1.进程间通信介绍
1.1 进程通信的基本概念
在之前我们已经学习过进程地址空间。Linux 环境下,进程地址空间相互独立,每个进程各自有不同的用户地址空间。任何一个进程的全局变量在另一个进程中都看不到,所以进程和进程之间不能相互访问,要交换数据必须通过内核,在内核中开辟一块缓冲区,进程1把数据从用户空间拷到内核缓冲区,进程2再从内核缓冲区把数据读走,内核提供的这种机制称为进程间通信(IPC,Inter Process Communication)。

1.2 为什么要进程间通信
进程通信主要有以下目的:
- 数据传输:一个进程需要将它的数据发送给另一个进程。
- 资源共享:多个进程之间共享同样的资源。
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
1.3 常见的进程通信方式
在进程间完成数据传递需要借助操作系统提供特殊的方法,如今常见的进程间通信方式有:
① 管道 (分为匿名管道与命名管道)
② 信号 (开销最小)
③ 共享内存
2.管道
2.1管道简介
管道是Unix中最古老的进程间通信方式,我们把从一个进程连接到另一个进程的数据流叫做管道。
在Linux中,| 符号被用来代表管道。因为在Linux中,不同的命令,如ps,ls,grep等命令的本质都是可执行程序,| 前面的命令前面的命令通常会输出大量的结果,这些结果将会交由 | 后面的命令继续处理。
如下面这个命令就是将ps axj中含有PID的结果输出:

2.2 管道的创建和应用
管道的本质是内核中一块供不同进程进行读写的缓冲区,而外在的操作形式是通过文件读写的方式进行。
#include
功能:创建一无名管道
原型
int pipe(int fd[2]);
参数
fd:文件描述符数组,这是一个输出型参数,调用该接口后,将会给fd[2]数组分配两个文件描述符,两个文件描述符分别对应管道的读写两端。其中fd[0]表示读端, fd[1]表示写端
返回值:成功返回0,失败返回错误代码
我们先用一个简单的例子来看一下管道的创建:
#include
#include
int main()
{
int fd[2];
int ret=pipe(fd);
if(-1==ret)
{
std::cout<<"管道创建失败!"< 运行后:

可以看到,此时fd[0]和fd[1]返回了两个文件描述符。这两个文件描述符分别分别对应管道的读写两端。
#include
#include
#include
#include
#include
#include
#include
int main()
{
int fd[2];
pipe(fd);
pid_t pid = fork();
if(pid < 0)
{
printf("fork error!");
}else if(pid == 0)
{
//child
close(fd[0]);
char str[100];
while(1)
{
printf("child:");
fgets(str, 100, stdin);
ssize_t len = strlen(str);
if(write(fd[1], str, len) != len)
{
perror("write to pipe");
exit(1);
}
memset(str, 0, len);
sleep(1);
}
}
//father
int count = 0;
close(fd[1]);
while(count < 10)
{
char str[100];
ssize_t s = read(fd[0], str, 100);
if(s < 0){
perror("read from pipe");
break;
}else{
printf("father:%s", str);
}
memset(str, 0, strlen(str));
}
return 0;
}
上面这段代码实现了子进程写入管道,父进程读出的过程。

2.3 管道的底层机制
管道是在有血缘关系的进程之间来通信的,如父子进程,兄弟进程等。因此,应用匿名管道时一定会有fork函数的参与。
如下面这个简化图可以看到,
-
父进程先使用pipe函数创建管道,得到两个文件描述符 fd[0]、fd[1]指向管道的读端和写端。
-
父进程调用fork创建子进程,此时父子进程有相同的struct files_struct,父子进程指向的struct file又指向了同一片文件缓冲区。(注意:这个表述并不严谨,我们下面马上就会讲到)
-
接下来父进程关闭写端,子进程关闭读端,就可以实现子进程向管道中写,父进程读。注意:管道的通信是单向的!!!!
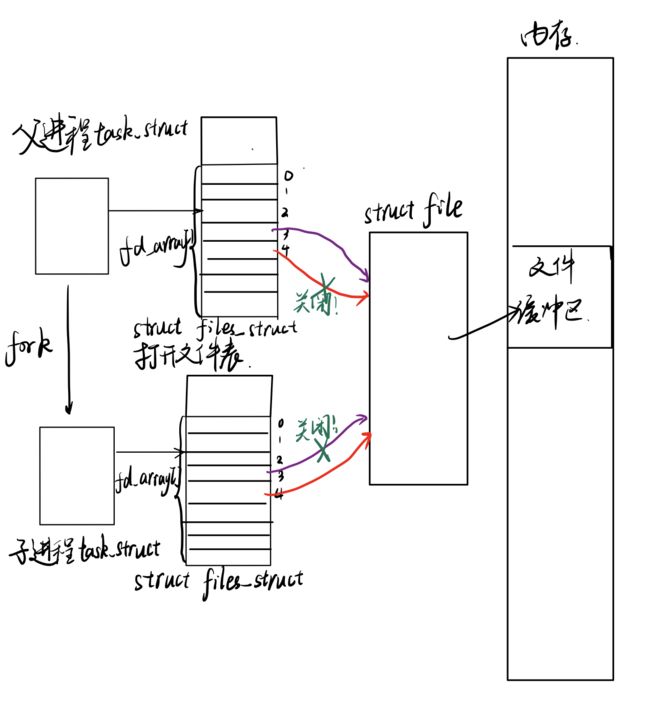
在 Linux 中,管道的实现并没有使用专门的数据结构,而是借助了文件系统的file结构和VFS的索引节点inode。通过将两个 file struct指向同一个临时的 inode,而这个 VFS 索引节点又指向一个物理页面而实现的。

如上图所示,有两个 file 数据结构,但它们定义文件操作例程地址是不同的,其中一个是向管道中写入数据的例程地址,而另一个是从管道中读出数据的例程地址。
这样,用户程序的系统调用仍然是通常的文件操作,而内核却利用这种抽象机制实现了管道这一特殊操作。看待管道,就如同看待文件一样!管道的使用和文件一致,迎合了“Linux一切皆文件思想”。
2.4 管道读写规则
用阻塞的方式打开管道(即默认情况下)
-
如果所有管道写端对应的文件描述符被关闭(管道写端引用计数为 0),读端在将管道中剩余数据读取后,再次read会返回0。(写端关闭)
-
如果有指向管道写端的文件描述符没关闭,且持有管道写端的进程也没有向管道中写数据,这时有进程从管道读端读数据,那么管道中剩余的数据都被读取后,再次 read 会阻塞。(读完不写)
-
如果所有指向管道读端的文件描述符都关闭了(管道读端引用计数为 0),进行write操作会产生信号SIGPIPE,进而可能导致write进程退出。(读端关闭)
-
如果有指向管道读端的文件描述符没关闭(管道读端引用计数大于 0),且读端进程并没有向管道中读进程,则当写端进程写满后,会进入阻塞。(写满不读)
2.5 管道的特点
- 只能用于具有共同祖先的进程(具有亲缘关系的进程)之间进行通信。
- 管道提供流式服务。
- 管道的生命周期随进程,进程退出,管道释放。
- 内核会对管道操作进行同步与互斥。
- 管道是半双工的,数据只能向一个方向流动;需要双方通信时,需要建立起两个管道
- 管道大小为65536 byte