前言
系统:win10
Python版本:python3.8.6
pycharm版本:pycharm 2021.1.2(Professional Edition)
完整代码下载:Baidu_Ocr.py-Python
一、获取百度智能云token
百度智能云 登录后找到人工智能界面下的文字识别->管理界面创建应用文字识别。

创建应用完成后记录下,后台界面提供的AppID、API key、Secret Key的信息

接下来根据 官方提供的文档获取使用Token
# encoding:utf-8
import requests
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=wgEHks0l6MCpalbs3lPuFX1U&client_secret=Z4Rn4ghBx9k06fUYPmSEIRbCFvWFxLyQ'
response = requests.get(host)
if response:
print(response.json()['access_token'])
二、百度借口调用
使用获取后token调用百度接口对图片进行识别提取文字
# encoding:utf-8
import requests
import base64
'''
通用文字识别(高精度版)
'''
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
# 二进制方式打开图片文件
f = open('图片.png', 'rb')
img = base64.b64encode(f.read())
params = {"image":img}
# 获取后的Token的调用
access_token = '24.0d99efe8a0454ffd8d620b632c58cccc.2592000.1639986425.282335-24065278'
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
print (response.json())
获取后的token为json格式的数据

此处步骤我们可以看出识别后的文件是以json的格式返回的所以要想达到取出文字的效果就需要对json格式的返回值进行解析
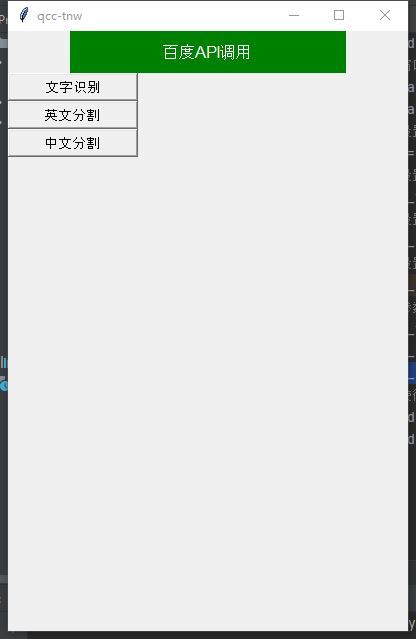
三、搭建窗口化的程序以便于使用
实现窗口可视化的第三方类库是Tkinter。可在终端输入 pip install tkinter 自行下载安装
导入tkinter模块包 构建我们的可视化窗口,要是实现的功能有截图识别文字,中英文分离,文字识别后自动发送给剪切板
from tkinter import *
# 创建窗口
window = Tk()
# 窗口名称
window.title('qcc-tnw')
# 设置窗口大小
window.geometry('400x600')
# 窗口标题设置
l=Label(window,text='百度API调用', bg='green', fg='white', font=('Arial', 12), width=30, height=2)
l.pack()
# 设置文本接收框
E1 = Text(window,width='100',height='100')
# 设置操作Button,单击运行文字识别 "window窗口,text表示按钮文本,font表示按钮本文字体,width表示按钮宽度,height表示按钮高度,command表示运行的函数"
img_txt = Button(window, text='文字识别', font=('Arial', 10), width=15, height=1)
# 设置操作Button,单击分割英文
cut_en = Button(window, text='英文分割', font=('Arial', 10), width=15, height=1)
# 设置操作Button,单击分割中文
cut_cn = Button(window, text='中文分割', font=('Arial', 10), width=15, height=1)
# 参数anchor='nw'表示在窗口的北偏西方向即左上角
img_txt.pack(anchor='nw')
cut_en.pack(anchor='nw')
cut_cn.pack(anchor='nw')
# 使得构建的窗口始终显示在桌面最上层
window.wm_attributes('-topmost',1)
window.mainloop()
四、实现截图的自动保存
通过上述对百度接口的解析发现接口是不支持提取剪切板中的文件的
所以通过PIL库截取的图片从剪切板保存到本地,在调用百度的接口实现图片中文字的识别
PIL的安装 终端输入 pip install PIL
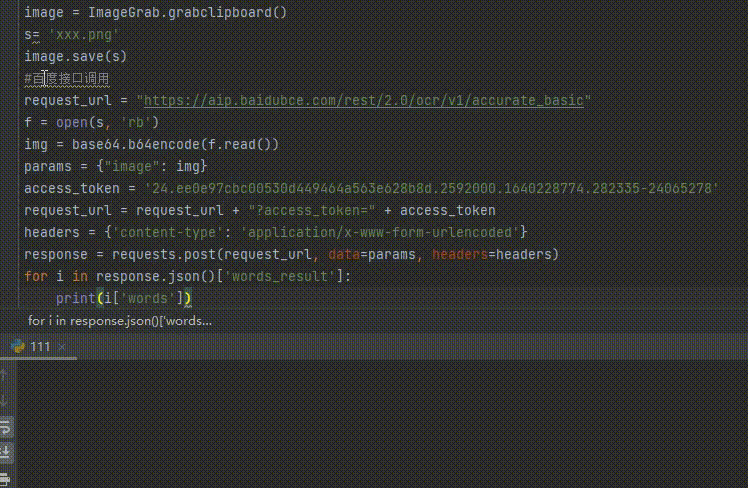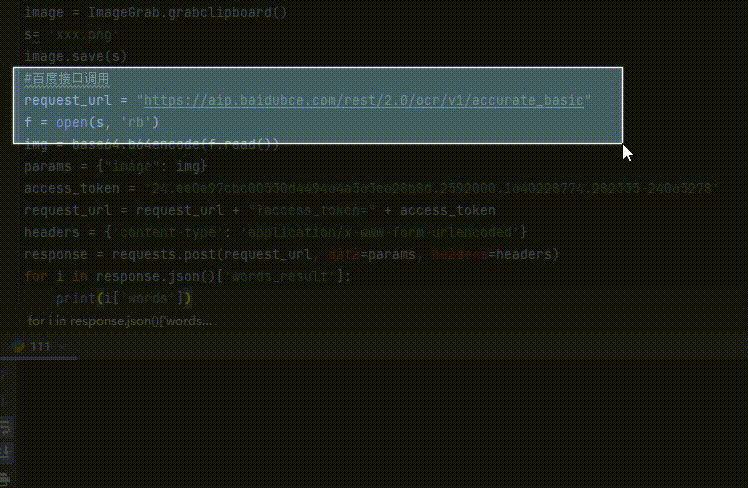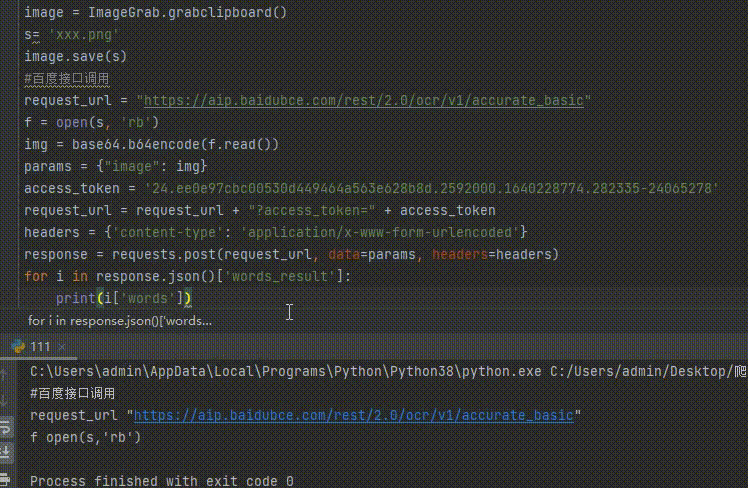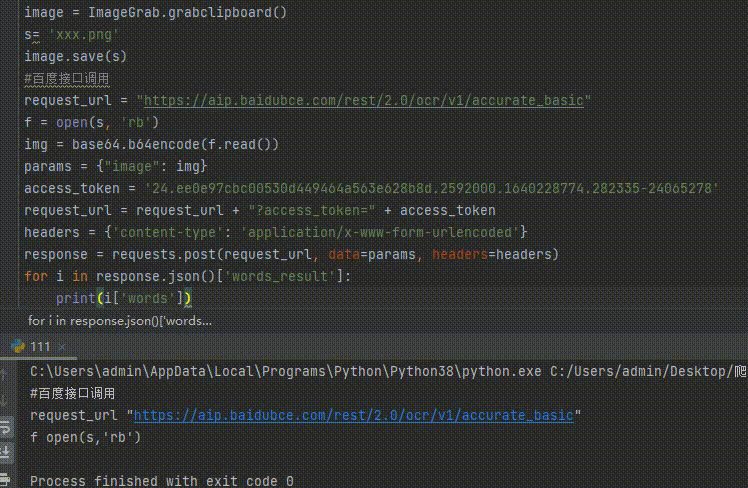
from PIL import ImageGrab
#取出剪切板的文件保存至本地
image = ImageGrab.grabclipboard()
s= 'xxx.png'
image.save(s)
#百度接口调用
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
f = open(s, 'rb')
img = base64.b64encode(f.read())
params = {"image": img}
access_token = '24.ee0e97cbc00530d449464a563e628b8d.2592000.1640228774.282335-24065278'
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
for i in response.json()['words_result']:
print(i['words'])
完成后可以使用qq或微信等的截图功能截图并运行程序
五、将识别到的文字输出显示在窗口文本框中并将文字发送到剪切板
if response:
for i in response.json()['words_result']:
# 接受识别后的文本
E1.insert("insert", i['words'] + '\n')
E1.pack(side=LEFT)
# 将识别后的文字写入剪切板
pyperclip.copy(E1.get("1.0","end"))
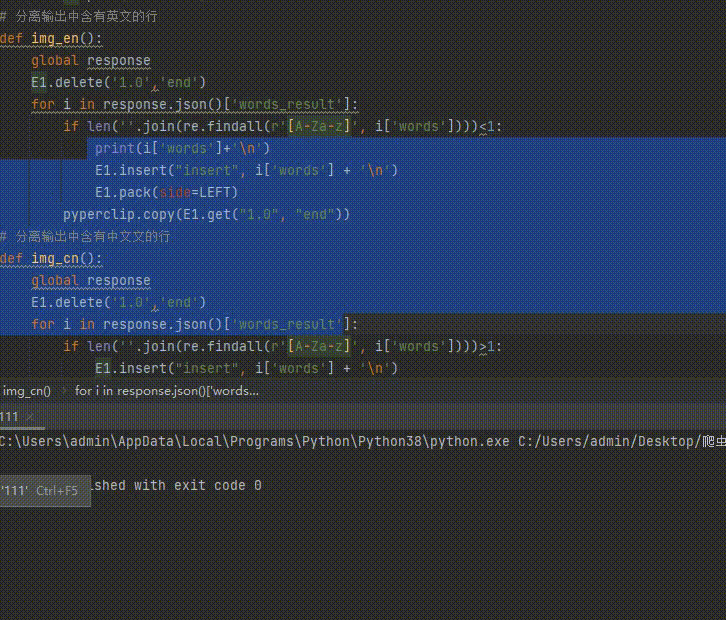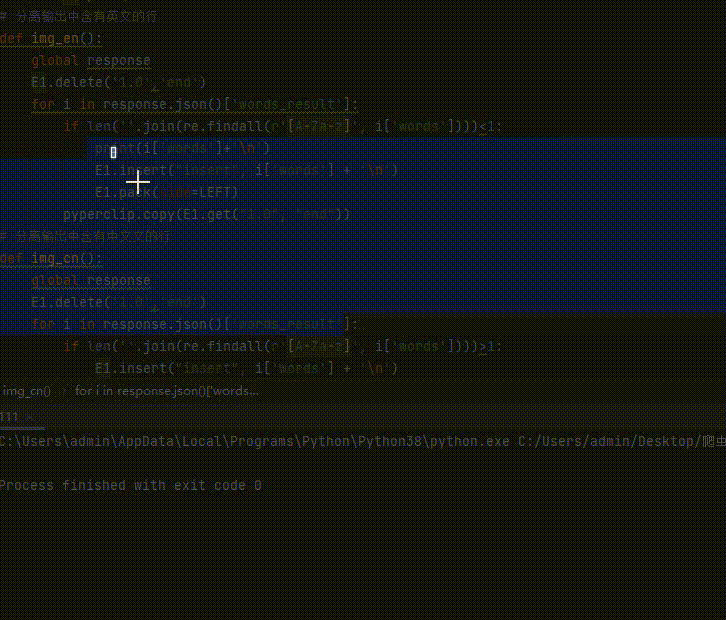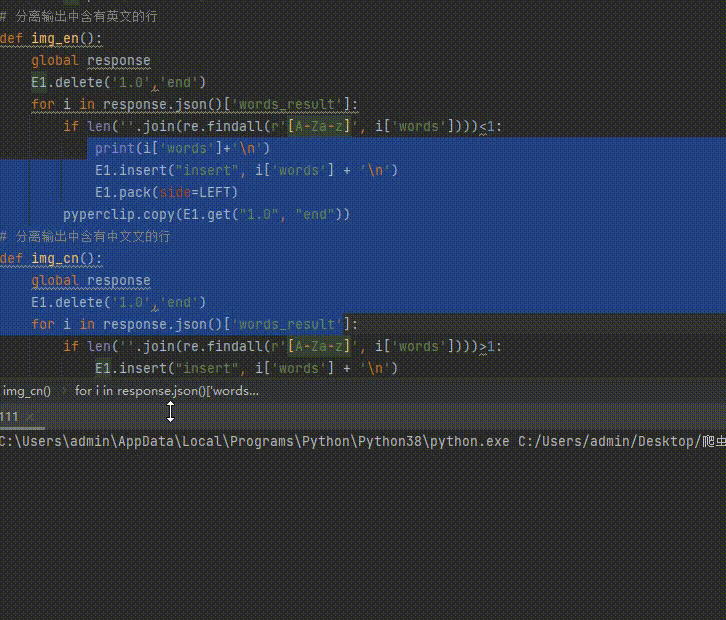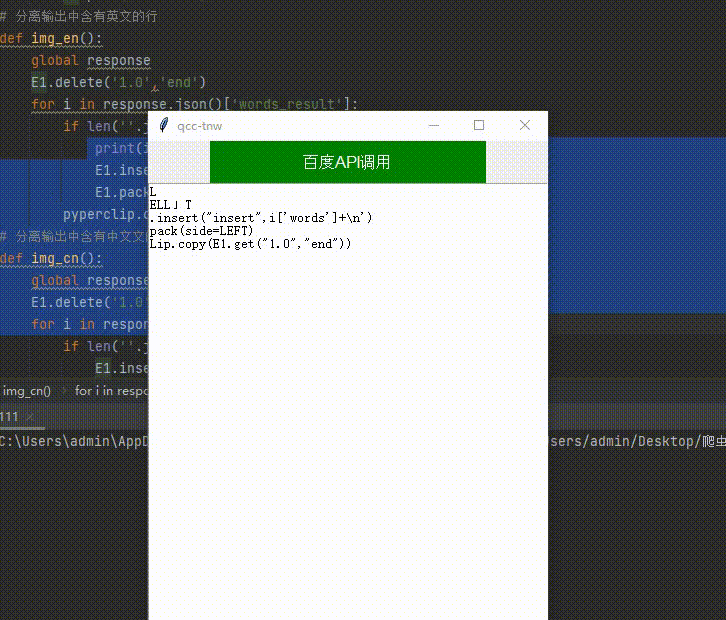
六、提取识别后文字中的中(英)文
此处的判断相对简单将 if len(''.join(re.findall(r'[A-Za-z]', i['words'])))<1: 中的‘<'改为‘>'即为中文
E1.delete('1.0','end')
for i in response.json()['words_result']:
#判断是否存在英文
if len(''.join(re.findall(r'[A-Za-z]', i['words'])))<1:
#将识别正则过滤后的文本在文本框中显示
E1.insert("insert", i['words'] + '\n')
E1.pack(side=LEFT)
#复制到剪切板
pyperclip.copy(E1.get("1.0", "end"))
最后将方法封装为函数形式传递至我们定义好的窗口按钮中
# 设置操作Button,单击运行文字识别 "window窗口,text表示按钮文本,font表示按钮本文字体,width表示按钮宽度,height表示按钮高度,command表示运行的函数"
img_txt = Button(window, text='文字识别', font=('Arial', 10), width=15, height=1,command=img_all)
# 设置操作Button,单击分割英文
cut_en = Button(window, text='英文分割', font=('Arial', 10), width=15, height=1,command=img_en)
# 设置操作Button,单击分割中文
cut_cn = Button(window, text='中文分割', font=('Arial', 10), width=15, height=1,command=img_cn)
# 参数anchor='nw'表示在窗口的北偏西方向即左上角
img_txt.pack(anchor='nw')
cut_en.pack(anchor='nw')
cut_cn.pack(anchor='nw')
window.wm_attributes('-topmost',1)
以上就是Python实战之实现截图识别文字的详细内容,更多关于Python 截图识别文字的资料请关注脚本之家其它相关文章!