
编者按:
随着智能手机和信息通信技术的不断发展和普及,大规模的轨迹数据存储已经比较普遍,成为挖掘用户行为模式的重要来源,工作地和居住地是用户行为模式的重要表现,可用于辅助智能城市的建设,比如优化通勤路线、产业布局、分析人口流动情况等,从而减少交通拥堵、提高市民生活便利性和满意度。同时也可以辅助商业地理地产、线下消费等行业的咨询决策,比如根据消费人群的居住工作信息优化品牌布局和商业定位、优化线下广告投放等。但针对现有的工作地居住地计算方法存在不同程度的难题,本文将提出一种改进方案。
一、现有方法
基于加权DBSCAN的工作地居住地计算方法
【可以查阅此文:极客星球|基于加权DBSCAN的工作地居住地计算方法】
二、现有方法局限性
Poi数据的覆盖度不足和准确度不足导致无法很好的对dbscan聚类进行加权。
三、改进方法
对地块用地属性进行分类,填补上述geohash地块无poi分类的不足。
四、地块分类的作用
在商业地理中对用地属性进行分类是很有意义的一项工作,例如在计算设备的居住地和工作地时,如果不提前对地块进行划分,仅考虑时间维度,就会导致许多设备的居住地被计算在商场、园区、公园等非居住地块,而工作地落在了道路、水路等非工作地块的结果。如果提前将用地属性权重加入到计算中,在计算居住地时仅考虑设备出现在属性为小区的地块的报点(工作地同理),就可以极大提升设备职住地预测结果的准确性。此文将介绍两种在商业地理中较为实用的两种用地属性分类的方法。
1、 基于k-NN的地块分类方法
第一种方法是先将整个地图划分成小网格(geohash),再将地图上的所有的小网格分成居住地、工作地和其他三个类别,分类的基础框架采用的是k-NN算法,但在该算法的基础上增加了一些修正步骤。
这个方法中我们的基本假设是不同用地属性的网格在一个工作日中不同时间产生点位上报的概率分布具有显著差异。直观上的理解就是,居住地在非工作时间段具有更大的概率产生报点,而工作地则在工作时间具有更大的概率产生报点。基于这个基本假设我们最初的想法是收集每个网格中近三个月的工作日的所有报点时间,用这些报点时间通过核估计的方法估计出该网格内一天中产生报点的概率随时间变化的概率密度函数(PDF),再将两个网格之间的距离定义为对应概率密度函数围成的面积。但这种先取差的绝对值再积分的思路在工程实现的过程中计算耗时太长,以我们目前的计算资源无法在合理的时间内完成整个城市地图的计算任务。在尝试了多种距离定义之后,最终我们选择了推土机距离(Wasserstein distance)作为k-NN的距离函数。
两个概率密度函数u和v之间的推土机距离的原始定义是![]() ,其中
,其中![]() 是u和v的联合分布,可以证明该定义与
是u和v的联合分布,可以证明该定义与![]() 是完全等价的[1],其中U和V是两个概率密度函数对应的累积分布函数(CDF)。在这个新的定义下,只需用经验累积分布(empirical CDF)来估算累计分布函数,再对样本数据进行排序,就可以通过四则运算得到两个分布之间的距离,从而规避对核估计函数的积分,极大提升了计算距离的效率。
是完全等价的[1],其中U和V是两个概率密度函数对应的累积分布函数(CDF)。在这个新的定义下,只需用经验累积分布(empirical CDF)来估算累计分布函数,再对样本数据进行排序,就可以通过四则运算得到两个分布之间的距离,从而规避对核估计函数的积分,极大提升了计算距离的效率。
在确定了距离函数之后,采用k-NN的算法逻辑对未知类型小网格分类成居住地、工作地和其他三个类型,在商业地理中,我们关注的居住地主要是小区,工作地则主要是写字楼和园区,除此之外的商场、公园、道路、湖泊、景区等等各种类型都归类在了其他类型中,在这个定义下,其他类型涵盖的用地属性实际上非常多,而我们的训练集难以涵盖如此多的类型。直接采用k-NN进行分类会导致样本不平衡,即训练集中居住类型网格和工作类型网格的数量大于其他类型,但实际情况恰好相反。
为了解决这个问题,我们先取出训练集中类型为居住地和工作地的网格组成新的训练集,采用k-NN算法将所有待分类的网格分为居住地和工作地两个类型,以居住地为例,在分类过程中会计算每个待分类网格与训练集中所有网格的距离,利用该数据再次计算每个被k-NN分类到居住地的网格与训练集中所有居住地网格的距离均值,然后设定居住地均值的阈值,将均值大于设定阈值的网格重新分类为其他,阈值的设置方法非常多,在此不再赘述,对于被k-NN分类到工作地的网格同理。至此我们完成了居住地、工作地和其他三种类型的分类,以下展示上海市长宁区的居住地分类结果。

上海市长宁区居住地分类结果
2、 基于maskrcnn模型的地块poi分割方法
除了上述的方法以外,是否还有办法对一个地块或者地方的用地属性进行分类呢?
在这里我们想到了,就是地图对于不同的地块的信息是不一样的,例如在地图中,小区一般都是很多个小的方形的建筑物密集排布;甚至有卫星图也可以很容易的分辨出地块的属性。
在这里安利一下达摩院的一个小工具:
https://aiearth.aliyun.com/
达摩院的能力当然是很强的,我们尝试着去简单复现一下。
整个算法的本质是要进行实例分割,简称抠图。
基于此,我们整理了大大小小4万多张地图图片,并将其内部建筑物一一抠出,并分成5大类:小区、写字楼、商场、园区、景区,部分如下图所示:
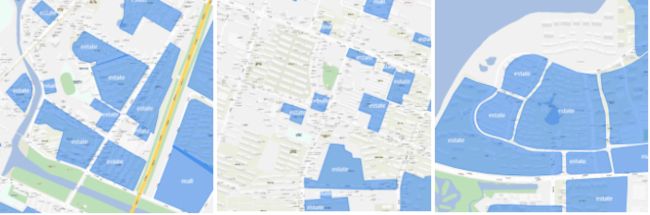
然后对数据进行处理,包括由经纬度组成的点转换成对应图片xy坐标的点,并以此生成mask遮罩,并对mask遮罩生成游程编码压缩存储空间。最后将这些所有信息一并通过json存起来。
至此,所有的数据已准备完毕,包括图片和对应的json文件。
下一步我们来训练模型:
在前期的测试和了解阶段,我们打算直接使用百度的easydl平台来实现简单的输出:

百度easydl平台
当前刚在平台上完成测试,测试结果尚佳,后续为了提升准确率,我们期望能将卫星图也加入到实例分割的数据中去,而两张图片的融合进行实例分割在百度的easydl平台将无法实现,只能自己创建模型,并对开源算法进行“魔改”。
在这里我们打算采用的是业界广泛使用而且有较多源码支持的Mask-RCNN
Mask-RCNN 是ICCV2017 的best paper, 是FAIR团队的Kaiming大神和RBG大神的作品,同时也是Faster R-CNN 和FCN的融合产物。优点是实现起来比较简单高效,缺点是相比当前新的模型,准确度和速度都尚未达标。当前地块分类对于模型像素级别分类的准确度的要求相对不高,而且因为是离线训练使用,在速度方面没有具体要求。所以从工程简易程度方面考虑,我们选择了Mask-RCNN模型。
Mask-RCNN模型“魔改”的内容主要是集中在对入参的矩阵大小进行修改,需要对源代码中的第一层矩阵向量大小从3改到6,从而实现两张图片像素RGB融合(一个像素3个维度,如:255,255,255),当前这部分工作还在进行当中,后续将会持续更新进展。
参考文献:
[1] Ramdas, Garcia, Cuturi “On Wasserstein Two Sample Testing and Related Families of Nonparametric Tests” (2015) https://arxiv.org/abs/1509.02237