ubuntu16.04+python+anaconda+tensorflow的深度学习2
目录
1、Tensorflow源代码解析
1.1 TensorFlow 的目录结构
1.1.1 contirb
1.1.2 core
1.1.3 examples
1.1.4 python
1.2 TensorFlow 源代码的学习方法
2、机器学习基础
2.1 有监督学习简介
拓展知识1 协调器 tf.train.Coordinator 和入队线程启动器 tf.train.start_queue_runners
2.2 保存训练检查点
拓展知识1 Python rsplit() 方法
拓展知识2 os.path.dirname用法
拓展知识3 tf.train.get_checkpoint_state
2.3 线性回归
拓展知识1 :tf.matmul() 和tf.multiply() 的区别
拓展知识2 tf.squared_difference
拓展知识3 tf.reduce_sum tensorflow维度上的操作
拓展知识4 tf.zeros( shape, dtype=tf.float32, name=None )
2.4 对数几率回归
拓展知识1 t ensorflow中 tf.reduce_mean函数
拓展知识2 tensorflow中四种不同交叉熵函数
拓展知识1 tf.train.string_input_producer()
拓展知识2 十图详解TensorFlow数据读取机制(附代码)
拓展知识2 文件读取器
拓展知识3 tf.train.shuffle_batch
拓展知识1 tf.equal()用法:
拓展知识2 tf.pack
拓展知识1 tf.data
拓展知识3 : 使用sess.run的情况总结
拓展知识3 python中获取路径函数区别
拓展知识4 os.path.join()函数
拓展知识4 assert 断言
2.5 softmax分类
拓展知识1 : tf.argmax() 用法
拓展知识2 : tf.cast()
拓展知识3:tf.stack()和tf.unstack()的用法__函数用法
拓展知识4 tf.nn.sparse_softmax_cross_entropy_with_logits()和tf.nn.softmax_cross_entropy_with_logits()的区别
2.6 多层神经网络
1、Tensorflow源代码解析
1.1 TensorFlow 的目录结构

1.1.1 contirb
contrib 目录中保存的是将常用的功能封装成的高级 API。但是这个目录并不是官方支持的,很有可能在高级 API 完善后被官方迁移到核心的 TensorFlow 目录中或去掉,现在有一部分包(package)在 https://github.com/tensorflow/models 有了更完整的体现。这里重点介绍几个常用包
● framework:很多函数(如 get_variables、get_global_step)都在这里定义,还有一些废弃或者不推推(deprecated)的函数。
● layers:这个包主要有 initializers.py、layers.py、optimizers.py、regularizers.py、summaries.py等文件。initializers.py 中主要是做变量初始化的函数。layers.py 中有关于层操作和权重偏置变量的函数。optimizers.py 中包含损失函数和 global_step 张量的优化器作。
regularizers.py 中包含带有权重的正则化函数。summaries.py 中包含将摘要操作添加到tf.GraphKeys.SUMMARIES 集合中的函数。
● learn:这个包是使用 TensorFlow 进行深度学习的高级 API,包括完成训练模型和评估模型、读取批处理数据和队列功能的 API 封装。
● rnn:这个包提供额外的 RNN Cell,也就是对 RNN 隐藏层的各种改进,如 LSTMBlockCell、GRUBlockCell、FusedRNNCell、GridLSTMCell、AttentionCellWrapper 等。
● seq2seq:这个包提供了建立神经网络 seq2seq 层和损失函数的操作。
● slim:TensorFlow-Slim (TF-Slim)是一个用于定义、训练和评估 TensorFlow 中的复杂模型的轻量级库。在使用中可以将 TF-Slim 与 TensorFlow 的原生函数和 tf.contrib 中的其他包进行自由组合。TF-Slim 现在已经被逐渐迁移到 TensorFlow 开源的 Models①
中,这里包含了几种广泛使用的卷积神经网络图像分类模型的代码,可以从头训练模型或者预训练模型开始微调。
1.1.2 core
这个目录中保存的都是 C 语言的文件,是 TensorFlow 的原始实现

├── BUILD
├── common_runtime # 公共运行库
├── debug
├── distributed_runtime # 分布式执行模块,含有grpc session、grpc worker、 grpc master 等
├── example
├── framework # 基础功能模块
├── graph
├── kernels # 一些核心操作在 CPU、CUDA 内核上的实现
├── lib # 公共基础库
├── ops
├── platform # 操作系统实现相关文件
├── protobuf # .proto 文件,用于传输时的结构序列化
├── public # API 的头文件目录
├── user_ops
└── util
Protocol Buffers 是谷歌公司创建的一个数据序列化②(serialization)工具,可以用于结构化数据序列化,很适合作为数据存储或者 RPC 数据交换的格式。定义完协议缓冲区后,将生成.pb.h和.pb.cc 文件,其中定义了相应的 get、set 以及序列化和反序列化函数。TensorFlow 的几个核心proto 文件 graph_def.proto、node_def.proto、op_def.proto 都保存在 framework 目录中。构图时先构建 graph_def,存储下来,然后在实际计算时再转成如图、节点、操作等的内存对象。
1.1.3 examples
examples 目录中给出了深度学习的一些例子,包括 MNIST、Word2vec、Deepdream、Iris、HDF5 的一些例子,对入门非常有帮助。此外,这个目录中还有 TensorFlow 在 Android 系统上的移动端实现,以及一些扩展为.ipynb 的文档教程,可以用 jupyter 打开
1.1.4 python
大部分函数都存在于此目录中,比如激活函数、卷积函数、池化函数、损失函数、优化方法等
1.2 TensorFlow 源代码的学习方法
(1)了解自己要研究的基本领域,如图像分类、物体检测、语音识别等,了解对应这个领域所用的技术,如卷积神经网络(convolutional neural network,CNN)和循环神经网络(recurrent neural network,RNN),知道实现的基本原理。
(2)尝试运行 GitHub 【https://github.com/tensorflow/models】上对应的基本模型,
如果研究领域是计算机视觉,可以看代码中的如下几个目录:compresssion(图像压缩)、im2txt(图像描述)、inception(对 ImageNet 数据集用 Inception V3 架构去训练和评估)、resnet(残差网络)、slim(图像分类)和 street(路标识别或验证码识别)。
如果研究领域是自然语言处理,可以看 lm_1b(语言模型)、namignizer(起名字)、swivel(使用 Swivel 算法转换词向量)、syntaxnet(分词和语法分析)、textsum(文本摘要)以及 tutorials目录里的 word2vec(词转换为向量)。
这些都是教科书式的代码,看懂学懂对今后自己实现模型大有裨益。尝试运行上述模型,并对模型进行调试和调参。当你完整阅读完 MNIST 或者 CIFAR10 整个项目的逻辑后,就会掌握 TensorFlow 项目架构
重说一下 slim 目录,该目录中 TF-Slim 是图像分类的一个库,它包含用于定义、训练和评估复杂模型的轻量级高级 API。可以用于训练和评估的几个广泛使用的 CNN 图像分类模型,如 lenet、alexnet、vgg、inception_v1、inception_v2 inception_v3、inception_v4、resnet_v1、resnet_v2 等,这些模型都位于 slim/nets 中,具体如下

TF-Slim 包含的脚本可以让人从头训练模型或从预先训练的网络开始训练模型并微调,这些脚本位于 slim/scripts,具体如下

TF-Slim 还包含用于下载标准图像数据集,将其转换为 TensorFlow 支持的 TFRecords 格式,这些脚本位于 slim/datasets,具体如下

随后可以轻松地在任何上述数据集上训练任何模型
(3)结合要做的项目,找到相关的论文,自己用 TensorFlow 实现这篇论文的内容,这会让你有一个质的飞跃
2、机器学习基础
2.1 有监督学习简介
监督学习问题中,我们的目标是依据某个带标注信息的输入数据集(即其中的每个样本都标注了真实的或期望的输出)去训练一个推断模型。该模型应能覆盖一个数据集,并可对不存在于初始训练集中的新样本的输出进行预测
推断模型即运用到数据上的一系列数学运算。具体的运算步骤是通过代码设置的,并由用于求解某个给定问题的模型确定。模型确定后,构成模型的运算也就固定了。在各运算内部,有一些与其定义相关的数值,如“乘以3”、“加2”。这些值都是模型的参数,且在训练过程中需要不断更新,以使模型能够学习,并对其输出进行调整
虽然不同的推断模型在所使用的运算的数量、运算的组合方式以及所使用的参数数量上千差万别,但对于训练,我们始终可采用相同的一般结构:

数据流图的高层、通用训练闭环
我们创建了一个训练闭环,它具有如下功能。
·首先对模型参数进行初始化。通常采用对参数随机赋值的方法,但对于比较简单的模型,也可以将各参数的初值均设为0。
·读取训练数据(包括每个数据样本及其期望输出)。通常人们会在这些数据送入模型之前,随机打乱样本的次序。
·在训练数据上执行推断模型。这样,在当前模型参数配置下,每个训练样本都会得到一个输出值。
·计算损失,损失是一个能够刻画模型在最后一步得到的输出与来自训练集的期望输出之间差距的概括性指标。
·调整模型参数。这一步对应于实际的学习过程。给定损失函数,学习的目的在于通过大量训练步骤改善各参数的值,从而将损失最小化。最常见的策略是使用梯度下降算法。
上述闭环会依据所需的学习速率、所给定的模型及其输入数据,通过大量循环不断重复上述过程。
当训练结束后,便进入评估阶段。在这一阶段中,我们需要对一个同样含有期望输出信息的不同测试集依据模型进行推断,并评估模型在该数据集上的损失。该测试集中包含了何种样本,模型是预先无法获悉的。通过评估,可以了解到所训练的模型在训练集之外的推广能力。一种常见的方法是将原始数据集一分为二,将70%的样本用于训练,其余30%的样本用于评估。
下面利用上述结构为模型训练和评估定义一个通用的代码框架:
import tensorflow as tf # 导入tensorflow库
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 设置输出等级,此时不输出警告
# 初始化变量和模型参数,定义训练闭环中的运算;inference的中文翻译是推测
def inference(x):
# 计算推断模型在数据x上的输出,并将结果返回
return y
def loss(x,y):
# 依据训练数据x及其期望输出y计算损失
return total_loss
def inputs():
# 读取或生成训练数据x及其期望输出y
return x, y
def train(total_loss):
# 根据计算的总损失训练或调整模型参数
return train_op
def evaluate(sess, x, y):
# 对训练得到的模型进行评估
return evaluate_value
# 在一个会话中启动数据流图,搭建流程
with tf.Session() as sess:
# 初始化所有的变量
tf.global_variables_initializer().run()
# 获取训练数据
x, y = inputs()
# 获取所有损失值
total_loss = loss(x, y)
# 获取经过此次训练更新后的模型参数
train_op = train(total_loss)
# 创建一个线程管理器(协调器)对象
coord = tf.train.Coordinator()
# 启动多个线程的同时将多个tensor(数据)推入内存序列中
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 实际的训练迭代次数
training_step = 1000
for step in range(training_step):
train_op = sess.run([train_op])
# 出于调试和学习的目的,查看损失在训练过程中递减的情况
if step % 10 ==0:
print('loss:', train_op)
# 评估现在的模型
evaluate_value = evaluate(sess, x, y)
# 终止所有的行程
coord.request_stop()
# 把线程加入主线程,等待threads结束
coord.join(threads)
# 关闭会话
sess.close()
拓展知识1 协调器 tf.train.Coordinator 和入队线程启动器 tf.train.start_queue_runners
https://blog.csdn.net/weixin_42052460/article/details/80714539
TensorFlow的Session对象是支持多线程的,可以在同一个会话(Session)中创建多个线程,并行执行。在 Session 中的所有线程都必须能被同步终止,异常必须能被正确捕获并报告,会话终止时, 队列必须能被正确地关闭ensorFlow提供了两个类来实现对Session中多线程的管理:tf.Coordinator和 tf.QueueRunner,这两个类往往一起使用。
Coordinator类用来管理在Session中的多个线程,可以用来同时停止多个工作线程并且向那个在等待所有工作线程终止的程序报告异常,该线程捕获到这个异常之后就会终止所有线程。使用 tf.train.Coordinator()来创建一个线程管理器(协调器)对象。
QueueRunner类用来启动tensor的入队线程,可以用来启动多个工作线程同时将多个tensor(训练数据)推送 入文件名称队列中,具体执行函数是 tf.train.start_queue_runners , 只有调用 tf.train.start_queue_runners 之后,才会真正把tensor推入内存序列中,供计算单元调用,否则会由于内存序列为空,数据流图会处于一直等待状态。
以上便是模型训练和评估的基本代码框架。首先需要对模型参数进行初始化;然后为每个训练闭环中的运算定义一个方法:读取训练数据(inputs方法),计算推断模型(inference方法),计算相对期望输出的损失(loss方法),调整模型参数(train方法),评估训练得到的模型(evaluate方法);之后,启动一个会话对象,并运行训练闭环。在接下来的几节中,将针对不同类型的推断模型为这些模板方法填充所需的代码。当对模型的响应满意后,便可将精力放在模型导出,以及用它对所需要使用的数据进行推断上。
2.2 保存训练检查点
上文曾经提到,训练模型意味着通过许多个训练周期更新其参数(或者用TensorFlow的语言来说,变量)。由于变量都保存在内存中,所以若计算机经历长时间训练后突然断电,所有工作都将丢失。幸运的是,借助tf.train.Saver类可将数据流图中的变量保存到专门的二进制文件中。我们应当周期性地保存所有变量,创建检查点(checkpoint)文件,并在必要时从最近的检查点恢复训练
为使用Saver类,需要对之前的训练闭环代码框架略做修改:
import tensorflow as tf # 导入tensorflow库
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 设置输出等级,此时不输出警告
# 初始化变量和模型参数,定义训练闭环中的运算;inference的中文翻译是推测
def inference(x):
# 计算推断模型在数据x上的输出,并将结果返回
return y
def loss(x, y):
# 依据训练数据x及其期望输出y计算损失
return total_loss
def inputs():
# 读取或生成训练数据x及其期望输出y
return x, y
def train(total_loss):
# 根据计算的总损失训练或调整模型参数
return train_op
def evaluate(sess, x, y):
# 对训练得到的模型进行评估
return evaluate_value
# 创建一个saver对象
saver = tf.train.Saver()
# 在一个会话中启动数据流图,搭建流程
with tf.Session() as sess:
# 初始化所有的变量
tf.global_variables_initializer().run()
# 获取训练数据
x, y = inputs()
# 获取所有损失值
total_loss = loss(x, y)
# 获取经过此次训练更新后的模型参数
train_op = train(total_loss)
# 创建一个线程管理器(协调器)对象
coord = tf.train.Coordinator()
# 启动多个线程的同时将多个tensor(数据)推入内存序列中
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 实际的训练迭代次数
training_step = 1000
for step in range(training_step):
train_op = sess.run([train_op])
# 出于调试和学习的目的,查看损失在训练过程中递减的情况
if step % 10 == 0:
saver.save(sess,'my-model', global_step=step)
print('loss:', train_op)
# 评估现在的模型
evaluate_value = evaluate(sess, x, y)
# 终止所有的行程
coord.request_stop()
# 把线程加入主线程,等待threads结束
coord.join(threads)
# 保存训练模型
saver.save(sess, 'my_model', global_step=training_step)
# 关闭会话
sess.close()在上述代码中,在开启会话对象之前实例化了一个Saver对象,然后在训练闭环部分插入了几行代码,使的每完成10次训练迭代便调用一次tf.train.Saver.save方法,并在训练结束后,再次调用该方法。每次调用tf.train.Saver.save方法都将创建一个遵循命名模板my-model-{step}的检查点文件,如my-model-10、my-model-20等。该文件会保存每个变量的当前值。默认情况下,Saver对象只会保留最近的5个文件,更早的文件都将被自动删除。
如果希望从某个检查点恢复训练,则应使用tf.train.get_checkpoint_state方法,以验证之前是否有检查点文件被保存下来,而tf.train.Saver.restore方法将负责恢复变量的值
import tensorflow as tf # 导入tensorflow库
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 设置输出等级,此时不输出警告
# initialize variables/model parameters(初始化变量和模型参数)
# define the training loop operations(定义训练闭环中的运算)
def inference(x):
# compute inference model over data X and return the result
# 计算推断模型在数据x上的输出,并将结果返回
return y
def loss(x, y):
# compute loss over training data X and expected values Y
# 依据训练数据x及其期望输出y计算损失
return total_loss
def inputs():
# read/generate input training data X and expected outputs Y
# 读取或生成训练数据x及其期望输出y
return x,y
def train(total_loss):
# train / adjust model parameters according to computed total loss
# 根据计算的总损失训练或调整模型参数
return train_op
def evaluate(sess, x, y):
# evaluate the resulting trained model
# 对训练得到的模型进行评估
return evaluate_value
# 创建一个saver对象
saver = tf.train.Saver()
# 在一个会话中启动数据流图,搭建流程
with tf.Session() as sess:
# 初始化所有的变量
tf.global_variables_initializer().run()
# 获取训练数据
x, y = inputs()
# 获取所有损失值
total_loss = loss(x, y)
# 获取经过此次训练更新后的模型参数
train_op = train(total_loss)
# 创建一个线程管理器(协调器)对象
coord = tf.train.Coordinator()
# 启动多个线程的同时将多个tensor(数据)推入内存序列中
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 验证之前是否已经保存了检查点文件,若有则恢复
initial_step = 0
# 检查当前文件的绝对目录下是否有检查点文件
ckpt = tf.train.get_checkpoint_state(os.path.dirname('__file__'))
# 如果有检查点文件,则恢复参数
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
initial_step = int(ckpt.model_checkpoint_path.rsplit('-', 1)[1])
# 实际的训练迭代次数
training_step = 1000
for step in range(training_step):
train_op = sess.run([train_op])
# 出于调试和学习的目的,查看损失在训练过程中递减的情况
if step % 10 == 0:
saver.save(sess,'my-model', global_step=step)
print('loss:', train_op)
# 评估现在的模型
evaluate_value = evaluate(sess, x, y)
# 终止所有的行程
coord.request_stop()
# 把线程加入主线程,等待threads结束
coord.join(threads)
# 保存训练模型
saver.save(sess, 'my_model', global_step=training_step)
# 关闭会话
sess.close()
拓展知识1 Python rsplit() 方法
http://www.cnblogs.com/wushuaishuai/p/7792874.html
Python rsplit() 方法通过指定分隔符对字符串进行分割并返回一个列表,默认分隔符为所有空字符,包括空格、换行(\n)、制表符(\t)等。类似于 split() 方法,只不过是从字符串最后面开始分割。
rsplit() 方法语法 S.rsplit([sep=None][,count=S.count(sep)])
sep -- 可选参数,指定的分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。 count -- 可选参数,分割次数,默认为分隔符在字符串中出现的总次数。
拓展知识2 os.path.dirname用法
https://blog.csdn.net/weixin_38470851/article/details/80367143
os.path.dirname(path) 功能:去掉文件名,返回目录
os.path.dirname(__file__) 功能: 得到当前文件的绝对路径
__file__表示了当前文件的path
拓展知识3 tf.train.get_checkpoint_state
https://blog.csdn.net/changeforeve/article/details/80268522
tf.train.get_checkpoint_state(checkpoint_dir,latest_filename=None)通过checkpoint文件checkpoint_dir找到模型文件名
函数返回:checkpoint文件CheckpointState proto类型的内容,其有model_checkpoint_path和all_model_checkpoint_paths两个属性。其中model_checkpoint_path保存了最新的tensorflow模型文件的文件名,all_model_checkpoint_paths则有未被删除的所有tensorflow模型文件的文件名
2.3 线性回归
在有监督学习问题中,线性回归是一种最简单的建模手段。给定一个数据点集合作为训练集,线性回归的目标是找到一个与这些数据最为吻合的线性函数。对于2D数据,这样的函数对应一条直线。
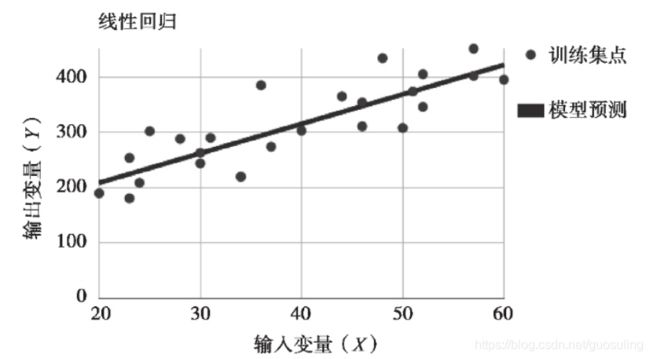
上图展示了一个2D情形下的线性回归模型。图中的点代表训练数据,而直线代表模型的推断结果。
下面运用少量数学公式解释线性回归模型的基本原理。线性函数的一般表达式为:
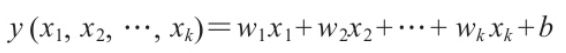
其矩阵(或张量)形式为:

·Y为待预测的值。
·x1 ,x2 ,…,xk 是一组独立的预测变量;在使用模型对新样本进行预测时,需要提供这些值。若采用矩阵形式,可一次性提供多个样本,其中每行对应一个样本。
·w1 ,w2 ,…,wk 为模型从训练数据中学习到的参数,或赋予每个变量的“权值”。
·b也是一个学习到的参数,这个线性函数中的常量也称为模型的偏置(bias)。
下面用代码来表示这种模型。这里没有使用权值的转置,而是将它们定义为单个列向
import tensorflow as tf # 导入tensorflow库
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 设置输出等级,此时不输出警告
# 初始化变脸和模型参数,定义训练闭环中的运算;inference的中文翻译是推测
w = tf.Variable(tf.zeros([2, 1]), name='weights')
b = tf.Variable(0, name='bias')
init = tf.global_variables_initializer()
def inference(x):
return tf.matmul(x, w)+b
接下来需要定义如何计算损失。对于这种简单的模型,将采用总平方误差,即模型对每个训练样本的预测值与期望输出之差的平方的总和。从代数角度看,这个损失函数实际上是预测的输出向量与期望向量之间欧氏距离的平方。对于2D数据集,总平方误差对应于每个数据点在垂直方向上到所预测的回归直线的距离的平方总和。这种损失函数也称为L2范数或L2损失函数。这里之所以采用平方,是为了避免计算平方根,因为对于最小化损失这个目标,有无平方并无本质区别,但有平方可以节省一定的计算量
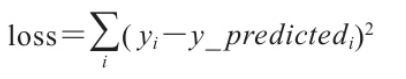
我们需要遍历i来求和,其中i为数据样本的索引。该函数的实现如下:
def loss(x, y):
y_predicted = inference(x)
return tf.reduce_sum(tf.squared_difference(y, y_predicted))接下来便可用数据实际训练模型。例如,将准备使用一个将年龄、体重(单位:千克)与血液脂肪含量关联的数据集
(http://people.sc.fsu.edu/~jburkardt/datasets/regression/x09.txt )
由于这个数据集规模很小,下面直接将其嵌入在代码中。下一节将演示如何像实际应用场景中那样从文件中读取训练数据
def inputs():
weight_age = [[84, 46], [73, 20], [65, 52], [70, 30],
[76, 57], [69, 25], [63, 28], [72, 36], [79, 57], [75, 44],
[27, 24], [89, 31], [65, 52], [57, 23], [59, 60], [69, 48],
[60,34], [79, 51], [75, 50], [82, 34], [59, 46], [67, 23],
[85, 37], [55, 40], [63, 30]]
blood_fat_content = [354, 190, 405, 263, 451, 302, 288, 385, 402, 365,
209, 290, 346, 254, 395, 434, 220, 374, 308, 220,
311, 181, 274, 303, 244]
下面定义模型的训练运算。我们将采用梯度下降算法对模型参数进行优化(下一节将介绍该算法)。
def train(total_loss):
learning_rate = 0.0000001
return tf.train.GradientDescentOptimizer(learning_rate).minimize(total_loss)运行上述代码时,将看到损失函数的值随训练步数的增加呈现逐渐减小的趋势
模型训练完毕后,便需要对其进行评估。下面计算一个年龄25岁、体重80千克的人的血液脂肪含量,这个数据并未在训练集中出现过,但可将预测结果与同年龄的、体重65千克的人进行比较
完整代码如下:
import tensorflow as tf # 导入tensorflow库
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 设置输出等级,此时不输出警告
# 初始化变脸和模型参数,定义训练闭环中的运算;inference的中文翻译是推测
w = tf.Variable(tf.zeros([2, 1]), name="weights")
b = tf.Variable(0., name='bais')
def inference(x):
# 计算推断模型在数据x上的输出,并将结果返回
y = tf.matmul(x, w)+b
return y
def loss(x, y):
# 依据训练数据x及其期望输出y计算损失
y_predicted = tf.transpose(inference(x)) # make it a row vector
# y_predicted = inference(x) # make it a row vector
total_loss = tf.reduce_sum(tf.squared_difference(y, y_predicted))
return total_loss
def inputs():
# 读取或生成训练数据x及其期望输出y
weight_age = [[84, 46], [73, 20], [65, 52], [70, 30], [76, 57], [69, 25], [63, 28], [72, 36], [79, 57], [75, 44],
[27, 24], [89, 31], [65, 52], [57, 23], [59, 60], [69, 48], [60, 34], [79, 51], [75, 50], [82, 34],
[59, 46], [67, 23], [85, 37], [55, 40], [63, 30]]
blood_fat_content = [354, 190, 405, 263, 451, 302, 288, 385, 402, 365, 209, 290, 346, 254, 395, 434, 220, 374, 308,
220, 311, 181, 274, 303, 244]
return tf.to_float(weight_age), tf.to_float(blood_fat_content)
def train(total_loss):
# 根据计算的总损失训练或调整模型参数
learning_rate = 0.0000001
op = tf.train.GradientDescentOptimizer(learning_rate).minimize(total_loss)
return op
def evaluate(sess, x, y):
# 对训练得到的模型进行评估
print(sess.run(inference([[80., 25.]]))) # ~ 303
return
# 在一个会话中启动数据流图,搭建流程
with tf.Session() as sess:
# 初始化所有的变量
tf.global_variables_initializer().run()
# 获取训练数据
x, y = inputs()
# 获取所有损失值
total_loss = loss(x, y)
# 获取经过此次训练更新后的模型参数
train_op = train(total_loss)
# 创建一个线程管理器(协调器)对象
coord = tf.train.Coordinator() # 可以去掉
# 启动多个线程的同时将多个tensor(数据)推入内存序列中
threads = tf.train.start_queue_runners(sess=sess, coord=coord) # 可以去掉
# 实际的训练迭代次数
training_step = 10000
for step in range(training_step):
a = sess.run([train_op])
# 评估现在的模型
evaluate(sess, x, y)
# 终止所有的行程
coord.request_stop() # 可以去掉
# 把线程加入主线程,等待threads结束
coord.join(threads) # 可以去掉
# 关闭会话
sess.close()
上述代码中注意:b = tf.Variable(0., name='bais'),此时的0加一个点表示此时的数据类型是float32,在执行矩阵运算(上述代码中的运算包含乘法和加法)时需要数据类型相匹配,而w = tf.Variable(tf.zeros([2, 1]), name="weights")中的tf.zeros([2, 1])默认的数据类型是float32,同时def inputs()函数中返回的也是float类型 【return tf.to_float(weight_age), tf.to_float(blood_fat_content)】,此三处的数据类型必须完全一致,可以发现在测试模型性能函数def evaluate(sess, x, y)中的数据[[80., 25.]]也是加了点的float32类型
拓展知识1 :tf.matmul() 和tf.multiply() 的区别
https://www.cnblogs.com/AlvinSui/p/8987707.html
tf.multiply()两个矩阵中对应元素各自相乘 ,格式: tf.multiply(x, y, name=None) 参数如下:
x: 一个类型为:half, float32, float64, uint8, int8, uint16, int16, int32, int64, complex64, complex128的张量。
y: 一个类型跟张量x相同的张量。
返回值: x * y element-wise.
注意: (1)multiply这个函数实现的是元素级别的相乘,也就是两个相乘的数元素各自相乘,而不是矩阵乘法,注意和tf.matmul区别。 (2)两个相乘的数必须有相同的数据类型,不然就会报错。
tf.matmul()将矩阵a乘以矩阵b,生成a * b。
格式: tf.matmul(a, b, transpose_a=False, transpose_b=False, adjoint_a=False, adjoint_b=False, a_is_sparse=False, b_is_sparse=False, name=None) 参数如下:
a: 一个类型为 float16, float32, float64, int32, complex64, complex128 且张量秩 > 1 的张量。
b: 一个类型跟张量a相同的张量。
transpose_a: 如果为真, a则在进行乘法计算前进行转置。
transpose_b: 如果为真, b则在进行乘法计算前进行转置。
adjoint_a: 如果为真, a则在进行乘法计算前进行共轭和转置。
adjoint_b: 如果为真, b则在进行乘法计算前进行共轭和转置。
a_is_sparse: 如果为真, a会被处理为稀疏矩阵。
b_is_sparse: 如果为真, b会被处理为稀疏矩阵。
name: 操作的名字(可选参数)
返回值: 一个跟张量a和张量b类型一样的张量且最内部矩阵是a和b中的相应矩阵的乘积。
注意: (1)输入必须是矩阵(或者是张量秩 >2的张量,表示成批的矩阵),并且其在转置之后有相匹配的矩阵尺寸。
(2)两个矩阵必须都是同样的类型,支持的类型如下:float16, float32, float64, int32, complex64, complex128。
拓展知识2 tf.squared_difference
https://www.cnblogs.com/superxuezhazha/p/9528167.html squared_difference( x, y, name=None ) 功能说明: 计算张量 x、y 对应元素差平方
| 参数名 | 必选 | 类型 | 说明 |
|---|---|---|---|
| x | 是 | 张量 | 是 half, float32, float64, int32, int64, complex64, complex128 其中一种类型 |
| y | 是 | 张量 | 是 half, float32, float64, int32, int64, complex64, complex128 其中一种类型 |
| name | 否 | string | 运算名称 |
拓展知识3 tf.reduce_sum tensorflow维度上的操作
https://blog.csdn.net/lxg0807/article/details/74625861
reduce_sum( input_tensor, axis=None, keep_dims=False, name=None, reduction_indices=None )
input_tensor:表示输入;axis:表示在那个维度进行sum操作;keep_dims:表示是否保留原始数据的维度,False相当于执行完后原始数据就会少一个维度;reduction_indices:为了跟旧版本的兼容,现在已经不使用了
拓展知识4 tf.zeros( shape, dtype=tf.float32, name=None )
注意:类似系列的函数默认数据类型都是float32
2.4 对数几率回归
线性回归模型所预测的是一个连续值或任意实数。下面介绍一种能够回答Yes-No类型的问题(如,这封邮件是否为垃圾邮件?)的模型。在机器学习领域,有一个极为常见的函数——logistic函数。由于外形与字母S相仿,它也称为sigmoid函数(sigma为等价于S的希腊字母)。
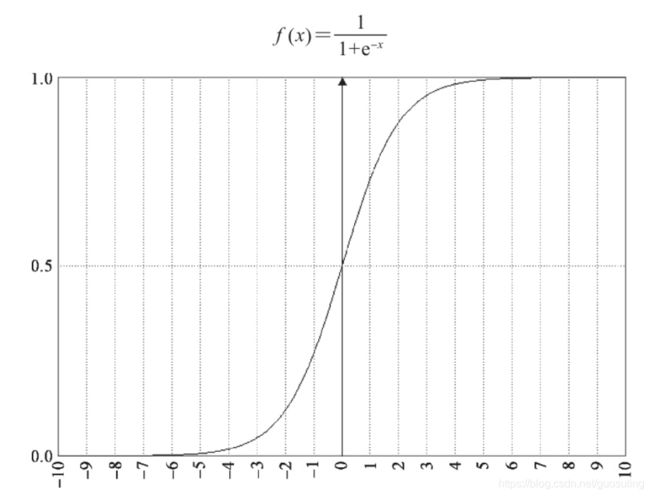
从上图可清楚地看到logistic/sigmoid函数呈现出类似字母“S”的形状。
logistic函数是一个概率分布函数,即给定某个特定输入,该函数将计算输出为“success”的概率,也就是对问题的回答为“Yes”的概率。这个函数接受单个输入值。为使该函数能够接受多维数据,或来自训练集中样本的特征,需要将它们合并为单个值,可利用上述的线性回归模型表达式
为在代码中对此进行表示,可复用线性模型的所有元素。不过,为了运用sigmoid函数,需要对预测部分稍做修改
修改1:#对数几率回归的变量初始化
w = tf.Variable(tf.zeros([5, 1]), name="weights")
b = tf.Variable(0., name='bais')修改2 增加函数combine_inputs函数,将原始数据的组合输出【即得到激活函数sigmoid的输入值】
def combine_inputs(x):
x1 = tf.matmul(x, w)+b
return x1修改3 :推测函数使用sigmoid激活函数
def inference(x):
# 计算推断模型在数据x上的输出,并将结果返回
y = tf.sigmoid(combine_inouts(x))
return y下面重点讨论该模型的损失函数,也可以使用平方误差。logistic函数会计算回答为“Yes”的概率。在训练集中,“Yes”回答应当代表100%的概率,或输出值为1的概率。然后,损失应当刻画的是对于特定样本,模型为其分配一个小于1的值的概率。因此,回答“No”将表示概率值为0,于是损失是模型为那个样本所分配的概率值,并取平方。
假设某个样本的期望输出为“Yes”,但模型为其预测了一个非常低的接近于0的概率,这意味着几乎可以100%地认为答案为“No”。平方误差所惩罚的是与损失为同一数量级的情形,就好比为“No”输出赋予的概率为20%、30%,甚至50%。对于这种类型的问题,采取如下的交叉熵(cross entropy)损失函数会更为有效。
![]()
可以用可视化的方式依据对“Yes”的预测结果,对这两种损失函数进行比较
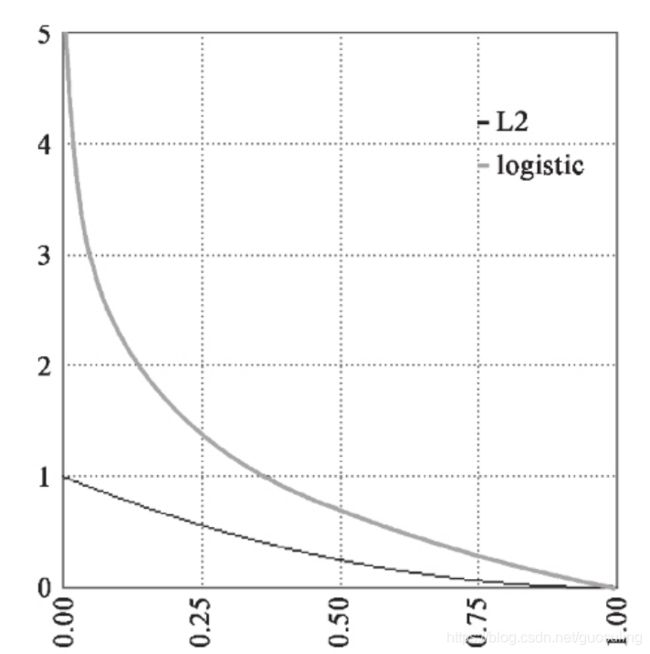
交叉熵与平方误差(L2)函数会被叠加绘制。交叉熵输出了一个更大的值(“惩罚”),因为输出与期望值相去甚远。
借助交叉熵,当模型对期望输出为“Yes”的样本的预测概率接近于0时,罚项的值就会增长到接近于无穷大。这就使得训练完成后,模型不可能做出这样的错误预测。这使得交叉熵更适合作为该模型的损失函数
TensorFlow提供了一个可在单个优化步骤中直接为一个sigmoid输出计算交叉熵的方法tf.nn.sigmoid_cross_entropy_with_logits:
修改4:更改损失的计算方式
def loss(x, y):
total_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=combine_inputs(x), labels=y))
return total_loss
拓展知识1 tensorflow中 tf.reduce_mean函数
https://blog.csdn.net/dcrmg/article/details/79797826
tf.reduce_mean 函数用于计算张量tensor沿着指定的数轴(tensor的某一维度)上的的平均值,主要用作降维或者计算tensor(图像)的平均值。
reduce_mean(input_tensor, axis=None,keep_dims=False,name=None,reduction_indices=None)
第一个参数input_tensor: 输入的待降维的tensor;
第二个参数axis: 指定的轴,如果不指定,则计算所有元素的均值;
第三个参数keep_dims:是否降维度,设置为True,输出的结果保持输入tensor的形状,否则,输出结果会降低维度;
第四个参数name: 操作的名称;
第五个参数 reduction_indices:在以前版本中用来指定轴,已弃用
拓展知识2 tensorflow中四种不同交叉熵函数
https://blog.csdn.net/qq_35203425/article/details/79773459
tensorflow中自带四种交叉熵函数,可以轻松的实现交叉熵的计算。
tf.nn.softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, dim=-1, name=None)
tf.nn.sparse_softmax_cross_entropy_with_logits(_sentinel=None,labels=None,logits=None, name=None) tf.nn.sigmoid_cross_entropy_with_logits(sentinel=None,labels=None, logits=None, name=None)
tf.nn.weighted_cross_entropy_with_logits(labels,logits, pos_weight, name=None)
注意:tensorflow交叉熵计算函数输入中的logits都不是softmax或sigmoid的输出,而是softmax或sigmoid函数的输入,因为它在函数内部进行sigmoid或softmax操作。而且不能在交叉熵函数前进行softmax或sigmoid,会导致计算会出错。
参数说明
_sentinel:本质上是不用的参数,不用填
logits:计算的输出,注意是未使用softmax或sigmoid的,维度一般是[batch_size, num_classes] ,单样本是[num_classes]。数据类型(type)是float32或float64;
labels:和logits具有相同的type(float)和shape的张量(tensor),即数据类型和张量维度都一致。
name:操作的名字,可填可不填
pos_weight:正样本的一个系数
输出说明
sigmoid交叉熵 输出为: loss,shape:[batch_size,num_classes] 注意:它对于输入的logits先通过sigmoid函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出。output不是一个数,而是一个batch中每个样本的loss,所以一般配合tf.reduce_mean(loss)使用。
softmax交叉熵 output: loss,shape:[batch_size],注意同上 sparse_softmax交叉熵 output: loss,shape:[batch_size] 注意同上 weighted交叉熵 output: loss,shape:[batch_size,num_classes] 注意同上
下面将该模型运用到一些数据上。我们准备使用来自 Kaggle竞赛数据集Titanic。
【训练数据载train.csv文件下载地址为:链接:https://pan.baidu.com/s/1XXaihbJflKlSjPoOcxW4zg 提取码:rcoi 】
修改5 ,将数据获取方式从之前的直接嵌入在py文件中改为加载数据文件
编写读取文件的基本代码。对于之前编写的框架,这是一个新的方法。你可加载和解析它,并创建一个批次来读取排列在某个张量中的多行数据,以提升推断计算的效率
def read_csv(batch_size, file_name, record_defaults):
file_queue = tf.train.string_input_producer([os.path.dirname(__file__)]+'/'+file_name)
reader = tf.TextLineReader(skip_header_lines=1)
key, value = reader.read(file_queue)
# decode_csv会将字符串(文本行)转换到具有指定默认值的由张量列构成的元祖中,他还会为每一列设置数据类型
decoded = tf.decode_csv(value, record_defaults=record_defaults)
# 实际上会读取一个文件,并加载一个张量中的batch_size行
return tf.train.shuffle_batch(decoded, batch_size=batch_size, capacity=batch_size * 50, min_after_dequeue=batch_size)
拓展知识1 tf.train.string_input_producer()
该函数生成并维护一个输入文件队列,不同线程中的文件读取函数可以共享这个文件队列。
tf.train.string_input_producer(string_tensor,num_epochs=None,shuffle=True,seed=None,capacity=32,name=None)
1、函数输入参数
string_tensor: A 1-D string tensor with the strings to produce. 1维字符串类型的tensor对象,如['ling1','ling2']
num_epochs: An integer (optional). If specified, string_input_producer produces each string from string_tensor num_epochs times before generating an OutOfRange error. If not specified, string_input_producer can cycle through the strings in string_tensor an unlimited number of times.迭代次数,例如有2个输入图片'ling1.jpg'和'ling2.jpg',若num_epochs=2,则该函数返回值为['ling1','ling2','ling1','ling2'],若不设置该参数,默认可以无限次读取输入的文件名列表
shuffle: Boolean. If true, the strings are randomly shuffled within each epoch.布尔类型。 如果为true,则在每个时期内随机洗牌。
seed: An integer (optional). Seed used if shuffle == True. 整数(可选)。 如果shuffle == True,则使用该种子产生随机数从而随机获取队列中文件名
capacity: An integer. Sets the queue capacity. 一个整数,设置队列容量,默认可以容纳32个文件名
name: A name for the operations (optional).节点名字
拓展知识2 十图详解TensorFlow数据读取机制(附代码)
https://www.sohu.com/a/148245200_115128
拓展知识2 文件读取器
https://www.cnblogs.com/Charles-Wan/p/6197019.html https://blog.csdn.net/u014061630/article/details/80712635
http://wiki.jikexueyuan.com/project/tensorflow-zh/how_tos/reading_data.html
http://www.tensorfly.cn/tfdoc/api_docs/python/io_ops.html#TextLineReader
TensorFlow 有三种方法读取数据:1)供给数据,用placeholder;2)从文件读取;3)用常量或者是变量来预加载数据,适用于数据规模比较小的情况。tf.data API:可以很容易的构建一个复杂的输入通道(pipeline)(首选数据输入方式)(Eager模式必须使用该API来构建输入通道),后续会总结tf.data API的用法,并使用该api实现本节的内容。
我们就简单的说一下从文件读取数据。 首先要知道你要读取的文件的格式,选择对应的文件读取器
根据你的文件格式, 选择对应的文件阅读器, 然后将文件名队列提供给阅读器的read方法。阅读器的read方法会输出一个key来表征输入的文件和其中的纪录(对于调试非常有用),同时得到一个字符串标量, 这个字符串标量可以被一个或多个解析器,或者转换操作将其解码为张量并且构造成为样本。
1)假如你要读取的文件是像 CSV 那样的文本文件,用的文件读取器和解码器就是 TextLineReader 和 decode_csv 。
csv是 逗号分隔符分割的text文件
tf.TextLineReader.__init__(skip_header_lines=None, name=None),其中skip_header_lines为一个可选的int。 默认为0.从每个文件的开头跳过的行数。
read 方法每执行一次,会从文件中读取一行。tf.TextLineReader.read(queue, name=None),该函数返回一个元组 A tuple of Tensors (key, value). 其中 key: A string scalar Tensor. value: A string scalar Tensor.
然后 decode_csv 将读取的内容解析成一个Tensor列表。参数 record_defaults 决定解析产生的Tensor的类型,另外,如果输入中有缺失值,则用record_defaults 指定的默认值来填充。tf.decode_csv(records, record_defaults, field_delim=None, name=None)
在使用run或者eval 执行 read 方法前,你必须调用 tf.train.start_queue_runners 去填充 queue。否则,read 方法将会堵塞(等待 filenames queue 中 enqueue 文件名)
2)假如你要读取的数据是像 cifar10 那样的 .bin 格式的二进制文件,就用 tf.FixedLengthRecordReader 和 tf.decode_raw 读取固定长度的文件读取器和解码器。
二进制文件中,每一个record都占固定bytes
read 方法每执行一次,会从文件中读取一行 tf.FixedLengthRecordReader.read(queue, name=None)
然后 decode_raw 将读取的内容解析成一个Tensor列表tf.decode_raw(bytes, out_type, little_endian=None, name=None)
例如,二进制格式的CIFAR-10数据集中的每一个record都占固定bytes:label占1 bytes,然后后面的image数据占3072 bytes。当你有一个unit8 tensor时,通过切片便可以得到各部分并reformat成需要的格式
3)如果你要读取的数据是图片或其他类型的格式,那么可以先把数据转换成 TensorFlow 的标准支持格式 tfrecords ,它其实是一种二进制文件,通过修改 tf.train.Example 的Features,将 protocol buffer 序列化为一个字符串,再通过 tf.python_io.TFRecordWriter 将序列化的字符串写入 tfrecords,然后再用跟上面一样的方式读取tfrecords,只是读取器变成了tf.TFRecordReader,之后通过一个解析器tf.parse_single_example ,然后用解码器 tf.decode_raw 解码
拓展知识3 tf.train.shuffle_batch
tf.train.shuffle_batch(tensor_list, batch_size, capacity, min_after_dequeue, num_threads=1, seed=None, enqueue_many=False, shapes=None, name=None)
参数说明 tensor_list :[example, label]表示样本和样本标签 batch_size: 返回的一个batch样本集的样本个数 capacity :队列中的容量。这主要是按顺序组合成一个batch min_after_dequeue,一定要保证这参数小于capacity参数的值,否则会出错。这个代表队列中的元素大于它的时候就输出乱的顺序的batch
个人理解:此函数一般和文件读取器和解码器,如 TextLineReader 和 decode_csv 同时使用,使用TextLineReader来定义一个读取器,然后设置该读取器的读入函数read的返回值(key, value),接着使用解码器decode_csv将读取器中读到的value解码,得到解码器的输出:样本[example, label],此输出可作为批量读入tf.train.shuffle_batch的
注意:其实读入和解码只是定义了一个操作,告诉了tensorflow如何读入和解码该文件,而批量读入函数tf.train.shuffle_batch则是关联了读入和解码的操作,其可以根据函数参数batch_size来确定每执行一次tf.train.shuffle_batch就执行多少次读入和解码函数。
修改6:改变生成特征向量的输入函数
def inputs():
# 读取或生成训练数据x及其期望输出y
passenger_id, survived, pclass, name, sex, age, sibsp, parch, ticket, fare, embarked = \
read_csv(100, 'train.csv', [[0.0], [0.0], [0], [''], [''], [0.0], [0.0], [0.0], [''], [0.0], [''], ['']])
# 转换属性数据
is_first_class = tf.to_float(tf.equal(pclass, [1]))
is_second_class = tf.to_float(tf.equal(pclass, [2]))
is_third_class = tf.to_float(tf.equal(pclass, [3]))
gender = tf.to_float(tf.equal(sex, ['female']))
# 最终将所有特征排列在一个矩阵中,然后对该矩阵转置,使其每行对应一个样本,每列对应一种特征
features = tf.transpose(tf.stack([is_first_class, is_second_class, is_third_class, gender, age]))
survived = tf.reshape(survived, [100, 1])
return features, survived在上述代码中,将输入定义为调用read_csv并对所读取的数据进行转换。为了转换为布尔型,我们使用tf.equal方法检查属性值与某些常量值是否相等,还利用 tf.to_float方法将布尔值转换成数值以进行推断。然后,利用tf.stack方法将所有布尔值打包进单个张量中
拓展知识1 tf.equal()用法:
equal(x, y, name=None) https://blog.csdn.net/ustbbsy/article/details/79564529
equal,相等的意思。顾名思义,就是判断,x, y 是不是相等,它的判断方法不是整体判断,而是逐个元素进行判断,如果相等就是True,不相等,就是False。由于是逐个元素判断,所以x,y 的维度类型要一致。
拓展知识2 tf.pack
tf.pack(values, axis=0, name=”pack”)
Packs a list of rank-R tensors into one rank-(R+1) tensor 将一个R维张量列表沿着axis轴组合成一个R+1维的张量
T 注意: F1.2.1中 tf.stack() 替代 tf.pack() 该函数使用方法无变化,仅仅名称变化
https://www.jianshu.com/p/a745119b32b4
修改7 训练模型函数的参数修改
def train(total_loss):
# 根据计算的总损失训练或调整模型参数
learning_rate = 0.01
op = tf.train.GradientDescentOptimizer(learning_rate).minimize(total_loss)
return op修改8 ,评估函数更改,
为了对训练结果进行评估,准备对训练集中的一批数据进行推断,并统计已经正确预测的样本总数。我们将这种方法称为度量准确率
def evaluate(sess, x, y):
# 对训练得到的模型进行评估
predicted = tf.cast(inference(x) > 0.5, tf.float32)
print(sess.run(tf.reduce_mean(tf.cast(tf.equal(predicted, y), tf.float32))))
return由于模型计算的是回答为“Yes”的概率,所以如果某个样本对应的输出大于0.5,则将输出转换为一个正的回答,然后利用tf.equal比较预测结果与实际值是否相等。最后,利用tf.reduce_mean统计所有正确预测的样本数,并除以该批次中的样本总数,从而得到正确的预测所占的百分比。
运行上述代码,将得到约80%的准确率。考虑到模型较为简单,这个结果还是比较令人满意的。完整代码如下
import time
import tensorflow as tf # 导入tensorflow库
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 设置输出等级,此时不输出警告
# 初始化变脸和模型参数,定义训练闭环中的运算;inference的中文翻译是推测
w = tf.Variable(tf.zeros([5, 1]), name="weights")
b = tf.Variable(0., name='bais')
def combine_inputs(x):
# 首先计算激活函数sigmoid的输入,即原始输入的组合
x1 = tf.matmul(x, w)+b
return x1
def inference(x):
# 计算推断模型在数据x上的输出,并将结果返回
y = tf.sigmoid(combine_inputs(x))
return y
def loss(x, y):
total_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=combine_inputs(x), labels=y))
return total_loss
def read_csv(batch_size, file_name, record_defaults):
# file_queue = tf.train.string_input_producer([os.path.dirname(__file__)+'/'+file_name])
file_queue = tf.train.string_input_producer([os.path.join(os.getcwd(), file_name)])
reader = tf.TextLineReader(skip_header_lines=1)
key, value = reader.read(file_queue)
# decode_csv会将字符串(文本行)转换到具有指定默认值的由张量列构成的元祖中,他还会为每一列设置数据类型
decoded = tf.decode_csv(value, record_defaults=record_defaults)
# 实际上会读取一个文件,并加载一个张量中的batch_size行
return tf.train.shuffle_batch(decoded, batch_size=batch_size, capacity=batch_size * 50, min_after_dequeue=batch_size)
def inputs():
# 读取或生成训练数据x及其期望输出y
passenger_id, survived, pclass, name, sex, age, sibsp, parch, ticket, fare, cabin, embarked = \
read_csv(100, 'train.csv', [[0.0], [0.0], [0], [''], [''], [0.0], [0.0], [0.0], [''], [0.0], [''], ['']])
# 转换属性数据
is_first_class = tf.to_float(tf.equal(pclass, [1]))
is_second_class = tf.to_float(tf.equal(pclass, [2]))
is_third_class = tf.to_float(tf.equal(pclass, [3]))
gender = tf.to_float(tf.equal(sex, ['female']))
# 最终将所有特征排列在一个矩阵中,然后对该矩阵转置,使其每行对应一个样本,每列对应一种特征
features = tf.transpose(tf.stack([is_first_class, is_second_class, is_third_class, gender, age]))
survived = tf.reshape(survived, [100, 1])
return features, survived
def train(total_loss):
# 根据计算的总损失训练或调整模型参数
learning_rate = 0.01
op = tf.train.GradientDescentOptimizer(learning_rate).minimize(total_loss)
return op
def evaluate(sess, x, y):
# 对训练得到的模型进行评估
predicted = tf.cast(inference(x) > 0.5, tf.float32)
print(sess.run(tf.reduce_mean(tf.cast(tf.equal(predicted, y), tf.float32))))
return
# 在一个会话中启动数据流图,搭建流程
with tf.Session() as sess:
# 初始化所有的变量
tf.global_variables_initializer().run()
# 获取训练数据
x, y = inputs()
# 获取所有损失值
total_loss = loss(x, y)
# 获取经过此次训练更新后的模型参数
train_op = train(total_loss)
# 创建一个线程管理器(协调器)对象
coord = tf.train.Coordinator()
# 启动多个线程的同时将多个tensor(数据)推入内存序列中
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 实际的训练迭代次数
training_step = 1000
for step in range(training_step):
a = sess.run([train_op])
# 评估现在的模型
evaluate(sess, x, y)
time.sleep(5)
# 终止所有的行程
coord.request_stop()
# 把线程加入主线程,等待threads结束
coord.join(threads)
# 关闭会话
sess.close()拓展知识1 tf.data
在 tf.data 之前,一般使用 QueueRunner,但 QueueRunner 基于 Python 的多线程及队列等,效率不够高,所以 Google发布了tf.data,其基于C++的多线程及队列,彻底提高了效率。所以不建议使用 QueueRunner 了,取而代之,使用 tf.data 模块吧:简单、高效
一个基于queue的从文件中读取records的通道(pipline)一般有以下几个步骤: https://blog.csdn.net/u014061630/article/details/80728694
1 文件名列表(The list of filenames)
2 文件名打乱(可选)(Optional filename shuffling)
3 epoch限制(可选)(Optional epoch limit)
4 文件名队列(Filename queue)
5 与文件格式匹配的Reader(A Reader for the file format)
6 decoder(A decoder for a record read by the reader)
7 预处理(可选)(Optional preprocessing)
8 Example队列(Example queue)
注意:tf.train.string_input_producer的输入参数对应于上述的1,2,3
tf.train.string_input_producer的输出对应于上述的4这一方法完全可以使用tf.data API来替代。
tf.data API 在 TensorFlow 中引入了两个新概念:
tf.data.Dataset:表示一系列元素,其中每个元素包含一个或多个 Tensor 对象。例如,在图片管道中,一个元素可能是单个训练样本,具有一对表示图片数据和标签的张量。可以通过两种不同的方式来创建数据集。
直接从 Tensor 创建 Dataset(例如 Dataset.from_tensor_slices());当然 Numpy 也是可以的,TensorFlow 会自动将其转换为 Tensor;通过对一个或多个 tf.data.Dataset 对象来使用变换(例如 Dataset.batch())来创建 Dataset
tf.data.Iterator:这是从数据集中提取元素的主要方法。Iterator.get_next() 指令会在执行时生成 Dataset 的下一个元素,并且此指令通常充当输入管道和模型之间的接口。最简单的迭代器是“单次迭代器”,它会对处理好的 Dataset 进行单次迭代。要实现更复杂的用途,您可以通过 `Iterator.initializer` 指令使用不同的数据集重新初始化和参数化迭代器,这样一来,您就可以在同一个程序中对训练和验证数据进行多次迭代(举例而言)。
一个基于 tf.data API的读取数据的步骤包含下列几步
1、根据被读入数据的类型选择相应的读入函数
如果您的所有输入数据都适合存储在内存中【NumPy 数组】,则根据输入数据创建 Dataset 的最简单方法是将它们转换为 tf.Tensor对象,并使用 Dataset.from_tensor_slices();
通过 tf.data.TFRecordDataset类,您可以将一个或多个 TFRecord 文件的内容作为输入管道的一部分进行流式传输
tf.data.FixedLengthRecordDataset 提供了一种从一个或多个二进制文件中读取数据的简单方法
tf.data.TextLineDataset 提供了一种从一个或多个文本文件中(csv文件)提取行的简单方法。给定一个或多个文件名,TextLineDataset 会为这些文件的每行生成一个字符串值元素
例如,针对本节的‘train.csv’训练集,采取tf.data.TextLineDataset方法读入文件!
dataset = tf.data.TextLineDataset([os.path.dirname(__file__) + '/' + file_name])
2、根据需要对读入的数据进行一系列预处理(map,batch,shuffle,repeat,skip)
map接收一个函数,Dataset中的每个元素都会被当作这个函数的输入,并将函数返回值作为新的Dataset,针对我们的训练集,映射函数如下,解码函数tf.decode_csv函数和之前讲的一样,其中line就是tf.data.TextLineDataset函数读入的数据(可能进行了一些预处理)
def map_csv(line):
record_defaults = [[0.0], [0.0], [0], [''], [''], [0.0], [0.0], [0.0], [''], [0.0], [''], ['']]
map_value = tf.decode_csv(line, record_defaults=record_defaults)
return map_value调用映射函数如下
dataset1 = dataset1.map(map_csv) batch就是将多个元素组合成batch,其实就是一种组合,tf.data.TextLineDataset 函数会为文件的每行生成一个字符串值元素,当使用迭代器取出时是一个元素一个元素的取出,即一行一行的取出,而batch就是将多个元素合为一个元素,本人理解:一般csv文件一行是一个样本,而batch组合后调用迭代器可以一次取出多个样本。针对我们训练集的batch操作函数如下
dataset1 = dataset.batch(batch_size)shuffle的功能为打乱dataset中的元素,它有一个参数buffersize,表示打乱时使用的buffer的大小,该值应该取一个较大的数值,如10000,本例中本人没有使用该预处理,
repeat的功能就是将整个序列重复多次,主要用来处理机器学习中的epoch,假设原先的数据是一个epoch,使用repeat(5)就可以将之变成5个epoch:如果直接调用repeat()的话,生成的序列就会无限重复下去,没有结束,因此也不会抛出tf.errors.OutOfRangeError异常:本例中使用方法如下:
dataset1 = dataset.batch(batch_size).repeat()可以注意到,上述代码将batch操作和repeat操作合并在一起,故:上述的四个预处理都可以叠加在一块,写在一条语句里面,
skip的功能是读取文件时跳过前面几行,本例中使用如下:
dataset = tf.data.TextLineDataset([os.path.dirname(__file__) + '/' + file_name]).skip(1)
注意:上述5个预处理操作和读入函数tf.data.TextLineDataset 写在一行,直接获得需要的数据集
重点注意: 上述5个预处理操作没有明显区别,但是特殊情况如下
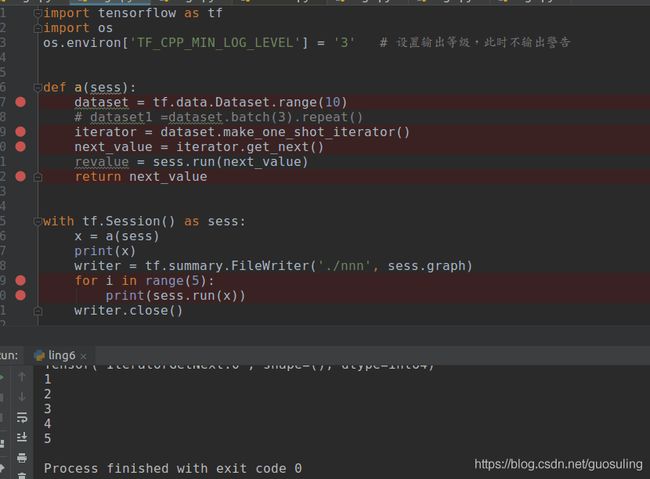
上图中首先生成了一个0-9的数据集,使用迭代器循环5次输出时依次输出了数字1,2,3,4,5

上图中依然是0- 9的数据集,但是循环超过10次时就会报错,因为迭代器已经走到该数据集的最后
使用预处理repeat之后,如下图所示

上述数据集是0-9,当先使用预处理batch操作将1-10的10个数据打包成3个一组时得到新的数据集【[0,1,2],[3,4,5],[6,7,8],[9]】 ,然后再使用预处理repeat操作,那么此时新的数据集变成【[0,1,2],[3,4,5],[6,7,8],[9]】【[0,1,2],[3,4,5],[6,7,8],[9]】。。。。。一直重复下去,如输出所示

上图的数据集依然是0-9的10个数字,首先采用repeat操作得到新的数据集【0,1,2,3,4,5,6,7,8,9,0,1,2,3,4,5,6,7,8,9.。。。。无限循环】,然后采用batch操作,新的数据集为【[0,1,2],[3,4,5],[6,7,8][9,0,1][2,3,4],[5,6,7]。。。。无限循环下去】
对此repeat和batch的先后操作,可以看出,先使用batch再使用repeat时,当使用迭代器获得的数据和另外的矩阵相乘时容易出现矩阵形状不匹配的问题,如下图所示

上图中执行了四次run,由前面知,四次run得到的x值分别为:【0,1,2】,【3,4,5】,【6,7,8】,【9】,所以与3*1的向量w相乘时前三次结果都正确,但是第四次run出错,出错具体信息如下,即形状不对应
InvalidArgumentError (see above for traceback): Input to reshape is a tensor with 1 values, but the requested shape has 3
[[node Reshape (defined at /homeng/pycharm-community-2018.3.2/Pycharmprojects/untitledng6.py:19) = _MklReshape[T=DT_FLOAT, Tshape=DT_INT32, _kernel="MklOp", _device="/job:localhost/replica:0/task:0/device:CPU:0"](ToFloat, Reshape/shape, DMT/_0, DMT/_1)]]
交换repeat和batch的顺序之后,四次run得到的x值分别为:【0,1,2】,【3,4,5】,【6,7,8】,【9,0,1】执行结果如下:无错误

3、生成迭代器
构建了表示输入数据的 Dataset 后,下一步就是创建 Iterator 来访问该数据集中的元素。tf.data API 目前支持下列迭代器,其复杂程度逐渐上升:单次迭代器,可初始化迭代器,可重新初始化迭代器,可 feeding 迭代器
单次迭代器是最简单的迭代器形式,仅支持对数据集进行一次迭代,不需要显式初始化。单次迭代器可以处理现有的基于队列的输入管道支持的几乎所有情况,但不支持参数化,本例中也可以使用单次迭代器,如下
iterator = dataset.make_one_shot_iterator() 您需要先运行显式 iterator.initializer 指令,才能使用可初始化迭代器。虽然有些不便,但它允许您使用一个或多个 tf.placeholder() 张量(可在初始化迭代器时馈送)参数化数据集的定义,本例中使用方法如下:
iterator = dataset1.make_initializable_iterator()
sess.run(iterator.initializer) 可重新初始化迭代器 可以通过多个不同的 Dataset 对象进行初始化。例如,您可能有一个训练输入管道,它会对输入图片进行随机扰动来改善泛化;还有一个验证输入管道,它会评估对未修改数据的预测。这些管道通常会使用不同的 Dataset 对象,这些对象具有相同的结构(即每个组件具有相同类型和兼容形状)。
可 feeding 迭代器可以与 tf.placeholder 一起使用,通过熟悉的 feed_dict 机制来选择每次调用 tf.Session.run 时所使用的 Iterator。它提供的功能与可重新初始化迭代器的相同,但在迭代器之间切换时不需要从数据集的开头初始化迭代器。
4、从迭代器中读取数据
Iterator.get_next() 方法返回一个或多个 tf.Tensor 对象,这些对象对应于迭代器的下一个元素。每次 eval 这些张量时,它们都会获取底层数据集中下一个元素的值。(请注意,与 TensorFlow 中的其他有状态对象一样,调用 Iterator.get_next() 并不会立即使迭代器进入下个状态。相反,您必须使用 TensorFlow 表达式中返回的 tf.Tensor 对象,并将该表达式的结果传递到 tf.Session.run(),以获取下一个元素并使迭代器进入下个状态
如果迭代器到达数据集的末尾,则执行 Iterator.get_next() 指令会产生 tf.errors.OutOfRangeError。在此之后,迭代器将处于不可用状态;如果需要继续使用,则必须对其重新初始化。
本例中使用方法如下:
next_batch = iterator.get_next()
return sess.run(next_batch)本例中完整代码如下
import tensorflow as tf # 导入tensorflow库
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 设置输出等级,此时不输出警告
# 初始化变脸和模型参数,定义训练闭环中的运算;inference的中文翻译是推测
w = tf.Variable(tf.zeros([5, 1]), name="weights")
b = tf.Variable(0., name='bais')
def combine_inputs(x):
# 首先计算激活函数sigmoid的输入,即原始输入的组合
x1 = tf.matmul(x, w)+b
return x1
def inference(x):
# 计算推断模型在数据x上的输出,并将结果返回
y = tf.sigmoid(combine_inputs(x))
return y
def loss(x, y):
total_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=combine_inputs(x), labels=y))
return total_loss
def map_csv(line):
record_defaults = [[0.0], [0.0], [0], [''], [''], [0.0], [0.0], [0.0], [''], [0.0], [''], ['']]
map_value = tf.decode_csv(line, record_defaults=record_defaults)
return map_value
def read_csv(sess, batch_size, file_name):
dataset = tf.data.TextLineDataset([os.path.dirname(__file__) + '/' + file_name]).skip(1).repeat()
dataset1 = dataset.batch(batch_size)
dataset1 = dataset1.map(map_csv)
iterator = dataset1.make_initializable_iterator()
sess.run(iterator.initializer)
# iterator = dataset.make_one_shot_iterator()
next_batch = iterator.get_next()
return next_batch
def inputs(sess, filename, batch_num):
# 读取或生成训练数据x及其期望输出y
passenger_id, survived, pclass, name, sex, age, sibsp, parch, ticket, fare, cabin, embarked = read_csv(sess, batch_num, filename)
# 转换属性数据
is_first_class = tf.to_float(tf.equal(pclass, [1]))
is_second_class = tf.to_float(tf.equal(pclass, [2]))
is_third_class = tf.to_float(tf.equal(pclass, [3]))
gender = tf.to_float(tf.equal(sex, ['female']))
# 最终将所有特征排列在一个矩阵中,然后对该矩阵转置,使其每行对应一个样本,每列对应一种特征
features = tf.transpose(tf.stack([is_first_class, is_second_class, is_third_class, gender, age]))
survived = tf.reshape(survived, [batch_num, 1])
return features, survived
def train(total_loss):
# 根据计算的总损失训练或调整模型参数
learning_rate = 0.01
op = tf.train.GradientDescentOptimizer(learning_rate).minimize(total_loss)
return op
def evaluate(sess, x, y):
# 对训练得到的模型进行评估
predicted = tf.cast(inference(x) > 0.5, tf.float32)
print(sess.run(tf.reduce_mean(tf.cast(tf.equal(predicted, y), tf.float32))))
return
# 在一个会话中启动数据流图,搭建流程
with tf.Session() as sess:
# 初始化所有的变量
tf.global_variables_initializer().run()
# 获取训练数据
x, y = inputs(sess, 'train.csv', 100)
# 获取所有损失值
total_loss = loss(x, y)
# 获取经过此次训练更新后的模型参数
train_op = train(total_loss)
# 训练
training_step = 1000
for step in range(training_step):
a = sess.run([train_op])
# 评估现在的模型
evaluate(sess, x, y)
# 关闭会话
sess.close()
拓展知识3 : 使用sess.run的情况总结
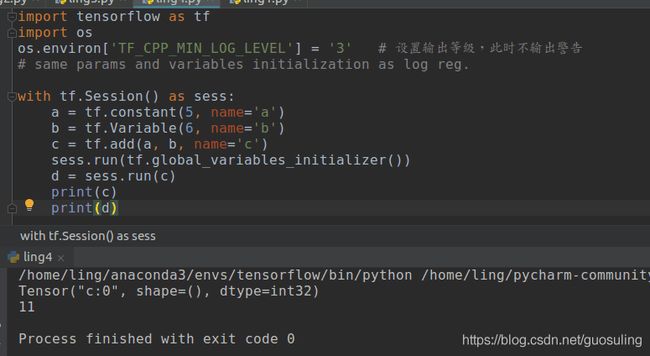
情况一:想立刻获取某个tensor张量的值,如下所示

上图中可以看出,c张量已经放到run里面运行了,但是再次print(c)时还是只输出c的属性,而输出sess.run(c)的返回值d时却看到了11,其实,11就是c张量此时的值,即:虽然此模型已经a,b,c节点都已经执行且已经生成了a,b,c张量值,但是直接print(张量)时还是只能获取张量的类型,只有输出张量在run函数里面之后的返回值才能得到张量的值,所以不能根据print(张量名)是否输出张量的值来确定输出该张量的节点是否被执行,比如上述代码中的a_op,b_op节点,虽然sess.run(c)时,与c张量有关的所有节点(a_op,b_op,c_op)肯定都已经执行且都生成了张量值(a,b,c),但是直接print(a)或者print(b)都只能得到其类型而不能得到其张量值
情况二、初始化某些节点
Variable对象与大多数其他TensorFlow对象在Graph中存在的方式都比较类似,但它们的状态实际上是由Session对象管理的。因此,为使用Variable对象,需要采取一些额外的步骤——必须在一个Session对象内对Variable对象进行初始化。这样会使Session对象开始追踪这个Variable对象的值的变化。数据读入迭代器的状态也是由session对象来管理其状态的,所以其初始化也需要在run中运行。
变量初始化,数据读入时迭代器初始化都需要在sess.run里面运行,变量初始化如下所示

数据读入时 迭代器初始化如下(上述已经介绍过4种迭代器:单次迭代器,可初始化迭代器,可重新初始化迭代器,可 feeding 迭代器,其中除了单次迭代器无需显示初始化外,其他三种迭代器的初始化都需要在run里面运行才能使该迭代器生效,注意:在run中运行的任何节点的状态sess会话都会记录并跟踪其状态),迭代器初始化举例如下:
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 设置输出等级,此时不输出警告
def a(sess):
dataset = tf.data.Dataset.range(10).repeat()
dataset1 =dataset.batch(3)
# iterator = dataset1.make_one_shot_iterator()
iterator =dataset1.make_initializable_iterator()
sess.run(iterator.initializer)
next_value = iterator.get_next()
# revalue = sess.run(next_value)
return next_value
with tf.Session() as sess:
value = a(sess)
for i in range(15):
print(sess.run(value))上述代码和下述代码功能一致
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 设置输出等级,此时不输出警告
with tf.Session() as sess:
# 首先建立0-9的数据集,然后repeat该数据集
dataset = tf.data.Dataset.range(10).repeat()
# 将数据集三个打包为一组
dataset1 = dataset.batch(3)
# iterator = dataset1.make_one_shot_iterator()
# 生成此数据集的可初始化迭代器
iterator = dataset1.make_initializable_iterator()
# 初始化迭代器
sess.run(iterator.initializer)
# 定义使用迭代器获取数据集下一步数据的张量
next_value = iterator.get_next()
# 依次得到数据集中的值
for i in range(15):
print(sess.run(next_value))
运行结果如下

程序变形如下
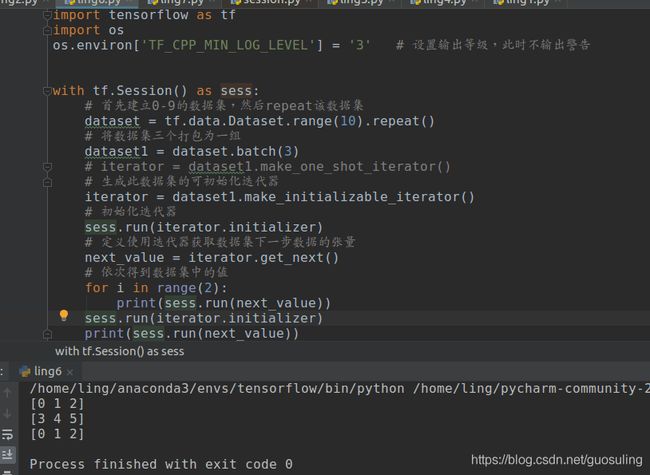
上下两张图对比可知,只要将迭代器的初始化再次run就会将该迭代器初始化,从而再次从数据库的头部读取文件
再次注意下述代码:
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 设置输出等级,此时不输出警告
def a(sess):
dataset = tf.data.Dataset.range(10).repeat()
dataset1 =dataset.batch(3)
# iterator = dataset1.make_one_shot_iterator()
iterator =dataset1.make_initializable_iterator()
sess.run(iterator.initializer)
next_value = iterator.get_next()
# revalue = sess.run(next_value)
return next_value
with tf.Session() as sess:
value = a(sess)
for i in range(15):
print(sess.run(value))
print(sess.run(value)) # 注意此处其运行结果如下

此时的初始化会有一点变动,正确的再次初始化数据库迭代器的方法如下

下述代码同样可以初始化,但是初始化得到的不再是value张量的值,如下
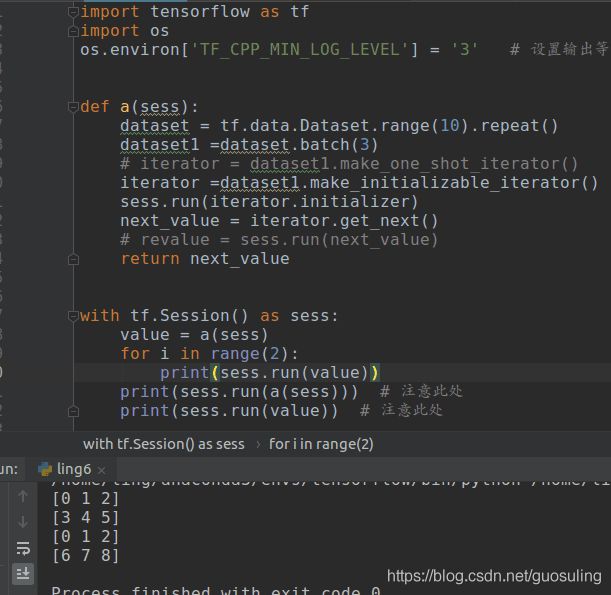
注意:上述函数中在循环体for中2次执行了print(sess.run(value)),而value的值由函数a(sess)得到,大家会误认为此处是循环执行了两次a(sess)函数体中的内容,故而初始化迭代器的语句sess.run(iterator.initializer)在也执行了两次,这是一个很大的误区,此处初始化迭代器的语句没有执行次,原因如下:tensorflow框架中,是图编程,在sess.run之前的所有操作只是定义了一组操作,这一组操作形成了一张图,当执行sess.run时再根据需要【此处的需要指的是要获得sess.run(tensor)时所需要的所有节点】数据开始流动,上述代码中函数a(sess)在run时就相当于一个包含多个节点的节点一样,该函数定义了一系列的操作,当执行sess.run(value)时你只需要执行 next_value = iterator.get_next()节点的操作就能得到value的值,无需再次初始化(已经在定义模型的时候就完成了初始化),故而没有再次执行初始化操作。
情况3 注意不要过分使用sess.run
错误使用1 :代码示例如下


上述代码中,唯一的区别就是标有“注意此处”的地方,整个代码的执行过程如下:首先构建模型a(sess),在该部分定义了数据集和其迭代器并初始化了该迭代器(初始化该迭代器后会话sess会记录该迭代器的状态,此时迭代器指向数据集的第一个元素0,),此时就是两个代码的不同之处:【左边代码直接返回迭代器指向的元素的tensor】,【而后侧代码会执行一次sess.run(next_value)故此时的迭代器指向了数据集的第二个元素1,然后返回迭代器此时指向元素的tensor】,接下来流程相同:循环2次获取迭代器指向的元素,故左侧迭代器获取了0和1,而右侧代码获取了1和2。我们一般需要的是左边代码的效果,所以不要在代码中任意加入sess.run
错误使用2 代码示例如下
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 设置输出等级,此时不输出警告
def a(sess):
dataset = tf.data.Dataset.range(10).repeat()
iterator =dataset.make_initializable_iterator()
sess.run(iterator.initializer)
next_value = iterator.get_next()
revalue = sess.run(next_value)
return revalue # 注意此处
with tf.Session() as sess:
value = a(sess)
for i in range(2):
print(sess.run(value))
上述代码执行效果如下

详细的错误信息如下,错误信息表示:在sess.run中的参数只能是字符串或者tensor张量,而此时的value却是int64类型
TypeError: Fetch argument 0 has invalid type , must be a string or Tensor. (Can not convert a int64 into a Tensor or Operation.)
上述代码在debug模式下运行结果如下,看绿色圈圈圈住的地方,其表示value是int64类型,值为0

上述代码经过修改,正确执行如下,但是执行结果却是输出两个0,这是为什么呢?下面将详细解释

先看一下两个代码的模型图,代码具体如下
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 设置输出等级,此时不输出警告
def a(sess):
dataset = tf.data.Dataset.range(10).repeat()
iterator =dataset.make_initializable_iterator()
sess.run(iterator.initializer)
next_value = iterator.get_next()
revalue = sess.run(next_value)
return revalue # 注意此处,直接返回run之后的值,此为代码1
with tf.Session() as sess:
value = tf.to_int32(a(sess))
b = tf.add(1, value, name='op_b')
writer = tf.summary.FileWriter('./1', sess.graph)
writer.close()
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 设置输出等级,此时不输出警告
def a(sess):
dataset = tf.data.Dataset.range(10).repeat()
iterator =dataset.make_initializable_iterator()
sess.run(iterator.initializer)
next_value = iterator.get_next()
return next_value # 注意此处,返回迭代器的tensor张量,此为代码2
with tf.Session() as sess:
value = tf.to_int32(a(sess))
b = tf.add(1, value, name='op_b')
writer = tf.summary.FileWriter('./1', sess.graph)
writer.close()
两个代码生成的模型如如下:
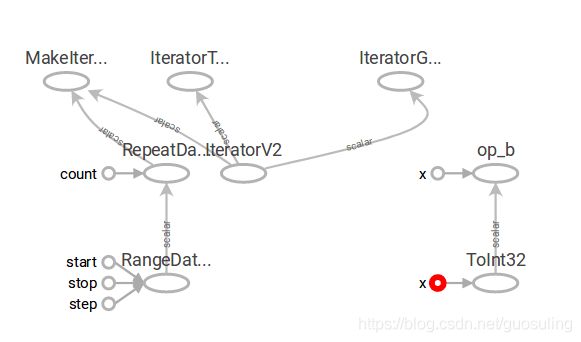
代码1的模型图如下:可以看出该代码生成的图是两个不相关联的部分
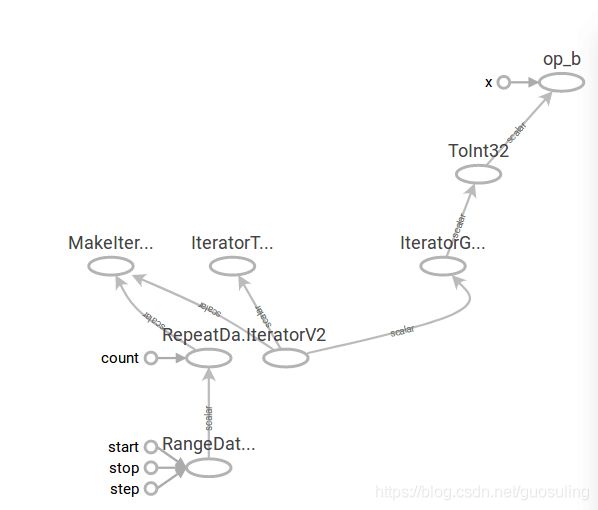
代码2的模型图如下:可以看出该代码生成的图是一个整图
再关注一下两个代码的b节点的输入节点
代码1 输入节点如下:


从上面两张图可得到结论:输入x和y都是const变量,核心原因就是代码1中返回的是sess.run之后的值,其恒为0,这就解释了为什么之前代码1为什么循环执行sess.run时恒输出0的问题,其就是因为a(sess)函数返回了一个具体的值而不是tensor张量,所以对于sess.run(b)时,无需执行迭代器节点,只需要执行相加的节点op_b,故恒为0
为验证上述结论,可以再看一下代码2的节点b的输入节点


总结:不要随便在函数中返回sess.run的值,因为如果直接返回sess.run的值那么会导致返回值成为一个常量,从而将模型分离,否则就可以返回一个tensor,从而是一个完整的图
拓展知识3 python中获取路径函数区别
https://blog.csdn.net/cyjs1988/article/details/77839238/
os.getcwd()获取的当前最外层调用的脚本路径
os.path.realname(__file__):获得的是深层的脚本文件的路径
os.path.dirname():去掉脚本的文件名,返回目录。
os.path.dirname(os,path.realname(__file__)):指的是,获得你刚才所引用的模块 所在的绝对路径,__file__为内置属性。
拓展知识4 os.path.join()函数
https://www.cnblogs.com/an-ning0920/p/10037790.html
os.path.join()函数:连接两个或更多的路径名组件
1.如果各组件名首字母不包含’/’,则函数会自动加上
2.如果有一个组件是一个绝对路径,则在它之前的所有组件均会被舍弃
3.如果最后一个组件为空,则生成的路径以一个’/’分隔符结尾
拓展知识4 assert 断言
https://www.cnblogs.com/liuchunxiao83/p/5298016.html
使用assert断言是学习python一个非常好的习惯,python assert 断言句语格式及用法很简单。在没完善一个程序之前,我们不知道程序在哪里会出错,与其让它在运行最崩溃,不如在出现错误条件时就崩溃,这时候就需要assert断言的帮助
python assert断言是声明其布尔值必须为真的判定,如果发生异常就说明表达示为假。可以理解assert断言语句为raise-if-not,用来测试表示式,其返回值为假,就会触发异常
assert的异常参数,其实就是在断言表达式后添加字符串信息,用来解释断言并更好的知道是哪里出了问题。格式如下:
assert expression [, arguments] 使用举例 assert len(lists) >=5,'列表元素个数小于5'
2.5 softmax分类
借助对数几率回归,可对Yes-No型问题的回答进行建模。现在,希望能够回答具有多个选项的问题,如“你的出生地是波士顿、伦敦还是悉尼?”对于这样的问题,可使用softmax函数,它是对数几率回归在C个可能不同的值上的推广。

注意:上图中的Xc和Xj前的负号要去掉
该函数的返回值为含C个分量的概率向量,每个分量对应于一个输出类别的概率。由于各分量为概率,C个分量之和始终为1,这是因为softmax的公式要求每个样本必须属于某个输出类别,且所有可能的样本均被覆盖。如果各分量之和小于1,则意味着存在一些隐藏的类别;若各分量之和大于1,则说明每个样本可能同时属于多个类别
可以证明,当类别总数为2时,所得到的输出概率与对数几率回归模型的输出完全相同
为实现该模型,需要将之前的模型实现中变量初始化部分稍做修改。由于模型需要计算C个而非1个输出,所以需要C个不同的权值组,每个组对应一个可能的输出。因此,会使用一个权值矩阵而非一个权值向量。该矩阵的每行都与一个输入特征对应,而每列都对应于一个输出类别。
在尝试softmax分类时,我们准备使用经典的鸢尾花数据集Iris(链接:https://pan.baidu.com/s/1HbHSXUC3Q5pLPy6qBftDIw
提取码:jk1m )。该数据集中包含4个数据特征及3个可能的输出类(不同类型的鸢尾花),因此权值矩阵的维数应为4×3
修改1: 变量初始化代码如下所示
# 初始化变脸和模型参数,定义训练闭环中的运算;inference的中文翻译是推测
w = tf.Variable(tf.zeros([4, 3]), name="weights")
b = tf.Variable(tf.zeros([3]), name='bais')修改2:推断模型修改如下
def inference(x):
# 计算推断模型在数据x上的输出,并将结果返回
y = tf.nn.softmax(combine_inputs(x))
return y修改3 修改损失函数如下
def loss(x, y):
total_loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=combine_inputs(x), labels=y))
return total_loss修改4 读入csv文件的映射函数修改
def map_csv(line):
record_defaults = [[0.0], [0.0], [0.0], [0.0], ['']]
map_value = tf.decode_csv(line, record_defaults=record_defaults)
return map_value修改5 输入函数修改
为了使用sparse_softmax_cross_entropy_with_logits,无须将每个类别都转换成它自己的变量,但需要将值转换为范围是0~2的整数,因为总的类别数为3。在数据集文件中,类别是一个来自“Iris-setosa”、“Iris-versicolor”和“Iris-virginica”的字符串。为对其进行转换,可用tf.pack创建一个张量,并利用tf.equal将文件输入与每个可能的值进行比较。然后,利用tf.argmax找到那个张量中值为真的位置,从而有效地将各类别转化为0~2范围的整数
def map_csv(line):
record_defaults = [[0.0], [0.0], [0.0], [0.0], ['']]
map_value = tf.decode_csv(line, record_defaults=record_defaults)
return map_value
def inputs(sess, filename, batch_num):
# 读取或生成训练数据x及其期望输出y
sepal_length, sepal_width, petal_length, petal_width, label = read_csv(sess, batch_num, filename)
# 转换属性数据
label_number = tf.to_int32(tf.argmax(tf.to_int32(tf.stack([
tf.equal(label, ["Iris-setosa"]),
tf.equal(label, ["Iris-versicolor"]),
tf.equal(label, ["Iris-virginica"])
])), 0))
# 最终将所有特征排列在一个矩阵中,然后对该矩阵转置,使其每行对应一个样本,每列对应一种特征
features = tf.transpose(tf.stack([sepal_length, sepal_width, petal_length, petal_width]))
return features, label_number修改6 评估函数修改如下
推断过程将计算各测试样本属于每个类别的概率。可利用tf.argmax函数来选择预测的输出值中具有最大概率的那个类别。最后,把tf.equal与期望的类别进行比较,并像之前sigmoid的例子中那样运用tf.reduce_mean计算准确率
def evaluate(sess, x, y):
# 对训练得到的模型进行评估
predicted = tf.cast(tf.argmax(inference(x), 1), tf.int32)
sess.run(tf.reduce_mean(tf.cast(tf.equal(predicted, y), tf.float32)))
return拓展知识1 : tf.argmax() 用法
https://blog.csdn.net/Jiaach/article/details/78874704
tf.argmax(input, dimension, name=None) 返回最大数值的下标
参数说明: dimension=0 按列找 ;dimension=1 按行找 ,默认按列找
拓展知识2 : tf.cast()
cast(x,dtype,name=None) 将x的数据格式转化成dtype.拓展知识3:tf.stack()和tf.unstack()的用法__函数用法
tf.stack()这是一个矩阵拼接的函数,tf.unstack()则是一个矩阵分解的函数
stack(values, axis=0, name="stack"),按轴axis打包数据,使用代码如下
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 设置输出等级,此时不输出警告
a = tf.constant([1, 2, 3])
b = tf.constant([4, 5, 6])
with tf.Session() as sess:
c = tf.stack([a, b], axis=0)
d = tf.stack([a, b], axis=1)
e = sess.run([c, d])
print([e])
在debug模式下运行,可以看到a和b打包后的具体值,如下 ,可以看出两个结果是转置的关系


拓展知识4 tf.nn.sparse_softmax_cross_entropy_with_logits()和tf.nn.softmax_cross_entropy_with_logits()的区别
https://blog.csdn.net/agentljc/article/details/79620774
tf.nn.sparse_softmax_cross_entropy_with_logits(labels,logits)多了一步稀疏编码,所以labels只需要输入不同的数值带表不同的类别即可,例如[1,2,3,3,2,1]
tf.nn.softmax_cross_entropy_with_logits(labels,logits)则没有稀疏编码,所以需要输入的labels即为one-hot编码,如[[1,0,0],[0,1,0],[0,0,1],[0,0,1],[0,1,0],[1,0,0]]
该部分整个代码为
import tensorflow as tf # 导入tensorflow库
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # 设置输出等级,此时不输出警告
# 初始化变脸和模型参数,定义训练闭环中的运算;inference的中文翻译是推测
w = tf.Variable(tf.zeros([4, 3]), name="weights")
b = tf.Variable(tf.zeros([3]), name='bais')
def combine_inputs(x):
# 首先计算激活函数sigmoid的输入,即原始输入的组合
x1 = tf.matmul(x, w)+b
return x1
def inference(x):
# 计算推断模型在数据x上的输出,并将结果返回
y = tf.nn.softmax(combine_inputs(x))
return y
def loss(x, y):
total_loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=combine_inputs(x), labels=y))
return total_loss
def map_csv(line):
record_defaults = [[0.0], [0.0], [0.0], [0.0], ['']]
map_value = tf.decode_csv(line, record_defaults=record_defaults)
return map_value
def read_csv(sess, batch_size, file_name):
dataset = tf.data.TextLineDataset([os.path.dirname(__file__) + '/' + file_name]).repeat()
dataset1 = dataset.batch(batch_size)
dataset2 = dataset1.map(map_csv)
iterator = dataset2.make_initializable_iterator()
sess.run(iterator.initializer)
next_batch = iterator.get_next()
return next_batch
def inputs(sess, filename, batch_num):
# 读取或生成训练数据x及其期望输出y
sepal_length, sepal_width, petal_length, petal_width, label = read_csv(sess, batch_num, filename)
# 转换属性数据
label_number = tf.to_int32(tf.argmax(tf.to_int32(tf.stack([
tf.equal(label, ["Iris-setosa"]),
tf.equal(label, ["Iris-versicolor"]),
tf.equal(label, ["Iris-virginica"])
])), 0))
# 最终将所有特征排列在一个矩阵中,然后对该矩阵转置,使其每行对应一个样本,每列对应一种特征
features = tf.transpose(tf.stack([sepal_length, sepal_width, petal_length, petal_width]))
return features, label_number
def train(total_loss):
# 根据计算的总损失训练或调整模型参数
learning_rate = 0.01
op = tf.train.GradientDescentOptimizer(learning_rate).minimize(total_loss)
return op
def evaluate(sess, x, y):
# 对训练得到的模型进行评估
predicted = tf.cast(tf.argmax(inference(x), 1), tf.int32)
sess.run(tf.reduce_mean(tf.cast(tf.equal(predicted, y), tf.float32)))
return
# 在一个会话中启动数据流图,搭建流程
with tf.Session() as sess:
# 初始化所有的变量
tf.global_variables_initializer().run()
# 获取训练数据
x, y = inputs(sess, 'lris.csv', 50)
# 获取所有损失值
total_loss = loss(x, y)
# 获取经过此次训练更新后的模型参数
train_op = train(total_loss)
writer = tf.summary.FileWriter('./test1', sess.graph)
# 训练
training_step = 2000
for step in range(training_step):
a = sess.run([train_op])
# 评估现在的模型
evaluate(sess, x, y)
# 关闭会话
sess.close()总结:上述总体代码的运行顺序如下:sess.run([train_op])之前的所有操作都是定义模型,真正开始执行是从run函数开始,执行顺序如下,首先input函数输入50个样本数据,然后计算在当前情况下的损失值total_loss,然后进行此次的训练。如此往复。
注意:一般调用tf.equal之后都需要调用tf.to_float或其他类似类型转换函数,因为tf.equal得到的是bool类型
【此例使用的训练集lris一共有150个样本】可以注意到评估函数evaluate函数也输入了参数x,此时的x同样是50个样本,但是根据之前训练此时training_step的不同,评估函数会获取不一样的50个样本,比如,若训练了2次,那么模型只能对前50*2=100个数据进行训练,同时评估函数获取的第100-149个样本,但是因为此时只对前100个样本进行过训练而没有对之后的50个样本进行训练导致此时的准确率为0,如下所示。所以训练次数最基本的要求是覆盖所有样本

2.6 多层神经网络
到目前为止,我们已经使用过了比较简单的神经网络,但并未特别声明。线性回归模型和对数几率回归模型本质上都是单个神经元,它具有以下功能:
·计算输入特征的加权和。可将偏置视为每个样本中输入特征为1的权重,称之为计算特征的线性组合。
·然后运用一个激活函数(或传递函数)并计算输出。对于线性回归的例子,传递函数为恒等式(即保持值不变),而对数几率回归将sigmoid函数作为传递函数。
下图表示了每个神经元的输入、处理和输出。

对于softmax分类,使用了一个含C个神经元的网络,其中每个神经元对应一个可能的输出类别
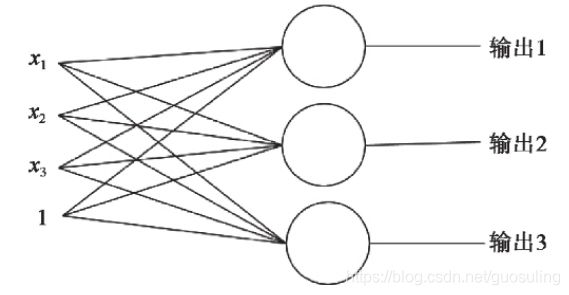
为求解一些更复杂的问题,如手写数字识别,或识别图像中的猫和狗,我们需要一个更复杂的模型。
首先从一个简单的例子开始,假设希望构建一个能够学习如何拟合“异或”(XOR)运算的网络
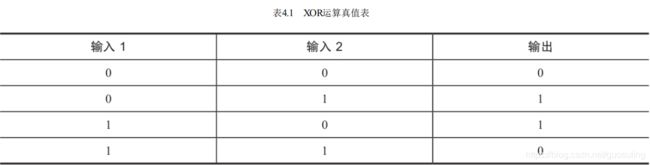
当两个输入中有一个为1但不全为1时,该运算结果应为1。这个问题看似比之前尝试过的都要简单,但到目前为止所接触过的模型都无法解决它。原因在于sigmoid类型的神经元要求数据线性可分,这意味着对于2D数据,一定存在一条直线(对于高维数据则为超平面),它可将分别属于两个类别的样本分隔在直线两侧,如下图所示
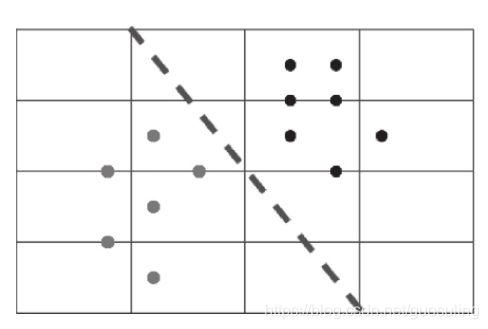
下面来看“异或”门函数的图形表示。

在上图中,无法找到一条直线能够完美地将黑色点(对应布尔值1)和灰色点(对应布尔值0)完美区分,这是因为“异或”函数的输出不是线性可分的
这个问题在20世纪70年代一度使神经网络研究失去重要性长达近10年之久,后来的研究人员为了继续使用神经网络解决这种不具备线性可分性的问题,采取在神经网络的输入端和输出端之间插入更多的神经元,如下图所示

可以看到,在输入层和输出层之间增加了一个隐含层(hidden layer),可这样来认识这个新层:它使得网络可以对输入数据提出更多的问题,隐含层中的每个神经元对应一个问题,并依据这些问题的回答最终决定输出的结果
添加隐含层的作用相当于在数据分布图中允许神经网络绘制一条以上的分隔线
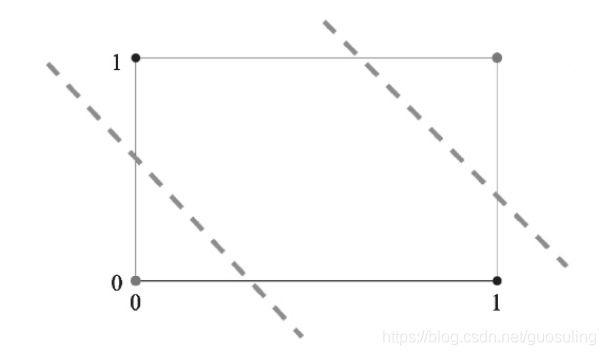
从上图可以看到,每条分隔线都为向输入数据提出的第一批问题针对平面进行了划分。然后,再将所有相等的输出划分到单个区域中。通过添加更多的隐含层,神经网络的层数变得更“深”。这些隐含层之间可采用不同类型的连接,甚至在每层中使用不同的激活函数
参考:《面向机器智能的TensorFlow实践》