作者简介
盛宇帆,StreamNative 开发工程师,Apache Pulsar 与 Apache Flink 贡献者。加入 StreamNative 之前,他曾就职于阿里大数据平台和腾讯云负责 Flink 开发工作。盛宇帆是腾讯云项目 Barad 的核心 committer 与项目落地负责人。他目前在 StreamNative 负责 Pulsar-Flink 和 Pulsar-Spark 相关的开发工作,他和他的团队已经将 Pulsar Source Connector 贡献给 Flink 社区,并于 Apache Flink 1.14.0 发布,并将在后续的发布中完整地将 Pulsar Connector 贡献给社区。
编辑:Jipei@StreamNative,Apache Pulsar 贡献者。
本文摘要
- 批流一体是数据计算的未来趋势,Pulsar Flink Connector 为基于 Apache Pulsar 在 Apache Flink 上以批流一体的方式处理数据提供了理想的解决方案。
- StreamNative 已将 Pulsar Source Connector 贡献至 Flink 1.14.0 版本。用户可以使用它从 Pulsar 读取数据,并保证每条数据只被处理一次。
- 最新 Pulsar Flink Connector 基于 Pulsar 2.8.0 和 Flink 1.14 版本,支持 Pulsar 的事务处理,进一步融合了两者的特性。
背景
随着数据日益膨胀,采用事件流处理数据至关重要。Apache Flink 将批流处理统一到计算引擎中,提供了一致化的编程接口。Apache Pulsar(与 Apache BookKeeper 一起)以 "流 "的方式统一数据。在 Pulsar 中,数据存储成一个副本,以流(streaming)(通过 pub-sub 接口)和 segment(用于批处理)的方式进行访问。Pulsar 解决了企业在使用不同的存储和消息技术解决方案时遇到的数据孤岛问题。
Flink 可以直接与 Pulsar broker 进行实时的流式读写,同时 Flink 也可以批量读取 Pulsar 底层离线存储,与 BookKeeper 的内容进行批次读写。同时支持批流,使得 Pulsar 和 Flink 先天就是契合的伙伴。把 Flink 和 Pulsar 结合使用,这两种开源技术可以创建一个统一的数据架构,为实时数据驱动企业提供最佳解决方案。
为了将 Pulsar 与 Flink 的功能进行整合,为用户提供更强大的开发能力,StreamNative 开发并开源了 Pulsar Flink Connector。经过多次的打磨,Pulsar Flink Connector 已合并进 Flink 代码仓库,并在 Flink 1.14.0 版本中发布!
Pulsar Flink Connector 基于 Apache Pulsar 和 Apache Flink 提供弹性数据处理,允许 Apache Flink 读写 Apache Pulsar 中的数据。使用 Pulsar Flink Connector,企业能够更专注于业务逻辑,无需关注存储问题。
打造全新的 Pulsar Flink Connector
在此版本之前,StreamNative 已发布 Pulsar Flink Connector 2.7 版本。为什么要推翻之前的代码,重新打造批流融合呢?在新版本中进行了哪些重构呢?

新版本改动
拆分设计
所有的数据消费都是基于 split(分流) 创建 Reader 去消费数据。如何将 Pulsar 消息抽象为 split?首先我们对 topic 进行抽象,针对每一个分区创建 Partition 示例。对有分区的 topic 就按数量创建,而对无分区的 topic 只有 1 个 partition,其值为 -1。

在 Pulsar 的 exclusive(独占)、shared(共享)和 failover(灾备)订阅模式中,我们将 topic partition 包装为在 Flink 上消费的 split,其中包含消费节点、存储节点和两个特殊的状态,最后消费的消息 ID 和当前处理的事务 ID 分别用于 Pulsar 的不同模式。在 Pulsar 的 key_shared (键共享)模式中,在 topic partition 和 split 间映射的时候增加了 range 层。

针对每个分区创建 split 的原因在于:
- Pulsar 的分区实际也是 topic;
- Topic 分区实际是子 topic;
- 仅可在单一 topic 上执行 Consumer.seek()。
枚举器(enumerator)设计
枚举器对应 split 分发和订阅的接口。这个设计注意分成两个部分,一部分是基于 TopicList,对于用户给定的一组 topic,从 Pulsar 进行信息查询;另一部分是 Topic Pattern,查询当前 topic、正则匹配并创建 split。
在 exclusive(独占)、key_shared(键共享)和 failover(灾备)模式中,一个 split 只会被以轮循的方式分配给一个 reader。




在 shared(共享)模式中,每个 split 会分给每个 reader,在此模式中,每个 reader 会消费 Pulsar 的每个 partition。


Reader 设计
在 exclusive(独占)和 failover(灾备)模式中,Reader 设计如下:

我们可以看到这个 topic 当前有三个分区,在 enumerator 这一层根据分区创建 3 个 split,Flink 的并行度为 3,产生 Reader 0、1、2 三个 reader 分别消费 split,由此形成独占的消费模式。Failover 模式和独占模式是一样的消费模型,二者都是顺序消费。
Unordered Reader
Unordered Split Reader
SortedMap> cursorsToCommit
ConcurrentMap cursorsOfFinishedSplits
ScheduledExecutorService cursorScheduler 在 Pulsar 的 Shared 和 Key_shared 模式下,消费是无序的。我们既不希望它顺序消费,也不希望一条条地 ACK。于是我们在这里引入事务(transaction),每创建一条消息就开启一个事务,在事务内进行 ACK,事务 ACK 会在 checkpoint 上进行提交。
Unordered Reader
Unordered Split Reader
TransactionCoordinatorClient coordinatorClient
SortedMap> transactionsToCommit
List transactionsOfFinishedSplits 类型系统
Pulsar 同 Flink 类似,都有类型系统。
Flink 的类型系统:
- DeserializationSchema:对原始数据进行解码;
- TypeInformation:Flink 每个 strength?之间基于 TypeInformation 进行数据序列化而传输
- TypeSerializer:TypeInformation 创建的序列化实例。
在 Pulsar 中:
- Schema:Pulsar Schema 是 Client 端数据序列化和反序列化的接口;
- SchemaInfo:接口创建 SchemaInfo 传输给 Broker,broker 根据 SchemaInfo 进行 Schema 版本的兼容和 Schema 是否能够升级的校验。SchemaInfo 使 broker 不需要进行序列化和反序列化;
- SchemaDefinition:给 Client 创建 Schema 所需的实例。
因此 Pulsar 和 Flink 在类型系统上进行打通,就产生了以下两种模式:
- 常见模式:Reader 以 Byte 数据的形式进行消费,用 Flink 的 DeserializationSchema 进行解析,DeserializationSchema 自带的 TypeInformation 向下游传递。Flink 和其他消息系统也是用这种模式。


- Pulsar 独有的模式:Reader 以 Byte 数据的形式进行消费,在 Flink 上以 Pulsar Schema 将数据进行解码,并自动创建能在 Flink 上使用的 TypeInformation。

但是在第二种模式中没有用到 Pulsar 自带的 Schema 兼容和校验,在下个版本中我们将用到这个特性。
版本要求
Flink 当前只提供 Pulsar Source connector,用户可以使用它从 Pulsar 读取数据,并保证每条数据只被处理一次。
连接器当前支持 Pulsar 2.7.0 之后的版本,但是连接器使用到了 Pulsar 的事务机制,建议在 Pulsar 2.8.0 及其之后的版本上使用连接器进行数据读取。更多关于 Pulsar API 兼容性设计可阅读 PIP-72。
org.apache.flink
flink-connector-pulsar_2.11
1.14.0
阅读文档,了解如何将连接器添加到 Flink 集群实例内。
使用 Flink 1.14.0 的 Pulsar Source Connector
新版本的 Pulsar Source Connector 已被合并进 Flink 最新发布的 1.14.0 版本。如果要想使用基于旧版的 SourceFunction 实现的 Pulsar Source Connector,或者是使用的 Flink 版本低于 1.14,可以使用 StreamNative 单独维护的 pulsar-flink。
构造 Pulsar Source Connector 实例
Pulsar Source Connector 提供了 builder 类来构造 Source Connector 实例。下面的代码实例使用 builder 类创建的 Source Connector 会从 topic “persistent://public/default/my-topic” 的数据开始端进行消费。连接器使用了 Exclusive(独占)的订阅方式消费消息,订阅名称为 my-subscription,并把消息体的二进制字节流以 UTF-8 的方式编码为字符串。
PulsarSource pulsarSource = PulsarSource.builder()
.setServiceUrl(serviceUrl)
.setAdminUrl(adminUrl)
.setStartCursor(StartCursor.earliest())
.setTopics("my-topic")
.setDeserializationSchema(PulsarDeserializationSchema.flinkSchema(new SimpleStringSchema()))
.setSubscriptionName("my-subscription")
.setSubscriptionType(SubscriptionType.Exclusive)
.build();
env.fromSource(source, WatermarkStrategy.noWatermarks(), "Pulsar Source"); 如果使用构造类构造 Pulsar Source Connector ,一定要提供下面几个属性:
- Pulsar 数据消费的地址,使用 setServiceUrl(String) 方法提供;
- Pulsar HTTP 管理地址,使用 setAdminUrl(String) 方法提供;
- Pulsar 订阅名称,使用 setSubscriptionName(String) 方法提供;
- 需要消费的 topic 或者是 topic 下面的分区,详见指定消费的 Topic 或者 Topic 分区;
- 解码 Pulsar 消息的反序列化器,详见反序列化器。
指定消费的 Topic/Topic 分区
Pulsar Source Connector 提供了两种订阅 topic 或 topic 分区的方式:
- Topic 列表,从这个 Topic 的所有分区上消费消息,例如:
PulsarSource.builder().setTopics("some-topic1", "some-topic2")
// 从 topic "topic-a" 的 0 和 1 分区上消费
PulsarSource.builder().setTopics("topic-a-partition-0", "topic-a-partition-2")- Topic 正则,连接器使用给定的正则表达式匹配出所有合规的 topic,例如:
PulsarSource.builder().setTopicPattern("topic-*")Topic 名称简写
从 Pulsar 2.0 之后,完整的 topic 名称格式为 {persistent|non-persistent}://租户/命名空间/topic。但是连接器不需要提供 topic 名称的完整定义,因为 topic 类型、租户、命名空间都设置了默认值。

当前支持的简写方式:
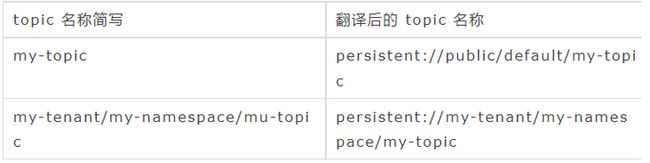
⚠️注意:对于 non-persistent(非持久化) topic,连接器不支持简写名称,non-persistent://public/default/my-topic不可简写成non-persistent://my-topic。
订阅分区结构的 Topic
对于 Pulsar 而言,Topic 分区也是一种 Topic。Pulsar 会将一个有分区的 Topic 在内部按照分区的大小拆分成等量的无分区 Topic。例如,在 Pulsar 的 sample 租户下面的 flink 命名空间里面创建了一个有 3 个分区的 topic,给它起名为 simple-string。可以在 Pulsar 上看到如下的 topic 列表:
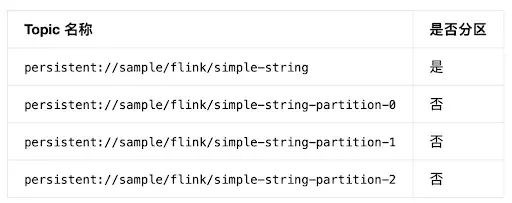
这意味着,用户可以用上面的子 topic 去直接消费分区里面的数据,不需要再去基于上层的父 topic 去消费全部分区的数据。例如:使用 PulsarSource.builder().setTopics("sample/flink/simple-string-partition-1", "sample/flink/simple-string-partition-2") 将会只消费 topic sample/flink/simple-string 上面的分区 1 和 2 里面的消息。
配置 Topic 正则表达式
前面提到了 Pulsar topic 有 persistent、non-persistent 两种类型,使用正则表达式消费数据的时候,连接器会尝试从正则表达式里面解析出消息的类型。例如:PulsarSource.builder().setTopicPattern("non-persistent://my-topic*") 会解析出 non-persistent topic 类型。如果用户使用 topic 名称简写的方式,连接器会使用默认的消息类型 persistent。
如果想用正则去消费 persistent 和 non-persistent 类型的 topic,需要使用 RegexSubscriptionMode 定义 topic 类型,例如:setTopicPattern("topic-*",RegexSubscriptionMode.AllTopics)`。
解析消息——反序列化器
反序列化器用于解析 Pulsar 消息,连接器使用 PulsarDeserializationSchema来定义反序列化器。用户可以在 builder 类中使用 setDeserializationSchema(PulsarDeserializationSchema)方法配置反序列化器,它会解析 Pulsar 的 Message 实例。
如果用户只关心消息体的二进制字节流,并不需要其他属性来解析数据。可以直接使用预定义的 PulsarDeserializationSchema。Pulsar 连接器里面提供了 3 种预定义好的反序列化器:
- 使用 Pulsar 的 Schema 解析消息。
// 基础数据类型
PulsarDeserializationSchema.pulsarSchema(Schema)
// 结构类型 (JSON, Protobuf, Avro, etc.)
PulsarDeserializationSchema.pulsarSchema(Schema, Class)
// 键值对类型
PulsarDeserializationSchema.pulsarSchema(Schema, Class, Class)- 使用 Flink 的
DeserializationSchema解析消息。
PulsarDeserializationSchema.flinkSchema(DeserializationSchema)- 使用 Flink 的 TypeInformation 解析消息。
PulsarDeserializationSchema.flinkTypeInfo(TypeInformation, ExecutionConfig)Pulsar 的 Message 包含了很多额外的属性。例如,消息的 key、消息发送时间、消息生产时间、用户在消息上自定义的键值对属性等。可以使用 Message 接口来获取这些属性。
如果用户需要基于这些额外的属性来解析一条消息,可以实现 PulsarDeserializationSchema 接口, 并一定要确保 PulsarDeserializationSchema.getProducedType()方法返回的 TypeInformation 是正确的结果。Flink 使用 TypeInformation 将解析出来的结果序列化传递到下游算子。
订阅模式
Pulsar 共支持四种订阅模式:exclusive(独占)、shared(共享)、failover(灾备)、 key_shared(key 共享)。当前 Pulsar 连接器里面,独占 和 灾备 的实现没有区别,如果 Flink 的一个 reader 挂了,连接器会把所有未消费的数据交给其他的 reader 来消费数据。默认情况下,如果没有指定订阅类型,连接器使用共享订阅类型(SubscriptionType.Shared)。
// 名为 "my-shared" 的共享订阅
PulsarSource.builder().setSubscriptionName("my-shared")
// 名为 "my-exclusive" 的独占订阅
PulsarSource.builder().setSubscriptionName("my-exclusive").setSubscriptionType(SubscriptionType.Exclusive)如果想在 Pulsar 连接器里面使用 key 共享 订阅,需要提供 RangeGenerator 实例。RangeGenerator 会生成一组消息 key 的 hash 范围,连接器会基于给定的范围来消费数据。Pulsar 连接器也提供了一个名为 UniformRangeGenerator 的默认实现,它会基于 flink Source Connector 的并行度将 hash 范围均分。
起始消费位置
连接器使用 setStartCursor(StartCursor) 方法给定开始消费的位置。内置的消费位置有:
- 从 topic 里面最早的一条消息开始消费。
StartCursor.earliest()- 从 topic 里面最新的一条消息开始消费。
StartCursor.latest()- 从给定的消息开始消费。
StartCursor.fromMessageId(MessageId)- 与前者不同的是,给定的消息可以跳过,再进行消费。
StartCursor.fromMessageId(MessageId,boolean)从给定的消息时间开始消费。
StartCursor.fromMessageTime(long)每条消息都有一个固定的序列号,这个序列号在 Pulsar 上有序排列,其包含了 ledger、entry、partition 等原始信息,用于在 Pulsar 底层存储上查找到具体的消息。Pulsar 称这个序列号为 MessageId,用户可以使用 DefaultImplementation.newMessageId(long ledgerId, long entryId, int partitionIndex)创建它。
边界
Pulsar 连接器同时支持流式和批的消费方式,默认情况下,连接器使用流的方式消费数据。除非任务失败或者被取消,否则连接器将持续消费数据。用户可以使用 setBoundedStopCursor(StopCursor)给定停止消费的位置,这种情况下连接器会使用批的方式进行消费。当所有 topic 分区都消费到了停止位置,Flink 任务就会结束。使用流的方式一样可以给定停止位置,使用 setUnboundedStopCursor(StopCursor)方法即可。内置的停止位置如下:
- 永不停止。
StopCursor.never()- 停止于 Pulsar 启动时 topic 里面最新的那条数据。
StopCursor.latest()- 停止于某条消息,结果里不包含此消息。
StopCursor.atMessageId(MessageId)- 停止于某条消息之后,结果里包含此消息。
StopCursor.afterMessageId(MessageId)- 停止于某个给定的消息时间戳。
StopCursor.atEventTime(long)其他配置项
除了前面提到的配置选项,连接器还提供了丰富的选项供 Pulsar 专家使用,在 builder 类里通过 setConfig(ConfigOption 和 setConfig(Configuration) 方法给定 Pulsar 客户端、Pulsar API 的全部配置。具体参考其他配置项
动态分区发现
为了能在启动 Flink 任务之后还能发现在 Pulsar 上扩容的分区或者是新创建的 topic,连接器提供了动态分区发现机制。该机制不需要重启 Flink 任务。对选项 PulsarSourceOptions.PULSAR_PARTITION_DISCOVERY_INTERVAL_MS设置一个正整数即可启用。
// 10 秒查询一次分区信息
PulsarSource.builder()
.setConfig(PulsarSourceOptions.PULSAR_PARTITION_DISCOVERY_INTERVAL_MS, 10000);默认情况下,Pulsar 启用动态分区发现,查询间隔为 30 秒。用户可以给定一个负数,将该功能禁用。如果使用批的方式消费数据,将无法启用该功能。
事件时间与 watermark
默认情况下,连接器使用 Pulsar Message 里面的时间作为解析结果的时间戳。用户可以使用 WatermarkStrategy 来自行解析出想要的消息时间,并向下游传递对应的水位线。
env.fromSource(pulsarSource, new CustomWatermarkStrategy(), "Pulsar Source With Custom Watermark Strategy")定义 WatermarkStrategy 参考文档。
消息确认
一旦在 topic 上创建了订阅,消息便会存储在 Pulsar 里。即使没有消费者,消息也不会被丢弃。只有当连接器同 Pulsar 确认此条消息已经被消费,该消息才以某种机制会被移除。连接器支持四种订阅方式,它们的消息确认方式也大不相同。
独占和灾备订阅
独占 和 灾备 订阅下,连接器使用累进式确认方式。确认某条消息已经被处理时,其前面被消费的消息会自动被置为已读。Pulsar 连接器会在 Flink 完成检查点时将对应时刻消费的消息置为已读,以此来保证 Pulsar 状态与 Flink 状态一致。如果用户没有在 Flink 上启用检查点,连接器可以使用周期性提交来将消费状态提交给 Pulsar,使用配置 PulsarSourceOptions.PULSAR_AUTO_COMMIT_CURSOR_INTERVAL来进行定义。
需要注意的是,此种场景下,Pulsar 连接器并不依赖于提交到 Pulsar 的状态来做容错。消息确认只是为了能在 Pulsar 端看到对应的消费处理情况。
共享和 key 共享订阅
共享 和 key 共享 需要依次确认每一条消息,所以连接器在 Pulsar 事务里面进行消息确认,然后将事务提交到 Pulsar。首先需要在 Pulsar 的 borker.conf 文件里面启用事务:
transactionCoordinatorEnabled=true连接器创建的事务的默认超时时间为 3 小时,请确保这个时间大于 Flink 检查点的间隔。用户可以使用 PulsarSourceOptions.PULSAR_TRANSACTION_TIMEOUT_MILLIS来设置事务的超时时间。
如果用户无法启用 Pulsar 的事务,或者是因为项目禁用了检查点,需要将 PulsarSourceOptions.PULSAR_ENABLE_AUTO_ACKNOWLEDGE_MESSAGE选项设置为 true,消息从 Pulsar 消费后会被立刻置为已读。连接器无法保证此种场景下的消息一致性。连接器在 Pulsar 上使用日志的形式记录某个事务下的消息确认,为了更好的性能,请缩短 Flink 做检查点的间隔。
升级与问题诊断
升级步骤参阅升级应用程序和 Flink 版本。Pulsar 连接器没有在 Flink 端存储消费的状态,所有的消费信息都推送到了 Pulsar。
注意:
- 不要同时升级 Pulsar 连接器和 Pulsar 服务端的版本。
- 使用最新版本的 Pulsar 客户端来消费消息。
Flink 只使用了 Pulsar 的Java 客户端 和管理 API。使用 Flink 和 Pulsar 交互时如果遇到问题,很有可能与 Flink 无关,请先升级 Pulsar 的版本、Pulsar 客户端的版本,或者修改 Pulsar 的配置、Pulsar 连接器的配置来尝试解决问题。
联系我们
欢迎大家使用 Pulsar Flink Connector 并与我们交流,共同优化这个批流一体的项目。目前社区已成立 Pulsar Flink Connector SIG(特殊兴趣小组),扫描下方 Bot 二维码,回复“Flink”加入 Pulsar Flink Connector SIG,与项目开发者交流。

关注公众号「Apache Pulsar」,获取干货与动态