「RocketMQ技术专题」帮你梳理RocketMQ/Kafka的选择理由及二者PK
前提背景
大家都知道,市面上有许多开源的MQ,例如,RocketMQ、Kafka、RabbitMQ等等,现在Pulsar也开始发光,今天我们谈谈笔者最常用的RocketMQ和Kafka,想必大家早就知道二者之间的特点以及区别,但是在实际场景中,二者的选取有可能会范迷惑,那么今天笔者就带领大家分析一下二者之间的区别,以及选取标准吧!
架构对比
RocketMQ的架构
RocketMQ由NameServer、Broker、Consumer、Producer组成,NameServer之间互不通信,Broker会向所有的nameServer注册,通过心跳判断broker是否存活,producer和consumer 通过nameserver就知道broker上有哪些topic。

Kafka的架构
Kafka的元数据信息都是保存在Zookeeper,新版本部分已经存放到了Kafka内部了,由Broker、Zookeeper、Producer、Consumer组成。
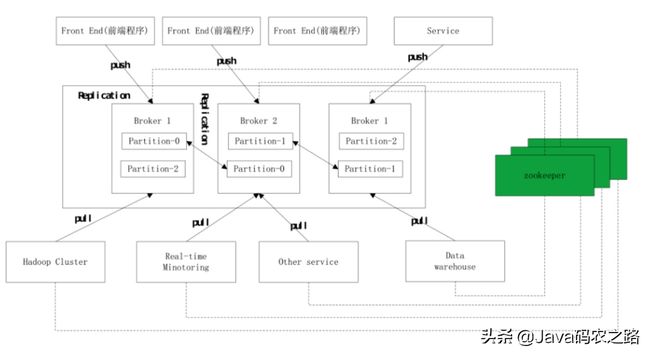
Broker对比
主从架构模型差异:
维度不同
- Kafka的master/slave是基于partition(分区)维度的,而RocketMQ是基于Broker维度的;Kafka的master/slave是可以切换的(主要依靠于Zookeeper的主备切换机制)RocketMQ无法实现自动切换,当RocketMQ的Master宕机时,读能被路由到slave上,但写会被路由到此topic的其他Broker上。
刷盘机制
RocketMQ支持同步刷盘,也就是每次消息都等刷入磁盘后再返回,保证消息不丢失,但对吞吐量稍有影响。一般在主从结构下,选择异步双写策略是比较可靠的选择。
消息查询
RocketMQ支持消息查询,除了queue的offset外,还支持自定义key。RocketMQ对offset和key都做了索引,均是独立的索引文件。
消费失败重试与延迟消费
RocketMQ针对每个topic都定义了延迟队列,当消息消费失败时,会发回给Broker存入延迟队列中,每个消费者在启动时默认订阅延迟队列,这样消费失败的消息在一段时候后又能够重新消费。
- 延迟时间与延迟级别一一对应,延迟时间是随失败次数逐渐增加的,最后一次间隔2小时。
- 当然发送消息是也可以指定延迟级别,这样就能主动设置延迟消费,在一些特定场景下还是有作用的。
数据读写速度
- Kafka每个partition独占一个目录,每个partition均有各自的数据文件.log,相当于一个topic有多个log文件。
- RocketMQ是每个topic共享一个数据文件commitlog,
Kafka的topic一般有多个partition,所以Kafka的数据写入速度比RocketMQ高出一个量级。
但Kafka的分区数超过一定数量的文件同时写入,会导致原先的顺序写转为随机写,性能急剧下降,所以kafka的分区数量是有限制的。
随机和顺序读写的对比
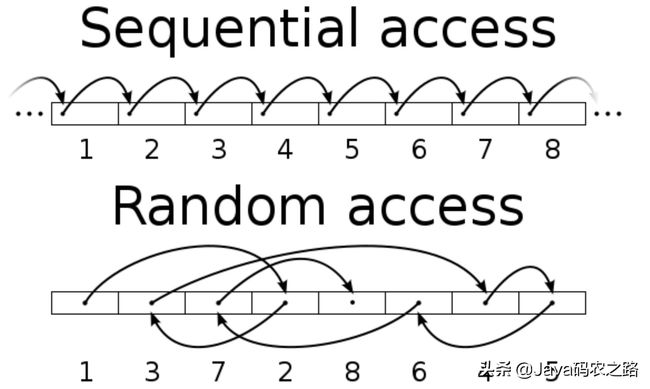
- 连续 / 随机 I/O(在底层硬盘维度)连续 I/O :指的是本次 I/O 给出的初始扇区地址和上一次 I/O 的结束扇区地址是完全连续或者相隔不多的。反之,如果相差很大,则算作一次随机 I/O。
- 发生随机I/O可能是因为磁盘碎片导致磁盘空间不连续,或者当前block空间小于文件大小导致的。
连续 I/O 比随机 I/O 效率高的原因是
- 连续 I/O,磁头几乎不用换道,或者换道的时间很短;
- 随机 I/O,如果这个 I/O 很多的话,会导致磁头不停地换道,造成效率的极大降低。
随机和顺序速度比较
IOPS和吞吐量:为何随机是关注IOPS,顺序关注吞吐量?
- 随机在每次IO操作的寻址时间和旋转延时都不能忽略不计,而这两个时间的存在也就限制了IOPS的大小;
- 顺序读写可以忽略不计寻址时间和旋转延时,主要花费在数据传输的时间上。
IOPS来衡量一个IO系统性能的时候,要说明读写的方式以及单次IO的大小,因为读写方式会受到旋转时间和寻道时间影响,而单次IO会受到数据传输时间影响。
服务治理
- Kafka用Zookeeper来做服务发现和治理,broker和consumer都会向其注册自身信息,同时订阅相应的znode,这样当有broker或者consumer宕机时能立刻感知,做相应的调整;
- RocketMQ用自定义的nameServer做服务发现和治理,其实时性差点,比如如果broker宕机,producer和consumer不会实时感知到,需要等到下次更新broker集群时(最长30S)才能做相应调整,服务有个不可用的窗口期,但数据不会丢失,且能保证一致性。但是某个consumer宕机,broker会实时反馈给其他consumer,立即触发负载均衡,这样能一定程度上保证消息消费的实时性。
Producer差异
发送方式
- kafka默认使用异步发送的形式,有一个memory buffer暂存消息,同时会将多个消息整合成一个数据包发送,这样能提高吞吐量,但对消息的实效有些影响;
- RocketMQ可选择使用同步或者异步发送。
发送响应
Kafka的发送ack支持三种设置:
- 消息存进memory buffer就返回(0);
- 等到leader收到消息返回(1)
- 等到leader和isr的follower都收到消息返回(-1)
上面也介绍了,Kafka都是异步刷盘
RocketMQ都需要等broker的响应确认,有同步刷盘,异步刷盘,同步双写,异步双写等策略,相比于Kafka多了一个同步刷盘。
Consumer差异
消息过滤
- RocketMQ的queue和kafka的partition对应,但RocketMQ的topic还能更加细分,可对消息加tag,同时订阅时也可指定特定的tag来对消息做更进一步的过滤。
有序消息
- RocketMQ支持全局有序和局部有序
- Kafka也支持有序消息,但是如果某个broker宕机了,就不能在保证有序了。
消费确认
RocketMQ仅支持手动确认,也就是消费完一条消息ack+1,会定期向broker同步消费进度,或者在下一次pull时附带上offset。
Kafka支持定时确认,拉取到消息自动确认和手动确认,offset存在zookeeper上。
消费并行度
Kafka的消费者默认是单线程的,一个Consumer可以订阅一个或者多个Partition,一个Partition同一时间只能被一个消费者消费,也就是有多少个Partition就最多有多少个线程同时消费。
如分区数为10,那么最多10台机器来并行消费(每台机器只能开启一个线程),或者一台机器消费(10个线程并行消费)。即消费并行度和分区数一致。
RocketMQ消费并行度分两种情况:有序消费模式和并发消费模式,
- 有序模式下,一个消费者也只存在一个线程消费,并行度同Kafka完全一致。
- 并发模式下,每次拉取的消息按consumeMessageBatchMaxSize(默认1)拆分后分配给消费者线程池,消费者线程池min=20,max=64。也就是每个queue的并发度在20-64之间,一个topic有多个queue就相乘。所以rocketmq的并发度比Kafka高出一个量级。
并发消费方式并行度取决于Consumer的线程数,如Topic配置10个队列,10台机器消费,每台机器100个线程,那么并行度为1000。
事务消息
RocketMQ指定一定程度上的事务消息,当前开源版本删除了事务消息回查功能,事务机制稍微变得没有这么可靠了,不过阿里云的rocketmq支持可靠的事务消息;kafka不支持分布式事务消息。
Topic和Tag的区别?
业务是否相关联
- 无直接关联的消息:淘宝交易消息,京东物流消息使用不同的 Topic 进行区分。
- 交易消息,电器类订单、女装类订单、化妆品类订单的消息可以用Tag进行区分。
消息优先级是否一致:如同样是物流消息,盒马必须小时内送达,天猫超市 24 小时内送达,淘宝物流则相对会慢一些,不同优先级的消息用不同的 Topic 进行区分。
消息量级是否相当:有些业务消息虽然量小但是实时性要求高,如果跟某些万亿量级的消息使用同一个Topic,则有可能会因为过长的等待时间而“饿死”,此时需要将不同量级的消息进行拆分,使用不同的Topic。
Tag和Topic的选用
针对消息分类,您可以选择创建多个Topic,或者在同一个Topic下创建多个Tag。
不同的Topic之间的消息没有必然的联系。
Tag则用来区分同一个Topic下相互关联的消息,例如全集和子集的关系、流程先后的关系。
通过合理的使用 Topic 和 Tag,可以让业务结构清晰,更可以提高效率。
Tag怎么实现消息过滤
RocketMQ分布式消息队列的消息过滤方式有别于其它MQ中间件,是在Consumer端订阅消息时再做消息过滤的。
RocketMQ这么做是在于其Producer端写入消息和Consumer端订阅消息采用分离存储的机制来实现的,Consumer端订阅消息是需要通过ConsumeQueue这个消息消费的逻辑队列拿到一个索引,然后再从CommitLog里面读取真正的消息实体内容,所以说到底也是还绕不开其存储结构。
ConsumeQueue的存储结构:可以看到其中有8个字节存储的Message Tag的哈希值,基于Tag的消息过滤是基于这个字段值的。

Tag过滤方式
- Consumer端在订阅消息时除了指定Topic还可以指定Tag,如果一个消息有多个Tag,可以用||分隔。
- Consumer端会将这个订阅请求构建成一个SubscriptionData,发送一个Pull消息的请求给Broker端。
- Broker端从RocketMQ的文件存储层—Store读取数据之前,会用这些数据先构建一个MessageFilter,然后传给Store。
- Store从ConsumeQueue读取到一条记录后,会用它记录的消息tag hash值去做过滤,由于在服务端只是根据hashcode进行判断。
无法精确对tag原始字符串进行过滤,故在消息消费端拉取到消息后,还需要对消息的原始tag字符串进行比对,如果不同,则丢弃该消息,不进行消息消费。
Message Body过滤方式
向服务器上传一段Java代码,可以对消息做任意形式的过滤,甚至可以做Message Body的过滤拆分
数据消息的堆积能力
理论上Kafka要比RocketMQ的堆积能力更强,不过RocketMQ单机也可以支持亿级的消息堆积能力,我们认为这个堆积能力已经完全可以满足业务需求。
消息数据回溯
- Kafka理论上可以按照Offset来回溯消息
- RocketMQ支持按照时间来回溯消息,精度毫秒,例如从一天之前的某时某分某秒开始重新消费消息,典型业务场景如consumer做订单分析,但是由于程序逻辑或者依赖的系统发生故障等原因,导致今天消费的消息全部无效,需要重新从昨天零点开始消费,那么以时间为起点的消息重放功能对于业务非常有帮助。
性能对比
- Kafka单机写入TPS约在百万条/秒,消息大小10个字节
- RocketMQ单机写入TPS单实例约7万条/秒,单机部署3个Broker,可以跑到最高12万条/秒,消息大小10个字节。
数据一致性和实时性
消息投递实时性
- Kafka使用短轮询方式,实时性取决于轮询间隔时间
- RocketMQ使用长轮询,同Push方式实时性一致,消息的投递延时通常在几个毫秒。
消费失败重试
- Kafka消费失败不支持重试
- RocketMQ消费失败支持定时重试,每次重试间隔时间顺延
消息顺序
- Kafka支持消息顺序,但是一台Broker宕机后,就会产生消息乱序
- RocketMQ支持严格的消息顺序,在顺序消息场景下,一台Broker宕机后,发送消息会失败,但是不会乱序
Mysql Binlog分发需要严格的消息顺序
(题外话)Kafka没有的,RocketMQ独有的tag机制
普通消息、事务消息、定时(延时)消息、顺序消息,不同的消息类型使用不同的 Topic,无法通过Tag进行区分。
总结
- RocketMQ定位于非日志的可靠消息传输(日志场景也OK),目前RocketMQ在阿里集团被广泛应用在订单,交易,充值,流计算,消息推送,日志流式处理,binglog分发等场景。
- RocketMQ的同步刷盘在单机可靠性上比Kafka更高,不会因为操作系统Crash,导致数据丢失。
- 同时同步Replication也比Kafka异步Replication更可靠,数据完全无单点。
- 另外Kafka的Replication以topic为单位,支持主机宕机,备机自动切换,但是这里有个问题,由于是异步Replication,那么切换后会有数据丢失,同时Leader如果重启后,会与已经存在的Leader产生数据冲突。
- 例如充值类应用,当前时刻调用运营商网关,充值失败,可能是对方压力过多,稍后在调用就会成功,如支付宝到银行扣款也是类似需求。这里的重试需要可靠的重试,即失败重试的消息不因为Consumer宕机导致丢失。