机器学习算法 07 —— 朴素贝叶斯算法(拉普拉斯平滑系数、商品评论情感分析案例)
文章目录
- 系列文章
- 朴素贝叶斯
- 1 什么朴素贝叶斯分类
- 2 概率复习
-
- 2.1 朴素贝叶斯
- 2.2 文章分类举例
- 2.3 拉普拉斯平滑系数
- 3 案例:商品评论情感分析
- 4 朴素贝叶斯算法总结
-
- 4.1 优缺点
- 4.2 内容汇总
-
- 朴素贝叶斯(NB)原理
- 朴素⻉叶斯朴素在哪⾥?
- 为什么引⼊条件独⽴性假设?
- 在估计条件概率P(X∣Y)时出现概率为0的情况怎么办?
- 为什么属性独⽴性假设在实际情况中很难成⽴,但朴素⻉叶斯仍能取得较好的效果?
- 朴素贝叶斯和逻辑回归(LR)的区别
系列文章
机器学习算法 01 —— K-近邻算法(数据集划分、归一化、标准化)
机器学习算法 02 —— 线性回归算法(正规方程、梯度下降、模型保存)
机器学习算法 03 —— 逻辑回归算法(精确率和召回率、ROC曲线和AUC指标、过采样和欠采样)
机器学习算法 04 —— 决策树(ID3、C4.5、CART,剪枝,特征提取,回归决策树)
机器学习算法 05 —— 集成学习(Bagging、随机森林、Boosting、AdaBost、GBDT)
机器学习算法 06 —— 聚类算法(k-means、算法优化、特征降维、主成分分析PCA)
机器学习算法 07 —— 朴素贝叶斯算法(拉普拉斯平滑系数、商品评论情感分析案例)
机器学习算法 08 —— 支持向量机SVM算法(核函数、手写数字识别案例)
机器学习算法 09 —— EM算法(马尔科夫算法HMM前置学习,EM用硬币案例进行说明)
机器学习算法 10 —— HMM模型(马尔科夫链、前向后向算法、维特比算法解码、hmmlearn)
朴素贝叶斯
学习目标:
- 说明条件概率与联合概率
- 说明⻉叶斯公式、以及特征独⽴的关系
- 记忆⻉叶斯公式
- 知道拉普拉斯平滑系数
- 应⽤⻉叶斯公式实现概率的计算
- 会使⽤朴素⻉叶斯对商品评论进⾏情感分析
1 什么朴素贝叶斯分类
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类,而朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。
像下面这两幅图,对于垃圾邮件和文章的分类,只需计算它们属于各个类别的概率,概率最大的一类就它们被划分到的类别。这也是和K-近邻算法、决策树算法分类的不同之处,用概率来分类。
2 概率复习
假设现在有两个事件A和B和C。
联合概率:包含多个事件,且所有事件同时发生的概率,记作P(A, B)。
条件概率:在事件A已经发生的情况下,事件B发生的概率,记作P(A|B)。
相互独立:事件A和事件B没有任何关系,所以公式P(A, C)=P(A)P©成立,且P(A, B|C)=P(A|C)P(B|C)。
贝叶斯公式: P ( A ∣ B ) = P ( B ∣ A ) P ( A ) P ( B ) P(A|B)=\frac{P(B|A)P(A)}{P(B)} P(A∣B)=P(B)P(B∣A)P(A),当我们无法直接计算条件概率P(A|B)时,贝叶斯公式可以帮助我们从另一个角度计算条件概率。
现在来个简单的例子:
| 样本编号 | 职业 | 体型 | 女生是否喜欢 |
|---|---|---|---|
| 1 | 程序员 | 超重 | 不喜欢 |
| 2 | 产品 | 匀称 | 喜欢 |
| 3 | 程序员 | 匀称 | 喜欢 |
| 4 | 程序员 | 超重 | 喜欢 |
| 5 | 美工 | 匀称 | 不喜欢 |
| 6 | 美工 | 超重 | 不喜欢 |
| 7 | 产品 | 匀称 | 喜欢 |
问题如下:
-
女生会喜欢的概率?
P(喜欢)=4/7,女生是否喜欢总共有7个样本,其中喜欢有4个。 -
职业程序员且体型匀称的概率?
P(程序员, 匀称)=1/7,总共有七个样本,其中是程序员并且体型匀称的只有1个。 -
在女生会喜欢的条件下,职业是程序员的概率?
P(程序员|喜欢)=2/4=1/2,女生喜欢的样本总共有4个,其中有2个程序员 -
在女生会喜欢的条件下,职业是程序员且体型超重的概率?
P(程序员, 超重|喜欢)=1/4,女生喜欢的样本总共有4个,其中是程序员且体型超重的只有1个
2.1 朴素贝叶斯
上面这几道问题都比较简单,我们直接观察表格都可以得出结论。那么假如我们想计算职业是产品且体型超重条件下女生会喜欢的概率?这下没法直接观察得出结论了,我们需要用到贝叶斯公式。
P ( 喜 欢 ∣ 产 品 , 超 重 ) = P ( 产 品 , 超 重 ∣ 喜 欢 ) ⋅ P ( 喜 欢 ) P ( 产 品 , 超 重 ) P(喜欢|产品, 超重)=\frac{ P(产品,超重|喜欢)·P(喜欢)}{P(产品,超重)} P(喜欢∣产品,超重)=P(产品,超重)P(产品,超重∣喜欢)⋅P(喜欢)
这个式子中,由于无法直接求出P(喜欢|产品,超重),所以利用贝叶斯公式将其转换。然而我们依然无法知道P(产品,超重|喜欢)的概率,因为样本数量太少了,如果仅根据已知的数据P(产品,超重|喜欢)的结果应该是0,但这显然不符合现实。
如果我们假设职业和体型是独立的,那么 P ( 产 品 , 超 重 ) = P ( 产 品 ) P ( 超 重 ) P(产品,超重)=P(产品)P(超重) P(产品,超重)=P(产品)P(超重)成立,就可以计算了。当然,根据我们有限的样本,这个其实是不成立的,不过朴素贝叶斯就是帮助我们解决这种问题的。
==朴素贝叶斯之所以有朴素二字,就是假定了特征与特征之间相互独立。==所以如果按照朴素贝叶斯的思路,计算结果如下:
P(喜欢)= 4/7
P(产品,超重)=P(产品)P(超重)= 2/7 * 3/7 = 6/49
P(产品,超重|喜欢)=P(产品|喜欢)P(超重|喜欢)= 1/2 * 1/4 = 1/8
因此,P(喜欢|产品,超重)= (1/8 * 4/7)/(6/49) = 7/12
2.2 文章分类举例
现在我们把贝叶斯公式应用到文章分类中
P ( C ∣ F 1 , F , 2 , . . . ) = P ( F 1 , F , 2 , . . . ∣ C ) P ( C ) P ( F 1 , F , 2 , . . . ) P(C|F_1, F_,2,...)=\frac{P(F_1, F_,2,...|C)P(C)}{P(F_1, F_,2,...)} P(C∣F1,F,2,...)=P(F1,F,2,...)P(F1,F,2,...∣C)P(C)
- W = F 1 , F , 2 , . . . W=F_1, F_,2,... W=F1,F,2,...,其中 F i F_i Fi表示某文章篇中的某个词,W是给定文章的一个特征,C是文章类别
- P©表示某种种文章类别的概率【某文章类别的数量 / 总文章数量】
- P ( F 1 , F 2 , . . . ) P(F_1,F_2,...) P(F1,F2,...)是预测文档中每个词的概率
- P(W|C)表示在某种文章类别的条件下某个词(特征)的概率
- P ( F 1 ∣ C ) = N i N P(F_1|C)=\frac{N_i}{N} P(F1∣C)=NNi, N i N_i Ni是词 F 1 F_1 F1在类别C中所有文章里出现的次数,N是类别C中所有词的所有出现次数。
现在我们来一个文章分类举例,通过前四个训练样本(⽂章),判断第五篇⽂章,是否属于China类。
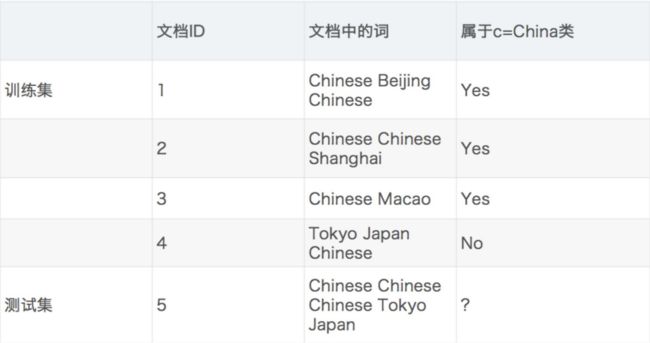
根据上面的公式(2) P ( C ∣ F 1 , F 2 , . . . ) P(C|F_1,F_2,...) P(C∣F1,F2,...),我们知道计算测试集属于China类别的概率如下【 P ( c ) = 3 4 P(c)=\frac{3}{4} P(c)=43】:
P ( c ∣ C h i n e s e , C h i n e s e , C h i n e s e , T o k y o , J a p a n ) = P ( C h i n e s e , C h i n e s e , C h i n e s e , T o k y o , J a p a n ∣ c ) ⋅ P ( c ) P ( C h i n e s e , C h i n e s e , C h i n e s e , T o k y o , J a p a n ) = P ( C h i n e s e ∣ c ) 3 ⋅ P ( T o k y o ∣ c ) ⋅ P ( J a p a n ∣ c ) ⋅ P ( c ) P ( C h i n e s e ) 3 ⋅ P ( T o k y o ) ⋅ P ( J a p a n ) P(c|Chinese,Chinese,Chinese,Tokyo,Japan)=\frac{P(Chinese,Chinese,Chinese,Tokyo,Japan|c) \cdot P(c)}{P(Chinese,Chinese,Chinese,Tokyo,Japan)}\\ =\frac{P(Chinese|c)^3 \cdot P(Tokyo|c) \cdot P(Japan|c) \cdot P(c)}{P(Chinese)^3 \cdot P(Tokyo) \cdot P(Japan)} P(c∣Chinese,Chinese,Chinese,Tokyo,Japan)=P(Chinese,Chinese,Chinese,Tokyo,Japan)P(Chinese,Chinese,Chinese,Tokyo,Japan∣c)⋅P(c)=P(Chinese)3⋅P(Tokyo)⋅P(Japan)P(Chinese∣c)3⋅P(Tokyo∣c)⋅P(Japan∣c)⋅P(c)
1、 P ( F 1 ∣ C ) = P ( C h i n e s e ∣ c ) P(F_1|C)=P(Chinese|c) P(F1∣C)=P(Chinese∣c)表示在属于China类的情况下,词Chinese出现的概率。根据上表的训练集,文档编号123属于China类,Chinese出现了5次,Beijing出现1次,Shanghai出现1次,Macao出现1次,所以 P ( C h i n e s e ∣ c ) = 5 8 P(Chinese|c)=\frac{5}{8} P(Chinese∣c)=85
2、由于属于China类的文档中没有出现Tokyo和Macao,所以 P ( T o k y o ∣ c ) = 0 8 = 0 P(Tokyo|c)=\frac{0}{8}=0 P(Tokyo∣c)=80=0、 P ( J a p a n ∣ c ) = 0 8 = 0 P(Japan|c)=\frac{0}{8}=0 P(Japan∣c)=80=0。
3、由于出现了0,所以 P ( c ∣ C h i n e s e , C h i n e s e , C h i n e s e , T o k y o , J a p a n ) = 0 P(c|Chinese,Chinese,Chinese,Tokyo,Japan)=0 P(c∣Chinese,Chinese,Chinese,Tokyo,Japan)=0,意思是测试集不可能属于China类?显然这也是不合理的。
4、现在我们计算下不属于China类的概率【只有文档4不属于China】。
P ( C h i n a ∣ c ˉ ) = 1 3 P ( J a p a n ∣ c ˉ ) = 1 3 P ( T o k y o ∣ c ˉ ) = 1 3 P ( c ˉ ∣ C h i n e s e , C h i n e s e , C h i n e s e , T o k y o , J a p a n ) = P ( C h i n e s e ∣ c ˉ ) 3 ⋅ P ( T o k y o ∣ c ˉ ) ⋅ P ( J a p a n ∣ c ˉ ) ⋅ P ( c ) P ( C h i n e s e ) 3 ⋅ P ( T o k y o ) ⋅ P ( J a p a n ) P(China|\bar c)=\frac{1}{3}\\ P(Japan|\bar c)=\frac{1}{3}\\ P(Tokyo|\bar c)=\frac{1}{3}\\ P(\bar c|Chinese,Chinese,Chinese,Tokyo,Japan)=\frac{P(Chinese|\bar c)^3 \cdot P(Tokyo|\bar c) \cdot P(Japan|\bar c) \cdot P(c)}{P(Chinese)^3 \cdot P(Tokyo) \cdot P(Japan)} P(China∣cˉ)=31P(Japan∣cˉ)=31P(Tokyo∣cˉ)=31P(cˉ∣Chinese,Chinese,Chinese,Tokyo,Japan)=P(Chinese)3⋅P(Tokyo)⋅P(Japan)P(Chinese∣cˉ)3⋅P(Tokyo∣cˉ)⋅P(Japan∣cˉ)⋅P(c)
从上面的计算中。我们得到 P ( T o k y o ∣ c ) P(Tokyo|c) P(Tokyo∣c)和 P ( J a p a n ∣ c ) P(Japan|c) P(Japan∣c)都是0,这是由于样本数量太少导致的,一旦出现这种情况最终计算结果就会是0,而这也不符合逻辑。所以我们需要一个解决方法——拉普拉斯平滑系数
2.3 拉普拉斯平滑系数
我们前面计算之所以会出现0,是因为某个词在某种文章下没有出现导致的。上面那个例子里就是测试集里的词Tokyo和Japan在训练集中的China类文章里没有出现过,所以公式 P ( F 1 ∣ C ) = N i N P(F_1|C)=\frac{N_i}{N} P(F1∣C)=NNi的 N i N_i Ni为0。而拉普拉斯系数就是给 N i N_i Ni和 N N N加上一个值,来避免这种情况发生。
公式如下:
P ( F 1 ∣ C ) = N i + α N + α m P(F_1|C)=\frac{N_i+\alpha}{N+\alpha m} P(F1∣C)=N+αmNi+α
其中
- α \alpha α即拉普拉斯平滑系数,通常为1。
- m是训练集文档中统计出的特征词个数。在上面例子里,训练集中有4篇文章,共有6种词,所以m=6。
现在按照拉普拉斯平滑系数重新计算。
# 这个⽂章是需要计算是不是China类:
⾸先计算是China类的概率: 0.0003
P(Chinese|C) = 5/8 -->(经过拉普拉斯平滑系数处理) 6/14
P(Tokyo|C) = 0/8 --> 1/14
P(Japan|C) = 0/8 --> 1/14
接着计算不是China类的概率: 0.0001
P(Chinese|C) = 1/3 --> 2/9
P(Tokyo|C) = 1/3 --> 2/9
P(Japan|C) = 1/3 --> 2/9
由于测试集的预测文章 是China类的概率0.0003 > 不是China类的概率0.0001,故文档5是China类
3 案例:商品评论情感分析
API:sklearn.naive_bayes.MultinomialNB(alpha = 1.0),其中alpha就是拉普拉斯平滑系数。
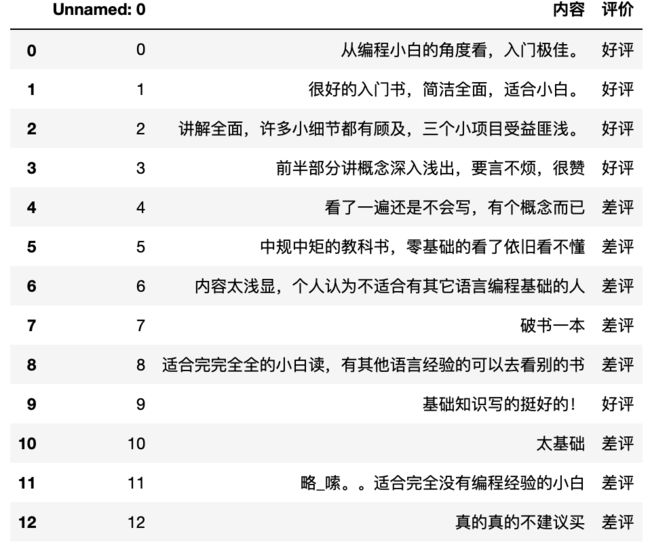
商品评论情感分析:通过对评论分析,得出该评论是好评还是差评。
数据下载:https://download.csdn.net/download/qq_39763246/21453691
代码:
import pandas as pd
import numpy as np
import jieba
import matplotlib.pyplot as plt
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
# 1. 获取数据(记得转换编码)
data = pd.read_csv("./data/commodity_comment/书籍评价.csv", encoding="gbk")
# 2. 数据基本处理
# 2.1 读取停用词文件【停用词来自网上,用于将一些没什么情感的词去除】
stop_words = []
with open('./data/commodity_comment/stopwords.txt', 'r', encoding='utf-8') as f:
lines = f.readlines() # 读取一行
for temp in lines:
line = temp.strip() # 去掉空格
stop_words.append(line) # 追加到停用词列表
# 由于文件来自网络,可能里面有重复词,所以先将其转换为set集合去重
stop_words = list(set(stop_words)) # 事实证明 用len()查看后,并没有重复的
# 2.2 把【内容】列转换成标准格式
comment_list = []
for temp in data["内容"]:
# temp是每一条内容,对它们进行分词处理
segment = jieba.cut(temp) # segment是分好词的对象
segment_str = ' '.join(segment) # 用空格分开每个词
comment_list.append(segment_str)
# 3. 特征工程 - 特征提取 中文文本提取,统计词的个数
# 3.1 加载停用词并实例化对象
count = CountVectorizer(stop_words=stop_words)
# 3.2 进行词数统计(可以得到所有内容中所有词的数量统计)
X = count.fit_transform(comment_list)
print("词:\n", count.get_feature_names()) # 打印所有词
print("统计:\n", X.toarray()) # 用toarray()转换为词频矩阵后,更容易观察,每一行就是一个评论,每一列对应一个词频
# 4. 数据分割。这一步骤以往是在 2.数据基本处理
# 用词频前10行作为训练集,后3行作为测试集
x_train = X.toarray()[:10, :]
y_train = (data["评价"].values)[:10] # 【评价】列是目标值,用前10作为训练集。values是只要值,没要行索引
x_test = X.toarray()[10:, :]
y_test = (data["评价"].values)[10:]
# 5. 模型训练
mnb = MultinomialNB()
mnb.fit(x_train, y_train)
# 6. 模型评估
print("预测值:", mnb.predict(x_test))
print("真实值:", y_test)
print("精确度:", mnb.score(x_test, y_test))
# 由于样本比较少,所以精确度能达到100%
#------------------------------------------------------------------------
# 我们可以对目标值【评价】进行01转换,好评为1,差评为0,并将其作为新列【评价标记】。
# 通常我们经常是用01来表示的,所以上面代码数据集划分处,可以用data['评价标记']代替
data.loc[data["评价"] == "好评", "评价标记"] = 1
data.loc[data["评价"] == "差评", "评价标记"] = 0
#------------------------------------------------------------------------

4 朴素贝叶斯算法总结
4.1 优缺点
优点:
-
朴素⻉叶斯模型发源于古典数学理论,有稳定的分类效率
-
对缺失数据不太敏感,算法也⽐较简单,常⽤于⽂本分类
-
分类准确度⾼,速度快
缺点:
-
由于使⽤了样本属性独⽴性的假设,所以如果特征属性关联性比较强时效果就不太好
-
需要计算先验概率,⽽先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳
4.2 内容汇总
朴素贝叶斯(NB)原理
朴素⻉叶斯法是基于⻉叶斯定理与特征条件独⽴假设的分类⽅法。
-
对于给定的待分类项x,通过学习到的模型计算后验概率分布,
-
即:在此项出现的条件下各个⽬标类别出现的概率,将后验概率最⼤的类作为x所属的类别。
朴素⻉叶斯朴素在哪⾥?
在计算条件概率分布P(X=x∣Y=c_k)时,NB引⼊了⼀个很强的条件独⽴假设,即,当Y确定时,X的各个特征分量取值之间相互独⽴。
为什么引⼊条件独⽴性假设?
为了避免⻉叶斯定理求解时⾯临的组合爆炸、样本稀疏问题。
假设条件概率分为

在估计条件概率P(X∣Y)时出现概率为0的情况怎么办?
解决这⼀问题的⽅法是采⽤⻉叶斯估计。
简单来说,引⼊ α \alpha α,
-
当 α = 0 \alpha=0 α=0时,就是普通的极⼤似然估计;
-
当 α = 1 \alpha=1 α=1时称为拉普拉斯平滑。
为什么属性独⽴性假设在实际情况中很难成⽴,但朴素⻉叶斯仍能取得较好的效果?
⼈们在使⽤分类器之前,⾸先做的第⼀步(也是最重要的⼀步)往往是特征选择,这个过程的⽬的就是为了排除特征之间的共线性、选择相对较为独⽴的特征;
对于分类任务来说,只要各类别的条件概率排序正确,⽆需精准概率值就可以得出正确分类;
如果属性间依赖对所有类别影响相同,或依赖关系的影响能相互抵消,则属性条件独⽴性假设在降低计算复杂度的同时不会对性能产⽣负⾯影响。
朴素贝叶斯和逻辑回归(LR)的区别
区别一:
1、朴素⻉叶斯是⽣成模型,
-
根据已有样本进⾏⻉叶斯估计学习出先验概率P(Y)和条件概率P(X|Y),
-
进⽽求出联合分布概率P(XY),
-
最后利⽤⻉叶斯定理求解P(Y|X),
2、⽽LR是判别模型,
- 根据极⼤化对数似然函数直接求出条件概率P(Y|X);
从概率框架的⻆度来理解机器学习,主要有两种策略:
第⼀种:给定 x, 可通过直接建模 P ( c ∣ x ) P(c|x) P(c∣x) 来预测 c,这样得到的是"判别式模型" (discriminative models);
第⼆种:也可先对联合概率分布 P ( x , c ) P(x,c) P(x,c) 建模,然后再由此获得$ P(c |x)$, 这样得到的是"⽣成式模型" (generative models) ;
显然,前⾯介绍的逻辑回归、决策树、都可归⼊判别式模型的范畴,还有后⾯学到的BP神经⽹络、⽀持向量机等;
对⽣成式模型来说,必然需要考虑 P ( c ∣ x ) = P ( x , c ) P ( x ) P(c|x)=\frac{P(x,c)}{P(x)} P(c∣x)=P(x)P(x,c)
区别二:
朴素⻉叶斯是基于很强的条件独⽴假设(在已知分类Y的条件下,各个特征变量取值是相互独⽴的),⽽LR则对此没有要求;
区别三:
朴素⻉叶斯适⽤于数据集少的情景,⽽LR适⽤于⼤规模数据集。
进⼀步说明。
前者是⽣成式模型,后者是判别式模型,⼆者的区别就是⽣成式模型与判别式模型的区别。
⾸先,朴素贝叶斯通过已知样本求得先验概率P(Y), 及条件概率P(X|Y), 对于给定的实例,计算联合概率,进⽽求出后验概率。也就是说,它尝试去找到底这个数据是怎么⽣成的(产⽣的),然后再进⾏分类。哪个类别最有可能产⽣这个信号,就属于那个类别。
-
优点: 样本容量增加时,收敛更快;隐变量存在时也可适⽤。
-
缺点:时间⻓;需要样本多;浪费计算资源
相⽐之下,逻辑回归不关⼼样本中类别的⽐例及类别下出现特征的概率,它直接给出预测模型的式⼦。设每个特征都有⼀个权重,训练样本数据更新权重w,得出最终表达式。
优点:
-
直接预测往往准确率更⾼;
-
简化问题;
-
可以反应数据的分布情况,类别的差异特征;
-
适⽤于较多类别的识别。
缺点:
-
收敛慢;
-
不适⽤于有隐变量的情况。