1+X 云计算运维与开发(中级)案例实战——ZooKeeper集群部署
传送门
教育部:职业教育将启动“1+X”证书制度改革
职业教育改革1+X证书制度试点启动
1+X成绩/证书查询入口
文章目录
- ==什么是zookeeper???==
- 1. 案例目标
- 2. 案例分析
-
- 2.1 规划节点
- 2.2 基础准备
- 3. 案例实施
-
- 3.1 基础环境配置
- 3.2 搭建ZooKeeper集群
什么是zookeeper???

ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为
分布式应用提供一致性服务的软件
-
功能: 配置维护、域名服务、分布式同步、组服务等
-
目标:
封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户 -
原理: ZooKeeper是以Fast Paxos算法为基础,Paxos 算法存在活锁的问题,即当有多个proposer交错提交时,有可能互相排斥导致没有一个proposer能提交成功,而Fast Paxos作了一些优化,
通过选举产生一个leader (领导者),只有leader才能提交proposer,具体算法可见Fast Paxos。因此,要想弄懂ZooKeeper首先得对Fast Paxos有所了解。 -
ZooKeeper的基本运转流程:
1、选举Leader
2、同步数据
3、选举Leader过程中算法有很多,但要达到的选举标准是一致的
4、Leader要具有最高的执行ID,类似root权限
5、集群中大多数的机器得到响应并接受选出的Leader
1. 案例目标
- 了解ZooKeeper分布式应用程序协调服务
- 使用三台机器搭建ZooKeeper集群
- 使用ZooKeeper集群
2. 案例分析
2.1 规划节点
ZooKeeper集群系统的节点规划,节点规划如下
| IP | 主机名 | 节点 |
|---|---|---|
| 172.16.51.170 | zookeeper1 | 集群节点 |
| 172.16.51.171 | zookeeper2 | 集群节点 |
| 172.16.51.172 | zookeeper3 | 集群节点 |
2.2 基础准备
登录OpenStack平台,使用提供的CentOS_7.2_x86_64_XD.qcow2镜像,flavor使用2vCPU/4GB内存/50GB硬盘创建云主机。使用提供的zookeeper-3.4.14.tar.gz包和gpmall-repo文件夹,安装zookeeper服务。
3. 案例实施
3.1 基础环境配置
- 1.修改主机名
使用hostnamectl命令修改三台主机的主机名
zookeeeper1节点
[root@localhost ~]# hostnamectl set-hostname zookeeper1
zookeeeper2节点
[root@localhost ~]# hostnamectl set-hostname zookeeper2
zookeeeper3节点
[root@localhost ~]# hostnamectl set-hostname zookeeper3
验证:修改完之后重新连接secureCRT,并查看主机名:
zookeeeper1节点
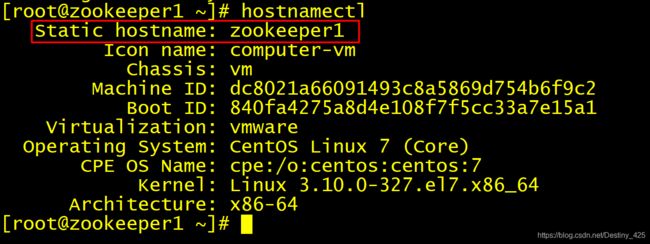
zookeeeper2节点
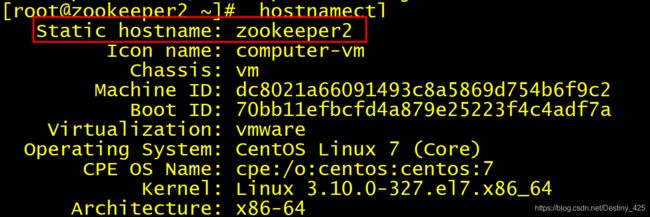
zookeeeper3节点
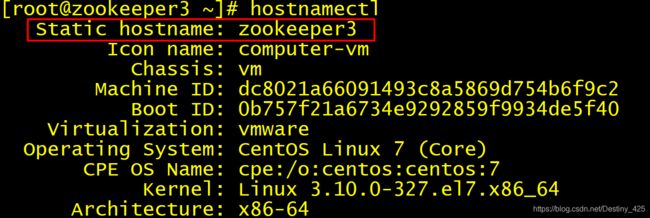
- 2.编辑hosts文件
修改三台集群虚拟机的/etc/hosts配置文件
vi /etc/hosts
//添加以下三行
172.16.51.170 zookeeeper1
172.16.51.171 zookeeeper2
172.16.51.172 zookeeeper3
所有节点都要配置
- 3.配置yum源
数据库集群需要安装MariaDB数据库服务,需要给集群虚拟机配置yum安装源文件,使用提供的gpmall-repo文件上传至三个虚拟机的/opt目录下,配置本地yum源。
修改三台集群虚拟机的yum源配置文件
cat /etc/yum.repos.d/local.repo
[base]
name=centos7
baseurl=file:///mnt/cd
gpgcheck=0
enabled=1
[mariadb]
name=mariadb
baseurl=file:///opt/gpmall-repo
gpgcheck=0
enabled=1
3.2 搭建ZooKeeper集群
- 1.安装JDK环境
给三个节点安装
Java JDK环境,命令如下
# yum install -y java java-devel
//验证
# java -version
openjdk version "1.8.0_222"
OpenJDK Runtime Environment (build 1.8.0_222-b10)
OpenJDK 64-Bit Server VM (build 25.222-b10, mixed mode)
- 2.解压ZooKeeper软件包
将zookeeper-3.4.14.tar.gz软件包上传至3个节点的/root目录下,进行解压操作,3个节点均执行命令如下
# tar -zxvf zookeeper-3.4.14.tar.gz
- 3.修改3个节点配置文件
在zookeeper1节点,进入zookeeper-3.4.14/conf目录下,修改zoo_sample.cfg文件为zoo.cfg,并编辑该文件内容如下
[root@zookeeper1 ~]# cd zookeeper-3.4.14/conf/
[root@zookeeper1 conf]# mv zoo_sample.cfg zoo.cfg
[root@zookeeper1 conf]# vi zoo.cfg
//最后添加以下三行
server.1=172.16.51.170:2888:3888
server.2=172.16.51.171:2888:3888
server.3=172.16.51.172:2888:3888
[root@zookeeper1 conf]# grep -n '^'[a-Z] zoo.cfg
2:tickTime=2000
5:initLimit=10
8:syncLimit=5
12:dataDir=/tmp/zookeeper
14:clientPort=2181
29:server.1=172.16.51.170:2888:3888
30:server.2=172.16.51.171:2888:3888
31:server.3=172.16.51.172:2888:3888
命令解析:
initLimit:ZooKeeper集群模式下包含多个zk进程,其中一个进程为leader,余下的进程为follower。当follower最初与leader建立连接时,它们之间会传输相当多的数据,尤其是follower的数据落后leader很多。initLimit配置follower与leader之间建立连接后进行同步的最长时间。
syncLimit:配置follower和leader之间发送消息,请求和应答的最大时间长度。
tickTime:tickTime则是上述两个超时配置的基本单位,例如对于initLimit,其配置值为5,说明其超时时间为 2000ms * 5 = 10秒。
server.id=host:port1:port2:其中id为一个数字,表示zk进程的id,这个id也是dataDir目录下myid文件的内容。host是该zk进程所在的IP地址,port1表示follower和leader交换消息所使用的端口,port2表示选举leader所使用的端口。
dataDir:其配置的含义跟单机模式下的含义类似,不同的是集群模式下还有一个myid文件。myid文件的内容只有一行,且内容只能为1 - 255之间的数字,这个数字亦即上面介绍server.id中的id,表示zk进程的id。
注意:zookeeper2和zookeeper3节点的操作与修改的配置和zookeeper1节点一样。
- 4.创建myid文件
在3台机器dataDir目录(此处为 /tmp/zookeeper)下,分别创建一个myid文件,文件内容分别只有一行,其内容为1,2,3。即文件中只有一个数字,这个数字即为上面zoo.cfg配置文件中指定的值。ZooKeeper是根据该文件来决定ZooKeeper集群各个机器的身份分配。
创建myid文件,命令如下
zookeeper1节点
[root@zookeeper1 ~]# mkdir /tmp/zookeeper
[root@zookeeper1 ~]# vi /tmp/zookeeper/myid
[root@zookeeper1 ~]# cat /tmp/zookeeper/myid
1
zookeeper2节点
[root@zookeeper2 ~]# mkdir /tmp/zookeeper
[root@zookeeper2 ~]# vi /tmp/zookeeper/myid
[root@zookeeper2 ~]# cat /tmp/zookeeper/myid
2
zookeeper3节点
[root@zookeeper3 ~]# mkdir /tmp/zookeeper
[root@zookeeper3 ~]# vi /tmp/zookeeper/myid
[root@zookeeper3 ~]# cat /tmp/zookeeper/myid
3
- 5.启动ZooKeeper服务
在3台节点的zookeeper/bin目录下执行命令如下:
zookeeper1节点
[root@zookeeper1 bin]# ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /root/zookeeper-3.4.14/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@zookeeper1 bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /root/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: follower
zookeeper2节点
[root@zookeeper2 bin]# ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /root/zookeeper-3.4.14/bin/../conf/zoo.cfg
Starting zookeeper ... already running as process 10175.
[root@zookeeper2 bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /root/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: leader
zookeeper3节点
[root@zookeeper3 bin]# ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /root/zookeeper-3.4.14/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@zookeeper3 bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /root/zookeeper-3.4.14/bin/../conf/zoo.cfg
Mode: follower
3个节点,zookeeper2为leader,其他的都是follower
至此,ZooKeeper集群配置完毕

上一篇:1+X 云计算运维与开发(中级)案例实战——构建读写分离的数据库集群
下一篇:1+X 云计算运维与开发(中级)案例实战——Kafka集群部署