是啰嗦吗?
这些繁琐的细节确实给初学者带来了一定的障碍,我想,这或许是历史原因吧,后面的接口总要兼容前面的代码。各位读者一定要有耐心,暂时不理解没有关系,根据教程中的代码“照猫画虎”即可,时间久了自然会接受。
为什么使用 sockaddr_in 而不使用 sockaddr
bind() 第二个参数的类型为 sockaddr,而代码中却使用 sockaddr_in,然后再强制转换为 sockaddr,这是为什么呢?
sockaddr 结构体的定义如下:
struct sockaddr{
sa_family_t sin_family; //地址族(Address Family),也就是地址类型
char sa_data[14]; //IP地址和端口号
};
下图是 sockaddr 与 sockaddr_in 的对比(括号中的数字表示所占用的字节数):
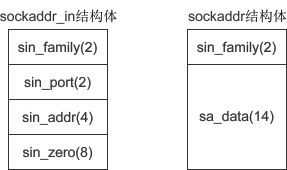
sockaddr 和 sockaddr_in 的长度相同,都是16字节,只是将IP地址和端口号合并到一起,用一个成员 sa_data 表示。要想给 sa_data 赋值,必须同时指明IP地址和端口号,例如”127.0.0.1:80“,遗憾的是,没有相关函数将这个字符串转换成需要的形式,也就很难给 sockaddr 类型的变量赋值,所以使用 sockaddr_in 来代替。这两个结构体的长度相同,强制转换类型时不会丢失字节,也没有多余的字节。
可以认为,sockaddr 是一种通用的结构体,可以用来保存多种类型的IP地址和端口号,而 sockaddr_in 是专门用来保存 IPv4 地址的结构体。另外还有 sockaddr_in6,用来保存 IPv6 地址,它的定义如下:
struct sockaddr_in6 {
sa_family_t sin6_family; //(2)地址类型,取值为AF_INET6
in_port_t sin6_port; //(2)16位端口号
uint32_t sin6_flowinfo; //(4)IPv6流信息
struct in6_addr sin6_addr; //(4)具体的IPv6地址
uint32_t sin6_scope_id; //(4)接口范围ID
};
正是由于通用结构体 sockaddr 使用不便,才针对不同的地址类型定义了不同的结构体。
3.connect() 函数
connect() 函数用来建立连接,它的原型为:
int connect(int sock, struct sockaddr *serv_addr, socklen_t addrlen); //Linux
4.listen() 函数
通过 listen() 函数可以让套接字进入被动监听状态,它的原型为:
int listen(int sock, int backlog); //Linux
sock 为需要进入监听状态的套接字,backlog 为请求队列的最大长度。
所谓被动监听,是指当没有客户端请求时,套接字处于“睡眠”状态,只有当接收到客户端请求时,套接字才会被“唤醒”来响应请求。
请求队列
当套接字正在处理客户端请求时,如果有新的请求进来,套接字是没法处理的,只能把它放进缓冲区,待当前请求处理完毕后,再从缓冲区中读取出来处理。如果不断有新的请求进来,它们就按照先后顺序在缓冲区中排队,直到缓冲区满。这个缓冲区,就称为请求队列(Request Queue)。
缓冲区的长度(能存放多少个客户端请求)可以通过 listen() 函数的 backlog 参数指定,但究竟为多少并没有什么标准,可以根据你的需求来定,并发量小的话可以是10或者20。
如果将 backlog 的值设置为 SOMAXCONN,就由系统来决定请求队列长度,这个值一般比较大,可能是几百,或者更多。
当请求队列满时,就不再接收新的请求,对于 Linux,客户端会收到 ECONNREFUSED 错误,对于 Windows,客户端会收到 WSAECONNREFUSED 错误。
注意:listen() 只是让套接字处于监听状态,并没有接收请求。接收请求需要使用 accept() 函数。
5.accept() 函数
当套接字处于监听状态时,可以通过 accept() 函数来接收客户端请求。它的原型为:
int accept(int sock, struct sockaddr *addr, socklen_t *addrlen); //Linux
它的参数与 listen() 和 connect() 是相同的:sock 为服务器端套接字,addr 为 sockaddr_in 结构体变量,addrlen 为参数 addr 的长度,可由 sizeof() 求得。
accept() 返回一个新的套接字来和客户端通信,addr 保存了客户端的IP地址和端口号,而 sock 是服务器端的套接字,大家注意区分。后面和客户端通信时,要使用这个新生成的套接字,而不是原来服务器端的套接字。
最后需要说明的是:listen() 只是让套接字进入监听状态,并没有真正接收客户端请求,listen() 后面的代码会继续执行,直到遇到 accept()。accept() 会阻塞程序执行(后面代码不能被执行),直到有新的请求到来。
6.write()函数
Linux 不区分套接字文件和普通文件,使用 write() 可以向套接字中写入数据,使用 read() 可以从套接字中读取数据。
前面我们说过,两台计算机之间的通信相当于两个套接字之间的通信,在服务器端用 write() 向套接字写入数据,客户端就能收到,然后再使用 read() 从套接字中读取出来,就完成了一次通信。
write() 的原型为:
ssize_t write(int fd, const void *buf, size_t nbytes);
fd 为要写入的文件的描述符,buf 为要写入的数据的缓冲区地址,nbytes 为要写入的数据的字节数。
size_t 是通过 typedef 声明的 unsigned int 类型;ssize_t 在 “size_t” 前面加了一个"s",代表 signed,即 ssize_t 是通过 typedef 声明的 signed int 类型。
write() 函数会将缓冲区 buf 中的 nbytes 个字节写入文件 fd,成功则返回写入的字节数,失败则返回 -1。
7.read()
read() 的原型为:
ssize_t read(int fd, void *buf, size_t nbytes);
fd 为要读取的文件的描述符,buf 为要接收数据的缓冲区地址,nbytes 为要读取的数据的字节数。
read() 函数会从 fd 文件中读取 nbytes 个字节并保存到缓冲区 buf,成功则返回读取到的字节数(但遇到文件结尾则返回0),失败则返回 -1。
三、总结
socket编程常用的函数不多,但是要在熟练掌握这些函数的基础上,我们还需要对网络的传输过程有一个足够的了解。