【论文分享】Relation-Aware Graph Attention Network for Visual Question Answering
分享一篇nlp领域运用注意力机制设计视觉问答系统的文章,只是对文章进行翻译以及简单的归纳。

目录
二、动机
三、方法
1、问题定义
2、模型结构
2.1 图的构建
2.2 关系编码器
2.3 多模融合及答案预测
3、模型的训练与测试
四、实验
1.数据集
2.实验细节
3.实验结果
4.消融实验
五、结论
Relation-Aware Graph Attention Network for Visual Question Answering
面向视觉问答的关系感知图注意网络

二、动机
在视觉问答任务中,模型要想正确回答复杂问题,必须要对图像中的视觉场景有充分的理解,特别是不同物体间的相互作用关系。现有方法大多关注的是对图像和文本的联合表示的学习,在这类方法框架下,通常将文本和图像分别用RNN和CNN进行编码,再将两者的表示向量输入到多模融合单元中,通过训练该融合单元得到对齐后的联合表示向量,最后将该表示向量输入到答案预测器中得到最终的回答。这类方法虽然可以处理部分VQA任务,但仍不能解决图像和文本间的语义鸿沟问题。例如,模型虽然可以检测出图像中的物体、背景等,但难以理解关于位置和动作的语义信息。
为了捕捉图像中物体的动作和位置信息,模型需要通过分析图中不同物体之间的动态交互关系,对图像中的视觉场景有更全面的认识,而不仅仅只是物体检测。一种可能的方法是将图像中物体间的相对几何位置(比如:摩托车在汽车旁边)与文本中的空间描述信息进行对齐,另一种则是通过学习物体间的语义依赖关系来捕捉视觉场景下的动态交互关系。基于此,提出了一种关系感知图注意力网络(ReGAT),引入了一种关系编码器。
三、方法
1、问题定义
给定一个基于图像I的问题q,模型需要从答案候选集A中选出最接近标准答案的回答a,正如VQA文献中的常见做法,这可以定义为一个分类问题:

2、模型结构
给出了ReGAT模型的整体结构图,其中包含:
- 图像编码器(Image Encoder):提取图中物体特征以及边界框特征
- 问题编码器(Question Encoder):对文本信息进行编码
- 关系编码器(Relation Encoder):提取图中物体间不同类型的关系
- 多模融合器(Fusion):将文本和图像的信息进行融合,得到一个联合表示
- 答案预测器(Answer Predictor):根据联合表示来预测问题的答案
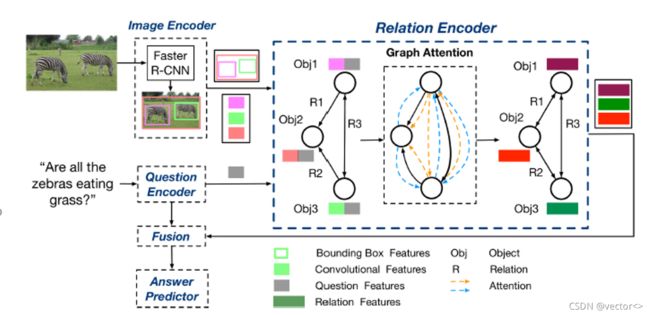
具体来说,ReGAT模型利用Faster R-CNN作为图像编码器来对图像进行编码,得到一组K个物体的特征向量vi及其对应的边界框特征向量bi,同时采用了带门控单元(GRU)的双向RNN作为问题编码器,在RNN的隐状态序列上利用自注意力机制进行编码,最后生成问题表示q。下面将具体介绍ReGAT模型中图的构建、关系编码器、多模融合以及答案预测部分。
2.1 图的构建
在ReGAT模型中,物体间的交互关系是利用图注意力机制进行捕捉的,因此首先需要构建出关系图
2.1.1 全连接关系图
将图中每个物体vi视为节点,可以构建出一个全连接图

其中每条边表示两物体间的一种隐含关系,这种关系可以通过图注意力分配给每条边的学习权值来体现。由于所有的权值都是隐式学习的,没有任何先验知识,ReGAT将利用这种图进行关系编码的编码器称为隐式关系编码器。
2.1.2 含先验知识的修剪图
物体间的显示关系是指人通过肉眼观察得到的先验关系信息,例如物体间的位置关系、动作关系等。如果物体(顶点)间存在显式关系,则可以通过修剪不含显式关系的顶点间的边,将全连接图Gimp转换为显式关系图,其中每条边表示一种关系的先验知识。ReGAT将建立在这个图上的关系编码器命名为显式关系编码器。
这类特征需要预先训练好分类器对图像进行关系抽取,不同类型的显式关系可以在这个修剪图的基础上学习。在视觉问答任务中,物体间的位置和动作关系是非常重要的,因此,ReGAT模型通过构建空间图(spatial graph)和语义图(semantic graph),用两种编码器分别对两种关系进行编码。图3举例说明了两种类型关系,其中红色和蓝色框表示两个物体,绿色框表示物体间的关系。

2.2 关系编码器
ReGAT提出一种基于图形的关系编码器,通过图形注意力网络学习图像中的显示和隐式关系,学习到的关系是问题自适应的,这意味着它们可以动态捕获与每个问题最相关的视觉对象关系
总之:用问题自适应图注意力机制学习对象间关系(显示和隐式)来丰富图像表示。具体而言,图形关系编码器由三个部分组成,分别是语义关系编码器,空间关系编码器,隐式关系编码器(其中语义关系和空间关系属于显式关系)。下面重点介绍一下这个图像关系编码器:
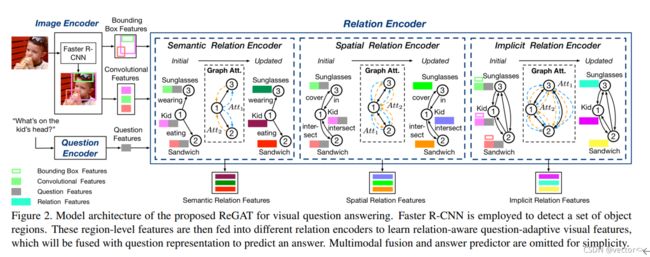
2.2.1 问题自适应图注意力(Question-adaptive Graph Attention):
在设计关系编码器时,使用问题自适应注意力机制将问题的语义信息注入到关系图中,动态地为每个问题最相关的关系分配更高的权重(上文提到的三个关系编码器中嵌入了注意力机制)
首先将问题嵌入q,与每一个视觉特征vi连接起来

随后在图结点上执行self-Attension,从而生成一个隐藏关系特征 表明了目标对象与其相邻对象之间的关系。基于此,每个图都会经过以下注意力机制:
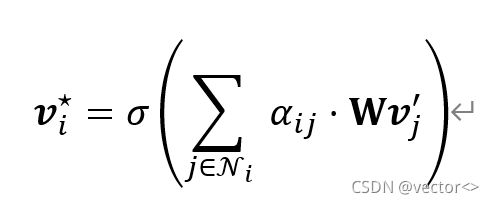
对于不同类型的关系图。注意力系数aij的定义不同,投影矩阵W也不同 ,非线性激活函数采用的是ReLU。为了稳定self-Attension的学习过程,使用了多头注意力的方法,共执行了M个独立的注意力机制,并将他们的输出串联起来,得到以下特征表示:
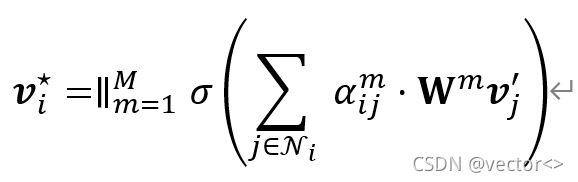
最后,经过注意力机制得到的这个特征V*将添加到原始的特征表示中作为最终的关系感知特征。
2.2.2 隐式关系:
注意力权重(如下图所示)不仅依赖于视觉特征权重还依赖于bounding-box权重由于隐式关系图是全连接的,节点Ni包含图中所有物体间的关系,包括其自身的隐含关系。ReGAT设计了一种注意力权重,不仅依赖节点的特征权重αvij,还依赖于边界框的权重αbij,具体计算过程如公式(5)所示:

其中,αvij表示特征间的相似性,由缩放的点积运算计算得到,计算过程如公式(6)所示:
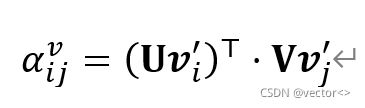
αijb 表示任意一对区域bi,bj间的相对几何位置,计算过程如公式(7)所示:

其中fb 首先计算一个4维的相对几何距离特征,然后通过计算不同波长的余弦和正弦函数将其嵌入到一个h维的特征空间中。
2.2.3 显式关系:
首先讨论语义图Gsem。由于在Gsem中每条边都包含标签信息,并且具有方向性,因此ReGAT设计了公式(3)中的注意力机制,使其能够正确处理不同方向和标签中的信息,具体计算如公式(8)所示:
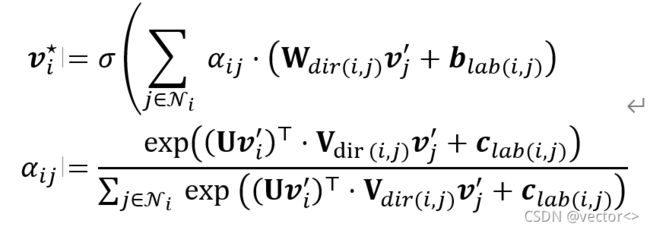
其中dir(i,j)根据每条边的方向性选择变换矩阵,lab(i,j)表示每条边的方向。经过这种图注意力机制对所有顶点进行编码后,就得到了物体间含先验语义的关系特征vi⋆i=1K 与图卷积网络不同,这种图注意机制有效地为相同邻域的节点分配了不同的重要性权重。结合问题适应机制,学习到的注意权重可以反映出哪些关系与特定的问题相关。关系编码器可以在空间图Espa上以相同的方式工作,两者之间参数不共享,因此为简单起见,不再赘述。
2.3 多模融合及答案预测
在获得关系感知的视觉特征后,ReGAT希望通过多模型融合策略将问题信息q与各个视觉表示vi融合。由于关系编码器中保留了视觉特征的维数,因此可以与任何现有的多模态融合方法结合来学习联合表示J:

其中,f表示多模融合方法,Θ表示融合单元中的参数。
在答案预测模块中,ReGAT采用双层多层感知器(MLP)作为分类器,以联合表示J作为输入。采用二元交叉熵作为训练函数。
3、模型的训练与测试
在训练阶段,ReGAT中不同的关系编码器各种进行独立训练。在测试阶段,ReGAT则将三个图注意力网络预测的答案分布进行加权求和得到最终的结果,具体过程如公式(10)所示:

其中α和β是模型的超参数,Prsem、Prspa以及Primp分别表示由语义关系、空间关系以及隐式关系训练得到的模型预测的答案概率。
四、实验
1.数据集
VQA 2.0: 训练数据集和验证数据集都用于训练
VQA-CP v2:是vqa 2.0数据集的一个派生,该数据集用于评估和减少VQA模型中面向问题的偏差。
Visual Genome:用于预训练语义关系分类器(semantic relation classifier),以及扩充VQA数据集。
2.实验细节
评估指标
精确度:

相关实验细节描述:
- 每个问题都被标记,每个单词都使用600维word embedding
- 压缩后的单词序列在第14个token之前被送入GRU
- 少于14个单词的问题末尾用零向量补充。
- GRU隐藏层的维度为1024(关系特征的维度为1024)
- 三个关系编码器都使用16头注意力机制
- 对于隐式关系,将压缩后的相对几何特征维度设置为64
- 对于来语义关系编码器,结合ResNet-101,从 Faster R-CNN模型中提取具有已知边界框(bounding box)的预训练对象特征,这些特征是从Res4b22特征图进行RoI池化后的Pool5层输出
- Faster R-NN 训练了1600个选定对象类和400个属性类,类似于自底向上的注意机制
相关实验参数描述:
- 深度学习框架:Pytorch
- 优化器:Adamax
- Mini-batch size:256
- 学习率:采用warm-up 策略(初始化为0.005,在每个epoch中线性增加,知道 epoch=4时,达到0.002。经过15个epoch之后每两个epoch学习率下降1/2,最多20个epoch)
- 每个下行映射都用过权重归一化和dropout进行正则化
3.实验结果

- Imp / Sem / Spa:表示只有一种单一类型的关系编码器(隐式、语义或空间)
- Imp+Sem / Imp+Spa / Sem+Spa:表示通过加权和使用两种不同类型的关系
- All:表示通过加权和整合了三种关系
在数据集VQA 2.0 和 VQA-CP v2 的实验结果都表明,每增加一种关系编码器都能对性能带来增益,文章提出的模型(即,同时具备三种关系编码器)能带来最好的效果。
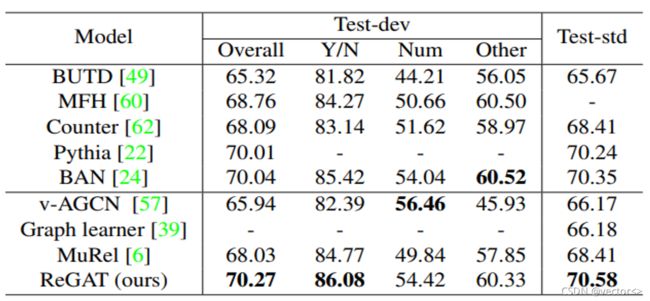
上图中前五行显示的是没有关系推理的模型的测试结果,下四行显示的是有关系推理的模型结果。无论是否存在关系推理,ReGAT都有最佳的效果
4.消融实验
为了说明问题自适应(将问题特征联系到每个对象表示)和注意力机制的重要性,作者进行了以下笑消融实验。

- 去掉注意力机制:将原模型中的图注意力网络替换为图卷积网络。根据实验结果的第三行和第四行可以说明注意力机制能提高准确性。
- 去掉问题自适应:根据s实验结果的第一行和第三行可以说明问题自适应能够提高模型的准确性
- 同时添加注意力机制以及问题自适应所带来的效果增益,比单独添加时带来的增益之和要更大。
五、结论
- 提出了一种基于关系感知的图形注意网络的VQA模型ReGAT,利用问题自适应注意机制构建多类型对象关系
- ReGAT利用显式关系和隐式关系两种视觉对象关系,通过图注意学习关系感知区域表示。
- 该方法在 VQA2.0和 VQA-CP v2数据集上都获得了最先进的结果
- ReGAT与通用的VQA模型兼容,可以通过即插即用的方式被注入到最先进的VQA架构中。