基于Attention_CNN_GRU的野生动物监测图像分类
大一的时候突发奇想选择了这样的一个方向,并查阅了相关文献,努力去完成这样的一个系统化的东西。但确实这方面做的人很少,也没有找到有关的进行学习,做的也是很是缓慢,同时也是运用到了Paddle框架,Paddle的一小部分展示如下:
import paddle
import sys
import os
import paddlehub as hub
module = hub.Module(name='resnet50_vd_animals')
Downloading resnet50_vd_animals
[==================================================] 100.00%
Uncompress /home/aistudio/.paddlehub/tmp/tmp2qvasfuz/resnet50_vd_animals
[==================================================] 100.00%
Filelist = []
Dirlist = []
path ='dataset/img'
import os
def set_label(file_path):
del_str='.ipynb_checkpoints'
for home, dirs, files in os.walk(file_path):
for d in dirs:
if del_str in d:
continue
else:
Dirlist.append(d)
set_label(path)
print(Dirlist)
def get_filelist(dir):
data_dict={}.fromkeys(['path','label'])
del_str='.ipynb_checkpoints'
for home, dirs, files in os.walk(path):
for filename in files:
if del_str in filename:
continue
else:
data_dict={}.fromkeys(['path','label'])
img_path=os.path.join(home, filename)
data_dict['path']=img_path
for i in range(len(Dirlist)):
if Dirlist[i] in img_path:
img_label=i
data_dict['label']=img_label
Filelist.append(data_dict)
return Filelist, Dirlist #返回文件名 路径
img_files,labels=get_filelist('dataset/img')
forecast_list=[]
def dict_save(trainfilename,validatafilename,data):
for i in range(len(data)):
if 0<=i%10 and i%10<=5:
with open(trainfilename,"a") as f:
train = data[i]["path"]+" "+str(data[i]["label"])+"\n"
f.write(train)
if 6<=i%10 and i%10<=7:
with open(validatafilename,"a") as f1:
validata = data[i]["path"]+" "+str(data[i]["label"])+"\n"
f1.write(validata)
if 8<=i%10:
forecast_list.append(data[i]["path"])
print("保存文件成功")
def text_save(filename, data):
str_list = [line+'\n' for line in data]
with open(filename, 'w') as f:
f.writelines(str_list)
print("保存文件成功")
validata_file='data/validata_list.txt'
label_file='data/label_list.txt'
train_file='data/train_list.txt'
dict_save(train_file,validata_file,img_files)
text_save(label_file,labels)
['野骆驼', '高鼻羚羊', '野牛', '麋鹿', '虎', '野马', '普氏原羚', '白唇鹿', '黑麂', ' 豚鹿', '丹顶鹤', '蒙古野驴', '中华秋沙鸭', '扭角羚', '鼷鹿', '西藏野驴', '熊猫', '台湾鬣羚', '河狸', '梅花鹿', '扬子鳄', '金钱豹', '藏羚', '云豹', '坡鹿', '紫貂', '野牦牛', '塔尔羊', '绿孔雀', '赤斑羚', '蜂猴', '藏羚羊']
保存文件成功
保存文件成功
from paddlehub.dataset.base_cv_dataset import BaseCVDataset
class HumanfaceDataset(BaseCVDataset):
def __init__(self):
self.dataset_dir = '/home/aistudio'
super(HumanfaceDataset,self).__init__(
base_path=self.dataset_dir,
train_list_file="data/train_list.txt",
label_list_file="data/label_list.txt",
validate_list_file="data/validata_list.txt",
)
dataset = HumanfaceDataset()
reader = hub.reader.ImageClassificationReader( #reader 负责对dataset进行数据预处理
image_width=module.get_expected_image_width(),
image_height=module.get_expected_image_height(),
images_mean=module.get_pretrained_images_mean(),
images_std=module.get_pretrained_images_std(),
dataset = dataset
)
config = hub.RunConfig(
use_cuda=True,
num_epoch=10,
batch_size=62,
log_interval=50,
strategy=hub.DefaultFinetuneStrategy())
input_dict, output_dict, program = module.context(trainable=True)
img = input_dict["image"]
feature_map = output_dict["feature_map"]
feed_list = [input_dict["image"].name]
task = hub.ImageClassifierTask(
data_reader=reader,
feed_list=feed_list,
feature=feature_map,
num_classes=dataset.num_labels,
config=config)
task.finetune_and_eval()
import numpy as np
import re
import os
data = forecast_list
label_map = dataset.label_dict()
index = 0
num = 0
run_states = task.predict(data=data)
results = [run_state.run_results for run_state in run_states]
count=0
num1=0
for batch_result in results:
batch_results = np.max(batch_result, axis=2)[0]
batch_result = np.argmax(batch_result, axis=2)[0]
for result in batch_result:
num+=1
index += 1
try:
if batch_results[index-1]:
pass
except:
index=1
result = label_map[result]
if batch_results[index-1]>=0.6:
num1+=1
print("input %i is %s, and the predict result is %s" %(num, data[num - 1], result))
res = re.compile('[\u4e00-\u9fff]+').findall(data[num - 1])
if res[0] in result:
count+=1
else:
print("input %i is %s, 该动物未被识别" %(num, data[num - 1]))
print("能够识别出来的精确率是:%.2f%%"%(count/num1*100))
其中对于图像的低照度增强,这里借鉴一下崔崔的:
def Image_enhancing(image):
img=cv2.cvtColor(image,cv2.COLOR_BGR2GARY)/255
# img = 0.2989*image[:, :, 2]+0.5870*image[:, :, 1]+0.1140*image[:, :, 0]
#二者效果一样,使用后者不需要再除以255
img = replaceZeroes(img)
img_n = (np.power(img, 0.24)+(1-img)*0.5+np.power(img, 2))/2
sigma = 3
window = 3*sigma*2+1
guass1 = cv2.GaussianBlur(img, (window, window), sigma)
r1 = guass1/img
R1 = np.power(img_n, r1)
sigma = 20
window = 3*sigma*2+1
guass2 = cv2.GaussianBlur(img, (window, window), sigma)
r2 = guass2/img
R2 = np.power(img_n, r2)
sigma = 24
window = 255
guass3 = cv2.GaussianBlur(img, (window, window), sigma)
r3 = guass3/img
R3 = np.power(img_n, r3/255)
R = (R1+R2+R3)/3
Rr = R*(image[:, :, 2]/img_n)
Rg = R*(image[:, :, 1]/img_n)
Rb = R*(image[:, :, 0]/img_n)
rgb = np.concatenate(
(Rb[:, :, np.newaxis], Rg[:, :, np.newaxis], Rr[:, :, np.newaxis]), axis=2)
return rgb+image
def replaceZeroes(img):
min_nonzero = min(img[np.nonzero(img)])
img[img == 0] = min_nonzero
return img以上的几个要点:
-
读取图像时需要归一化,归一化放在转为灰度图之后;
-
显示增强图像时需要除以255;
-
cv2.imread()读取图片通道为BGR;
-
有文章说需要将增强图像超过1的部分设为1,详见此,但实际并没有遇到问题。
我在上一篇CRNN+CTC中会给出Paddle的图像增强的几种代码。
第一章 绪论
1.1
研究背景及意义
作为生态链中不可或缺的一环,野生动物在生物多样性中扮演着重要的角色。近年来,由于经济的高速发展和城市化进程的影响,野生动物栖息地遭到破坏。
同时,随着人口增多和消费水平的提高,人们对保护野生动物的意识淡薄,造成
相当数量的野生动物种类处于受胁状态。保护野生动物不仅仅事关大自然的生态
平衡,还对我们人类的生存与发展有着重大意义。
红外触发相机和无线图像传感网络技术作为监测野生动物的主要方式,广泛地应用于各个自然保护区的野生动物监测中,相比于传统的人工监测方式,大大提高了监测效率。然而,随着在自然保护区中部署红外触发相机数量的增长,红外触发相机获得的图片数量也呈指数增长,这对当前以人工为主的图像分类方式无疑是十分缓慢且困难的,大大降低了监测图像的实时性。
科学有效的野生动物分类识别系统是了解并保护野生动物资源的首要前提。深度学习发展,使得各种神经网络模型推陈出新,随着
ImageNet
在实际应用中的成功实现,图像分类识别广泛应用于目标检测、自然语言处理、图像识别等领域。研究人员逐渐把深度神经网络应用到野生动物图像监测领域,因此,部分研究人员开始探索将图像分类应用于野生动物图像监测之中。针对上述问题,本文对图像之间的感兴趣区域与深度卷积神经网络结合进行特征提取,然后通过卷积神经网络分析学习图像间的时间关系,改善监测图像实时性差的问题,同时解决由于图像数据集数据量巨大的问题。
第二章 系统架构
2.1
需求分析
一方面,在野外环境下,野生动物监测图像受动物位置不固定、背景信息复杂、天气变化等各种因素影响,从而导致红外触发相机监测到的图像存在着误触发现象,导致服务器终端对图像进行分类时不能准确识别,同时还会降低对野生动物获取信息的效率,特别是在珍惜野生动物出现时,问题尤为明显。另一方面,尽管图像分类已经在图像监测领域取得一定的成就,但由于野生动物图像采集周期长、公开数据集少、处理数据量大,使得深度神经网络在对野生动物识别领域上发展相对缓慢。同时,目前针对低质量的图像识别研究主要是人脸和文本的识别,而针对野生动物监测图像的识别研究较少。最后,随着在自然保护区中部署红外触发相机数量的增长,红外触发相机获得的图片数量也呈指数增长,后期处理复杂,如何对大量的图像数据进行有效管理和分析成为了野生动物研究人员必须面对的问题。
2.2
系统方案设计
针对上述问题,本文提出了基于
Attention-CNN-GRU
的野生动物分类识别系统方案设计,其示意图如图
1
所示。该系统可供野生动物监测领域研究员研究使用,也可以将其应用到安卓手机系统上,为普通群众提供野生动物信息。服务器终端依据红外触发相机的地址将拍摄到的野生动物图像归类到不同文件夹,并将其送入训练好的分类模型进行分类与识别。
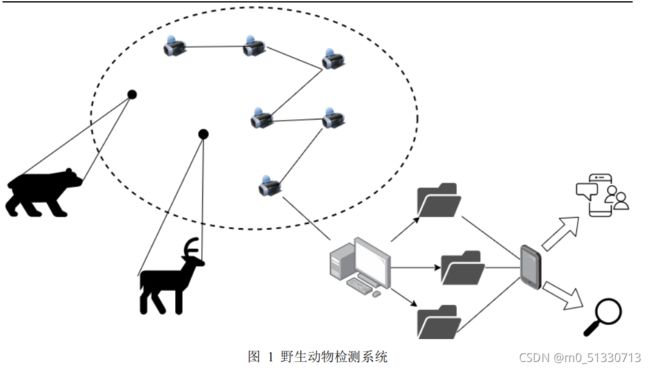
对于监测系统平台而言,
通过人工智能建立基于深度学习的物种图像监测与识别系统,实现对影像和抓拍图片画面的全自动化监测,准确识别画面中物种类型、数量、发生时间。同时,抓拍到的图片经模型识别成功后,会放进相应动物种类的文件夹中。
对于手机系统而言,首先要对产品进行
UI
框架的搭建,在百度
AI
基于
IDL大规模图像训练基础上,然后,通过网络爬虫广泛收集数据,最后,利用
EasyDL
实现定制化高精度
AI
模型,提供拍照识别功能对动物和部分野生动物进行有效
识别。同时,还可以自动搜索并展示出识别到的动物的信息,达到便携性、实用
性和普及性的目的,从而满足不同人群的不同需求。
第三章 系统方案
3.1
数据准备
3.1.1
数据集
该测试方案的数据集主要包括
2
个来源:一是自然保护区部署的红外触发相机所拍摄的野生动物图像、二是来源于
Snapshot Serengeti
公开数据集。将第一类数据集记为
DS1
,第二类数据集记为
DS2
,将
DS1
和
DS2
合称为
DS
。其中,数据集
DS1
由
30617
张图片构成,由于自然因素或其他因素造成的误触图像有
13226张;数据集
DS2
包含
46
种野生动物,约
120
万张图片,该测试方案选取其中
26种动物,
31536
张图片。
3.1.2
相关系数
为了更好的了解数据集的特征,提高图像识别的准确度、减少误触等负面因素影响。测试首先从相同监测地点野生动物图像相关性、不同监测地点同种野生
动物图像相关性以及相同监测地点不同场景切换相关性等三个方面,对数据集中
图像间存在关系进行了研究与分析。
3.2
基于相关系数的野生动物图像分析
3.2.1
相同监测地点野生动物图像相关性
首先,分析相同监测地点
A
连续拍摄的
9
组图像之间的相关性。经计算,得出各组图像之间的相关系数、预先距离,并把数据分别以柱形图的形式展示。其
中,(
a
,
b
)表示图像
a
和图像
b
之间的关系。
图
2
监测点
A
中的图片之间的相关系数
图
3
监测点
A
中的图片之间的余弦距离。
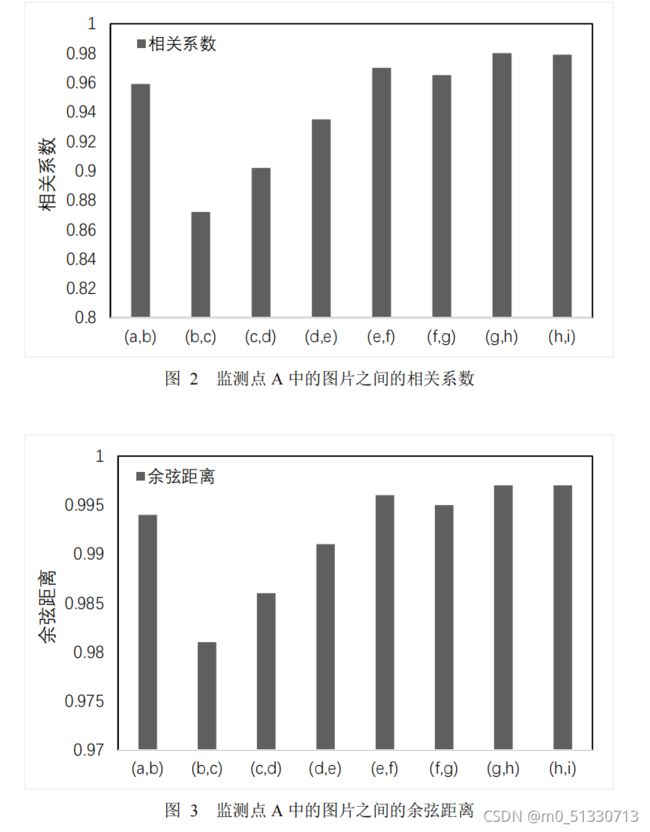
从图
1
和图
2
可知,图片(
b
)和图片(
c
)相关性最低,图片(
g
)和图片(
h
)
相关性最高,它们之间自相关系数的最大差值为
0.108068
,余弦距离,最大差值
为
0.0157317
。相邻图片间自相关系数与余弦距离变化波动较小,且相邻图片间相
关系数均大于
0.87
,余弦相似度均大于
0.98
。因此,该序列图片彼此之间在时序方面体现出强相关的特性。
3.2.2
不同监测地点同种野生动物图像相关性
然后,分析不同监测地点
B
连续拍摄的野生动物图片之间的相关性规律。
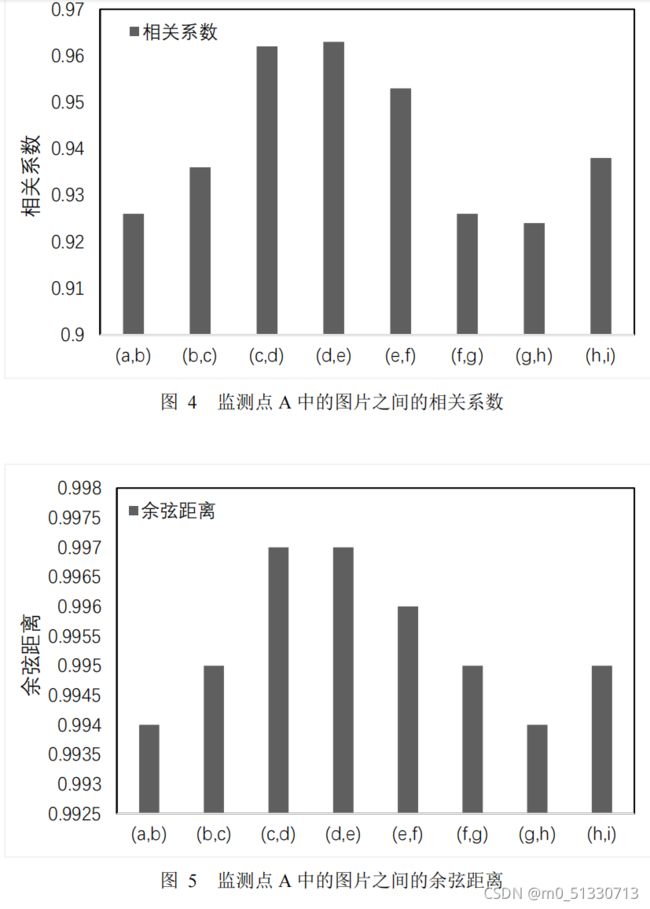
从图
3
和图
4
可以看出,图片(g
)和图片(
h
)相关性最低,图片(
d
)和图
片(e
)相关性最高。图片(
g
)和图片(
h
)中动物的相对位移较大,因此,两者
相关系最小,图片(d
)和图片(
e
)中动物的相对位移较小,因此,两者相关系
最大。同时,与监测地点A类似,监测地点B连续拍摄野生动物图像之间相关系
数均大于
0.92
余弦距离均大于
0.944
,体现出相同监测地点野生动物图像间强相
关性的特征。
3.2.3
相同监测地点不同场景切换相关性
接着,分析相同监测地点
C
不同场景连续拍摄的野生动物图片之间的相关性规律。
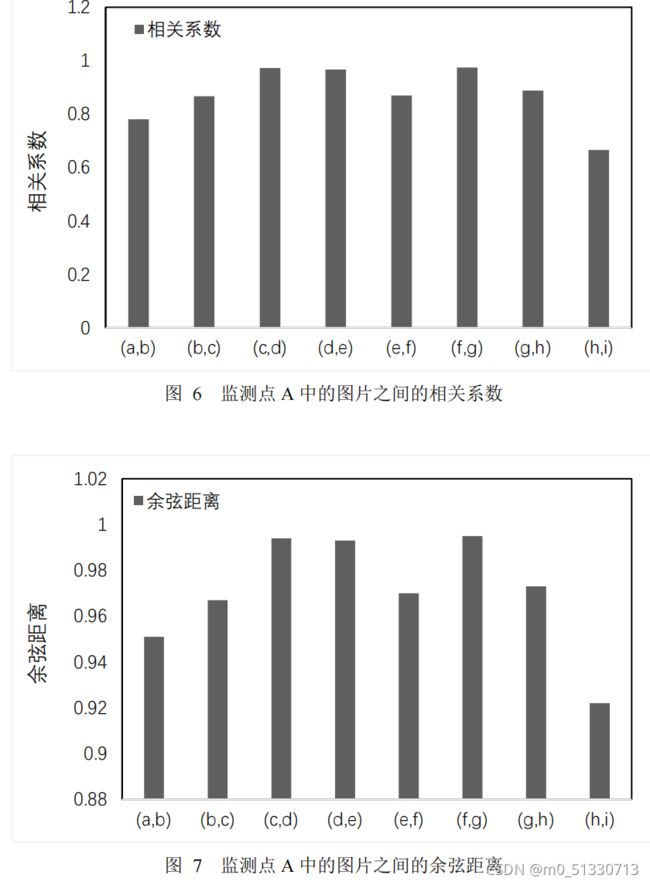
由图
5
和图
6
可以看出,在相同地点的不同场景在相关性性变化方面,相关系数和余弦距离有着相似的趋势,与余弦距离相比,相关系数的变化更为明显。因此,在后续实验中选用相关系数作为衡量野生动物图片之间相关性的标准。
第四章 系统测试
4.1 CNN
结构在野生动物图像数据集上的分析与测试
为对比不同的模型结构在不同数据集上的分类效果,选取
AlexNet
、
VGG16
、Inception V4
、
ResNet50
、
ResNet101
等不同网络模型在数据集
DS1
和
DS2
上测试准确率。
表
1
在
DS1
数据集上不同网络模型测试结果
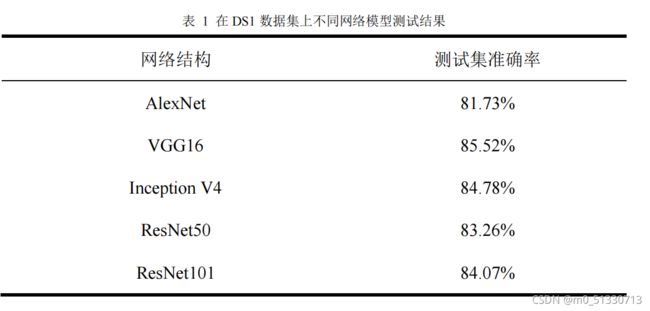
由表
1
可以看出,对于数据集
DS1
,经典的深度卷积网络模型都能较为准确
的识别野生动物图像。其中,网络结构较浅的
AlexNet
模型测试准确率最低,为81.73%
,
Inception V4
模型测试准确率最高,为
84.78%
,准确率高出
3.05%
,而与网络结构更深的
ResNet101
相比,准确率高出
0.71%
。由
AlexNet
、
Inception V4
、ResNet101
网络结构看出,随着网络结构深度和广度的增加,经过不断改进的网络模型在相同数据集上的分类识别问题上的表现更好。
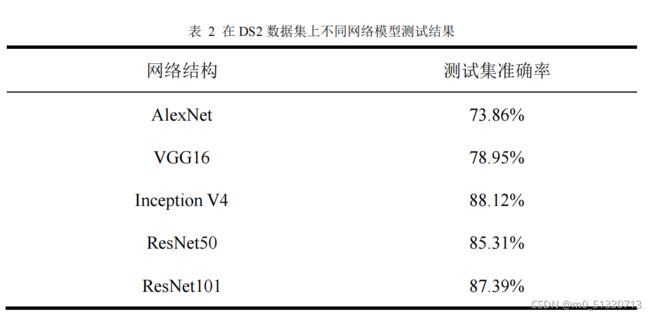
由表
2
可以发现,随着数据集中动物的类别增多,一些较浅的网络结构模型
测试准确率大幅度下降,而对于较深且不断改进过网络模型,其测试准确率不降反升。其中
Inception V4
网络模型测试准确率和增长都为最高,分别为
88.12%
和3.34%
。这种结果可能的原因是对于简单的分类任务,浅层的神经网络与深层的神经网络区别相对平缓,但是当分类类别数目增多时,深层神经网络具有更好地适应性。
4.2
循环神经网络改进与分析
LSTM
是经典
RNN
方法的改进版,可以用来学习时序上的长期依赖关系。
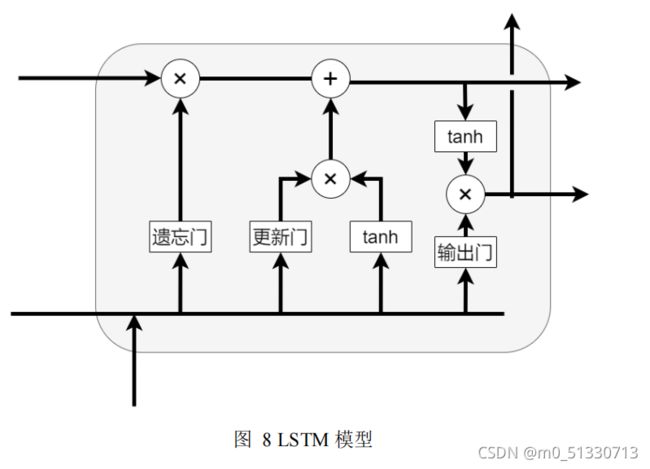
如图
所示,
LSTM
相比经典
RNN
更加复杂,
LSTM
引入了
3
个门结
构控制时间上信息传递的过程,这克服了短时记忆地影响,能很好地捕获更长时期的时序信息,有效地解决了传统循环卷积神经网络随着时间间隔增加出现的梯度爆炸或梯度弥散。而且,在
LSTM
中权重可以进行变动,而非
RNN
原有的权重固定的模式,保证了序列信息有效存储与忘记,比
vanilla
循环神经网络更易学习长期依赖关系。
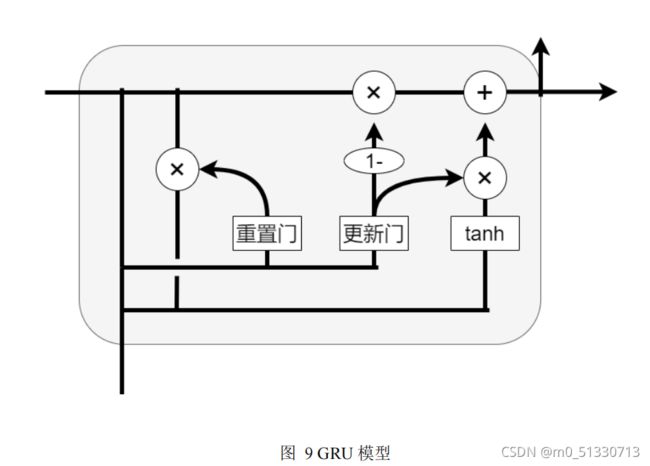
GRU
是新一代的循环神经网络,与
LSTM
非常相似。如图
8
所示,
GRU作为
LSTM
的一种变体,将忘记门和输入门合成了一个单一的更新门。同样还混合了细胞状态和隐藏状态,加诸其他一些改动,最终的模型比标准的
LSTM模型要简单。
经过实验发现,
GRU
模型与
LSTM
模型效果基本相同,由于
GRU
结构既能很好地捕获长时期的历史信息,又相对来说计算简单,故后续实验在构建循环神经网络中将采用
GRU
模型 。
4.2
实现原理
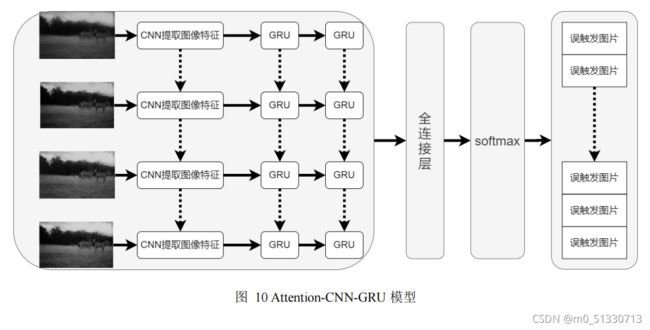
为解决单独的循环神经网络用于序列间图像分类不理想的问题,在基于上述实验分析的结论下,提出基于
Attention-CNN-GRU
的网络模型结构,该模型的结构图如图
10
所示,模型首先对输入的图像的序列,计算图像之间的相关系数变化值,确定注意力分布矩阵,然后通过深度卷积神经网络对输入网络的序列图像进行特征提取,并将提取后的特征和注意力矩阵依次送入由两层
GRU
网络堆叠的网络中,分析学习图像间在的时间方面关系,最后通过全连接层和
Softmax
层将预测结果输出。
其中,
CNN
结构模型选用上述实验中准确率最高的
Inception V4
,
GRU
层数为2层,每个
GRU
网络模型中包含
256
个
GRU
单元。同时,该方法的注意力机制在结合野生动物监测图像特点的基础上,通过序列图像相关系数的变化值,从而影响野生动物序列图片或误触发序列图片特征输入
GRU
网络模型的特征成分。
第五章 测试数据
5.1
实验与分析
为了验证基于模型的
Attention-CNN-GRU
有效性和可行性,通过对野生动物数据集
DS1
和数据集
DS
的基础上进行了多组对比实验。其中,训练网络模型的优化器采用
Adam
算法,初始学习率为
0.00001
,训练批次大小为
16
。每次实验过程中,模型测试结果取5次测试结果的平均值作为最终的输出结果。
首先,对于数据集
DS1
,分别采用
DGGNet
,
ResNet
,
Inception V4
三种不同的网络结构作为图像特征提取网络,然后将提取特征传递给相同结构的
GRU
模型,最后通过全连接层得到分类结果。
从表
3
中可以看出,在网络结构相同的情况下,卷积的网络的提取能力决定了分类结果的准确度。

其次,选用相同的神经网络
Inception V4
,对不同的循环网络结构模型的性能
进行比较分析。
从表
4
中可以看出,选用相同的神经网络
Inception V4
,循环网络结构
GRU和
LSTM
模型的性能基本相同,
GRU
模型性能仅比
LSTM
模型性能高
0.37%
,同时
GRU
模型结构相较简单,因此,该算法选用
GRU
模型作为循环网络结构。

随后,选用相同的深度卷积神经网络
Inception V4
和结构相同的
GRU
模型,加入注意力机制后,对比分析其准确率的影响从表
5
中可以看出,通过注意力机制的引入,对分类的准确率有着显著提升,比未加入注意力的分类模型准确率提高
2.21%
。

5.2
结果分析
综上所述,基于
Attention-CNN-GRU
野生动物分类识别方法,在野生动物图像数据集
DS1
上,通过与传统的深度卷积神经网络分类方法进行对比,在外接设
备出现误触或抖动的情况下,对野生动物分类识别的准确率可以达到
87.59%
,比采用传统的深度卷积神经网络分类方法高
2.81%
,经过在野生动物数据集合
DS
的实验验证表明,该方法可行有效。
第六章 功能特色
6.1
野生动物识别系统
6.1.1
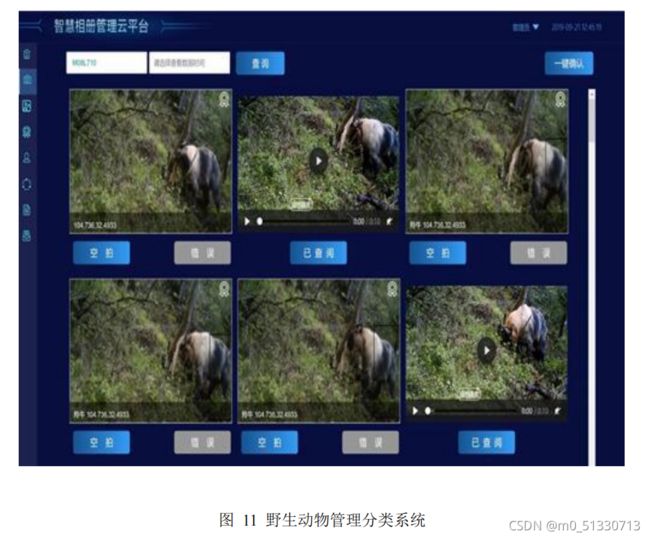
物种监测与识别
物种监测与识别基于
Attention-CNN-GRU
的识别分类方法。对红外触发器
所拍摄的野生动物图像进行经行特征提取后,将其反馈到训练算法中进行分类识
别,系统会自动对识别出的动物图像进行文件归类,如图
10
所示。
6.1.2
物种监测数据管理和分析
该系统可以对红外出发相机传输回来的图像进行监测管理,实时收集物种监测与识别系统传输的物种类型、
数量、发生时间、位置信息等,进行数据的二次编辑与确认,以保证其准确性,为分析保护地的物种种群结构、数量变化提供数
据支撑,并结合区域环境监测因子数据,研究环境变化对其影响。对处理成功的
图像信息,通过识别次数、未识别、已识别及已识别精准度分类统计,分物种及
时间梯度来分析物种自动化观测系统的运行效率;同时基于识别的数量分析保护
地的网格粗密度、多样性指数等,生成物种观测分析报告。
6.2
手机端
6.2.1
便携查询和知识科普
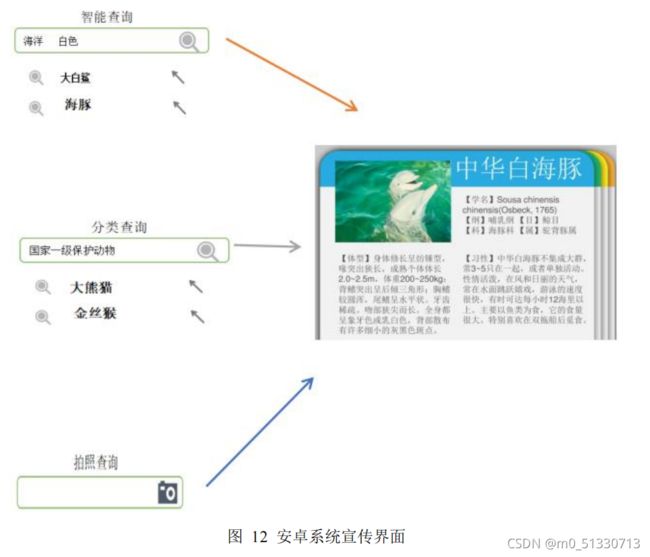
①动物智能查询
通过筛选动物特征值,辅助用户快速确定物种,并显示该物种主要信息(中英文及拉丁名称,主要特征,保护级别等)。
②动物分类查询
根据国家分级的保护动物和普通野生动物来分类,对于一级保护动物重点关注,重点保护。对于查询到的野生动物进行详细介绍,例如动物现存的数量、栖
息地以及其他和动物相关的信息。
③动物拍照咨询
如果用户不能确定该动物是否是国家保护动物,可将需要鉴定的动物拍照上传,由深度学习的系统或专业人员进行辨别并回复。
④野生动物知识科普
保护野生动物的第一步就是了解野生动物,对于查询到的野生动物,该
APP会提供相应的基本信息介绍,包括名称、图片、分布区域、生活习性、繁殖方式、保护级别等,让用户能够清晰了解到与野生动物相关的内容。
6.2.2
自由社区
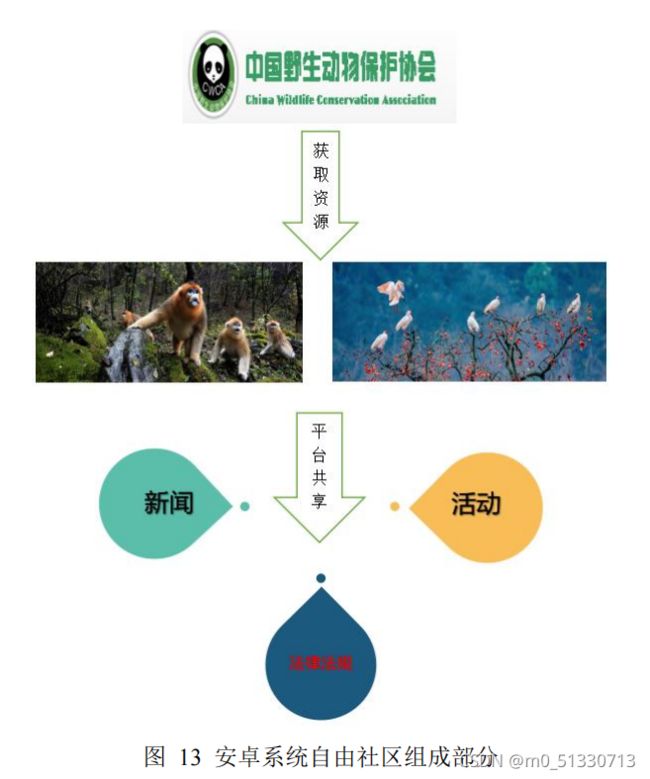
①张贴讨论
使用者可以在社区中以文字、图片或视频等形式自由的表达自己的思想,如提建议、讨论、提问、回答问题。
②日常分享
使用者可以制作相关的野生动物视频,分享动物日常,上传到平台中,让更多的人通过观看视频来了解动物保护,树立正确的动物保护意识。
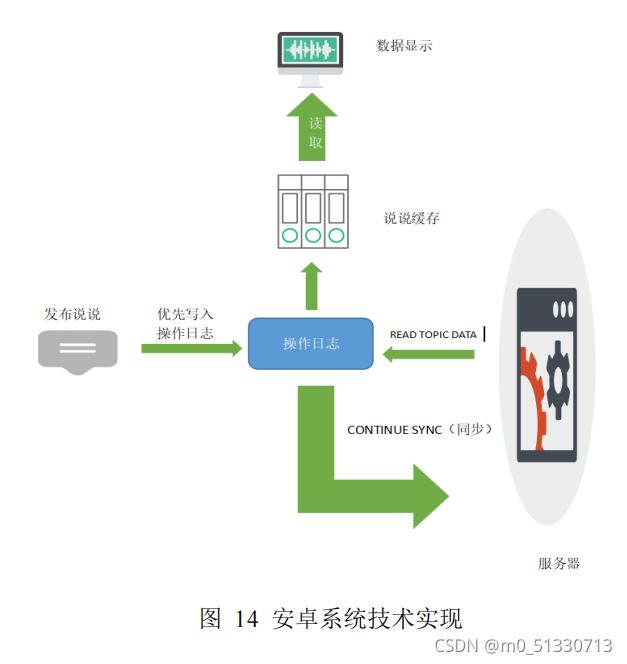
6.2.3
拍照实现
使用
vgg19
模型和
inception-v3
模型对宠物(野生动物)健康进行初步判断。
VGG-19
有
16
个卷积层,其卷积核大小都是
3*3
,步长为
1*1
,卷积层的通道数
分别是
64
、
128
、
256
、
512
,所有最大池化层的卷积核大小为
2*2
,步长为
1*1
,
最后有三个全连接层,通道数分别是
4096
,
4096
,
1000
。
①首先需要查看每层卷积操作的通道数是否与代码对应,尝试增加
batchnormalize
与一些激活函数,对
VGG-19
进行优化,能够极大的提高模型的准确率,同时有利于对模型的训练以及缩短训练所需时间。我们使用
VGG-19
作为骨干网络,再用一种目标检测算法完成对对象的目标检测,包括眼部:眼睛清澈及炯炯有神或过多的眼泪和眼屎或宠物不停用前足挠眼睛(可以以视频模式出现)鼻子:鼻子热干发红或鼻头有流鼻涕。耳道:耳道内推积耳垢。皮肤:毛发浓密健康或皮屑掉落,皮屑多或皮肤上有红点,脱毛现象。牙齿和口腔:口内的粘膜呈粉红色或牙齿黄、口臭或牙齿呈深红色或暗红色。尾巴:下垂。我们使用
inception-v3模型对宠物进行分类处理,我们可以利用谷歌在大型图像数据库
ImageNet
上训练好的
Inception-v3
模型进行图像分类。输入:一张图片。输出:与输入图相匹配的库内图片名及匹配分数。
②使用
YOLOv5
模型进行对宠物花纹毛色的识别从而进行身份的准确定位,发放“宠物身份证”。我们使用移动端高性价比的
MobileNetV3
作为骨干网络利用
YOLOv5
进行分类处理。首先进行的是猫和狗的种类分类,输入输出之后对两种种类的动物继续进行分别分类。对于猫狗的花纹、颜色以及一些能够识别的特征进行分类与识别像人类的身份证的形式上传到数据库中记录,对于宠物的主人我们也会提取信息进行身份验证与识别,对于宠物的丢失与寻找也会派上用场。
6.2.3
宠物主人识别
对于宠物主人的人脸识别与记录以及后期的识别我们采用卷积神经网络进行实现。首先,使用采集的照片训练自己的模型(图片格式
132*197
,每人
10张,
8
张加入训练集,
1
张
validation
,
1
张
test
)。随后,调用
keras.application中的
base_model
(
xception
、
inception
、
resnet50
、
VGG16
、
VGG19
)做特征提取,更换我们自己的全链接层。接着,把
basemodel
的顶层的卷积层和池化层放开
+
全链接层。在操作过程中要注意卷积层和池化层的放开不能放开太多,否则提前用大量图片训练的模型就失去效果,造成过拟合的情况。最后,经人脸识别和图像分析(打印每次训练的损失函数和准确度)之后得出的数据结果,用opencv
框出人脸。