R语言 SVM(线性可分、线性不可分、多分类)
关注微信公共号:小程在线

关注CSDN博客:程志伟的博客
R版本:3.6.1
setwd('G:\\R语言\\大三下半年\\数据挖掘:R语言实战\\')
> library("e1071", lib.loc="H:/Program Files/R/R-3.6.1/library")
Warning message:
程辑包‘e1071’是用R版本3.6.2 来建造的
#############模拟线性可分下的SVM
> set.seed(12345)
> x<-matrix(rnorm(n=40*2,mean=0,sd=1),ncol=2,byrow=TRUE)
> y<-c(rep(-1,20),rep(1,20))
> x[y==1,]<-x[y==1,]+1.5
> data_train<-data.frame(Fx1=x[,1],Fx2=x[,2],Fy=as.factor(y)) #生成训练样本集
> x<-matrix(rnorm(n=20,mean=0,sd=1),ncol=2,byrow=TRUE)
> y<-sample(x=c(-1,1),size=10,replace=TRUE)
> x[y==1,]<-x[y==1,]+1.5
> data_test<-data.frame(Fx1=x[,1],Fx2=x[,2],Fy=as.factor(y)) #生成测试样本集
> plot(data_train[,2:1],col=as.integer(as.vector(data_train[,3]))+2,pch=8,cex=0.7,main="训练样本集-1和+1类散点图")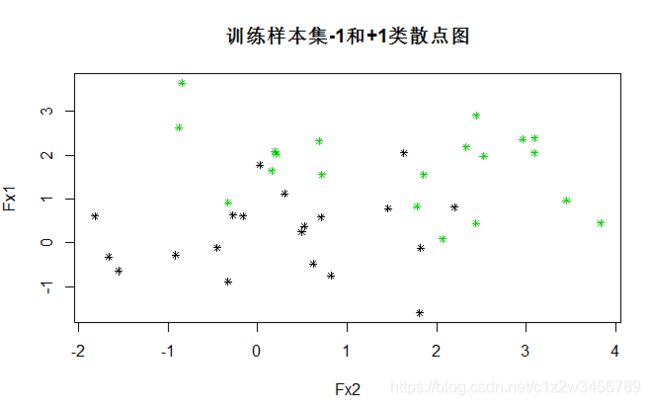
> SvmFit<-svm(Fy~.,data=data_train,type="C-classification",kernel="linear",cost=10,scale=FALSE)
> summary(SvmFit)
Call:
svm(formula = Fy ~ ., data = data_train, type = "C-classification",
kernel = "linear", cost = 10, scale = FALSE)
Parameters:
SVM-Type: C-classification
SVM-Kernel: linear
cost: 10
Number of Support Vectors: 16
( 8 8 )
Number of Classes: 2
Levels:
-1 1
> SvmFit$index
[1] 1 6 7 10 11 16 17 20 22 24 28 31 33 35 36 37
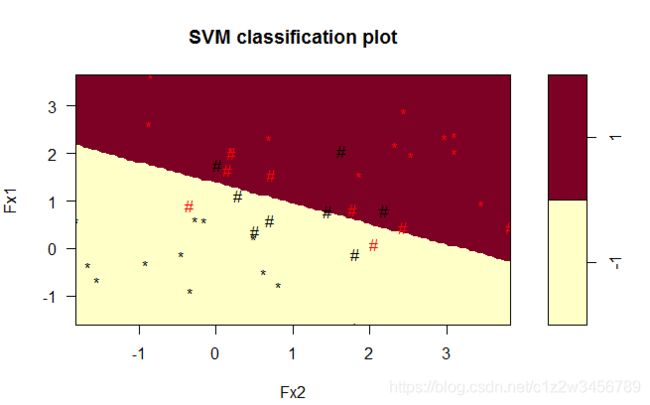
> plot(x=SvmFit,data=data_train,formula=Fx1~Fx2,svSymbol="#",dataSymbol="*",grid=100)
> SvmFit<-svm(Fy~.,data=data_train,type="C-classification",kernel="linear",cost=0.1,scale=FALSE)
> summary(SvmFit)
Call:
svm(formula = Fy ~ ., data = data_train, type = "C-classification",
kernel = "linear", cost = 0.1, scale = FALSE)
Parameters:
SVM-Type: C-classification
SVM-Kernel: linear
cost: 0.1
Number of Support Vectors: 25
( 12 13 )
Number of Classes: 2
Levels:
-1 1
##############10折交叉验证选取损失惩罚参数C
> set.seed(12345)
> tObj<-tune.svm(Fy~.,data=data_train,type="C-classification",kernel="linear",
+ cost=c(0.001,0.01,0.1,1,5,10,100,1000),scale=FALSE)
> summary(tObj)
Parameter tuning of ‘svm’:
- sampling method: 10-fold cross validation
- best parameters:
cost
5
- best performance: 0.175
- Detailed performance results:
cost error dispersion
1 1e-03 0.675 0.3129164
2 1e-02 0.375 0.3584302
3 1e-01 0.225 0.2486072
4 1e+00 0.200 0.2297341
5 5e+00 0.175 0.2371708
6 1e+01 0.175 0.2371708
7 1e+02 0.175 0.2371708
8 1e+03 0.175 0.2371708
> BestSvm<-tObj$best.model
> summary(BestSvm)
Call:
best.svm(x = Fy ~ ., data = data_train, cost = c(0.001, 0.01,
0.1, 1, 5, 10, 100, 1000), type = "C-classification", kernel = "linear",
scale = FALSE)
Parameters:
SVM-Type: C-classification
SVM-Kernel: linear
cost: 5
Number of Support Vectors: 16
( 8 8 )
Number of Classes: 2
Levels:
-1 1
> yPred<-predict(BestSvm,data_test)
> (ConfM<-table(yPred,data_test$Fy))
yPred -1 1
-1 6 0
1 1 3
> (Err<-(sum(ConfM)-sum(diag(ConfM)))/sum(ConfM))
[1] 0.1
训练样本40个观测。不同颜色代表不同类别。
当损失惩罚参数C=10时,一共16个向量。
利用tune.svm函数尝试不同的惩罚参数。
> ##############模拟线性不可分下的SVM
> set.seed(12345)
> x<-matrix(rnorm(n=400,mean=0,sd=1),ncol=2,byrow=TRUE)
> x[1:100,]<-x[1:100,]+2
> x[101:150,]<-x[101:150,]-2
> y<-c(rep(1,150),rep(2,50))
> data<-data.frame(Fx1=x[,1],Fx2=x[,2],Fy=as.factor(y))
> flag<-sample(1:200,size=100)
> data_train<-data[flag,]
> data_test<-data[-flag,]
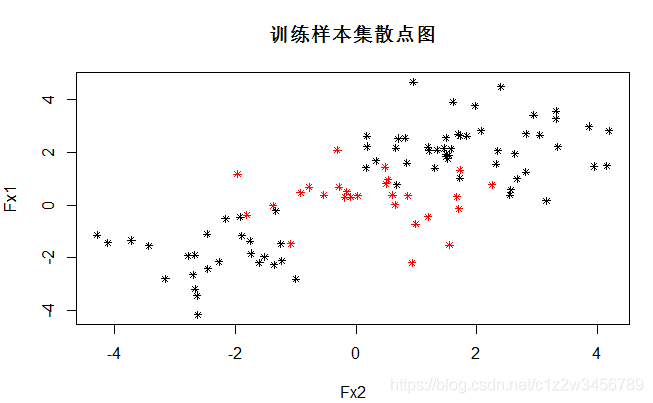
> plot(data_train[,2:1],col=as.integer(as.vector(data_train[,3])),pch=8,cex=0.7,main="训练样本集散点图")
> set.seed(12345)
> tObj<-tune.svm(Fy~.,data=data_train,type="C-classification",kernel="radial",
+ cost=c(0.001,0.01,0.1,1,5,10,100,1000),gamma=c(0.5,1,2,3,4),scale=FALSE)
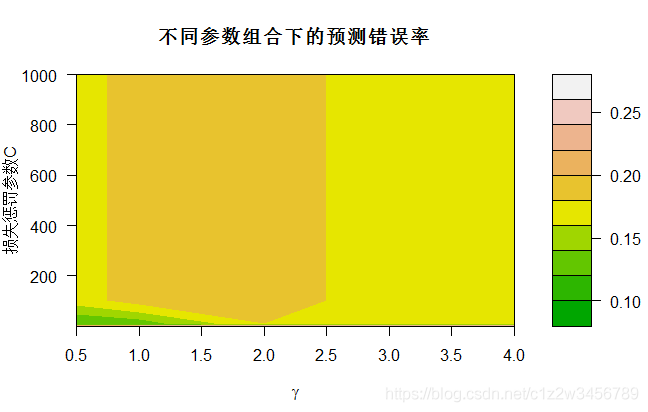
> plot(tObj,xlab=expression(gamma),ylab="损失惩罚参数C",
+ main="不同参数组合下的预测错误率",nlevels=10,color.palette=terrain.colors)
> BestSvm<-tObj$best.model
> summary(BestSvm)
Call:
best.svm(x = Fy ~ ., data = data_train, gamma = c(0.5, 1, 2,
3, 4), cost = c(0.001, 0.01, 0.1, 1, 5, 10, 100, 1000),
type = "C-classification", kernel = "radial", scale = FALSE)
Parameters:
SVM-Type: C-classification
SVM-Kernel: radial
cost: 1
Number of Support Vectors: 40
( 23 17 )
Number of Classes: 2
Levels:
1 2
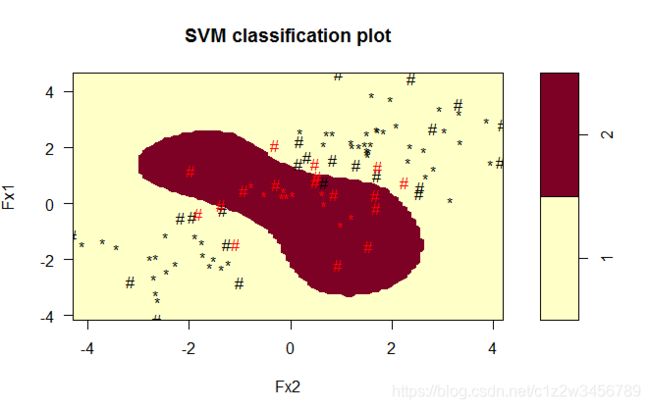
> plot(x=BestSvm,data=data_train,formula=Fx1~Fx2,svSymbol="#",dataSymbol="*",grid=100)
> yPred<-predict(BestSvm,data_test)
> (ConfM<-table(yPred,data_test$Fy))
yPred 1 2
1 73 6
2 4 17
> (Err<-(sum(ConfM)-sum(diag(ConfM)))/sum(ConfM))
[1] 0.1
线性不可分采用径向基核函数。
plot画出预测误差,颜色越深误差越小。
预测误差率为0.1。
> ##############模拟多类别的SVM
> set.seed(12345)
> x<-matrix(rnorm(n=400,mean=0,sd=1),ncol=2,byrow=TRUE)
> x[1:100,]<-x[1:100,]+2
> x[101:150,]<-x[101:150,]-2
> x<-rbind(x,matrix(rnorm(n=100,mean=0,sd=1),ncol=2,byrow=TRUE))
> y<-c(rep(1,150),rep(2,50))
> y<-c(y,rep(0,50))
> x[y==0,2]<-x[y==0,2]+3
> data<-data.frame(Fx1=x[,1],Fx2=x[,2],Fy=as.factor(y))
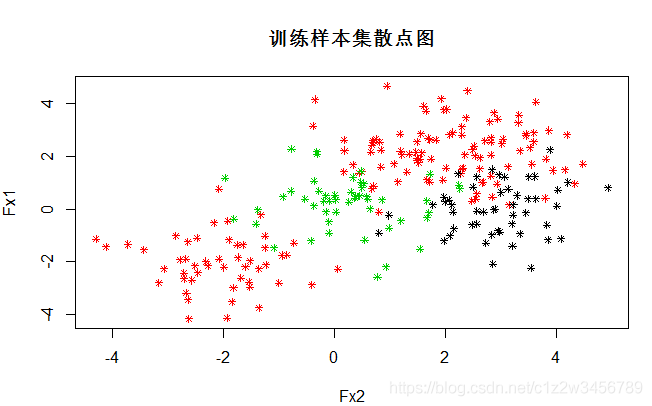
> plot(data[,2:1],col=as.integer(as.vector(data[,3]))+1,pch=8,cex=0.7,main="训练样本集散点图")
> set.seed(12345)
> tObj<-tune.svm(Fy~.,data=data,type="C-classification",kernel="radial",
+ cost=c(0.001,0.01,0.1,1,5,10,100,1000),gamma=c(0.5,1,2,3,4),scale=FALSE)
> BestSvm<-tObj$best.model
> summary(BestSvm)
Call:
best.svm(x = Fy ~ ., data = data, gamma = c(0.5, 1, 2, 3, 4),
cost = c(0.001, 0.01, 0.1, 1, 5, 10, 100, 1000), type = "C-classification",
kernel = "radial", scale = FALSE)
Parameters:
SVM-Type: C-classification
SVM-Kernel: radial
cost: 5
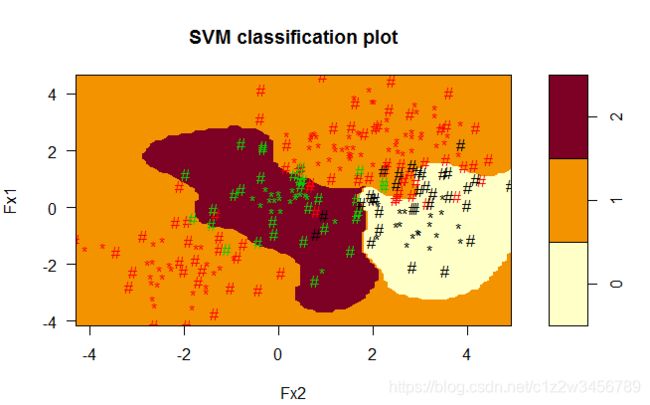
Number of Support Vectors: 133
( 70 31 32 )
Number of Classes: 3
Levels:
0 1 2
> plot(x=BestSvm,data=data,formula=Fx1~Fx2,svSymbol="#",dataSymbol="*",grid=100)
> SvmFit<-svm(Fy~.,data=data,type="C-classification",kernel="radial",cost=5,gamma=1,scale=FALSE)
> head(SvmFit$decision.values)
1/2 1/0 2/0
1 1.033036 1.2345269 -0.61225558
2 1.600637 1.2219439 0.76098974
3 1.068253 1.0112116 0.59276079
4 1.047869 0.9999145 0.05666298
5 2.146043 1.4892178 1.23321397
6 1.031256 1.2279855 -1.10302134
> yPred<-predict(SvmFit,data)
> (ConfM<-table(yPred,data$Fy))
yPred 0 1 2
0 42 3 0
1 6 143 6
2 2 4 44
> (Err<-(sum(ConfM)-sum(diag(ConfM)))/sum(ConfM))
[1] 0.084
> ################天猫数据SVM
> Tmall_train<-read.table("G:\\R语言\\大三下半年\\R语言数据挖掘方法及应用\\天猫_Train_1.txt",header=TRUE,sep=",")
> Tmall_train$BuyOrNot<-as.factor(Tmall_train$BuyOrNot)
> set.seed(12345)
> tObj<-tune.svm(BuyOrNot~.,data=Tmall_train,type="C-classification",kernel="radial",gamma=10^(-6:-3),cost=10^(-3:2))
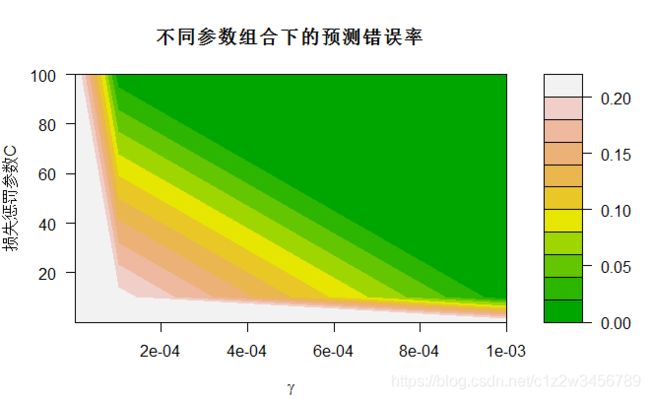
> plot(tObj,xlab=expression(gamma),ylab="损失惩罚参数C",
+ main="不同参数组合下的预测错误率",nlevels=10,color.palette=terrain.colors)
> BestSvm<-tObj$best.model
> summary(BestSvm)
Call:
best.svm(x = BuyOrNot ~ ., data = Tmall_train, gamma = 10^(-6:-3),
cost = 10^(-3:2), type = "C-classification", kernel = "radial")
Parameters:
SVM-Type: C-classification
SVM-Kernel: radial
cost: 100
Number of Support Vectors: 79
( 40 39 )
Number of Classes: 2
Levels:
0 1
> Tmall_test<-read.table("G:\\R语言\\大三下半年\\R语言数据挖掘方法及应用\\天猫_Test_1.txt",header=TRUE,sep=",")
> Tmall_test$BuyOrNot<-as.factor(Tmall_test$BuyOrNot)
> yPred<-predict(BestSvm,Tmall_test)
> (ConfM<-table(yPred,Tmall_test$BuyOrNot))
yPred 0 1
0 270 0
1 27 523
> (Err<-(sum(ConfM)-sum(diag(ConfM)))/sum(ConfM))
[1] 0.03292683
模型在gamma=0.001和C=100时模型最优,共有79个支持向量,预测误差为0.032.