Python爬取百度指数中的搜索指数
本文是在实际需要中使用爬虫获取数据,然后进行对应的数据分析,仅是学习用途,特此记录。
1.环境:Python3.7+PyCharm
1.1 所需要的库:datetime,requests,execjs(非必须)
1.2 为了更好的查看json数据,建议在chrome中安装JSONView插件(https://github.com/gildas-lormeau/JSONView-for-Chrome)
2.百度指数中的数据获取难点:
2.1 百度指数的URL请求地址返回的数据,并不是可以直接进行json解析使用的数据,而是加密之后的数据和uniqid,需要通过uniqid再次请求对应的地址(后面部分介绍)获取到解密的密钥,然后在前端页面进行解密,然后再渲染到折线图中。
2.2 必须要在百度指数页面登录百度账号,由于时间关系,本次数据爬取都是在登录之后进行的操作。
2.3 需要将前端解密代码转化为Python代码,获取直接使用前端代码也可以。
2.3.1 不转换像下面这样使用也可以解密,直接利用execjs直接JavaScript代码即可。
# Python的强大之处就在于,拥有很强大的第三方库,可以直接执行js代码,即对解密算法不熟悉,无法转换为Python代码时,直接执行js代码即可
js = execjs.compile('''
function decryption(t, e){
for(var a=t.split(""),i=e.split(""),n={},s=[],o=0;o)
res = js.call('decryption', key, source) # 调用此方式解密,需要打开上面的注解
2.3.2 前端JavaScript代码对应的Python代码
# 搜索指数数据解密
def decryption(keys, data):
dec_dict = {
}
for j in range(len(keys) // 2):
dec_dict[keys[j]] = keys[len(keys) // 2 + j]
dec_data = ''
for k in range(len(data)):
dec_data += dec_dict[data[k]]
return dec_data
2.4 获取自己登陆之后的Cookie(必须要有,否则无法获取到数据),具体的Cookie获取如下图,请注意看我下图标红的地方。
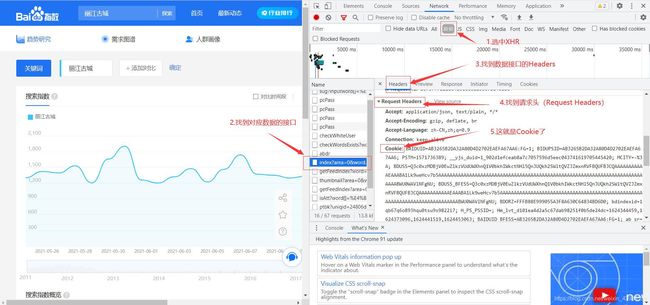
3.爬取数据的步骤
3.1 构建请求头,爬虫必须,请求头直接全部复制2.4中的请求头即可。
header = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': '你登陆之后的Cookie',
'Host': 'index.baidu.com',
'Referer': 'https://index.baidu.com/v2/main/index.html',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36'
}
3.2 分析url
3.2.1 请求数据的url,2.4已经给出
dataUrl = 'https://index.baidu.com/api/SearchApi/index?area=0&word=[[%7B%22name%22:%22%E4%B8%BD%E6%B1%9F%E5%8F%A4%E5%9F%8E%22,%22wordType%22:1%7D]]&days=30'
其中,汉字和部分符号被替换,只需找到对应的汉字部分即可,%22是",所以,哪里是汉字,对比浏览器的地址栏就晓得了吧,url最后的days=30,代表获取一个月的数据,从当前日期的前一天往前推一个月,可以根据需要修改days获取更多的数据或者更少的数据。在浏览器中输入dataUrl中的内容,可以得到以下数据

经过对all,pc,wise对应的数据进行解密,和搜索指数的折线图显示的数据对比,发现all部分的数据就是搜索指数的数据。本次请求返回的数据就在这里了,可以看到uniqid,而且每次刷新加密的数据和uniqid都会变。

3.2.2 获取密钥的url
经过多次分析,发现请求数据的url下面的uniqid出现在了下面这个url中

因此需要先对请求数据对应的url进行数据获取,解析出搜索指数对应的加密数据和uniqid,然后拼接url获取密钥,最后调用解密方法解密即可获取到搜索指数的数据。
keyUrl = 'https://index.baidu.com/Interface/ptbk?uniqid='
3.2.3 找到了对应的url,我们的爬虫也就完成了,接下来就是发送请求,解析数据,然后对数据进行解密即可。
4.完整代码
import datetime
import requests
import execjs
# 搜索指数数据解密
def decryption(keys, data):
dec_dict = {
}
for j in range(len(keys) // 2):
dec_dict[keys[j]] = keys[len(keys) // 2 + j]
dec_data = ''
for k in range(len(data)):
dec_data += dec_dict[data[k]]
return dec_data
if __name__ == "__main__":
scenicName = '丽江古城'
dataUrl = 'https://index.baidu.com/api/SearchApi/index?area=0&word=[[%7B%22name%22:%22' + scenicName + '%22,%22wordType%22:1%7D]]&days=30'
keyUrl = 'https://index.baidu.com/Interface/ptbk?uniqid='
header = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': '你登陆之后的Cookie',
'Host': 'index.baidu.com',
'Referer': 'https://index.baidu.com/v2/main/index.html',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36'
}
# 设置请求超时时间为30秒
resData = requests.get(dataUrl, timeout=30, headers=header)
uniqid = resData.json()['data']['uniqid']
print("uniqid:{}".format(uniqid))
keyData = requests.get(keyUrl + uniqid, timeout=30, headers=header)
keyData.raise_for_status()
keyData.encoding = resData.apparent_encoding
# 开始对json数据进行解析
startDate = resData.json()['data']['userIndexes'][0]['all']['startDate']
print("startDate:{}".format(startDate))
endDate = resData.json()['data']['userIndexes'][0]['all']['endDate']
print("endDate:{}".format(endDate))
source = (resData.json()['data']['userIndexes'][0]['all']['data']) # 原加密数据
print("原加密数据:{}".format(source))
key = keyData.json()['data'] # 密钥
print("密钥:{}".format(key))
# Python的强大之处就在于,拥有很强大的第三方库,可以直接执行js代码,即对解密算法不熟悉,无法转换为Python代码时,直接执行js代码即可
# js = execjs.compile('''
# function decryption(t, e){
# for(var a=t.split(""),i=e.split(""),n={},s=[],o=0;o
# n[a[o]]=a[a.length/2+o]
# for(var r=0;r
# s.push(n[i[r]])
# return s.join("")
# }
# ''')
# res = js.call('decryption', key, source) # 调用此方式解密,需要打开上面的注解
res = decryption(key, source)
# print(type(res))
resArr = res.split(",")
dateStart = datetime.datetime.strptime(startDate, '%Y-%m-%d')
dateEnd = datetime.datetime.strptime(endDate, '%Y-%m-%d')
dataLs = []
while dateStart <= dateEnd:
dataLs.append(str(dateStart))
dateStart += datetime.timedelta(days=1)
# print(dateStart.strftime('%Y-%m-%d'))
ls = []
for i in range(len(dataLs)):
ls.append([scenicName, dataLs[i], resArr[i]])
for i in range(len(ls)):
print(ls[i])
5.总结
总的来说,本次爬虫大体完成,在代码的编写之余,查阅了解密算法的Python实现,还查看了对日期的操作博客,所有的博客地址如下:
https://blog.csdn.net/weixin_41074255/article/details/90579939
https://blog.csdn.net/junli_chen/article/details/52944724
https://blog.csdn.net/lilongsy/article/details/80242427
https://blog.csdn.net/philip502/article/details/14004815/
感谢各位大牛的博客,因为有了你们我才能完成这篇博客,本文只为记录我在实际中遇到的问题和解决的方法,如有不足还请见谅,若有更好的解决方式,可以评论出来大家一起参考。